Apache Spark용 Azure Synapse Dedicated SQL 풀 커넥터
소개
Azure Synapse Analytics의 Apache Spark용 Azure Synapse 전용 SQL 풀 커넥터는 Apache Spark 런타임과 전용 SQL 풀 간에 대용량 데이터 세트를 효율적으로 전송합니다. 커넥터는 Azure Synapse 작업 영역과 함께 기본 라이브러리로 제공됩니다. 이 커넥터는 Scala 언어를 사용하여 구현됩니다. 커넥터는 Scala 및 Python을 지원합니다. 다른 Notebook 언어 선택 항목과 함께 커넥터를 사용하려면 Spark 매직 명령 %%spark를 사용합니다.
간략하게 보자면, 이 커넥터는 다음과 같은 기능을 제공합니다.
- Azure Synapse Dedicated SQL 풀에서 읽기:
- Synapse Dedicated SQL 풀 테이블(내/외부) 및 뷰에서 대형 데이터 세트를 읽습니다.
- DataFrame의 필터가 해당 SQL 조건자 푸시다운에 매핑되는 포괄적인 조건자 푸시다운을 지원합니다.
- 열 정리를 지원합니다.
- 쿼리 푸시다운을 지원합니다.
- Azure Synapse Dedicated SQL 풀에 쓰기:
- 대량의 데이터를 내부 및 외부 테이블 형식으로 수집합니다.
- 다음과 같은 DataFrame 저장 모드 기본 설정을 지원합니다.
AppendErrorIfExistsIgnoreOverwrite
- 외부 테이블 형식에 쓰기는 Parquet 및 구분된 텍스트 파일 형식(예: CSV)을 지원합니다.
- 내부 테이블에 데이터를 쓰기 위해 커넥터는 이제 CETAS/CTAS 방법 대신 COPY 문을 사용합니다.
- 향상된 기능은 엔드투엔드 쓰기 처리량 성능을 최적화합니다.
- 클라이언트가 사후 쓰기 메트릭을 받는 데 사용할 수 있는 선택적 콜백 핸들(Scala 함수 인수)을 도입합니다.
- 몇 가지 예에는 레코드 수, 특정 작업을 완료하는 데 걸리는 시간 및 실패 이유가 있습니다.
오케스트레이션 접근 방식
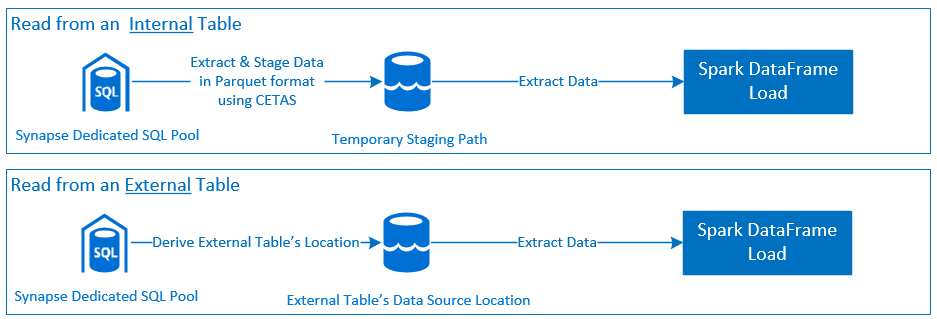
읽기
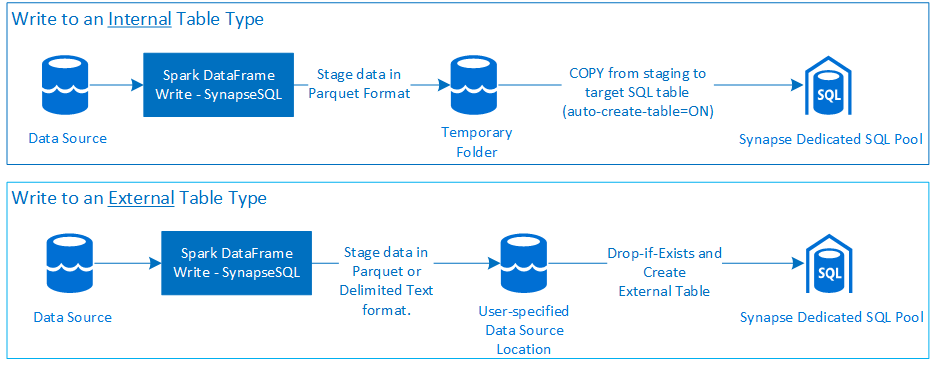
쓰기
필수 조건
필수 Azure 리소스 설정과 같은 필수 구성 요소 및 구성 단계는 이 섹션에서 설명합니다.
