Azure Stream Analytics 사용자 지정 Blob 출력 분할
Azure Stream Analytics는 사용자 지정 필드 또는 특성 및 DateTime 사용자 지정 경로 패턴을 사용하여 사용자 지정 Blob 출력 분할을 지원합니다.
사용자 지정 필드 또는 특성
사용자 지정 필드 또는 입력 특성은 출력을 더 많이 제어하도록 허용하여 다운스트림 데이터 처리 및 보고 워크플로를 개선합니다.
파티션 키 옵션
입력 데이터를 분할하는 데 사용되는 파티션 키 또는 열 이름에는 Blob 이름에 허용되는 문자가 포함될 수 있습니다. 별칭과 함께 사용되지 않는 한 중첩 필드를 파티션 키로 사용할 수 없습니다. 그러나 특정 문자를 사용하여 파일 계층 구조를 만들 수 있습니다. 예를 들어 다른 두 열의 데이터를 결합하여 고유한 파티션 키를 만드는 열을 만들려면 다음 쿼리를 사용할 수 있습니다.
SELECT name, id, CONCAT(name, "/", id) AS nameid
파티션 키는 ( 또는 BIGINTFLOATBIT 1.2 호환성 수준 이상)이어야 합니다.NVARCHAR(MAX) , Array및 Records 형식은 DateTime지원되지 않지만 문자열로 변환되는 경우 파티션 키로 사용할 수 있습니다. 자세한 내용은 Azure Stream Analytics 데이터 형식을 참조 하세요.
예시
수집된 데이터에 세션을 식별하는 열 client_id 이 포함된 외부 비디오 게임 서비스에 연결된 라이브 사용자 세션에서 입력 데이터를 사용하는 작업이 있다고 가정합니다. 데이터를 분할하려면 client_id작업을 만들 때 Blob 출력 속성에 파티션 토큰 {client_id} 을 포함하도록 Blob 경로 패턴 필드를 설정합니다. 다양한 client_id 값이 있는 데이터가 Stream Analytics 작업을 통해 흐르면 출력 데이터는 폴더당 단일 client_id 값을 기반으로 별도의 폴더에 저장됩니다.

마찬가지로, 작업 입력이 각 센서가 있는 수백만 개의 센서의 센서 sensor_id데이터인 경우 경로 패턴은 {sensor_id} 각 센서 데이터를 다른 폴더로 분할하는 것입니다.
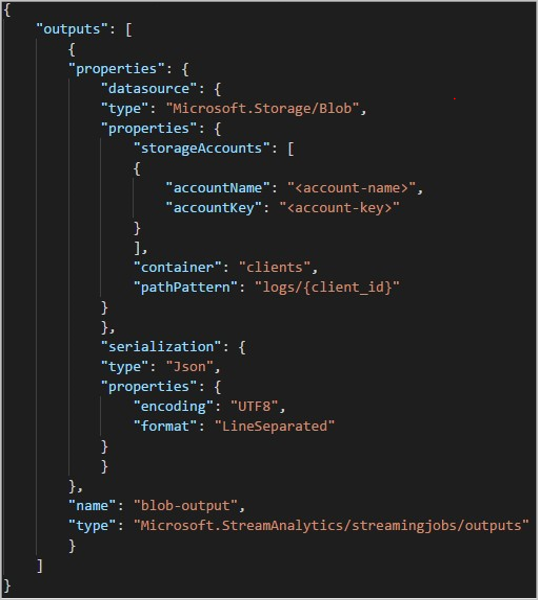
REST API를 사용하는 경우 해당 요청에 사용되는 JSON 파일의 출력 섹션은 다음 이미지와 같을 수 있습니다.
작업이 실행되고 나면 컨테이너는 clients 다음 이미지와 같이 표시될 수 있습니다.
