자습서: Azure AI 서비스를 사용한 Text Analytics
이 자습서에서는 Text Analytics를 사용하여 Azure Synapse Analytics 에서 구조화되지 않은 텍스트를 분석하는 방법을 알아봅니다. Text Analytics은 NLP(자연어 처리) 기능을 사용하여 텍스트 마이닝 및 Text Analytics를 수행할 수 있게 해주는 Azure AI 서비스입니다.
이 자습서에서는 SynapseML에서 Text Analytics를 사용하여 다음을 수행하는 방법을 보여 줍니다.
- 문장 또는 문서 수준의 감정 레이블 검색
- 지정된 텍스트 입력에 대한 언어 식별
- 잘 알려진 기술 자료 링크가 있는 텍스트에서 엔터티 인식
- 텍스트에서 핵심 구 추출
- 텍스트에서 다른 엔터티를 식별하고 미리 정의된 클래스 또는 형식으로 분류
- 지정된 텍스트에서 중요한 엔터티 식별 및 수정
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
- Azure Synapse Analytics 작업 영역(기본 스토리지로 구성된 Azure Data Lake Storage Gen2 스토리지 계정이 있음). 사용하는 Data Lake Storage Gen2 파일 시스템의 Storage Blob 데이터 기여자여야 합니다.
- Azure Synapse Analytics 작업 영역의 Spark 풀 자세한 내용은 Azure Synapse에서 Spark 풀 만들기를 참조하세요.
- 자습서 에 설명된 사전 구성 단계는 Azure Synapse에서 Azure AI 서비스 구성입니다.
시작하기
Synapse Studio를 열고 새 Notebook을 만듭니다. 시작하려면 SynapseML을 가져옵니다.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
텍스트 분석 구성
미리 구성 단계에서 구성한 연결된 텍스트 분석을 사용합니다.
linked_service_name = "<Your linked service for text analytics>"
텍스트 감정
텍스트 감정 분석은 문장 및 문서 수준에서 감정 레이블(예: "부정", "중립" 및 "긍정")과 신뢰도 점수를 검색하는 방법을 제공합니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
예상 결과
| text | 감정 |
|---|---|
| 나는 오늘 너무 행복해요, 그것은 화창한입니다! | 긍정 |
| 나는이 혼잡 한 시간 트래픽에 의해 좌절 | 부정 |
| Spark의 Azure AI 서비스는 나쁘지 않음 | 중립 |
