Azure AI 검색의 의미 체계 순위 지정
Azure AI 검색에서 의미 순위매기기은 Microsoft의 언어 이해 모델을 사용하여 검색 결과의 순위를 재지정함으로써 검색 관련성을 크게 개선하는 기능입니다. 이 문서는 의미 순위매기기의 동작과 이점을 이해하는 데 도움이 되는 개략적인 소개입니다.
의미 순위매기기는 사용량에 따라 청구되는 프리미엄 기능입니다. 이 문서를 백그라운드에서 수행하는 것이 좋지만 시작하려면 다음 단계를 따릅니다.
참고 항목
의미 순위매기기는 생성형 AI 또는 벡터를 사용하지 않습니다. 벡터 및 유사성 검색을 찾는 경우 자세한 내용은 Azure AI Search의 벡터 검색을 참조하세요.
의미 체계 순위 지정이란?
의미 순위매기기는 텍스트 기반 쿼리, 벡터 쿼리, 하이브리드 쿼리에 대한 초기 BM25 순위 또는 RRF 순위 검색 결과의 품질을 향상시키는 쿼리 쪽 기능의 컬렉션입니다. 검색 서비스에서 사용하도록 설정하면 의미 체계 순위 지정은 쿼리 실행 파이프라인을 두 가지 방식으로 확장합니다.
첫째, BM25 또는 RRF(역 순위 퓨전)를 사용하여 점수가 매겨진 초기 결과 집합에 보조 순위를 추가합니다. 이 보조 순위는 Microsoft Bing에서 채택한 다국어 딥 러닝 모델을 사용하여 의미상 가장 관련성이 높은 결과를 승격시킵니다.
둘째, 사용자의 검색 환경을 개선하기 위해 검색 페이지에서 렌더링할 수 있는 캡션과 답변을 응답에서 추출하여 반환합니다.
의미 순위 다시 매기기의 기능은 다음과 같습니다.
| 기능 | 설명 |
|---|---|
| L2 순위 | 쿼리의 컨텍스트 또는 의미 체계 의미를 사용하여 미리 순위가 지정된 결과에 대한 새 관련성 점수를 계산합니다. |
| 의미 체계 캡션 및 강조 표시 | 필드에서 콘텐츠를 가장 잘 요약하는 축어적 문장과 구를 추출하고 쉽게 검사할 수 있도록 핵심 구를 강조 표시합니다. 검색 결과 페이지에서 개별 콘텐츠 필드가 너무 조밀한 경우 결과를 요약하는 캡션이 유용합니다. 강조 표시된 텍스트는 사용자가 일치 항목으로 간주되는 이유를 빠르게 확인할 수 있도록 가장 관련성이 높은 용어와 구를 승격시킵니다. |
| 의미 체계 답변 | 의미 체계 쿼리에서 반환되는 선택적 및 추가 하위 구조입니다. 질문처럼 보이는 쿼리에 직접 답변을 제공합니다. 문서에 대답의 특성이 있는 텍스트가 있어야 합니다. |
의미 순위매기기의 작동 방식
의미 순위매기기는 Microsoft에서 호스트하는 언어 이해 모델에 쿼리와 결과를 제공하고 더 나은 일치 항목을 검색합니다.
다음 그림에서는 개념을 설명합니다. "capital"이라는 용어의 경우, 컨텍스트가 금융인지, 법률인지, 지리인지, 문법인지에 따라 의미가 달라집니다. 의미 순위매기기는 언어 이해를 통해 컨텍스트를 감지하고 쿼리 의도에 맞는 결과를 승격시킬 수 있습니다.
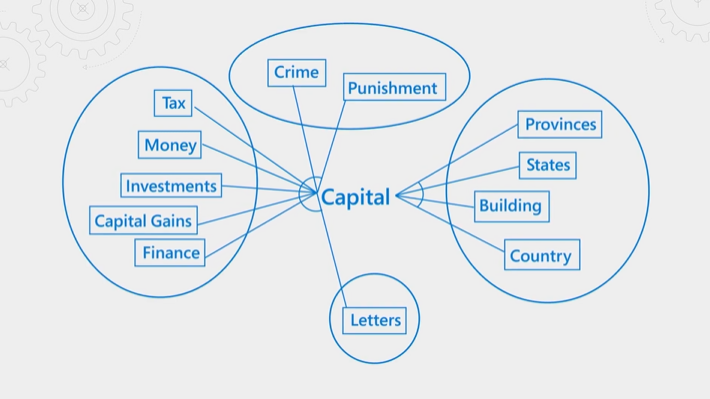
의미 체계 순위 지정에는 리소스와 시간이 모두 많이 듭니다. 쿼리 작업의 예상되는 대기 시간 내에 처리를 완료하기 위해 의미 순위매기기에 대한 입력이 통합 및 감소되어 순위 재지정 단계가 최대한 빠르게 완료될 수 있습니다.