Azure 리소스
다음 종속 Azure 리소스를 검토하고 설정합니다.
- Azure Data Lake Storage - Azure Synapse 작업 영역의 기본 스토리지 계정으로 사용됩니다.
- Azure Synapse 작업 영역 - Notebook을 만들고, DataFrame 기반 수신-송신 워크플로를 빌드하여 배포합니다.
- 전용 SQL 풀(이전의 SQL DW) - 엔터프라이즈 데이터 웨어하우징 기능을 제공합니다.
- Azure Synapse 서버리스 Spark 풀 - 작업이 Spark 애플리케이션으로 실행되는 Spark 런타임입니다.
데이터베이스 준비
Synapse Dedicated SQL 풀 데이터베이스에 연결하고 다음 설정 명령문을 실행합니다.
Azure Synapse 작업 영역에 로그인하는 데 사용되는 Microsoft Entra 사용자 ID에 매핑되는 데이터베이스 사용자를 만듭니다.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;커넥터가 각 테이블에 성공적으로 데이터를 쓰고 읽을 수 있도록 테이블을 정의할 스키마를 만듭니다.
CREATE SCHEMA [<schema_name>];
인증
Microsoft Entra ID 기반 인증
Microsoft Entra ID 기반 인증은 통합 인증 방식입니다. 사용자는 Azure Synapse Analytics 작업 영역에 성공적으로 로그인해야 합니다.
기본 인증
기본 인증 방법을 사용하려면 사용자가 username 및 password 옵션을 구성해야 합니다. Azure Synapse 전용 SQL 풀에서 테이블을 읽고 쓰기 위한 관련 구성 매개 변수에 대해 알아보려면 구성 옵션 섹션을 참조하세요.
Authorization
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 - 스토리지 계정에 액세스 권한을 부여하는 두 가지 방법이 있습니다.
- 역할 기반 액세스 제어 역할 - Storage Blob 데이터 기여자 역할
- 권한을 할당하면
Storage Blob Data Contributor RoleAzure Storage Blob 컨테이너에서 읽고 쓰고 삭제할 수 있는 사용자 권한이 부여됩니다. - RBAC는 컨테이너 수준에서 거친 제어 접근 방식을 제공합니다.
- 권한을 할당하면
-
ACL(액세스 제어 목록)
- ACL 접근 방식을 사용하면 지정된 폴더 아래의 특정 경로 및/또는 파일을 세밀하게 제어할 수 있습니다.
- RBAC 접근 방식을 사용하여 사용자에게 이미 권한이 부여된 경우 ACL 검사가 적용되지 않습니다.
- 다음과 같은 두 가지 유형의 ACL 권한이 있습니다.
- 액세스 권한(특정 수준 또는 개체에 적용됨)
- 기본 권한(자식 개체를 만들 때 모든 자식 개체에 자동으로 적용됨)
- 권한의 유형은 다음과 같습니다.
-
Execute는 폴더 계층을 트래버스하거나 탐색할 수 있습니다. -
Read는 읽을 수 있습니다. -
Write는 쓸 수 있습니다.
-
- 커넥터가 스토리지 위치에서 쓰고 읽을 수 있도록 ACL을 구성하는 것이 중요합니다.
참고 항목
Synapse 작업 영역 파이프라인을 사용하여 Notebooks를 실행하려면 Synapse 작업 영역 기본 관리 ID에 대해 위에 나열된 액세스 권한도 부여해야 합니다. 작업 영역의 기본 관리 ID 이름은 작업 영역의 이름과 동일합니다.
보안 스토리지 계정과 함께 Synapse 작업 영역을 사용하려면 관리 프라이빗 엔드포인트를 Notebook에서 구성해야 합니다. 관리 프라이빗 엔드포인트는
Networking창에 있는 ADLS Gen2 스토리지 계정의Private endpoint connections섹션에서 승인되어야 합니다.
Azure Synapse Dedicated SQL 풀
Azure Synapse 전용 SQL Pool과의 성공적인 상호 작용을 활성화하려면 전용 SQL 엔드포인트에서 Active Directory Admin으로 구성된 사용자가 아닌 한 다음 권한 부여가 필요합니다.
