키워드 검색 관련성(BM25 채점)
이 문서에서는 전체 텍스트 검색에서 검색 점수를 계산하는 데 사용되는 BM25 관련성 채점 알고리즘을 설명합니다. BM25 관련성은 전체 텍스트 검색에만 적용됩니다. 필터 쿼리, 자동 완성 및 제안된 쿼리, 와일드카드 검색 및 유사 항목 검색 쿼리는 관련성에 대해 점수가 매겨지거나 순위가 지정되지 않습니다.
전체 텍스트 검색에 사용되는 채점 알고리즘
Azure AI 검색은 전체 텍스트 검색에 다음과 같은 채점 알고리즘을 제공합니다.
| 알고리즘 | 사용 | 범위 |
|---|---|---|
BM25Similarity |
2020년 7월 이후 생성된 모든 검색 서비스에 대한 고정 알고리즘. 이 알고리즘을 구성할 수 있지만 이전 알고리즘(클래식)으로 전환할 수는 없습니다. | 바인딩 되지 않음 |
ClassicSimilarity |
2020년 7월 이전의 이전 검색 서비스에 대한 기본값입니다. 이전 서비스에서는 BM25를 옵트인하고 인덱스별로 BM25 알고리즘을 선택할 수 있습니다. | 0 < 1.00 |
BM25와 Classic은 모두 TF-IDF와 유사한 검색 함수로, 각각의 문서-쿼리 쌍에 대한 관련성 점수를 계산한 다음, 결과 순위 지정에 사용하는 데 TF(용어 빈도)와 IDF(역 문서 빈도)를 변수로 사용합니다. 개념적으로 클래식과 유사하지만 BM25는 사용자 조사에 의해 측정된 바와 같이 보다 직관적인 일치 항목을 생성하는 확률적 정보 검색에 뿌리를 두고 있습니다.
BM25는 사용자가 일치하는 용어의 용어 빈도로 관련성 점수의 크기를 조정하는 방법을 결정할 수 있도록 하는 등 고급 사용자 지정 옵션을 제공합니다.
BM25 순위 지정 작동 방식
관련성 채점은 현재 쿼리 컨텍스트에서 항목 관련성을 나타내는 지표 역할을 하는 검색 점수(@search.score)의 계산을 나타냅니다. 범위는 바인딩되지 않습니다. 하지만 점수가 높을수록 항목 관련성도 높아집니다.
검색 점수는 문자열 입력과 쿼리 자체의 통계 속성에 따라 계산됩니다. Azure AI 검색은 검색 용어와 일치하는 문서를 찾고(searchMode에 따라 일부 또는 전체) 검색 용어 인스턴스가 많이 포함된 문서에 높은 점수를 매깁니다. 해당 용어가 데이터 인덱스에는 거의 없지만 해당 문서 내에서는 자주 나오는 경우 검색 점수가 더 높아집니다. 이와 같은 관련성 계산 방식의 기준을 TF-IDF, 즉 용어 빈도와 문서 빈도 반비례라고 합니다.
전체 결과 집합에서 검색 점수가 반복될 수 있습니다. 여러 적중 항목의 검색 점수가 같은 경우 동일 점수의 항목 순서는 정의되지 않고 안정적이지 않습니다. 쿼리를 다시 실행합니다. 그러면 특히 무료 서비스나 복제본이 여러 개 있는 청구 가능한 서비스를 사용하는 경우 항목 이동 위치가 표시될 수 있습니다. 즉, 두 항목의 점수가 같으면 어떤 항목이 먼저 표시되는지 보장되지 않습니다.
반복 점수 간의 동률을 끊으려면 $orderby 절을 첫 번째 순서에 점수로 추가한 다음 정렬 가능한 다른 필드(예$orderby=search.score() desc,Rating desc: )로 정렬할 수 있습니다.
인덱스에서 searchable로 표시된 필드나 쿼리의 searchFields만 점수 매기기에 사용됩니다. retrievable로 표시된 필드나 쿼리의 select에 지정된 필드만 검색 점수와 함께 검색 결과에서 반환됩니다.
참고 항목
@search.score = 1은 점수가 매겨지지 않거나 순위가 지정되지 않은 결과 세트를 나타냅니다. 점수는 모든 결과에서 균일합니다. 점수가 매칭되지 않은 결과는 쿼리 양식이 유사 항목 검색, 와일드카드 또는 정규식 쿼리 또는 빈 검색일 때 발생합니다(search=*, 필터와 쌍을 이루는 경우도 있음). 여기서 필터는 일치 항목을 반환하는 기본 수단입니다.