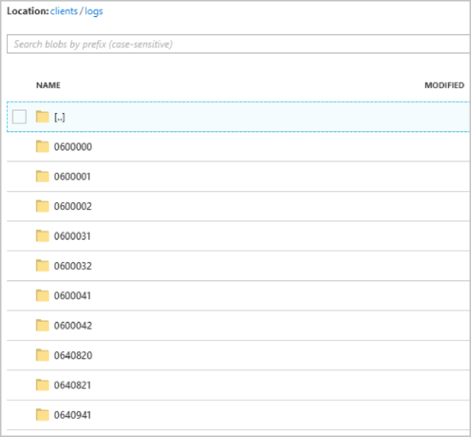
각 폴더에는 각 Blob에 하나 이상의 레코드가 포함된 여러 Blob이 포함될 수 있습니다. 앞의 예제에서는 다음 내용으로 레이블이 지정된 "06000000" 폴더에 단일 Blob이 있습니다.
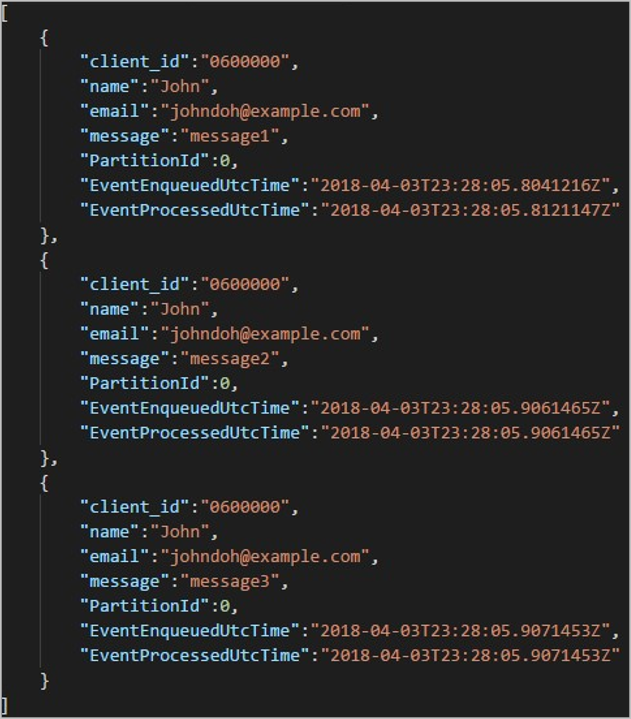
출력 경로의 출력을 분할하는 데 사용된 열이 client_id 있었기 때문에 Blob의 각 레코드에는 폴더 이름과 일치하는 열이 있습니다 client_id.
제한 사항
경로 패턴 Blob 출력 속성에는 하나의 사용자 지정 파티션 키만 허용됩니다. 다음 경로 패턴은 모두 유효합니다.
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
고객이 둘 이상의 입력 필드를 사용하려는 경우 Blob 출력
CONCAT에서 사용자 지정 경로 파티션에 대한 쿼리에서 복합 키를 만들 수 있습니다. 예제는select concat (col1, col2) as compositeColumn into blobOutput from input입니다. 그런 다음 Azure Blob Storage에서 사용자 지정 경로로 지정할compositeColumn수 있습니다.파티션 키는 대/소문자를 구분하지 않으므로
John및john과 같은 파티션 키는 동등합니다. 또한 식을 파티션 키로 사용할 수 없습니다. 예를 들어 작동하지{columnA + columnB}않습니다.입력 스트림이 파티션 키 카디널리티가 8,000 미만인 레코드로 구성되면 레코드가 기존 Blob에 추가됩니다. 필요한 경우에만 새 Blob을 만듭니다. 카디널리티가 8,000개를 초과하면 기존 Blob이 기록될 것이라는 보장은 없습니다. 동일한 파티션 키를 사용하는 임의 수의 레코드에 대해 새 Blob이 만들어지지 않습니다.
blob 출력이 변경 불가능으로 구성된 경우 Stream Analytics는 데이터가 전송될 때마다 새 blob을 만듭니다.
사용자 지정 날짜/시간 경로 패턴
사용자 지정 DateTime 경로 패턴을 사용하면 Hive 스트리밍 규칙에 맞는 출력 형식을 지정할 수 있으므로 Stream Analytics는 다운스트림 처리를 위해 Azure HDInsight 및 Azure Databricks로 데이터를 보낼 수 있습니다. 사용자 지정 DateTime 경로 패턴은 형식 지정자와 함께 Blob 출력의 경로 접두사 필드에서 키워드를 사용하여 datetime 쉽게 구현할 수 있습니다. 예제는 {datetime:yyyy}입니다.