읽기 시나리오
시스템 저장 프로시저
sp_addrolemember를 사용하여 사용자에게db_exporter권한을 부여합니다.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
쓰기 시나리오
- 커넥터는 COPY 명령을 사용하여 스테이징의 데이터를 내부 테이블의 관리되는 위치에 씁니다.
여기에 설명된 필수 권한을 구성합니다.
다음은 동일한 빠른 액세스 코드 조각입니다.
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- 커넥터는 COPY 명령을 사용하여 스테이징의 데이터를 내부 테이블의 관리되는 위치에 씁니다.
API 설명서
Apache Spark용 Azure Synapse Dedicated SQL 풀 커넥터 - API 설명서.
구성 옵션
읽기 또는 쓰기 작업을 성공적으로 부트스트랩하고 오케스트레이션하려면 커넥터에 특정 구성 매개 변수가 필요합니다. 개체 정의 - com.microsoft.spark.sqlanalytics.utils.Constants는 각 매개 변수 키에 대해 표준화된 상수 목록을 제공합니다.
다음은 사용 시나리오에 따른 구성 옵션 목록입니다.
-
Microsoft Entra ID 기반 인증을 사용하여 읽기
- 자격 증명은 자동 매핑되며 사용자는 특정 구성 옵션을 제공할 필요가 없습니다.
-
synapsesql메서드에 대한 세 부분으로 된 테이블 이름 인수는 Azure Synapse 전용 SQL 풀의 해당 테이블에서 읽어야 합니다.
-
기본 인증을 사용하여 읽기
- Azure Synapse 전용 SQL 엔드포인트
-
Constants.SERVER- Synapse 전용 SQL 풀 엔드포인트(서버 FQDN) -
Constants.USER- SQL 사용자 이름입니다. -
Constants.PASSWORD- SQL 사용자 암호입니다.
-
- Azure Data Lake Storage(Gen2) 엔드포인트 - 준비 폴더
-
Constants.DATA_SOURCE- 데이터 원본 위치 매개 변수에 설정된 스토리지 경로는 데이터 스테이징에 사용됩니다.
-
- Azure Synapse 전용 SQL 엔드포인트
-
Microsoft Entra ID 기반 인증을 사용하여 쓰기
- Azure Synapse 전용 SQL 엔드포인트
- 기본적으로 커넥터는
synapsesql메서드의 세 부분으로 구성된 테이블 이름 매개 변수에 설정된 데이터베이스 이름을 사용하여 Synapse 전용 SQL 엔드포인트를 유추합니다. - 또는 사용자는
Constants.SERVER옵션을 사용하여 sql 엔드포인트를 지정할 수 있습니다. 엔드포인트가 해당 스키마로 해당 데이터베이스를 호스팅하는지 확인합니다.
- 기본적으로 커넥터는
- Azure Data Lake Storage(Gen2) 엔드포인트 - 준비 폴더
- 내부 테이블 형식의 경우:
-
Constants.TEMP_FOLDER또는Constants.DATA_SOURCE옵션을 구성합니다. - 사용자가
Constants.DATA_SOURCE옵션을 제공하도록 선택한 경우 DataSource의location값을 사용하여 준비 폴더가 파생됩니다. - 둘 다 제공되면
Constants.TEMP_FOLDER옵션 값이 사용됩니다. - 준비 폴더 옵션이 없는 경우 커넥터는 런타임 구성(
spark.sqlanalyticsconnector.stagingdir.prefix)을 기반으로 합니다.
-
- 외부 테이블 형식의 경우:
-
Constants.DATA_SOURCE는 필요한 구성 옵션입니다. - 커넥터는
synapsesql메서드에 대한location인수와 함께 데이터 원본의 위치 매개 변수에 설정된 스토리지 경로를 사용하고 외부 테이블 데이터를 유지하기 위한 절대 경로를 파생합니다. -
synapsesql메서드에 대한location인수가 지정되지 않은 경우 커넥터는 위치 값을<base_path>/dbName/schemaName/tableName으로 파생합니다.
