Azure Data Lake Storage에서 Common Data Model 테이블에 연결
참고
Azure Active Directory는 이제 Microsoft Entra ID입니다. 자세히 알아보기
Common Data Model 테이블과 함께 Azure Data Lake Storage 계정을 사용하여 Dynamics 365 Customer Insights - Data에 데이터를 수집합니다. 데이터 수집은 전체 또는 증분일 수 있습니다.
전제 조건
Azure Data Lake Storage 계정에는 계층 구조 네임스페이스가 활성화되어 있어야 합니다. 데이터는 루트 폴더를 정의하고 각 테이블에 대한 하위 폴더가 있는 계층적 폴더 형식으로 저장해야 합니다. 하위 폴더에는 전체 데이터 또는 증분 데이터 폴더가 있을 수 있습니다.
Microsoft Entra 서비스 주체로 인증하려면 테넌트에 구성되어 있는지 확인하세요. 자세한 내용은 Microsoft Entra 서비스 주체를 사용하여 Azure Data Lake Storage 계정에 연결을 참조하세요.
방화벽으로 보호되는 스토리지에 연결하려면 Azure Private Link를 설정하세요.
데이터 레이크에 현재 프라이빗 링크 연결이 있는 경우 Customer Insights - Data도 네트워크 액세스 설정에 관계없이 프라이빗 링크를 사용하여 연결해야 합니다.
연결하고 데이터를 수집하려는 Azure Data Lake Storage는 Dynamics 365 Customer Insights 환경과 동일한 Azure 지역에 있어야 하며 구독은 동일한 테넌트에 있어야 합니다. 다른 Azure 지역의 데이터 레이크에서 Common Data Model 폴더에 대한 연결은 지원되지 않습니다. 환경의 Azure 지역을 알아보려면 Customer Insights - Data에서 관리자>시스템>정보로 이동하세요.
온라인 서비스에 저장된 데이터는 데이터가 처리되거나 저장되는 위치와 다른 위치에 저장될 수 있습니다. 온라인 서비스에서 저장된 데이터를 가져오거나 이에 연결하면 데이터가 전송될 수 있다는 데 동의하는 것입니다. Microsoft 보안 센터에서 자세히 알아보세요.
Customer Insights - Data 서비스 주체는 스토리지 계정에 액세스하려면 다음 역할 중 하나에 있어야 합니다. 자세한 내용은 서비스 주체에 스토리지 계정에 액세스할 수 있는 권한 부여를 참조하세요.
- 스토리지 Blob 데이터 Reader
- 스토리지 Blob 데이터 담당자
- Storage Blob 데이터 Contributor
Azure 구독 옵션을 사용하여 Azure Storage에 연결할 때 데이터 원본 연결을 설정하는 사용자는 저장소 계정에 대해 최소한 Storage Blob 데이터 Contributor 권한이 필요합니다.
Azure 리소스 옵션을 사용하여 Azure Storage에 연결할 때 데이터 원본 연결을 설정하는 사용자는 최소한 스토리지 계정에 대한 Microsoft.Storage/storageAccounts/read 작업에 대한 권한이 필요합니다. 이 작업을 포함하는 Azure 기본 제공 역할은 Reader 역할입니다. 필요한 작업으로만 액세스를 제한하려면 이 작업만 포함하는 Azure 사용자 지정 역할을 만드세요.
최적의 성능을 위해서는 파티션 크기가 1GB 이하여야 하며 폴더 내 파티션 파일 수는 1000개를 초과할 수 없습니다.
Data Lake Storage의 데이터는 데이터 저장을 위한 Common Data Model 표준을 따라야 하며 데이터 파일(*.csv 또는 *.parquet)의 스키마를 나타내는 Common Data Model 매니페스트가 있어야 합니다. 매니페스트는 테이블 열 및 데이터 형식, 데이터 파일 위치 및 파일 형식과 같은 테이블의 세부 정보를 제공해야 합니다. 자세한 내용은 Common Data Model 매니페스트를 참조하세요. 매니페스트가 없는 경우 Storage Blob 데이터 소유자 또는 Storage Blob 데이터 기여자 액세스 권한이 있는 관리자는 데이터를 수집할 때 스키마를 정의할 수 있습니다.
노트
.parquet 파일의 필드에 Int96 데이터 유형이 있는 경우 데이터가 테이블 페이지에 표시되지 않을 수 있습니다. Unix 타임스탬프 형식(1970년 1월 1일 자정 UTC 이후의 시간을 초 단위로 나타냄)과 같은 표준 데이터 유형을 사용하는 것이 좋습니다.
