자습서 1: 관리되는 네트워크 격리를 사용하여 기능 집합 개발 및 등록
이 자습서 시리즈는 프로토타입 제작, 학습, 운영화 등 기계 학습 수명 주기의 모든 단계를 기능이 원활하게 통합하는 방법을 보여 줍니다.
Azure Machine Learning 관리 기능 저장소를 사용하여 기능을 검색, 만들기 및 운용할 수 있습니다. 기계 학습 수명 주기에는 다양한 기능을 실험하는 프로토타입 제작 단계가 포함됩니다. 또한 모델이 배포되고 유추 단계에서 기능 데이터를 찾는 운영화 단계도 포함됩니다. 기능은 기계 학습 수명 주기에서 결합 조직 역할을 합니다. 관리되는 네트워크 격리 기본 개념에 대해 자세히 알아보려면 관리되는 네트워크 격리란? 및 관리되는 네트워크 격리 리소스의 최상위 엔터티 이해에 대해 알아보세요.
이 자습서에서는 사용자 지정 변환을 사용하여 기능 집합 사양을 만드는 방법을 설명합니다. 그런 다음, 해당 기능 집합을 사용하여 학습 데이터를 생성하고, 구체화를 사용하도록 설정하고, 백필을 수행합니다. 구체화는 기능 기간의 기능 값을 계산한 다음, 해당 값을 구체화 저장소에 저장합니다. 그러면 모든 기능 쿼리는 구체화 저장소의 해당 값을 사용할 수 있습니다.
구체화가 없으면 기능 집합 쿼리는 값을 반환하기 전에 기능을 계산하기 위해 즉시 원본에 변환을 적용합니다. 이 프로세스는 프로토타이핑 단계에 적합합니다. 그러나 프로덕션 환경에서의 학습 및 유추 작업의 경우 안정성과 가용성을 높이기 위해 기능을 구체화하는 것이 좋습니다.
이 자습서는 관리되는 네트워크 격리 자습서 시리즈의 첫 번째 부분입니다. 여기서는 다음 방법을 알아봅니다.
- 새로운 최소 기능 저장소 리소스를 만듭니다.
- 기능 변환 기능을 사용하여 기능 집합을 개발하고 로컬에서 테스트합니다.
- 기능 저장소에 기능 저장소 엔터티를 등록합니다.
- 개발한 기능 집합을 기능 저장소에 등록합니다.
- 만든 기능을 사용하여 샘플 학습 DataFrame을 만듭니다.
- 기능 집합에서 오프라인 구체화를 사용하도록 설정하고 기능 데이터를 백필합니다.
이 자습서 시리즈에는 두 개의 추적이 있습니다.
- SDK 전용 추적은 Python SDK만 사용합니다. 순수 Python 기반 개발 및 배포를 위해서는 이 추적을 선택합니다.
- SDK 및 CLI 추적은 기능 집합 개발 및 테스트에만 Python SDK를 사용하고 CRUD(만들기, 읽기, 업데이트 및 삭제) 작업에는 CLI를 사용합니다. 이 추적은 CLI/YAML이 기본 설정되는 CI/CD(연속 통합 및 지속적인 업데이트) 또는 GitOps 시나리오에 유용합니다.
필수 조건
이 자습서를 진행하기 전에 다음 필수 조건을 충족해야 합니다.
Azure Machine Learning 작업 영역 작업 영역 만들기에 대한 자세한 내용은 빠른 시작: 작업 영역 리소스 만들기를 참조 하세요.
사용자 계정에서 기능 저장소가 만들어진 리소스 그룹에 대한 소유자 역할이 필요합니다.
이 자습서에 새 리소스 그룹을 사용하기로 선택한 경우 리소스 그룹을 삭제하면 모든 리소스를 쉽게 삭제할 수 있습니다.
Notebook 환경 준비
이 자습서에서는 개발을 위해 Azure Machine Learning Spark Notebook을 사용합니다.