다음 비디오 세그먼트는 Azure AI 검색에서 사용되는 일반 공급 순위 지정 알고리즘에 대한 설명을 빠르게 제공합니다. 자세한 배경 정보는 전체 비디오를 시청하여 확인할 수 있습니다.
텍스트 결과 점수
결과 순위가 지정될 때마다 @search.score 속성에는 결과 순서를 지정하는 데 사용되는 값이 포함됩니다.
다음 표에서는 점수 매기기 속성, 알고리즘 및 범위를 식별합니다.
| 검색 방법 | 매개 변수 | 점수 매기기 알고리즘 | 범위 |
|---|---|---|---|
| 전체 텍스트 검색 | @search.score |
인덱스에 지정된 매개 변수를 사용하는 BM25 알고리즘 | 바인딩 되지 않음 |
점수 변형
검색 점수는 동일한 결과 집합의 다른 문서를 기준으로 일치 수준을 반영하여 일반적인 관련성 정보를 전달합니다. 그러나 쿼리마다 점수가 항상 일치하는 것은 아니므로, 쿼리 작업에서 검색 문서의 순서가 지정되는 방법에서 약간 차이가 있을 수 있습니다. 이러한 상황이 발생하는 원인은 다음과 같이 몇 가지로 설명할 수 있습니다.
| 원인 | 설명 |
|---|---|
| 동일한 점수 | 여러 문서의 점수가 동일한 경우 그 중 아무거나 먼저 표시될 수 있습니다. |
| 데이터 변동성 | 인덱스 콘텐츠에 따라 문서를 추가, 수정 또는 삭제할 수 있습니다. 시간 경과에 따라 인덱스 업데이트가 처리되면 용어 빈도가 변경되며 일치하는 문서의 검색 점수에 영향이 있습니다. |
| 여러 복제본 | 여러 복제본을 사용하는 서비스의 경우 각 복제본에 대해 병렬로 쿼리가 실행됩니다. 검색 점수를 계산하는 데 사용되는 인덱스 통계는 복제본별로 산출되며 쿼리 응답에서는 결과가 병합 및 정렬됩니다. 복제본은 대부분 서로를 반영하지만 약간의 상태 차이가 있으므로 통계가 다를 수 있습니다. 예를 들어, 한 복제본이 해당 통계에 영향을 주는 문서를 삭제했는데 이 문서가 다른 복제본에 병합되었을 수 있습니다. 일반적으로 복제본별 통계에서의 차이는 소규모 인덱스에서 더 두드러집니다. 다음 섹션에서는 이 조건에 대한 자세한 정보를 제공합니다. |
쿼리 결과에 대한 분할 효과
분할된 데이터베이스는 인덱스의 청크입니다. Azure AI 검색은 분할된 데이터베이스를 새 검색 단위로 이동하여 파티션을 더 빠르게 추가할 수 있도록 인덱스를 분할된 데이터베이스로 세분화합니다. 검색 서비스에서 분할 관리는 구현 세부 정보이며 구성할 수 없습니다. 하지만 인덱스가 분할된다는 점을 알면 순위 지정과 자동 완성 동작 중의 간헐적인 변칙을 이해하는 데 도움이 됩니다.
순위 지정 변칙: 검색 점수가 먼저 분할 수준에서 계산된 다음 단일 결과 집합으로 집계됩니다. 분할 콘텐츠의 특성에 따라 한 분할의 일치에 다른 분할의 일치보다 더 높은 순위가 지정될 수 있습니다. 검색 결과에 직관적이지 않은 순위가 있는 경우, 특히 인덱스가 작을 때 나타나는 분할 효과 때문일 가능성이 높습니다. 전체 인덱스에서 전역적으로 점수를 계산을 선택하여 순위 지정 변칙을 피할 수 있지만 이 경우 성능 저하가 발생합니다.
자동 완성 변칙: 부분적으로 입력된 용어의 처음 몇 개 문자에서 일치가 이루어지는 자동 완성 쿼리는 철자의 작은 편차를 용인하는 유사 매개 변수를 허용합니다. 자동 완성의 경우 유사 일치는 현재 분할 내 용어로 제한됩니다. 예를 들어 분할에 "Microsoft"가 있고 부분 용어인 "micro"가 입력되면 검색 엔진에서 해당 분할의 "Microsoft"와 일치시킵니다. 하지만 인덱스의 나머지를 보유한 다른 분할에서는 일치시키지 않습니다.
