자습서: Blob 인벤토리 보고서 분석
Blob 및 컨테이너가 프로덕션에서 저장, 구성 및 사용되는 방식을 이해하면 비용과 성능 간의 장단점을 더 잘 최적화할 수 있습니다.
이 자습서에서는 시간에 따른 데이터 증가, 시간에 따른 데이터 추가, 수정된 파일 수, Blob 스냅샷 크기, 각 계층에 대한 액세스 패턴, 데이터가 현재 및 시간에 따라 분산되는 방식(예: 계층 간 데이터, 파일 형식, 컨테이너 및 Blob 형식)과 같은 통계를 생성하고 시각화하는 방법을 보여 줍니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Blob 인벤토리 보고서 생성
- Synapse 작업 영역 설정
- Synapse Studio 설정
- Synapse Studio 분석 데이터 생성
- Power BI에서 결과 시각화
필수 조건
Azure 구독 - 무료로 계정 만들기
Azure Storage 계정 - 스토리지 계정 만들기
사용자 ID에 Storage Blob 데이터 기여자 역할이 할당되었는지 확인.
인벤토리 보고서 생성
스토리지 계정에 Blob 인벤토리 보고서를 사용하도록 설정. Azure Storage Blob 인벤토리 보고서 사용을 참조하세요.
첫 번째 보고서를 생성하기 위해 인벤토리 보고서를 사용하도록 설정한 후 최대 24시간을 기다려야 할 수 있습니다.
Synapse 작업 영역 설정
Azure Synapse 작업 영역을 만듭니다. Azure Synapse 작업 영역 만들기를 참조하세요.
참고 항목
작업 영역을 만드는 과정의 일환으로 계층 구조 네임스페이스가 있는 스토리지 계정을 만듭니다. Azure Synapse Spark 테이블 및 애플리케이션 로그를 이 계정에 저장합니다. Azure Synapse는 이 계정을 기본 스토리지 계정으로 참조합니다. 혼동을 방지하기 위해 이 문서에서는 인벤토리 보고서 계정이라는 용어를 사용하여 인벤토리 보고서가 포함된 계정을 가리킵니다.
Synapse 작업 영역에서 기여자 역할을 사용자 ID에 할당합니다. Azure RBAC: 작업 영역에 대한 소유자 역할을 참조하세요.
인벤토리 보고서 계정으로 이동한 다음 스토리지 Blob 데이터 기여자 역할을 작업 영역의 시스템 관리 ID에 할당하여 스토리지 계정의 인벤토리 보고서에 액세스할 수 있는 권한을 Synapse 작업 영역에 부여합니다. Azure Portal을 사용하여 Azure 역할 할당을 참조하세요.
기본 스토리지 계정으로 이동하여 Blob Storage 기여자 역할을 사용자 ID에 할당합니다.
Synapse Studio 설정
Synapse Studio에서 Synapse 작업 영역을 엽니다. Synapse 스튜디오 열기를 참조하세요.
Synapse Studio ID에 Synapse 관리자 역할이 할당되었는지 확인합니다. Synapse RBAC: 작업 영역에 대한 Synapse 관리자 역할을 참조하세요.
Apache Spark 풀을 만듭니다. 서버리스 Apache Spark 풀 만들기를 참조하세요.
샘플 Notebook 설정 및 실행
이 섹션에서는 보고서에서 시각화할 통계 데이터를 생성합니다. 이 자습서를 간소화하기 위해 이 섹션에서는 샘플 구성 파일과 샘플 PySpark Notebook을 사용합니다. Notebook에는 Azure Synapse Studio에서 실행되는 쿼리 컬렉션이 포함되어 있습니다.
샘플 구성 파일 수정 및 업로드
BlobInventoryStorageAccountConfiguration.json 파일을 다운로드합니다.
해당 파일의 다음 자리 표시자를 업데이트합니다.
storageAccountName을 인벤토리 보고서 계정의 이름으로 설정합니다.destinationContainer을 인벤토리 보고서를 보유하는 컨테이너의 이름으로 설정합니다.blobInventoryRuleName을 분석하려는 결과를 생성한 인벤토리 보고서 규칙의 이름으로 설정합니다.accessKey를 인벤토리 보고서 계정의 계정 키로 설정합니다.
Synapse 작업 영역을 만들 때 지정한 기본 스토리지 계정의 컨테이너에 이 파일을 업로드합니다.