Azure Machine Learning 스튜디오 환경의 왼쪽 창에서 Notebooks을 선택한 다음 샘플 탭을 선택합니다.
featurestore_sample 디렉터리(샘플>SDK v2>sdk>python>featurestore_sample 선택)로 이동한 다음 복제를 선택합니다.
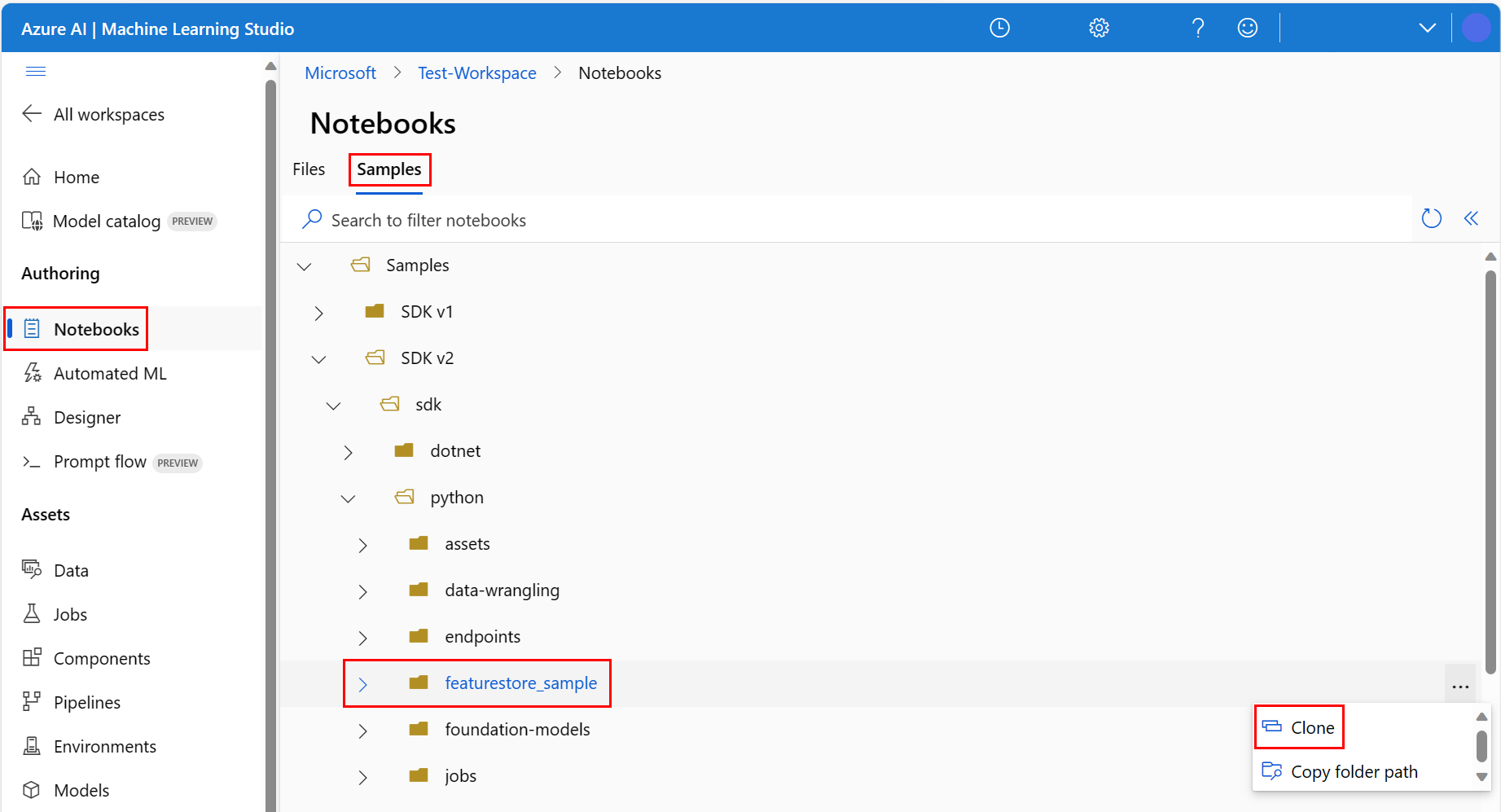
대상 디렉터리 선택 패널이 열립니다. 사용자 디렉터리를 선택한 다음, 사용자 이름을 선택하고 마지막으로 복제를 선택합니다.