-
- 내부 테이블 형식의 경우:
- Azure Synapse 전용 SQL 엔드포인트
-
기본 인증을 사용하여 쓰기
- Azure Synapse 전용 SQL 엔드포인트
-
Constants.SERVER- - Synapse 전용 SQL 풀 엔드포인트(서버 FQDN). -
Constants.USER- SQL 사용자 이름입니다. -
Constants.PASSWORD- SQL 사용자 암호입니다. -
Constants.TEMP_FOLDERS(내부 테이블 형식만 해당) 또는Constants.DATA_SOURCE를 호스팅하는 스토리지 계정과 연결된Constants.STAGING_STORAGE_ACCOUNT_KEY.
-
- Azure Data Lake Storage(Gen2) 엔드포인트 - 준비 폴더
- SQL 기본 인증 자격 증명은 스토리지 엔드포인트에 액세스하는 데 적용되지 않습니다.
- 따라서 Azure Data Lake Storage Gen2 섹션에 설명된 대로 관련 스토리지 액세스 권한을 할당해야 합니다.
- Azure Synapse 전용 SQL 엔드포인트
코드 템플릿
이 섹션에서는 Apache Spark용 Azure Synapse Dedicated SQL 풀 커넥터를 사용하고 호출하는 방법을 설명하는 참조 코드 템플릿을 제공합니다.
참고 항목
Python에서 커넥터 사용-
- 커넥터는 Spark 3용 Python에서만 지원됩니다. Spark 2.4(지원되지 않음)의 경우 Scala 커넥터 API를 사용하여 DataFrame.createOrReplaceTempView 또는 DataFrame.createOrReplaceGlobalTempView를 사용하여 PySpark의 DataFrame에서 콘텐츠와 상호 작용할 수 있습니다. 섹션 - 셀 전체에서 구체화된 데이터 사용을 참조하세요.
- 콜백 핸들은 Python에서 사용할 수 없습니다.
Azure Synapse 전용 SQL 풀에서 읽기
읽기 요청 - synapsesql 메서드 서명
Microsoft Entra ID 기반 인증을 사용하여 테이블에서 읽기
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Microsoft Entra ID 기반 인증을 사용하여 쿼리에서 읽기
참고 항목
쿼리에서 읽는 동안의 제한 사항은 다음과 같습니다.
- 테이블 이름과 쿼리는 동시에 지정할 수 없습니다.
- 선택 쿼리만 허용됩니다. DDL 및 DML SQL은 허용되지 않습니다.
- 데이터 프레임의 선택 및 필터 옵션은 쿼리를 지정할 때 SQL 전용 풀로 푸시다운되지 않습니다.
- 쿼리에서 읽기는 Spark 3에서만 사용할 수 있습니다.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
기본 인증을 사용하여 테이블에서 읽기
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
기본 인증을 사용하여 쿼리에서 읽기
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Azure Synapse 전용 SQL 풀에 쓰기
쓰기 요청 - synapsesql 메서드 서명
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Microsoft Entra ID 기반 인증을 사용하여 쓰기
다음은 쓰기 시나리오에 커넥터를 사용하는 방법을 설명하는 포괄적인 코드 템플릿입니다.
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
기본 인증을 사용하여 쓰기
다음 코드 조각은 Microsoft Entra ID 기반 인증을 사용하여 쓰기 섹션에 설명된 쓰기 정의를 바꿔 SQL 기본 인증 방식을 사용하여 쓰기 요청을 제출합니다.
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
기본 인증 방법에서는 원본 스토리지 경로에서 데이터를 읽으려면 다른 구성 옵션이 필요합니다. 다음 코드 조각은 서비스 주체 자격 증명을 사용하여 Azure Data Lake Storage Gen2 데이터 원본에서 읽는 예제를 제공합니다.
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
지원되는 DataFrame 저장 모드
다음 SaveModes는 Azure Synapse 전용 SQL 풀의 대상 테이블에 원본 데이터를 쓸 때 지원됩니다.
- ErrorIfExists(기본 저장 모드)
- 대상 테이블이 있으면 쓰기가 중단되고 호출 수신자에게 예외가 반환됩니다. 대상 테이블이 없으면 스테이징 폴더의 데이터를 사용하여 새 테이블이 만들어집니다.
- 무시
- 대상 테이블이 있으면 쓰기에서 쓰기 요청을 무시하고 오류는 반환되지 않습니다. 대상 테이블이 없으면 스테이징 폴더의 데이터를 사용하여 새 테이블이 만들어집니다.
- Overwrite
- 대상 테이블이 있으면 대상의 기존 데이터가 스테이징 폴더의 데이터로 바뀝니다. 대상 테이블이 없으면 스테이징 폴더의 데이터를 사용하여 새 테이블이 만들어집니다.
