검색 앱에 패싯 탐색 추가
패싯 탐색은 검색 앱의 쿼리 결과에 대한 자기 주도형 드릴다운 필터링에 사용됩니다. 여기서 애플리케이션은 검색 범위를 문서 그룹(예: 범주 또는 브랜드)으로 지정하기 위한 양식 컨트롤을 제공합니다. Azure AI 검색은 환경을 지원하는 데이터 구조 및 필터를 제공합니다.
이 문서에서는 Azure AI 검색에서 패싯 탐색 구조를 만들기 위한 기본 단계를 알아봅니다.
- 인덱스에서 필드 특성 설정
- 요청 및 응답 구조화
- 프레젠테이션 계층에서 탐색 컨트롤 및 필터 추가
프레젠테이션 계층의 코드는 패싯 탐색 환경에서 많은 작업을 수행합니다. 이 문서의 끝에 나열된 데모 및 샘플은 모든 항목을 함께 가져오는 방법을 보여 주는 작업 코드를 제공합니다.
검색 페이지의 패싯 탐색
패싯은 동적이며 쿼리에서 반환됩니다. 검색 응답에는 결과에서 문서를 탐색하는 데 사용되는 모든 패싯 범주가 함께 제공됩니다. 쿼리를 먼저 실행한 다음, 현재 결과에서 패싯을 끌어와 패싯 탐색 구조로 어셈블합니다.
Azure AI 검색에서 패싯은 한 계층 깊이이며 계층 구조일 수 없습니다. 패싯 탐색 구조에 익숙하지 않은 경우 다음 예제에서 왼쪽에 있는 항목을 참조하세요. 개수는 각 패싯의 일치 항목 수를 나타냅니다. 동일한 문서가 여러 패싯으로 나타날 수 있습니다.
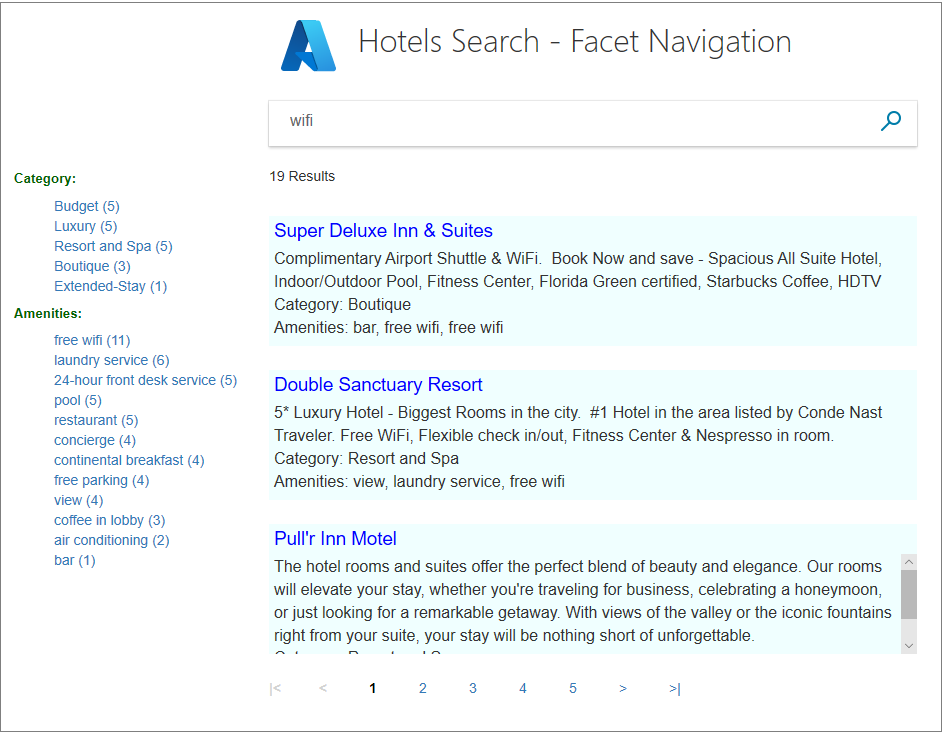
패싯을 사용하면 원하는 항목을 쉽게 찾을 수 있으며 항상 결과를 얻을 수 있습니다. 개발자는 패싯을 통해 검색 인덱스를 탐색하는 데 가장 유용한 검색 조건을 노출할 수 있습니다.