의미 체계 순위 지정에의 세 단계는 다음과 같습니다.
- 입력 수집 및 요약
- 의미 순위매기기를 사용하여 결과 점수 매기기
- 다시 점수가 매겨진 결과, 캡션, 답변을 출력
입력을 수집하고 요약하는 방법
의미 체계 순위 지정에서 쿼리 하위 시스템은 검색 결과를 요약 및 순위 지정 모델에 대한 입력으로 전달합니다. 순위 지정 모델에는 입력 크기 제약 조건이 있고 처리 집약적이므로 효율적인 처리를 위해 검색 결과의 크기를 조정하고 구조화(요약)해야 합니다.
의미 순위매기기는 텍스트 쿼리의 BM25 순위 지정 결과 또는 벡터나 하이브리드 쿼리의 RRF 순위 지정 결과로 시작됩니다. 순위 재지정 연습에는 텍스트 필드만 사용되며, 결과에 50개 넘게 포함되어 있더라도 상위 50개 결과에만 의미 체계 순위 지정이 진행됩니다. 일반적으로 의미 체계 순위 지정에 사용되는 필드는 정보 및 설명입니다.
검색 결과의 각 문서에 대해 요약 모델은 최대 2,000개의 토큰을 허용합니다. 여기서 토큰은 약 10자입니다. 입력은 의미 체계 구성에 나열된 "title", "keyword" 및 "content" 필드에서 어셈블됩니다.
지나치게 긴 문자열은 전체 길이가 요약 단계의 입력 요구 사항을 충족하도록 잘립니다. 이렇게 자르는 작업 때문에 우선 순위에 따라 의미 체계 구성에 필드를 추가하는 것이 중요합니다. 텍스트가 많은 필드가 있는 큰 문서를 사용하는 경우 최대 제한 이후의 모든 항목은 무시됩니다.
의미 체계 필드 토큰 제한 "title" 토큰 128개 "keyword 토큰 128개 "content" 나머지 토큰 요약 출력은 각 필드에서 가장 관련성이 높은 정보로 구성된 각 문서에 대한 요약 문자열입니다. 요약 문자열은 채점을 위해 순위매기기에 전송되고, 캡션 및 답변을 위해 기계 독해 모델로 전송됩니다.
2024년 11월 현재 의미 체계 순위에 전달된 생성된 각 요약 문자열의 최대 길이는 2,048개 토큰입니다. 이전에는 256개의 토큰이었습니다.
순위 지정 방법
점수 매기기는 캡션 및 2,048 토큰 길이를 채우는 요약 문자열의 다른 콘텐츠에 대해 수행됩니다.
캡션은 제공된 쿼리를 기준으로 개념 및 의미 체계 관련성에 대해 평가됩니다.
@search.rerankerScore는 해당 쿼리에 대한 문서의 의미 체계 관련성을 기반으로 각 문서에 할당됩니다. 점수 범위는 4~0(높음에서 낮음)이며, 점수가 높을수록 관련성이 높다는 것을 의미합니다.
점수 의미 4.0 이 문서는 관련성이 높으며 질문에 대해 완전한 답변을 제공하지만, 질문과 관련이 없는 추가 텍스트가 포함될 수 있습니다. 3.0 문서는 관련이 있지만 완성할 수 있는 세부 정보가 부족합니다. 2.0 문서는 다소 관련이 있습니다. 질문에 부분적으로 답변하거나 질문의 일부 측면만 다룹니다. 1.0 이 문서는 질문과 관련이 있으며, 그 중 일부만 답변합니다. 0.0 문서는 관련이 없습니다. 일치 항목은 점수를 기준으로 내림차순으로 나열되고 쿼리 응답 페이로드에 포함됩니다. 페이로드에는 답변, 일반 텍스트 및 강조 표시된 캡션과 select 절에서 검색할 수 있거나 지정된 것으로 표시된 모든 필드가 포함됩니다.