제한 사항
- Customer Insights - Data는 정밀도가 16보다 큰 10진수 유형의 열을 지원하지 않습니다.
Azure Data Lake Storage에 연결
데이터 연결 이름, 데이터 경로(예: 컨테이너 내의 폴더) 및 테이블 이름은 문자로 시작하는 이름을 사용해야 합니다. 이름에는 문자, 숫자 및 밑줄(_)만 사용할 수 있습니다. 특수 문자는 지원되지 않습니다.
데이터>데이터 원본으로 이동.
데이터 원본 추가를 선택합니다.
Azure Data Lake Common Data Model 테이블을 선택합니다.

데이터 소스 이름과 선택적 설명을 입력합니다. 이 이름은 다운스트림 프로세스에서 참조되며 데이터 원본을 만든 후에는 변경할 수 없습니다.
다음을 사용하여 스토리지 연결에 대해 다음 옵션 중 하나를 선택합니다. 자세한 내용은 Microsoft Entra 서비스 주체를 사용하여 Azure Data Lake Storage 계정에 연결을 참조하세요.
- Azure 리소스: 리소스 ID를 입력합니다.
- Azure 구독: 구독을 선택한 다음 리소스 그룹 및 스토리지 계정을 선택합니다.
참고
데이터 원본을 만들려면 컨테이너에 대해 다음 역할 중 하나가 필요합니다.
- Storage Blob 데이터 리더는 스토리지 계정에서 데이터를 읽고 Customer Insights - Data로 수집하는 데 충분합니다.
- Customer Insights - Data에서 매니페스트 파일을 직접 편집하려면 Storage Blob 데이터 기여자 또는 담당자가 필요합니다.
스토리지 계정에 대한 역할이 있으면 모든 컨테이너에 동일한 역할이 제공됩니다.
데이터를 가져올 데이터 및 스키마(model.json 또는 manifest.json 파일)가 포함된 컨테이너의 이름을 선택합니다.
참고
환경의 다른 데이터 원본과 연결된 model.json 또는 manifest.json 파일은 목록에 표시되지 않습니다. 그러나 여러 환경의 데이터 원본에 동일한 model.json 또는 manifest.json 파일을 사용할 수 있습니다.
선택적으로 Azure Private Link를 통해 스토리지 계정에서 데이터를 수집하려는 경우 프라이빗 링크 사용을 선택합니다. 자세한 내용은 프라이빗 링크를 참고하세요.
새 스키마를 생성하려면 새 스키마 파일 생성으로 이동합니다.
기존 스키마를 사용하려면 model.json 또는 manifest.cdm.json 파일이 포함된 폴더로 이동합니다. 디렉터리 내에서 검색하여 파일을 찾을 수 있습니다.
json 파일을 선택하고 다음을 선택합니다. 사용 가능한 테이블이 표시됩니다.
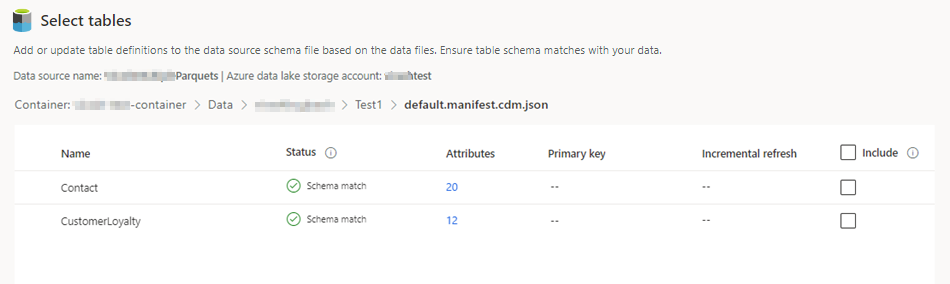
포함할 테이블을 선택합니다.
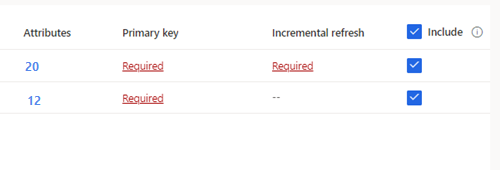
팁
JSON 편집 인터페이스에서 테이블을 편집하려면 해당 테이블을 선택하고 나서 스키마 파일 편집을 선택합니다. 변경하고 저장을 선택합니다.