언어 감지기
언어 감지기는 각 문서에 대해 텍스트 입력을 평가하고, 분석 강도를 나타내는 점수가 있는 언어 식별자를 반환합니다. 이 기능은 알 수 없는 언어로 된 임의의 텍스트를 수집하는 콘텐츠 저장소에 유용합니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
예상 결과
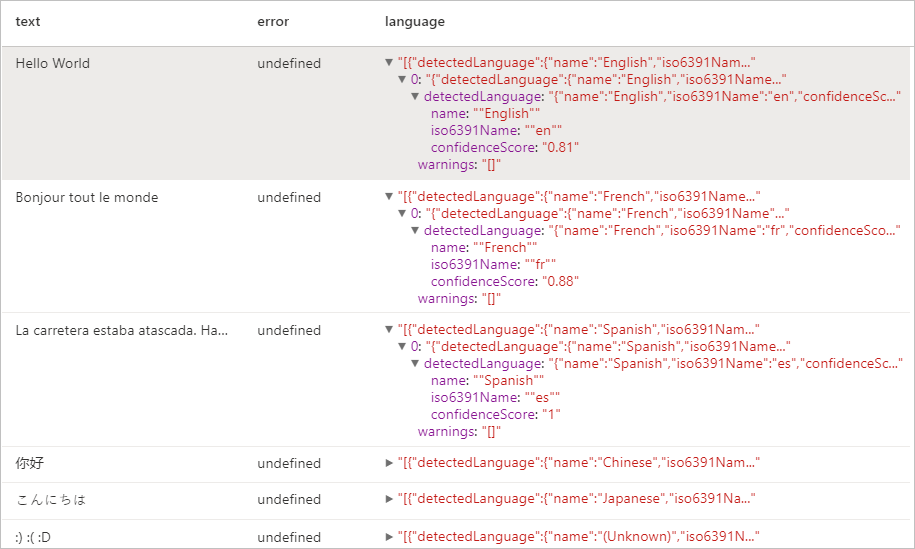
엔터티 감지기
엔터티 감지기는 잘 알려진 기술 자료에 대한 링크가 있는 인식된 엔터티 목록을 반환합니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
예상 결과
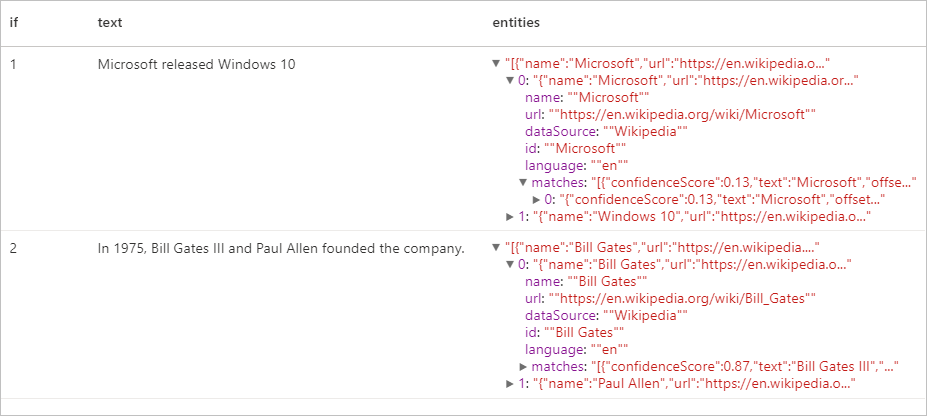
핵심 구 추출기
핵심 구 추출은 구조화되지 않은 텍스트를 평가하고 핵심 구 목록을 반환합니다. 이 기능은 문서 컬렉션에서 주요 지점을 빠르게 식별해야 하는 경우에 유용합니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
예상 결과
| text | keyPhrases |
|---|---|
| Hello world. 이는 제가 선호하는 입력 텍스트입니다. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
NER(명명된 엔터티 인식)
NER(명명된 엔터티 인식)은 텍스트에서 다양한 엔터티를 식별하고 이를 사용자, 위치, 이벤트, 제품, 조직 등의 미리 정의된 클래스 또는 형식으로 분류하는 기능입니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
예상 결과
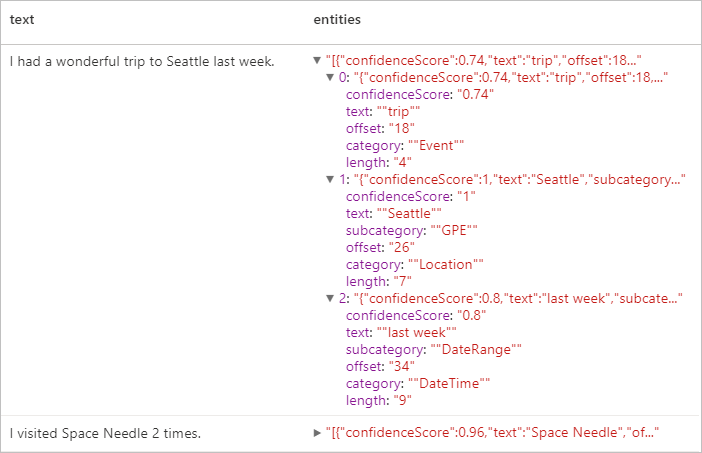
PII(개인 식별 정보) V3.1
PII 기능은 NER의 일부이며 전화 번호, 이메일 주소, 우편 주소, 여권 번호 등의 개별 사용자와 연결된 텍스트에서 중요한 엔터티를 식별하고 교정할 수 있습니다. 사용 가능한 언어 목록은 Text Analytics API에서 지원되는 언어를 참조하세요.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
예상 결과
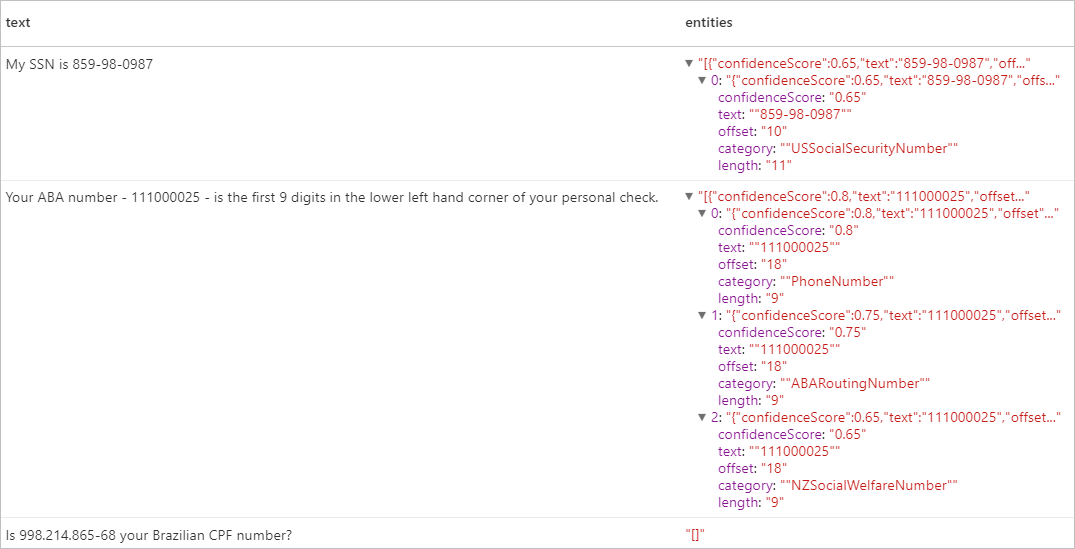
리소스 정리
Spark 인스턴스가 종료되도록 하려면 연결된 세션(Notebook)을 종료합니다. Apache Spark 풀에 지정된 유휴 시간에 도달하면 풀이 종료됩니다. Notebook 오른쪽 상단에 있는 상태 표시줄에서 세션 중지를 선택할 수도 있습니다.