참고 항목
지정된 쿼리의 경우 @search.rerankerScore 배포는 인프라 수준의 조건으로 인해 약간의 변화를 나타낼 수 있습니다. 순위 모델 업데이트도 배포에 영향을 미치는 것으로 알려져 있습니다. 이러한 이유로 최소 임계값에 대한 사용자 지정 코드를 작성하거나 벡터 및 하이브리드 쿼리에 대한 임계값 속성을 설정하는 경우 제한을 너무 세분화하지 않습니다.
의미 순위매기기의 출력
각 요약 문자열에서 기계 독해 모델은 가장 대표적인 구절을 찾습니다.
출력은 다음과 같습니다.
문서에 대한 의미 체계 캡션. 각 캡션은 일반 텍스트 버전 및 강조 표시 버전으로 사용할 수 있으며 문서 당 200단어 미만으로 자주 사용됩니다.
선택 사항인 의미 체계 답변(
answers매개 변수를 지정했다고 가정) 쿼리가 질문으로 제기되었으며 긴 문자열에서 질문에 적당한 답변을 제공하는 구절이 발견됩니다.
캡션 및 답변은 항상 인덱스의 축어적 텍스트입니다. 이 워크플로에는 새 콘텐츠를 만들거나 작성하는 생성 AI 모델이 없습니다.
의미 체계 기능 및 제한 사항
의미 순위매기기는 최신 기술이므로 수행할 수 있는 작업과 수행할 수 없는 작업에 대한 기대치를 설정하는 것이 중요합니다. 수행할 수 있는 작업은 다음과 같습니다.
의미 체계 측면에서 원래 쿼리의 의도에 더 가까운 일치 항목을 승격시킵니다.
캡션 및 답변으로 사용할 문자열을 찾습니다. 캡션과 답변은 응답에 반환되며 검색 결과 페이지에 렌더링될 수 있습니다.
의미 순위매기기가 할 수 없는 것은 의미 체계 측면에서 관련된 결과를 찾기 위해 전체 말뭉치에 대해 쿼리를 다시 실행하는 것입니다. 의미 체계 순위 지정은 기본 순위 지정 알고리즘에 따라 점수가 매겨진 상위 50개 결과로 구성된 기존 결과 집합의 순위를 다시 매깁니다. 또한 의미 순위매기기는 새 정보 또는 문자열을 만들 수 없습니다. 캡션과 답변은 콘텐츠에서 그대로 추출되므로 답변과 비슷한 텍스트가 결과에 포함되지 않는 경우 언어 모델에서 이 텍스트를 생성하지 않습니다.
의미 체계 순위 지정이 모든 시나리오에서 도움이 되는 것은 아니지만, 어떤 콘텐츠는 해당 기능을 통해 상당한 이점을 얻을 수 있습니다. 의미 순위매기기의 언어 모델은 정보가 풍부한 산문 구조의 검색 가능한 콘텐츠에서 가장 효과적입니다. 기술 자료, 온라인 설명서 또는 설명 콘텐츠가 포함된 문서는 의미 순위매기기 기능에서 가장 많은 이점을 얻습니다.
기본 기술은 Bing 및 Microsoft Research에서 제공되었으며 추가 기능으로 Azure AI 검색 인프라에 통합되었습니다. 의미 순위매기기를 뒷받침하는 연구 및 AI 투자에 대한 자세한 내용은 Bing의 AI가 Azure AI 검색을 지원하는 방법(Microsoft Research 블로그)을 참조하세요.
다음 동영상에서는 기능의 개요를 제공합니다.
가용성 및 가격 책정
의미 순위매기기는 국가별 가용성에 따라 기본 및 상위 계층의 검색 서비스에서 사용할 수 있습니다.
의미 순위매기기를 사용하도록 설정할 때 해당 기능에 대한 요금제를 선택합니다.
- 낮은 쿼리 볼륨(매월 1,000개 미만)에서는 의미 체계 순위가 무료입니다.
- 쿼리량이 많을 경우 표준 요금제를 선택합니다.
Azure AI 검색 가격 책정 페이지에는 다양한 통화 및 간격에 대한 청구 요금이 표시됩니다.
의미 순위매기기에 대한 요금은 쿼리 요청에 queryType=semantic이 포함되고 검색 문자열이 비어 있지 않은 경우에 부과됩니다(예: search=pet friendly hotels in New York). 검색 문자열이 비어 있으면(search=*) queryType이 semantic으로 설정되어 있어도 요금이 청구되지 않습니다.
의미 순위매기기를 시작하는 방법
지역별 가용성을 확인합니다.
Azure Portal에 로그인하여 검색 서비스가 기본 이상인지 확인합니다.