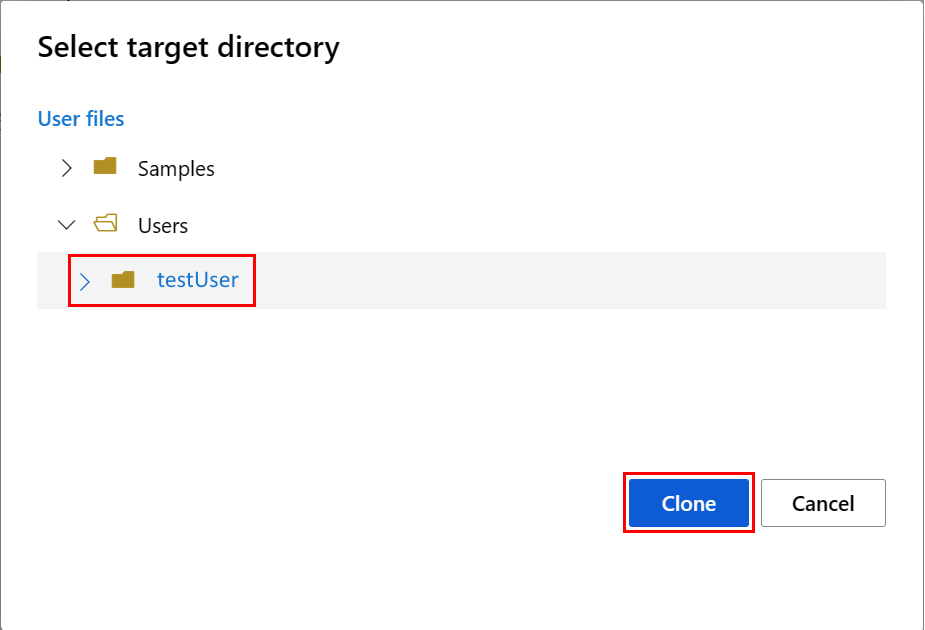
Notebook 환경을 구성하려면 conda.yml 파일을 업로드해야 합니다.
- 왼쪽 창에서 Notebooks를 선택한 다음 파일 탭을 선택합니다.
- env 디렉터리로 이동(사용자>your_user_name>featurestore_sample>프로젝트>env 선택)한 다음, conda.yml 파일을 선택합니다.
- 다운로드를 선택합니다.