인덱스에서 패싯 사용
"facetable" 특성을 true로 설정하면 인덱스 정의에서 필드별로 패싯을 사용하도록 설정할 수 있습니다.
반드시 필요한 것은 아니지만 검색 애플리케이션의 패싯 탐색 환경으로 돌아가는 데 필요한 필터를 빌드할 수 있도록 "filterable" 특성도 설정해야 합니다.
"hotels" 샘플 인덱스의 다음 예제에서는 단일 값 또는 짧은 구를 포함하는 낮은 카디널리티 필드("Category", "Tags", "Rating")에서 "facetable" 및 "filterable"을 보여 줍니다.
{
"name": "hotels",
"fields": [
{ "name": "hotelId", "type": "Edm.String", "key": true, "searchable": false, "sortable": false, "facetable": false },
{ "name": "Description", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": false },
{ "name": "HotelName", "type": "Edm.String", "facetable": false },
{ "name": "Category", "type": "Edm.String", "filterable": true, "facetable": true },
{ "name": "Tags", "type": "Collection(Edm.String)", "filterable": true, "facetable": true },
{ "name": "Rating", "type": "Edm.Int32", "filterable": true, "facetable": true },
{ "name": "Location", "type": "Edm.GeographyPoint" }
]
}
필드 선택
패싯은 단일 값 필드 및 컬렉션에 대해 계산될 수 있습니다. 패싯 탐색에서 가장 잘 작동하는 필드에는 다음과 같은 특성이 있습니다.
낮은 카디널리티(검색 모음의 문서 전체에서 반복되는 소수의 고유 값)
탐색 트리에서 잘 렌더링되는 짧은 설명 값(한두 단어)
필드 이름 자체가 아닌 필드 내 값이 패싯 탐색 구조에서 패싯을 생성합니다. 패싯이 Color라는 문자열 필드인 경우 패싯은 파란색, 녹색 및 해당 필드의 다른 모든 값이 됩니다.
모범 사례는 필드에 null 값, 맞춤법 오류 또는 대/소문자 불일치, 동일한 단어의 단수 및 복수 버전이 있는지 확인하는 것입니다. 기본적으로 필터와 패싯은 어휘 분석이나 맞춤법 검사를 거치지 않습니다. 즉, 단어의 한 문자가 다르더라도 "facetable" 필드의 모든 값이 잠재적인 패싯입니다. 필요에 따라 "filterable" 및 "facetable" 필드에 노멀라이저를 할당하여 대/소문자 및 문자의 변형을 고르게 할 수 있습니다.
REST 및 Azure SDK의 기본값
Azure SDK 중 하나를 사용하는 경우 코드에서 필드 특성을 명시적으로 설정해야 합니다. 반면 REST API에는 데이터 형식을 기반으로 하는 필드 특성에 대한 기본값이 있습니다. 다음 데이터 형식은 기본적으로 "filterable" 및 "facetable"입니다.
Edm.StringEdm.DateTimeOffsetEdm.Boolean- 위 형식의 컬렉션(예:
Collection(Edm.String)또는Collection(Edm.Double))
Edm.GeographyPoint 또는 Collection(Edm.GeographyPoint) 필드는 패싯 탐색에서 사용할 수 없습니다. 카디널리티가 낮은 필드에서 패싯 성능이 가장 뛰어납니다. 지리적 좌표를 확인하기 때문에 지정된 데이터 세트에서 두 개의 좌표 집합이 동일한 경우는 거의 없습니다. 따라서 지리적 좌표에는 패싯이 지원되지 않습니다. 위치별로 패싯을 만들려면 도시 또는 지역 필드가 필요합니다.
팁
성능 및 스토리지 최적화를 위한 최고의 방법으로, 패싯으로 사용하지 말아야 하는 필드에 대해 패싯을 해제합니다. 특히 ID 또는 제품 이름과 같은 고유한 값의 문자열 필드는 패싯 탐색에서 실수로(그리고 비효과적으로) 사용되지 않도록 "facetable": false로 설정해야 합니다. 이는 기본적으로 필터 및 패싯을 사용하도록 설정하는 REST API의 경우 특히 그렇습니다.