샘플 PySpark Notebook 가져오기
ReportAnalysis.ipynb 샘플 Notebook을 다운로드합니다.
참고 항목
.ipynb확장명으로 이 파일을 저장해야 합니다.Synapse Studio에서 Synapse 작업 영역을 엽니다. Synapse 스튜디오 열기를 참조하세요.
Synapse Studio에서 개발 탭을 선택합니다.
더하기 기호(+)를 선택하여 항목을 추가합니다.
가져오기를 선택하고, 다운로드한 샘플 파일로 이동하고, 해당 파일을 선택한 다음, 열기를 선택합니다.
속성 대화 상자가 나타납니다.
속성 대화 상자에서 세션 구성 링크를 선택합니다.

구성 세션 대화 상자가 열립니다.
세션 구성 대화 상자의 연결 대상 드롭다운 목록에서 이 문서의 앞부분에서 만든 Spark 풀을 선택합니다. 그런 다음, 적용 단추를 선택합니다.
Python Notebook 수정
Python Notebook의 첫 번째 셀에서
storage_account변수 값을 기본 스토리지 계정의 이름으로 설정합니다.container_name변수 값을 Synapse 작업 영역을 만들 때 지정한 해당 계정의 컨테이너 이름으로 업데이트합니다.게시 단추를 선택합니다.
PySpark Notebook 실행
PySpark Notebook에서 모두 실행을 선택합니다.
Spark 세션을 시작하는 데 몇 분, 인벤토리 보고서를 처리하는 데 몇 분 정도 걸립니다. 처리할 인벤토리 보고서가 많은 경우 첫 번째 실행은 시간이 걸릴 수 있습니다. 후속 실행은 마지막 실행 이후 생성된 새 인벤토리 보고서만 처리합니다.
참고 항목
Notebook이 실행 중인 전자 필기장을 변경하는 경우 게시 단추를 사용하여 해당 변경 내용을 게시해야 합니다.
데이터 탭을 선택하여 Notebook이 성공적으로 실행되었는지 확인합니다.
reportdata라는 데이터베이스는 데이터 창의 작업 영역 탭에 표시됩니다. 이 데이터베이스가 표시되지 않으면 웹 페이지를 새로 고쳐야 할 수 있습니다.
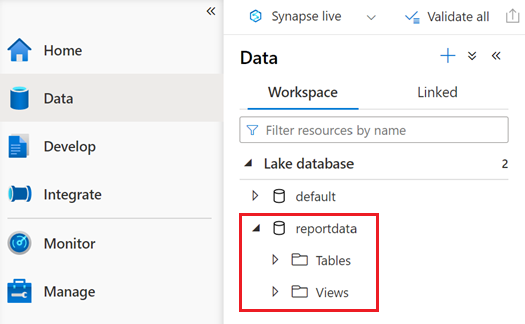
데이터베이스에는 테이블 집합이 포함되어 있습니다. 각 테이블에는 PySpark Notebook에서 쿼리를 실행하여 얻은 정보가 포함되어 있습니다.
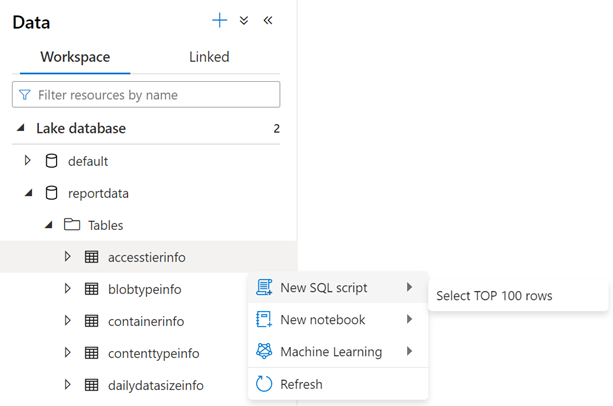
테이블의 내용을 검사하려면 reportdata 데이터베이스의 Tables 폴더를 확장합니다. 그런 다음 테이블을 마우스 오른쪽 단추로 클릭하고 SQL 스크립트 선택을 선택한 다음 상위 100개 행 선택을 선택합니다.