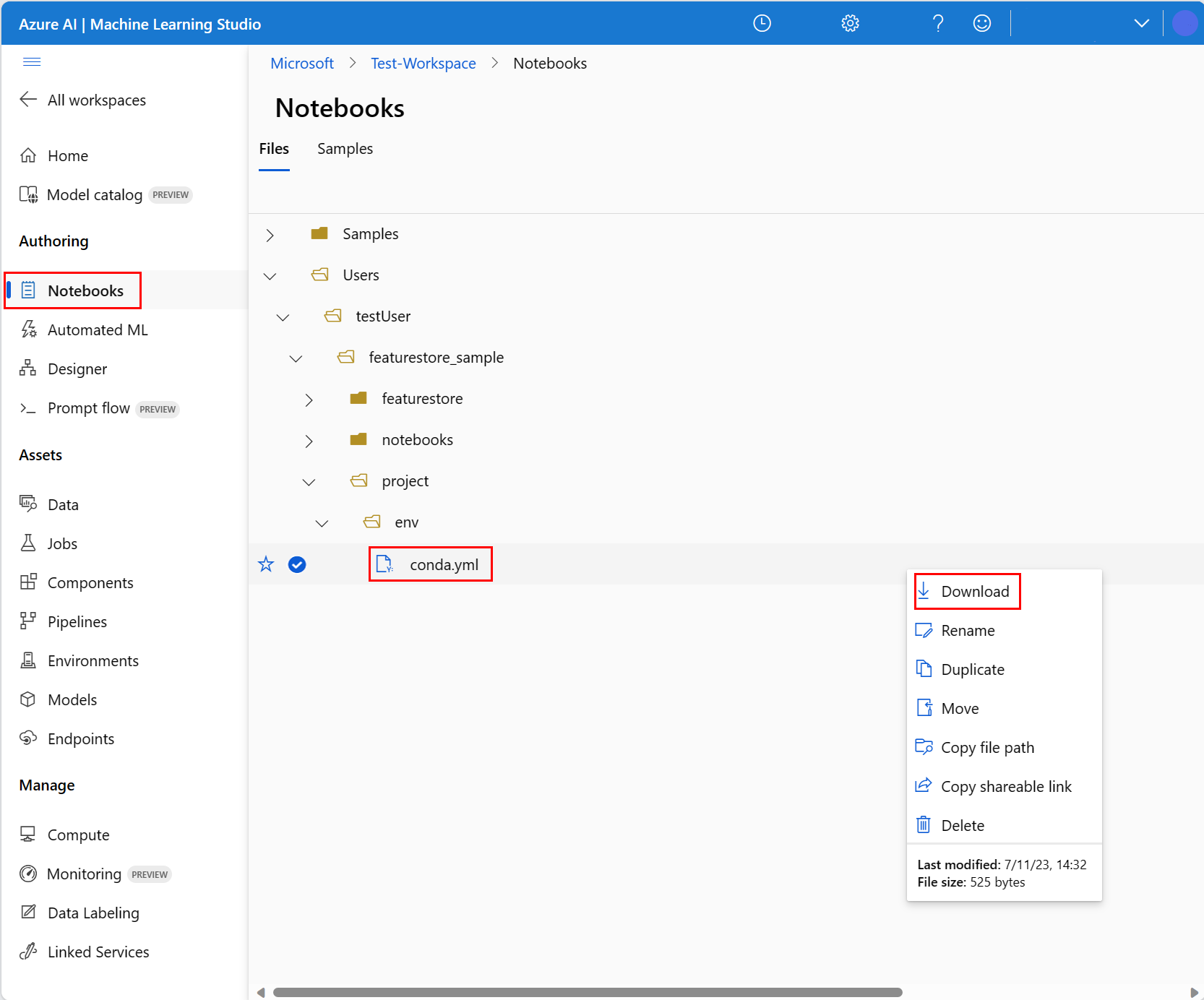
- 위쪽 탐색의 컴퓨팅 드롭다운에서 서버리스 Spark Compute를 선택합니다. 이 작업은 1~2분 정도 걸릴 수 있습니다. 상단 상태 표시줄이 구성 세션을 표시할 때까지 기다립니다.
- 상단 상태 표시줄에서 세션 구성을 선택합니다.
- Python 패키지를 선택합니다.
- Conda 파일 업로드를 선택합니다.
- 로컬 디바이스에서 다운로드한
conda.yml파일을 선택합니다. - (선택 사항) 서버리스 Spark 클러스터 시작 시간을 줄이기 위해 세션 시간 제한(분 단위 유휴 시간)을 늘릴 수 있습니다.
Azure Machine Learning 환경에서 Notebook을 열고 세션 구성을 선택합니다.