다음 다이어그램에서는 복제본, 파티션, 분할 및 검색 단위 간의 관계를 보여줍니다. 단일 인덱스가 2개의 복제본과 2개의 파티션이 있는 서비스에서 4개의 검색 단위에 걸쳐 존재하는 방법의 예를 보여줍니다. 4개의 각 검색 단위는 인덱스 분할의 절반만 저장합니다. 왼쪽 열에 있는 검색 단위는 분할의 첫 절반을 저장하여 첫 번째 파티션을 구성하고, 오른쪽 열은 분할의 나머지 절반을 저장하여 두 번째 파티션을 구성합니다. 2개의 복제본이 있으므로 각 인덱스 분할의 복사본이 2개 있습니다. 상단 행의 검색 단위는 1개의 복사본을 저장하여 첫 번째 복제본을 구성하고, 하단 행은 다른 복사본을 저장하여 두 번째 복제본을 구성합니다.
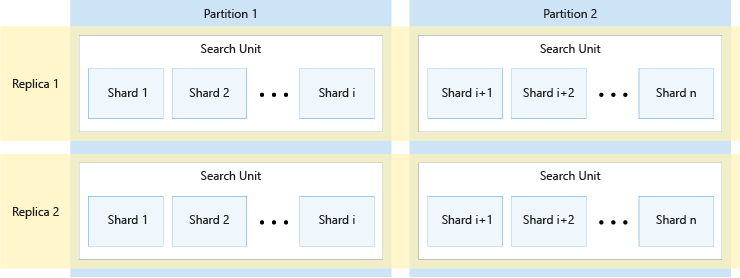
위의 다이어그램은 한 가지 예시에 불과합니다. 최대 36개의 검색 단위에서 파티션 및 복제본의 여러 조합을 사용할 수 있습니다.
참고 항목
복제본 및 파티션 수는 12를 고르게 나눌 수 있는 값입니다(특히 1, 2, 3, 4, 6, 12). Azure AI 검색은 각 인덱스를 모든 파티션 사이에 고르게 분할할 수 있도록 12개의 부분으로 미리 나눕니다. 예를 들어, 서비스에 파티션이 세 개 있는 상태에서 인덱스를 하나 만들 경우 각 파티션에는 분할된 인덱스가 4개가 포함됩니다. Azure AI 검색에서 인덱스를 분할하는 방법은 구현에 관한 세부 정보이며 이후 릴리스에서 변경될 수 있습니다. 지금은 그 숫자가 12이지만 이후에 12가 아닌 값으로 바뀔 수도 있습니다.
통계 및 고정 세션 점수 매기기
확장성을 위해 Azure AI 검색은 분할 프로세스를 통해 각 인덱스를 수평으로 분산합니다. 즉, 인덱스 부분이 물리적으로 분리됩니다.
기본적으로 문서 점수는 분할된 데이터베이스 내 데이터의 통계 속성에 따라 계산됩니다. 이 방법은 일반적으로 많은 양의 데이터 모음이 있을 때는 문제가 되지 않으며, 모든 분할된 데이터베이스의 정보를 기준으로 점수를 계산해야 하는 경우보다 더 나은 성능을 제공합니다. 즉, 이러한 성능 최적화를 사용하면 매우 유사한 두 개의 문서(또는 동일한 문서)가 서로 다른 분할된 데이터베이스에 속하게 될 때 서로 다른 관련성 점수를 갖게 될 수 있습니다.
모든 분할된 데이터베이스의 통계 속성에 따라 점수를 계산하려면 쿼리 매개 변수로 scoringStatistics=global을 추가하여(또는 쿼리 요청의 본문 매개 변수로 "scoringStatistics": "global" 추가) 수행할 수 있습니다.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
scoringStatistics를 사용하면 동일한 복제본의 모든 분할된 데이터베이스에서 같은 결과를 제공합니다. 즉, 인덱스에 대한 최신 변경 내용으로 업데이트되므로 복제본이 서로 약간 다를 수 있습니다. 일부 시나리오에서는 사용자가 "쿼리 세션" 중에 더 일관된 결과를 얻도록 할 수 있습니다. 이러한 시나리오에서는 쿼리의 일부로 sessionId를 제공할 수 있습니다. sessionId는 고유한 사용자 세션을 참조하기 위해 만드는 고유 문자열입니다.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
동일한 sessionId를 사용한다면 같은 복제본을 대상으로 최상의 시도를 진행하여 사용자에게 표시되는 결과의 일관성을 높일 수 있습니다.
참고 항목
동일한 sessionId 값을 반복해서 다시 사용하면 복제본 간에 요청 부하가 분산되지 못하며 검색 서비스의 성능에 부정적인 영향을 미칠 수 있습니다. sessionId로 사용되는 값은 '_' 문자로 시작할 수 없습니다.