지원되는 토큰
다음 형식 지정자 토큰은 사용자 지정 DateTime 형식을 구현하기 위해 단독으로 또는 함께 사용할 수 있습니다.
| 형식 지정자 | 설명 | 예제 시간 2018-01-02T10:06:08에 대한 결과 |
|---|---|---|
| {datetime:yyyy} | 연도(4자리 숫자) | 2018 |
| {datetime:MM} | 월(01-12) | 01 |
| {datetime:M} | 월(1-12) | 1 |
| {datetime:dd} | 일(01-31) | 02 |
| {datetime:d} | 일(1-31) | 2 |
| {datetime:HH} | 시간(00-23의 24시간 형식) | 10 |
| {datetime:mm} | 분(00-60) | 06 |
| {datetime:m} | 분(0-60) | 6 |
| {datetime:ss} | 초(00-60) | 08 |
사용자 지정 DateTime 패턴을 사용하지 않으려면 경로 접두사 필드에 토큰을 {time} 추가하여 {date} 기본 제공 DateTime 형식으로 드롭다운을 생성할 수 있습니다.
확장성 및 제한 사항
경로 접두사 문자 제한에 도달할 때까지 경로 패턴에서 원하는 만큼 토큰({datetime:<specifier>})을 사용할 수 있습니다. 서식 지정자는 날짜 및 시간 드롭다운 목록에서 이미 나열된 조합 이외의 단일 토큰 내에서 결합할 수 없습니다.
logs/MM/dd 경로 파티션의 경우:
| 유효한 식 | 잘못된 식 |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
경로 접두사에서 동일한 형식 지정자를 여러 번 사용할 수 있습니다. 토큰은 매번 반복되어야 합니다.
Hive 스트리밍 규칙
Blob Storage에 대한 사용자 지정 경로 패턴은 폴더 이름에 레이블이 지정되어야 하는 Hive 스트리밍 규칙과 함께 column= 사용할 수 있습니다.
예제는 year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}입니다.
사용자 지정 출력은 테이블을 변경하고 Stream Analytics와 Hive 간에 포트 데이터에 파티션을 수동으로 추가하는 번거로움을 제거합니다. 대신 다음을 사용하여 많은 폴더를 자동으로 추가할 수 있습니다.
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
예시
Stream Analytics Azure Portal 빠른 시작에 따라 스토리지 계정, 리소스 그룹, Stream Analytics 작업 및 입력 원본을 만듭니다. 빠른 시작에 사용된 것과 동일한 샘플 데이터를 사용합니다. 샘플 데이터는 GitHub에서도 사용할 수 있습니다.
다음 구성을 사용하여 Blob 출력 싱크를 만듭니다.
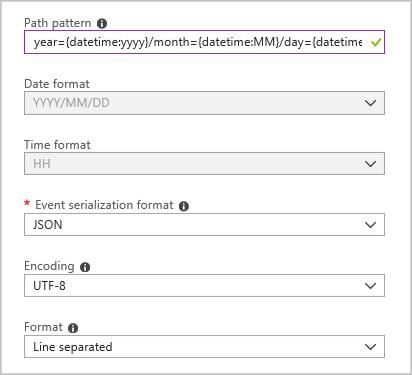
전체 경로 패턴은 다음과 같습니다.
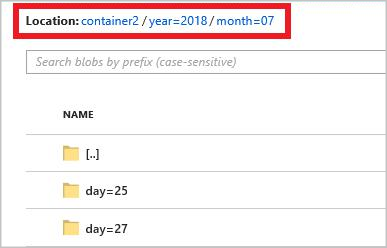
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
작업을 시작하는 경우 경로 패턴에 따라 폴더 구조는 Blob 컨테이너에서 생성됩니다. 일 수준으로 드릴다운할 수 있습니다.