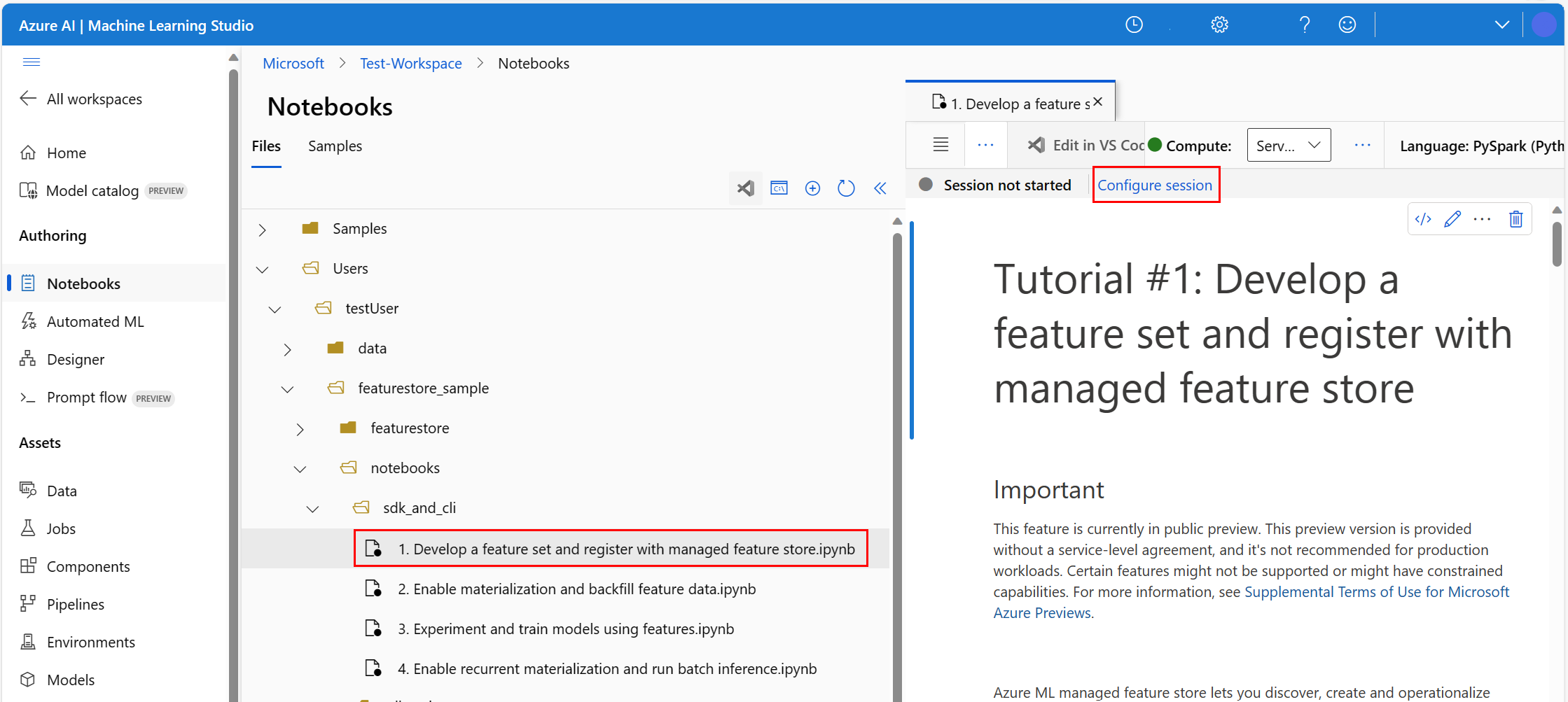
세션 구성 패널에서 Python 패키지를 선택합니다.
Conda 파일을 업로드합니다.
- Python 패키지 탭에서 Conda 파일 업로드를 선택합니다.
- Conda 파일을 호스팅하는 디렉터리를 찾습니다.
- conda.yml을 선택한 다음 열기를 선택합니다.
적용을 선택합니다.






Spark 세션 시작
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")샘플의 루트 디렉터리 설정
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")CLI 설정
해당 없음.