패싯 요청 및 응답
패싯은 쿼리에 지정되고 패싯 탐색 구조는 응답 상단에 반환됩니다. 요청 및 응답의 구조는 매우 간단합니다. 실제로 패싯 탐색의 실제 작동은 프레젠테이션 계층에서 이루어지며 이는 이후 섹션에서 다룹니다.
다음 REST 예제는 전체 인덱스로 범위가 지정된, 정규화되지 않은 쿼리("search": "*")입니다(기본 제공 호텔 샘플 참조). 패싯은 일반적으로 필드 목록이지만 이 쿼리는 더 읽기 쉬운 응답을 위해 하나의 필드만 표시합니다.
POST https://{{service_name}}.search.windows.net/indexes/hotels/docs/search?api-version={{api_version}}
{
"search": "*",
"queryType": "simple",
"select": "",
"searchFields": "",
"filter": "",
"facets": [ "Category"],
"orderby": "",
"count": true
}
열린 쿼리를 사용하여 검색 페이지를 초기화하여 패싯 탐색 구조를 완전히 채우는 것이 유용합니다. 요청에 쿼리 용어를 전달하는 즉시 패싯 탐색 구조의 범위가 전체 인덱스가 아닌 결과의 일치 항목으로 지정됩니다.
이 예에 대한 응답에는 상단에 패싯 탐색 구조가 포함되어 있습니다. 구조는 "Category" 값과 각각의 호텔 수로 구성됩니다. 그 뒤에 나머지 검색 결과가 표시됩니다(여기서는 간단한 설명을 위해 잘림). 이 예제는 여러 가지 이유로 잘 작동합니다. 이 필드의 패싯 수는 한도(기본값: 10) 이내이므로 모두 표시되고 50개 호텔 인덱스의 모든 호텔이 정확히 이러한 범주 중 하나로 표시됩니다.
{
"@odata.context": "https://demo-search-svc.search.windows.net/indexes('hotels')/$metadata#docs(*)",
"@odata.count": 50,
"@search.facets": {
"Category": [
{
"count": 13,
"value": "Budget"
},
{
"count": 12,
"value": "Resort and Spa"
},
{
"count": 9,
"value": "Luxury"
},
{
"count": 7,
"value": "Boutique"
},
{
"count": 5,
"value": "Suite"
},
{
"count": 4,
"value": "Extended-Stay"
}
]
},
"value": [
{
"@search.score": 1.0,
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Category": "Boutique",
"Tags": [
"pool",
"air conditioning",
"concierge"
],
"ParkingIncluded": false,
}
]
}
패싯 구문
패싯 쿼리 매개 변수는 "facetable" 필드의 쉼표로 구분된 목록으로 설정되며, 데이터 형식에 따라 개수, 정렬 순서 및 범위(count:<integer>, sort:<>, interval:<integer> 및 values:<list>)를 설정하도록 추가로 매개 변수화할 수 있습니다. 패싯 매개 변수에 대한 자세한 내용은 REST API의 쿼리 매개 변수를 참조하세요.
POST https://{{service_name}}.search.windows.net/indexes/hotels/docs/search?api-version={{api_version}}
{
"search": "*",
"facets": [ "Category", "Tags,count:5", "Rating,values:1|2|3|4|5"],
"count": true
}
각 패싯 탐색 트리에는 상위 10개 패싯이라는 기본 한도가 있습니다. 이 기본값은 값 목록을 관리하기 쉬운 크기로 유지하므로 탐색 구조에 유용합니다. "count"에 값을 할당하여 기본값을 재정의할 수 있습니다. 예를 들어 "Tags,count:5"는 Tags 섹션 아래의 태그 수를 상위 5개로 줄입니다.
Numeric 및 DateTime 값의 경우에만 패싯 필드(예: facet=Rating,values:1|2|3|4|5)에서 값을 명시적으로 설정하여 결과를 연속 범위(숫자 값 또는 기간을 기준으로 하는 범위)로 구분할 수 있습니다. 또는 facet=Rating,interval:1과 같이 "interval"을 추가할 수 있습니다.