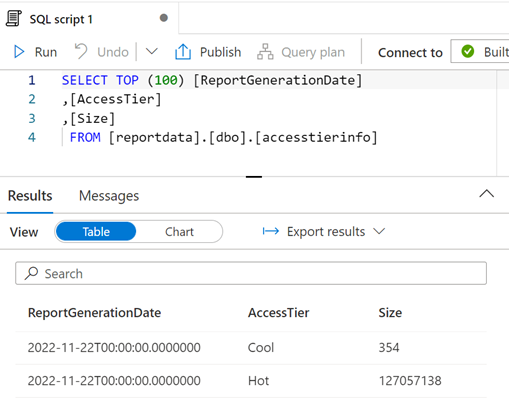
필요에 따라 쿼리를 수정한 다음 실행을 선택하여 결과를 볼 수 있습니다.
데이터 시각화
ReportAnalysis.pbit 샘플 보고서 파일을 다운로드합니다.
Power BI Desktop을 실행합니다. 설치 지침은 Power BI Desktop 가져오기를 참조하세요.
Power BI에서 파일, 보고서 열기, 보고서 찾아보기를 차례로 선택합니다.
열기 대화 상자에서 파일 형식을 Power BI 템플릿 파일(*.pbit)으로 변경합니다.

다운로드한 ReportAnalysis.pbit 파일의 위치로 이동한 다음 열기를 선택합니다.