참고 항목
기능 저장소를 사용하여 프로젝트 전체에서 기능을 재사용합니다. 프로젝트 작업 영역(Azure Machine Learning 작업 영역)을 사용하면 기능 저장소의 기능을 활용하여 유추 모델을 학습할 수 있습니다. 많은 프로젝트 작업 영역이 동일한 기능 저장소를 공유하고 재사용할 수 있습니다.
이 자습서에서는 두 가지 SDK를 사용합니다.
기능 저장소 CRUD SDK
Azure Machine Learning 작업 영역에서 사용하는 것과 동일한
MLClient(패키지 이름azure-ai-ml) SDK를 사용합니다. 기능 저장소는 일종의 작업 영역으로 구현됩니다. 결과적으로 이 SDK는 기능 저장소, 기능 집합 및 기능 저장소 엔터티에 대한 CRUD 작업에 사용됩니다.기능 저장소 코어 SDK
이 SDK(
azureml-featurestore)는 기능 집합 개발 및 사용량을 위한 것입니다. 이 자습서의 이후 단계에서는 다음 작업을 설명합니다.- 기능 집합 사양을 개발합니다.
- 기능 데이터를 검색합니다.
- 등록된 기능 집합을 나열하거나 가져옵니다.
- 기능 검색 사양을 생성하고 해결합니다.
- 특정 시점 조인을 사용하여 학습 및 유추 데이터를 생성합니다.
이전 conda.yml 지침에서 이 단계를 다루었으므로 이 자습서에서는 해당 SDK를 명시적으로 설치할 필요가 없습니다.
최소 기능 저장소 만들기
이름, 위치, 기타 값을 포함한 기능 저장소 매개 변수를 설정합니다.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]기능 저장소를 만듭니다.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Azure Machine Learning용 기능 저장소 코어 SDK 클라이언트를 초기화합니다.
이 자습서의 앞부분에서 설명한 대로 기능 저장소 코어 SDK 클라이언트는 기능을 개발하고 사용하는 데 사용됩니다.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )기능 저장소에서 "Azure Machine Learning 데이터 과학자" 역할을 사용자 ID에 부여합니다. 사용자 개체 ID 찾기에 설명된 대로 Azure Portal에서 Microsoft Entra 개체 ID 값을 가져옵니다.
기능 저장소 작업 영역에서 리소스를 만들 수 있도록 AzureML 데이터 과학자 역할을 사용자 ID에 할당합니다. 사용 권한을 전파하는 데 약간의 시간이 필요할 수 있습니다.
액세스 제어에 대한 자세한 내용은 관리되는 네트워크 격리 리소스에 대한 액세스 제어 관리를 참조하세요.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
기능 집합 프로토타입 및 개발
다음 단계에서는 롤링 기간 집계 기반 기능이 있는 transactions라는 기능 집합을 빌드합니다.
transactions원본 데이터를 탐색합니다.이 Notebook은 공개적으로 액세스할 수 있는 Blob 컨테이너에 호스트된 샘플 데이터를 사용합니다.
wasbs드라이버를 통해서만 Spark로 읽을 수 있습니다. 자체 원본 데이터를 사용하여 기능 집합을 만드는 경우 Azure Data Lake Storage Gen2 계정에서 호스팅하고 데이터 경로에서abfss드라이버를 사용합니다.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted value기능 집합을 로컬에서 개발합니다.
기능 집합 사양은 로컬에서 개발하고 테스트할 수 있는 기능 집합의 독립적인 정의입니다. 여기서는 다음과 같은 롤링 창 집계 기능을 만듭니다.
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
기능 변환 코드 파일(featurestore/featuresets/transactions/transformation_code/transaction_transform.py)을 검토합니다. 기능에 대해 정의된 롤링 집계를 확인합니다. Spark 변환기입니다.
기능 집합 및 변환에 대해 자세히 알아보려면 관리되는 네트워크 격리 리소스를 방문하세요.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )기능 집합 사양으로 내보냅니다.