각 범위는 0부터 작성되며, 목록의 값을 엔드포인트로 사용하고 이전 범위를 잘라 불연속 간격을 만듭니다.
패싯 수의 불일치
특정 상황에서는 분할 아키텍처로 인해 패싯 수가 완전히 정확하지 않을 수 있습니다. 모든 검색 인덱스는 여러 개의 분할된 데이터베이스에 분할되며, 각 분할된 데이터베이스는 문서 수에 따라 상위 N개의 패싯을 보고합니다. 이 값이 단일 결과로 통합됩니다. 각 분할된 데이터베이스의 상위 N개 패싯만 해당하므로 패싯 응답에서 일치하는 문서를 놓치거나 과소 계수할 수 있습니다.
정확도를 보장하기 위해 count:<number>를 인위적으로 큰 숫자로 늘려 각 분할된 데이터베이스에서 전체 보고를 강제로 적용할 수 있습니다. 무제한 패싯의 경우 "count": "0"을 지정하면 됩니다. 또는 "count"를 패싯 필드의 고유 값 수보다 크거나 같은 값으로 설정할 수 있습니다. 예를 들어 고유 값이 5개인 "size" 필드로 패싯하는 경우 모든 일치 항목이 패싯 응답에 표시되도록 "count:5"를 설정할 수 있습니다.
이 해결 방법은 쿼리 대기 시간이 늘어나는 단점이 있으므로 꼭 필요한 경우에만 사용합니다.
프레젠테이션 계층
애플리케이션 코드에서 패턴은 패싯 쿼리 매개 변수를 사용하여 패싯 결과 및 $filter 식과 함께 패싯 탐색 구조를 반환합니다. 필터 식은 클릭 이벤트를 처리하고 패싯 선택에 따라 검색 결과의 범위를 더 좁혀 줍니다.
패싯 및 필터 조합
사용자가 직함 패싯에서 값을 선택하는 경우 NYCJobs 데모에서 JobsSearch.cs 파일의 다음 코드 조각은 선택된 직함을 필터에 추가합니다.
if (businessTitleFacet != "")
filter = "business_title eq '" + businessTitleFacet + "'";
호텔 샘플의 또 다른 예는 다음과 같습니다. 다음 코드 조각은 사용자가 범주 패싯에서 값을 선택하는 경우 categoryFacet을 필터에 추가합니다.
if (!String.IsNullOrEmpty(categoryFacet))
filter = $"category eq '{categoryFacet}'";
패싯 탐색용 HTML
NYCJobs 샘플 애플리케이션의 index.cshtml 파일에서 가져온 다음 예제는 검색 결과 페이지에 패싯 탐색을 표시하는 동적 HTML 구조를 표시합니다. 검색 용어를 제출하거나 패킷을 선택 또는 선택 취소하면 자동으로 패싯 목록이 작성되거나 다시 작성됩니다.
<div class="widget sidebar-widget jobs-filter-widget">
<h5 class="widget-title">Filter Results</h5>
<p id="filterReset"></p>
<div class="widget-content">
<h6 id="businessTitleFacetTitle">Business Title</h6>
<ul class="filter-list" id="business_title_facets">
</ul>
<h6>Location</h6>
<ul class="filter-list" id="posting_type_facets">
</ul>
<h6>Posting Type</h6>
<ul class="filter-list" id="posting_type_facets"></ul>
<h6>Minimum Salary</h6>
<ul class="filter-list" id="salary_range_facets">
</ul>
</div>
</div>
동적으로 HTML 빌드
index.cshtml(역시 NYCJobs 데모에서 가져옴)의 다음 코드 조각은 첫 번째 패싯인 직함을 표시하는 HTML을 동적으로 빌드합니다. 그와 유사한 기능은 다른 패싯에 대한 HTML을 동적으로 빌드합니다. 각 패싯에는 해당 패싯 결과에 대해 발견된 항목 수를 표시하는 레이블과 수가 있습니다.
function UpdateBusinessTitleFacets(data) {
var facetResultsHTML = '';
for (var i = 0; i < data.length; i++) {
facetResultsHTML += '<li><a href="javascript:void(0)" onclick="ChooseBusinessTitleFacet(\'' + data[i].Value + '\');">' + data[i].Value + ' (' + data[i].Count + ')</span></a></li>';
}
$("#business_title_facets").html(facetResultsHTML);
}
패싯 작업을 위한 팁
이 섹션은 도움이 될 수 있는 팁과 해결 방법을 모은 것입니다.