기본 키가 정의되지 않은 선택된 테이블의 경우 기본 키 아래에 필수가 표시됩니다. 이러한 각 테이블에 대해 다음을 수행합니다.
- 필수를 선택합니다. 테이블 편집 패널이 표시됩니다.
- 기본 키를 선택합니다. 기본 키는 테이블에 고유한 특성입니다. 특성이 유효한 기본 키가 되려면 중복 값, 누락 된 값 또는 null 값을 포함하지 않아야 합니다. 문자열, 정수 및 GUID 데이터 유형 특성은 기본 키로 지원됩니다.
- 선택적으로 파티션 패턴을 변경합니다.
- 닫기를 선택하여 패널을 저장하고 닫습니다.
포함된 각 테이블의 열 수를 선택합니다. 특성 관리 페이지가 표시됩니다.
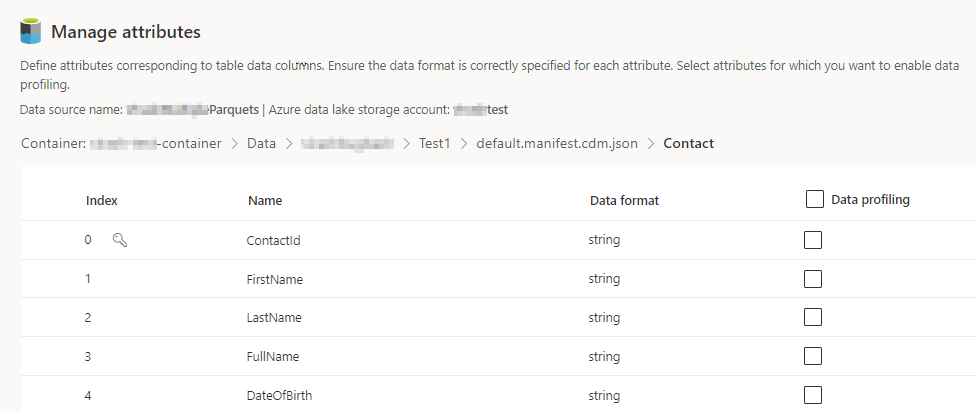
- 새 열을 생성하거나 기존 열을 편집 또는 삭제합니다. 이름, 데이터 형식을 변경하거나 의미 유형을 추가할 수 있습니다.
- 분석 및 기타 기능을 활성화하려면 전체 테이블 또는 특정 열에 대한 데이터 프로파일링을 선택합니다. 기본적으로 데이터 프로파일링에 대해 활성화된 테이블이 없습니다.
- 완료를 선택합니다.
저장을 선택합니다. 데이터 원본 페이지가 열리고 새로 고침 중 상태의 새 데이터 원본이 표시됩니다.

데이터를 로드하는 데 시간이 걸릴 수 있습니다. 새로 고침이 완료되면, 수집된 데이터를 테이블 페이지에서 검토할 수 있습니다.
새 스키마 파일 만들기
스키마 파일 만들기를 선택합니다.
파일의 이름을 입력하고 저장을 선택합니다.
새 테이블을 선택합니다. 새 테이블 패널이 표시됩니다.
테이블 이름을 입력하고 데이터 파일 위치를 선택합니다.
- 여러 .csv 또는 .parquet 파일: 루트 폴더를 찾아 패턴 유형을 선택하고 표현식을 입력합니다.
- 단일 .csv 또는 .parquet 파일: .csv 또는 .parquet 파일을 찾아 선택합니다.
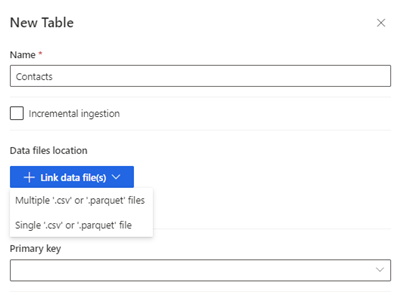
저장을 선택합니다.
특성 정의를 선택하여 특성을 수동으로 추가하거나 자동 생성을 선택합니다. 특성을 정의하려면 이름을 입력하고 데이터 형식 및 선택적 의미 유형을 선택합니다. 자동 생성 특성의 경우:
특성이 자동 생성된 후 특성 검토를 선택합니다. 특성 관리 페이지가 표시됩니다.
데이터 형식이 각 특성에 대해 올바른지 확인합니다.
분석 및 기타 기능을 활성화하려면 전체 테이블 또는 특정 열에 대한 데이터 프로파일링을 선택합니다. 기본적으로 데이터 프로파일링에 대해 활성화된 테이블이 없습니다.