- 추가
- 대상 테이블이 있으면 새 데이터가 대상 테이블에 적용됩니다. 대상 테이블이 없으면 스테이징 폴더의 데이터를 사용하여 새 테이블이 만들어집니다.
쓰기 요청 콜백 핸들
쓰기 경로 API가 변경되면서 클라이언트에 사후 쓰기 메트릭의 키->값 맵을 제공하는 실험적 기능이 도입되었습니다. 메트릭에 대한 키는 새 개체 정의 Constants.FeedbackConstants에 정의됩니다. 메트릭은 콜백 핸들(Scala Function)을 전달하여 JSON 문자열로 검색할 수 있습니다. 다음은 함수 시그니처입니다.
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
다음은 몇 가지 주목할만한 메트릭입니다(카멜 사례로 표시됨).
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
다음은 사후 쓰기 메트릭이 있는 샘플 JSON 문자열입니다.
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
더 많은 코드 샘플
셀 전체에서 구체화된 데이터 사용
Spark DataFrame의 createOrReplaceTempView는 임시 보기를 등록하여 다른 셀에서 가져온 데이터에 액세스하는 데 사용할 수 있습니다.
- 데이터가 페치되는 셀(Notebook 언어 선택이
Scala인 경우)입니다.
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- 이제 Notebook의 언어 선택을
PySpark (Python)으로 변경하고 등록된 보기<temporary_view_name>에서 데이터를 가져옵니다.
spark.sql("select * from <temporary_view_name>").show()
응답 처리
synapsesql 호출에는 성공 또는 실패 상태의 두 가지 가능한 종료 상태가 있습니다. 이 섹션에서는 각 시나리오에 대한 요청 응답을 처리하는 방법을 설명합니다.
읽기 요청 응답
완료되면 읽기 응답 코드 조각이 셀의 출력에 표시됩니다. 현재 셀에서 오류가 발생하면 후속 셀 실행도 취소됩니다. 자세한 오류 정보는 Spark 애플리케이션 로그에서 사용할 수 있습니다.
쓰기 요청 응답
기본적으로 쓰기 응답은 셀 출력에 인쇄됩니다. 실패 시 현재 셀이 실패한 것으로 표시되고 후속 셀 실행이 중단됩니다. 다른 방법은 콜백 핸들 옵션을 synapsesql 메서드에 전달하는 것입니다. 콜백 핸들은 쓰기 응답에 대한 프로그래밍 방식의 액세스를 제공합니다.
기타 고려 사항
- Azure Synapse 전용 SQL 풀 테이블에서 읽을 때:
- 커넥터의 열 정리 기능을 활용하려면 DataFrame에 필요한 필터를 적용하는 것이 좋습니다.
- 읽기 시나리오는
SELECT쿼리 문을 프레이밍할 때TOP(n-rows)절을 지원하지 않습니다. 데이터를 제한하는 방법은 DataFrame의 limit(.) 절을 사용하는 것입니다.- 예 - 셀 전체에서 구체화된 데이터 사용 섹션을 참조하세요.
- Azure Synapse 전용 SQL 풀 테이블에 쓸 때:
- 내부 테이블 형식의 경우 다음과 같습니다.
- 테이블은 ROUND_ROBIN 데이터 배포를 사용하여 만들어집니다.
- 열 형식은 원본에서 데이터를 읽는 DataFrame에서 유추됩니다. 문자열 열은
NVARCHAR(4000)에 매핑됩니다.
- 외부 테이블 형식의 경우 다음과 같습니다.
- DataFrame의 초기 병렬 처리는 외부 테이블에 대한 데이터 조직을 구동합니다.
- 열 형식은 원본에서 데이터를 읽는 DataFrame에서 유추됩니다.
- 실행기 간에 더 나은 데이터 분산은
spark.sql.files.maxPartitionBytes및 DataFrame의repartition매개 변수를 튜닝하여 달성할 수 있습니다. - 대용량 데이터 집합을 작성할 때는 트랜잭션 크기를 제한하는 DWU 성능 수준 설정의 영향을 고려하는 것이 중요합니다.
- 내부 테이블 형식의 경우 다음과 같습니다.
- Azure Data Lake Storage Gen2 사용률 추세를 모니터링하여 읽기 및 쓰기 성능에 영향을 줄 수 있는 제한 동작을 파악합니다.