관련성 튜닝
Azure AI Search에서 하이브리드 쿼리의 키워드 검색 및 텍스트 부분에 대해 BM25 알고리즘 매개 변수를 구성하고 검색 관련성을 조정하고 다음 메커니즘을 통해 검색 점수를 높일 수 있습니다.
| 접근 방식 | 구현 | 설명 |
|---|---|---|
| BM25 알고리즘 구성 | 검색 인덱스 | 문서 길이 및 용어 빈도가 관련성 점수에 미치는 영향을 구성합니다. |
| 점수 매기기 프로필 | 검색 인덱스 | 콘텐츠 특성에 따라 일치 항목의 검색 점수를 높일 수 있는 기준을 제공합니다. 예를 들어 수익 잠재력에 따라 일치 항목을 승격하거나, 최신 항목을 승격하거나, 인벤토리에 너무 오래 있었던 항목을 높일 수 있습니다. 점수 매기기 프로필은 가중 필드, 함수 및 매개 변수로 구성된 인덱스 정의의 일부입니다. 인덱스를 다시 빌드하지 않고도 점수 매기기 프로필 변경 내용으로 기존 인덱스를 업데이트할 수 있습니다. |
| 의미 체계 순위 | 쿼리 요청 | 검색 결과에 컴퓨터 읽기 이해력을 적용하여 의미상 관련성이 더 큰 결과를 가장 먼저 보여줍니다. |
| featuresMode 매개 변수 | 쿼리 요청 | 이 매개 변수는 BM25 순위 점수의 압축을 푸는 데 주로 사용되지만 사용자 지정 점수 매기기 솔루션을 제공하는 코드에서 사용할 수 있습니다. |
featuresMode 매개 변수(미리 보기)
문서 검색 요청은 필드 수준에서 BM25 관련성 점수에 대한 자세한 정보를 제공하는 featuresMode 매개 변수를 지원합니다. @searchScore가 전체 문서에 대하여 계산되는 반면(해당 쿼리의 컨텍스트에서의 문서 관련성 정도), featuresMode를 통해서는 @search.features 구조에서 설명한 바와 같이 개별 필드에 대한 정보를 얻을 수 있습니다. 해당 구조에는 쿼리에서 사용한 모든 필드가 들어갑니다(쿼리 내의 searchFields를 통한 특정 필드 또는 인덱스 내에서 searchable라는 특성을 갖는 모든 필드).
각 필드에 대해 @search.features는 다음 값을 제공합니다.
- 필드에서 찾은 고유한 토큰의 수
- 유사성 점수 또는 쿼리 용어와 관련해 해당 필드의 콘텐츠가 얼마나 유사한지에 대한 측정값
- 용어 빈도 또는 필드 내에서 해당 쿼리 용어가 발견된 횟수
"설명" 및 "제목" 필드를 대상으로 하는 쿼리에 대해서는 @search.features를 포함하는 응답이 다음과 같을 수 있습니다.
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
이러한 데이터 요소를 사용자 지정 채점 솔루션에서 사용하거나 검색 관련성 문제를 디버그하는 데 정보를 사용할 수 있습니다.
featuresMode 매개 변수는 REST API에 설명되어 있지 않지만 미리 보기 REST API 호출에서 BM25 순위의 텍스트(키워드) 검색을 검색하는 데 사용할 수 있습니다.
전체 텍스트 쿼리 응답의 순위가 지정된 결과 수
기본적으로 페이지 매김을 사용하지 않는 경우 검색 엔진은 전체 텍스트 검색에서 상위 50개 순위 일치 항목을 반환합니다. 매개 변수를 top 사용하여 더 작거나 더 많은 수의 항목을 반환할 수 있습니다(단일 응답에서 최대 1,000개). 결과를 사용하고 skip next 페이지를 만들 수 있습니다. 페이징은 각 논리 페이지의 결과 수를 결정하고 콘텐츠 탐색을 지원합니다. 자세한 내용은 셰이프 검색 결과를 참조하세요.
전체 텍스트 쿼리가 하이브리드 쿼리의 일부인 경우 쿼리의 텍스트 쪽에서 결과 수를 늘리거나 줄이도록 설정할 maxTextRecallSize 수 있습니다.
전체 텍스트 검색에는 일치 항목 최대 1,000개가 적용됩니다(API 응답 제한 참조). 일치 항목 1,000개가 발견되면 검색 엔진은 더 이상 검색하지 않습니다.