빠른 시작: Synapse 작업 영역 만들기
이 빠른 시작에서는 Synapse 작업 영역을 만들고 나머지 자습서에 따라 전용 SQL 풀과 서버리스 Apache Spark 풀을 만들 수 있습니다.
필수 조건
- Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- 이 자습서의 단계를 완료하려면 소유자 역할이 할당된 리소스 그룹에 대한 액세스 권한이 있어야 합니다. 이 리소스 그룹에 Synapse 작업 영역을 만듭니다.
Azure Portal에서 Synapse 작업 영역 만들기
프로세스 시작
- Azure Portal을 열고 검색 창에서 enter 키를 누르지 않고 Synapse를 입력합니다.
- 서비스 아래의 검색 결과에서 Azure Synapse Analytics를 선택합니다.
- 만들기를 선택하여 작업 영역을 만듭니다.
기본 사항 탭 > 프로젝트 세부 정보
다음 필드를 작성합니다.
- 구독 - 구독을 선택합니다.
- 리소스 그룹 - 리소스 그룹을 사용합니다.
- 관리되는 리소스 그룹 - 비워 둡니다.
기본 사항 탭 > 작업 영역 세부 정보
다음 필드를 작성합니다.
- 작업 영역 이름 - 전역적으로 고유한 이름을 선택합니다. 이 자습서에서는 myworkspace를 사용합니다.
- 지역 - 클라이언트 애플리케이션/서비스(예: Azure Virtual Machine, Power BI, Azure Analysis Service)와 데이터가 포함된 스토리지(예: Azure Data Lake 스토리지, Azure Cosmos DB 분석 스토리지)를 배치한 지역을 선택합니다.
참고 항목
클라이언트 애플리케이션 또는 스토리지와 공동 배치되지 않는 작업 영역은 많은 성능 문제의 근본 원인이 될 수 있습니다. 데이터 또는 클라이언트를 여러 지역에 배치하는 경우 데이터와 클라이언트가 공동 배치된 다른 지역에 별도의 작업 영역을 만들 수 있습니다.
Data Lake Storage Gen 2 선택 아래에서:
계정 이름별로 새로 만들기를 선택하고 새 스토리지 계정의 이름을 contosolake로 지정하고, 이 이름은 고유해야 합니다.
팁
"Azure Synapse 리소스 공급자(Microsoft.Synapse)를 선택한 구독에 등록해야 함"이라는 오류가 발생하면 Azure Portal을 열고 구독을 선택합니다. 구독을 선택합니다. 설정 목록에서 리소스 공급자를 선택합니다. Microsoft.Synapse를 검색하여 선택한 다음 등록을 선택합니다.
파일 시스템 이름별로 새로 만들기를 선택하고 사용자 이름을 지정합니다. 이렇게 하면 users라는 스토리지 컨테이너가 생성됩니다. 작업 영역에서는 이 스토리지 계정을 Spark 테이블 및 Spark 애플리케이션 로그에 대한 "기본" 스토리지 계정으로 사용합니다.
Data Lake Storage Gen2 계정에 Storage Blob 데이터 기여자 역할 할당 상자를 선택합니다.
프로세스 완료
검토 + 만들기>만들기를 차례로 선택합니다. 몇 분 안에 작업 영역이 준비됩니다.
참고 항목
기존 전용 SQL 풀(이전의 SQL DW)에서 작업 영역 기능을 사용하도록 설정하려면 전용 SQL 풀(이전의 SQL DW)에 작업 영역을 사용하도록 설정하는 방법을 참조하세요.
Synapse Studio 열기
Azure Synapse 작업 영역이 만들어지면 다음 두 가지 방법으로 Synapse Studio를 열 수 있습니다.
Azure Portal에서 Synapse 작업 영역을 열고, Synapse 작업 영역의 개요 섹션에 있는 Synapse Studio 열기 상자에서 열기를 선택합니다.