Synapse 작업 영역의 이름과 데이터 기본 이름을 제공하도록 요청하는 대화 상자가 나타납니다.
대화 상자에서 synapse_workspace_name 필드를 작업 영역 이름으로 설정하고 database_name 필드를
reportdata로 설정합니다. 그런 다음 로드 단추를 선택합니다.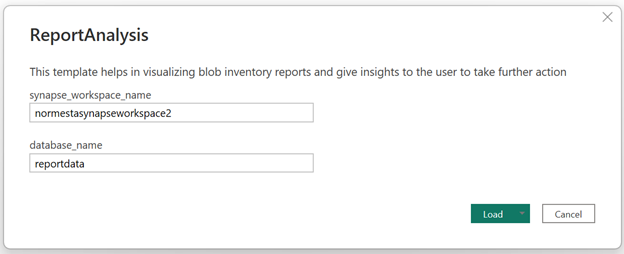
Notebook에서 검색한 데이터의 시각화를 제공하는 보고서가 나타납니다. 다음 이미지는 이 보고서에 표시되는 차트 및 그래프의 형식을 보여 줍니다.
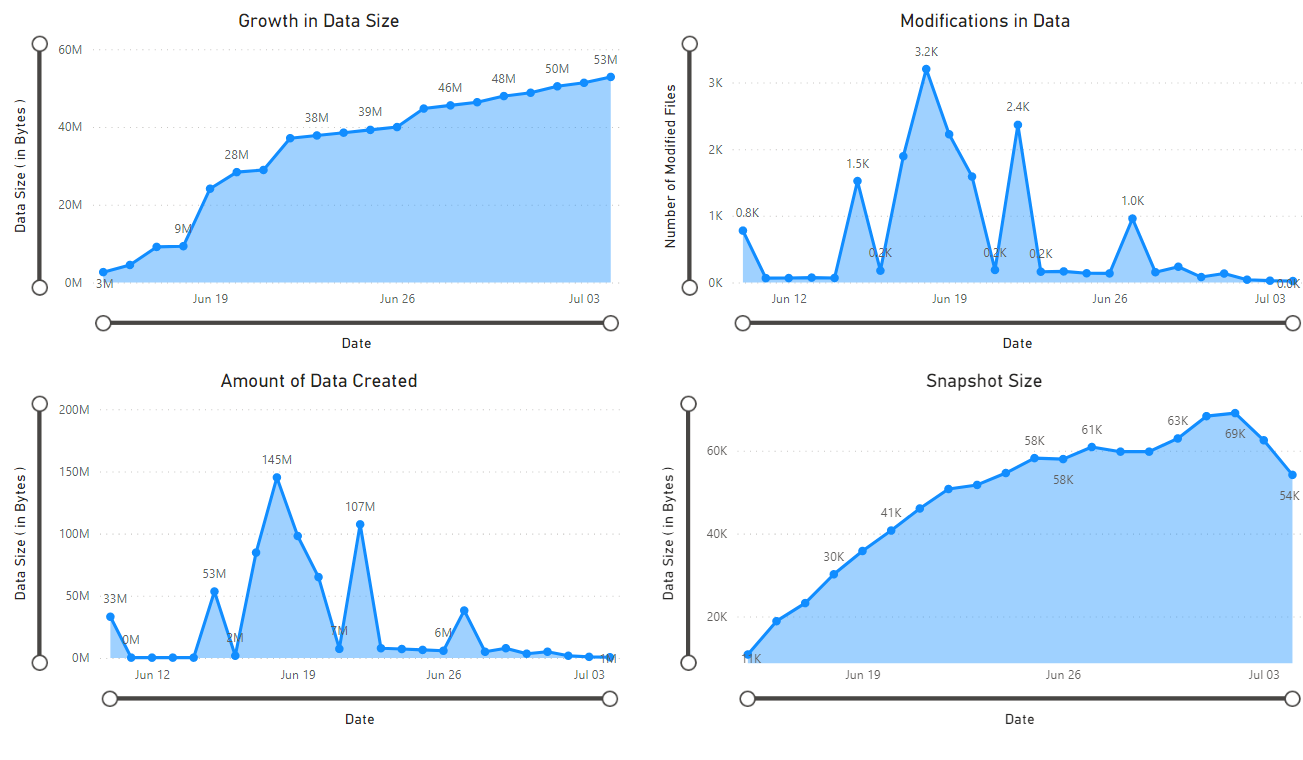
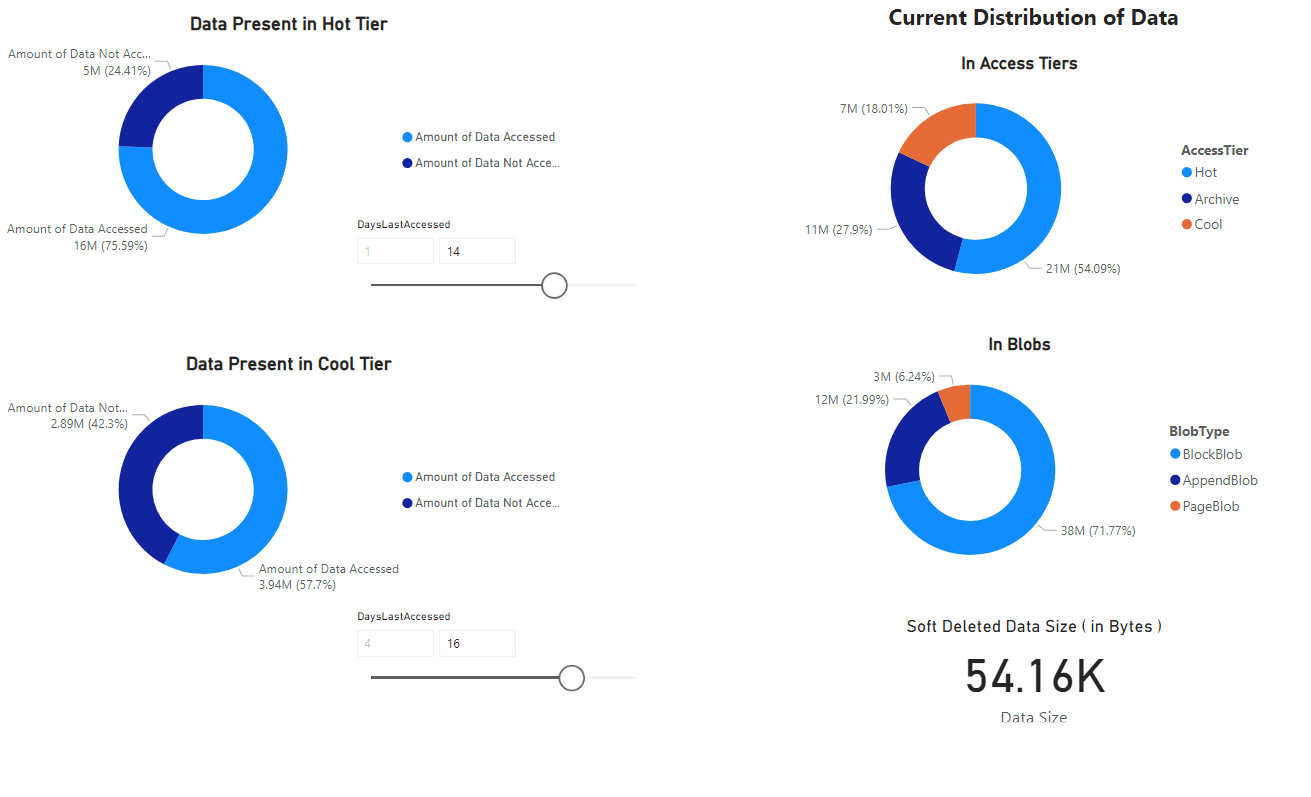