완료를 선택합니다. 테이블 선택 페이지가 표시됩니다.
해당되는 경우 테이블 및 열을 계속 추가합니다.
모든 테이블이 추가된 후 포함을 선택하여 데이터 원본 수집에 테이블을 포함합니다.
기본 키가 정의되지 않은 선택된 테이블의 경우 기본 키 아래에 필수가 표시됩니다. 이러한 각 테이블에 대해 다음을 수행합니다.
- 필수를 선택합니다. 테이블 편집 패널이 표시됩니다.
- 기본 키를 선택합니다. 기본 키는 테이블에 고유한 특성입니다. 특성이 유효한 기본 키가 되려면 중복 값, 누락 된 값 또는 null 값을 포함하지 않아야 합니다. 문자열, 정수 및 GUID 데이터 유형 특성은 기본 키로 지원됩니다.
- 선택적으로 파티션 패턴을 변경합니다.
- 닫기를 선택하여 패널을 저장하고 닫습니다.
저장을 선택합니다. 데이터 원본 페이지가 열리고 새로 고침 중 상태의 새 데이터 원본이 표시됩니다.
데이터를 로드하는 데 시간이 걸릴 수 있습니다. 새로 고침이 완료되면, 수집된 데이터를 데이터>테이블 페이지에서 검토할 수 있습니다.
Azure Data Lake Storage 데이터 원본 편집
다음을 사용하여 스토리지 계정에 연결 옵션을 업데이트할 수 있습니다. 자세한 내용은 Microsoft Entra 서비스 주체를 사용하여 Azure Data Lake Storage 계정에 연결을 참조하세요. 저장소 계정과 다른 컨테이너에 연결하거나 계정 이름을 변경하려면 새로운 데이터 원본 연결을 만듭니다.
데이터>데이터 원본으로 이동. 업데이트하려는 데이터 원본 옆에 있는 편집을 선택합니다.
다음 정보를 변경합니다.
설명
다음을 사용하여 스토리지 연결 및 연결 정보입니다. 연결을 업데이트할 때 컨테이너 정보를 변경할 수 없습니다.
노트
스토리지 계정 또는 컨테이너에 다음 역할 중 하나를 할당해야 합니다.
- 스토리지 Blob 데이터 Reader
- 스토리지 Blob 데이터 담당자
- Storage Blob 데이터 Contributor
Azure Private Link를 통해 스토리지 계정에서 데이터를 수집하려는 경우 프라이빗 링크를 사용하도록 설정합니다. 자세한 내용은 프라이빗 링크를 참고하세요.
다음을 선택합니다.
다음 중 하나를 변경합니다.
컨테이너와 다른 테이블 집합이 있는 다른 model.json 또는 manifest.json 파일로 이동합니다.
수집할 테이블을 추가하려면 새 테이블을 선택합니다.
종속성이 없는 경우 이미 선택한 테이블을 제거하려면 테이블을 선택하고 삭제를 선택합니다.
중요
기존 model.json 또는 manifest.json 파일과 테이블 집합에 대한 종속성이 있는 경우 오류 메시지가 표시되고 다른 model.json 또는 manifest.json 파일을 선택할 수 없습니다. model.json 또는 manifest.json 파일을 변경하기 전에 이러한 종속성을 제거하거나 종속성 제거를 방지하기 위해 사용할 model.json 또는 manifest.json 파일로 새 데이터 원본를 만드십시오.
데이터 파일 위치 또는 기본 키를 변경하려면 편집을 선택합니다.
.json 파일의 테이블 이름과 일치하도록 테이블 이름만 변경하세요.
노트
수집 후 테이블 이름은 항상 model.json 또는 manifest.json 파일의 테이블 이름과 동일하게 유지하세요. Customer Insights - Data는 시스템을 새로 고칠 때마다 model.json 또는 manifest.json을 사용하여 모든 테이블 이름의 유효성을 검사합니다. 테이블 이름이 변경되면 Customer Insights - Data가 .json 파일에서 새 테이블 이름을 찾을 수 없기 때문에 오류가 발생합니다. 수집된 테이블 이름이 실수로 변경된 경우 .json 파일의 이름과 일치하도록 테이블 이름을 편집하세요.
열을 선택하여 추가 또는 변경하거나 데이터 프로파일링을 활성화합니다. 그런 다음 완료를 선택합니다.
저장을 선택하여 변경 사항을 적용하고 데이터 원본 페이지로 돌아갑니다.