https://web.azuresynapse.net(으)로 이동하여 작업 영역에 로그인합니다.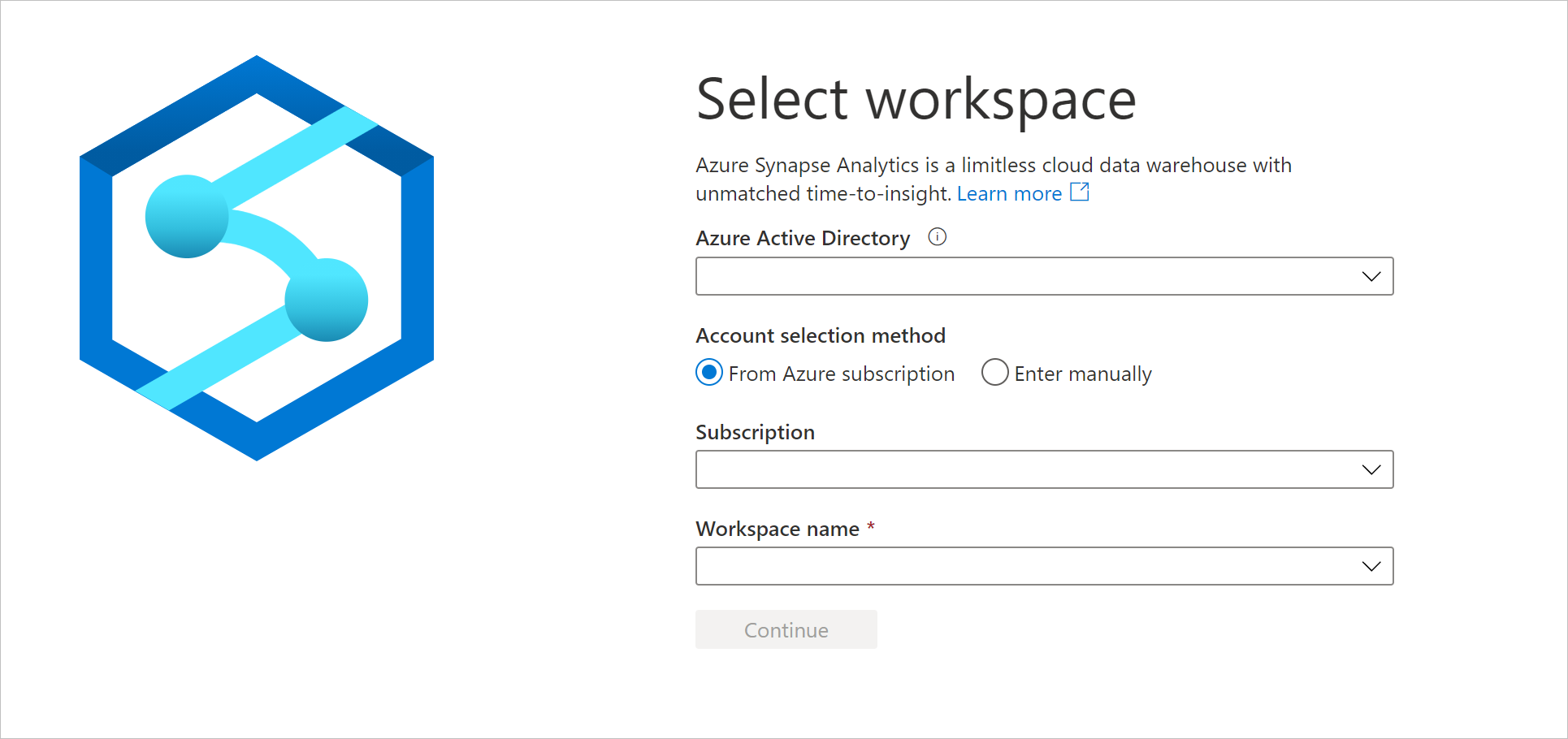
참고 항목
작업 영역에 로그인하기 위한 두 가지 계정 선택 방법이 있습니다. 하나는 Azure 구독에서 가져온 것이고 다른 하나는 수동으로 입력에서 가져온 것입니다. Synapse Azure 역할 또는 더 높은 수준의 Azure 역할이 있는 경우 두 가지 방법을 모두 사용하여 작업 영역에 로그인할 수 있습니다. 관련 Azure 역할이 없고 Synapse RBAC 역할로 부여된 경우 수동으로 입력이 작업 영역에 로그인하는 유일한 방법입니다. Synapse RBAC에 대한 자세한 내용은 Synapse RBAC(역할 기반 액세스 제어)란?을 참조합니다.
기본 스토리지 계정에 샘플 데이터 배치
이 시작 가이드의 많은 예제에 대해 NYC Taxi Cab 데이터의 작은 10만 행 샘플 데이터 세트를 사용할 것입니다. 작업 영역에 대해 만든 기본 스토리지 계정에 배치하여 시작합니다.
- NYC Taxi - 녹색 여행 데이터 세트를 컴퓨터에 다운로드합니다.
- 링크에서 원래 데이터 세트 위치로 이동하여 특정 연도를 선택하고 Parquet 형식의 녹색 택시 여행 레코드를 다운로드합니다.
- 다운로드한 파일의 이름을 NYCTripSmall.parquet으로 바꿉니다.
- Synapse Studio에서 데이터 허브로 이동합니다.
- 연결됨을 선택합니다.
- Azure Data Lake Storage Gen2 범주 아래에 myworkspace(기본 - contosolake)와 같은 이름의 항목이 표시됩니다.
- 사용자(기본)라는 컨테이너를 선택합니다.
- 업로드를 선택하고 다운로드한
NYCTripSmall.parquet파일을 선택합니다.
parquet 파일이 업로드되면 두 개의 동등한 URI를 통해 사용할 수 있습니다.
https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquetabfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet
팁
이 자습서의 뒷부분에 나오는 예제에서는 UI의 contosolake를 작업 영역에 대해 선택한 기본 스토리지 계정의 이름으로 바꾸어야 합니다.