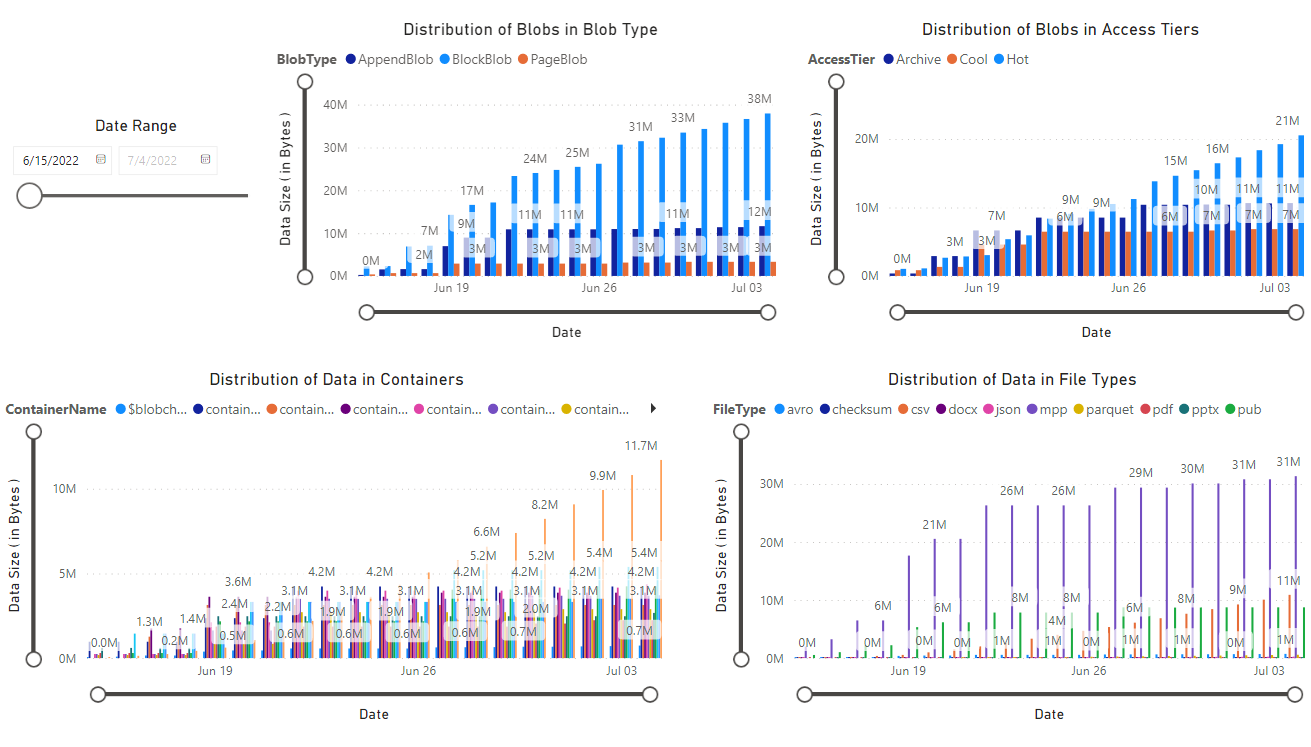
다음 단계
정기적으로 Notebook을 계속 실행하도록 Azure Synapse 파이프라인을 설정합니다. 이렇게 하면 새 인벤토리 보고서를 만드는 즉시 처리할 수 있습니다. 초기 실행 후 각 다음 실행은 증분 데이터를 분석한 다음 해당 분석 결과로 테이블을 업데이트합니다. 지침은 파이프라인과 통합을 참조하세요.
스토리지 계정에서 개별 컨테이너를 분석하는 방법에 대해 알아봅니다. 아래 문서를 참조하세요.
Blob 및 컨테이너의 분석을 기반으로 비용을 최적화하는 방법에 대해 알아봅니다. 아래 문서를 참조하세요.