필터링된 결과와 비동기적으로 패싯 탐색 구조 유지
Azure AI 검색에서 패싯 탐색의 과제 중 하나는 패싯이 현재 결과에 대해서만 존재한다는 것입니다. 실제로 사용자가 역순으로 탐색하고 검색 콘텐츠를 통해 대체 경로를 탐색하는 단계를 거슬러 올라갈 수 있도록 정적 패싯 집합을 유지하는 것이 일반적입니다.
이것이 일반적인 사용 사례이지만, 현재 패싯 탐색 구조에는 기본적으로 제공되지 않습니다. 정적 패싯을 원하는 개발자는 일반적으로 두 개의 필터링된 쿼리를 실행하여 제한 사항을 해결합니다. 하나는 결과에 적용되고 다른 하나는 탐색 용도로 패싯의 정적 목록을 만드는 데 사용됩니다.
패싯 지우기
검색 결과 페이지를 디자인할 때 패싯을 지우는 메커니즘을 추가해야 합니다. 확인란을 추가하는 경우 필터를 지우는 방법을 쉽게 확인할 수 있습니다. 다른 레이아웃에는 이동 경로 탐색 패턴 또는 다른 창의적인 방법이 필요할 수 있습니다. 호텔 C# 샘플에서 빈 검색을 보내 페이지를 초기화할 수 있습니다. 반면 NYCJobs 샘플 애플리케이션은 선택한 패싯 뒤에 패싯을 지우는 클릭 가능한 [X] 패싯을 제공합니다. 이는 사용자에게 더 강력한 시각적 큐입니다.
추가 필터로 패싯 결과 자르기
패싯 결과는 패싯 용어와 일치하는 검색 결과에서 발견된 문서입니다. 다음 예제의 cloud computing에 대한 검색 결과에서 254개 항목은 콘텐츠 형식이 internal specification입니다. 항목은 상호 배타적이지 않을 수 있습니다. 하나의 항목이 두 필터 조건을 모두 충족하는 경우에는 각각 하나로 계수됩니다. 이 중복은 주로 문서 태깅을 구현하는 데 사용되는 Collection(Edm.String) 필드를 패싯할 때 발생합니다.
Search term: "cloud computing"
Content type
Internal specification (254)
Video (10)
일반적으로 패싯 결과가 지속적으로 너무 큰 경우에는 필터를 더 추가하여 사용자에게 검색 범위를 좁힐 수 있는 추가 옵션을 제공하는 것이 좋습니다.
패싯 전용 검색 환경
애플리케이션에서 검색 상자 없이 패싯 탐색만 사용하는 경우 필드를 searchable=false, filterable=true, facetable=true로 표시하여 보다 압축된 인덱스를 생성할 수 있습니다. 인덱스에는 반전된 인덱스가 포함되지 않으며 인덱싱 중에 텍스트 분석이나 토큰화가 수행되지 않습니다. 필터는 문자 수준에서 정확히 일치하는 항목에 대해 만들어집니다.
쿼리 시 입력 유효성 검사
신뢰할 수 없는 사용자 입력을 기반으로 패싯 목록을 동적으로 빌드하는 경우 패싯 필드의 이름이 올바른지 확인합니다. 또는 .NET에서 Uri.EscapeDataString()을 사용하거나 본인이 선택한 플랫폼에서 그에 상응하는 옵션을 사용하여 URL을 빌드할 때 이름을 이스케이프합니다.
샘플
패싯 탐색에는 다음 샘플을 권장합니다. 샘플에는 필터, 제안 및 자동 완성도 포함되어 있습니다. 이러한 샘플은 프레젠테이션 계층에 React를 사용합니다.