기능 집합 사양을 기능 저장소에 등록하려면 해당 사양을 특정 형식으로 저장해야 합니다.
생성된
transactions기능 집합 사양을 검토합니다. 파일 트리에서 이 파일을 열어 featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml 사양을 확인합니다.사양에는 다음 요소가 포함됩니다.
source: 스토리지 리소스에 대한 참조입니다. 이 경우 Blob Storage 리소스의 parquet 파일입니다.features: 기능 및 해당 데이터 형식의 목록입니다. 변환 코드를 제공하는 경우 코드는 기능 및 데이터 형식에 매핑되는 DataFrame을 반환해야 합니다.index_columns: 기능 집합의 값에 액세스하는 데 필요한 조인 키입니다.
사양에 대해 자세히 알아보려면 관리되는 네트워크 격리 및 CLI(v2) 기능 집합 YAML 스키마 리소스의 최상위 엔터티 이해에 방문하세요.
기능 집합 사양을 유지하면 또 다른 이점이 있습니다. 기능 집합 사양은 소스 제어를 지원합니다.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
기능 저장소 엔터티 등록
엔터티는 동일한 논리 엔터티를 사용하는 기능 집합에서 동일한 조인 키 정의를 사용하도록 강제 적용하는 것이 가장 좋습니다. 엔터티의 예로는 계정과 고객이 있습니다. 엔터티는 일반적으로 한 번 만들어진 다음 기능 집합 전체에서 재사용됩니다. 자세한 내용은 관리되는 네트워크 격리 최상위 엔터티 이해에 방문하세요.
기능 저장소 CRUD 클라이언트를 초기화합니다.
이 자습서
MLClient의 앞부분에서 설명한 대로 기능 저장소 자산을 만들고, 읽고, 업데이트하고, 삭제하는 데 사용됩니다. 여기에 표시된 Notebook 코드 셀 샘플은 이전 단계에서 만든 기능 저장소를 검색합니다. 여기서는 리소스 그룹 수준에서 범위가 지정되므로 이 자습서의 앞부분에서 사용한 것과 동일한ml_client값을 다시 사용할 수 없습니다. 적절한 범위 지정은 기능 저장소를 만들기 위한 필수 조건입니다.이 코드 샘플에서 클라이언트의 범위는 기능 저장소 수준으로 지정됩니다.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )기능 저장소에
account엔터티를 등록합니다.string형식의 조인 키accountID가 있는account엔터티를 만듭니다.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
기능 저장소에 트랜잭션 기능 집합을 등록합니다.
이 코드를 사용하여 기능 집합 자산을 기능 저장소에 등록합니다. 그런 다음 해당 자산을 재사용하고 쉽게 공유할 수 있습니다. 기능 집합 자산을 등록하면 버전 관리 및 구체화를 포함한 관리 기능이 제공됩니다. 이 자습서 시리즈의 이후 단계에서는 관리되는 기능을 다룹니다.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())기능 저장소 UI
기능 저장소 자산 만들기 및 업데이트는 SDK 및 CLI를 통해서만 발생할 수 있습니다. UI를 사용하여 기능 저장소를 검색하거나 찾아볼 수 있습니다.
- Azure Machine Learning 글로벌 방문 페이지를 엽니다.
- 왼쪽 창에서 기능 저장소를 선택합니다.
- 액세스 가능한 기능 저장소 목록에서 이 자습서의 앞부분에서 만든 기능 저장소를 선택합니다.
오프라인 스토리지의 사용자 계정에 Storage Blob 데이터 읽기 권한자 역할 액세스 권한을 부여합니다.
Storage Blob 데이터 판독기 역할은 오프라인 저장소의 사용자 계정에 할당되어야 합니다. 이렇게 하면 사용자 계정이 오프라인 구체화 저장소에서 구체화된 기능 데이터를 읽을 수 있습니다.
사용자 개체 ID 찾기에 설명된 대로 Azure Portal에서 Microsoft Entra 개체 ID 값을 가져옵니다.
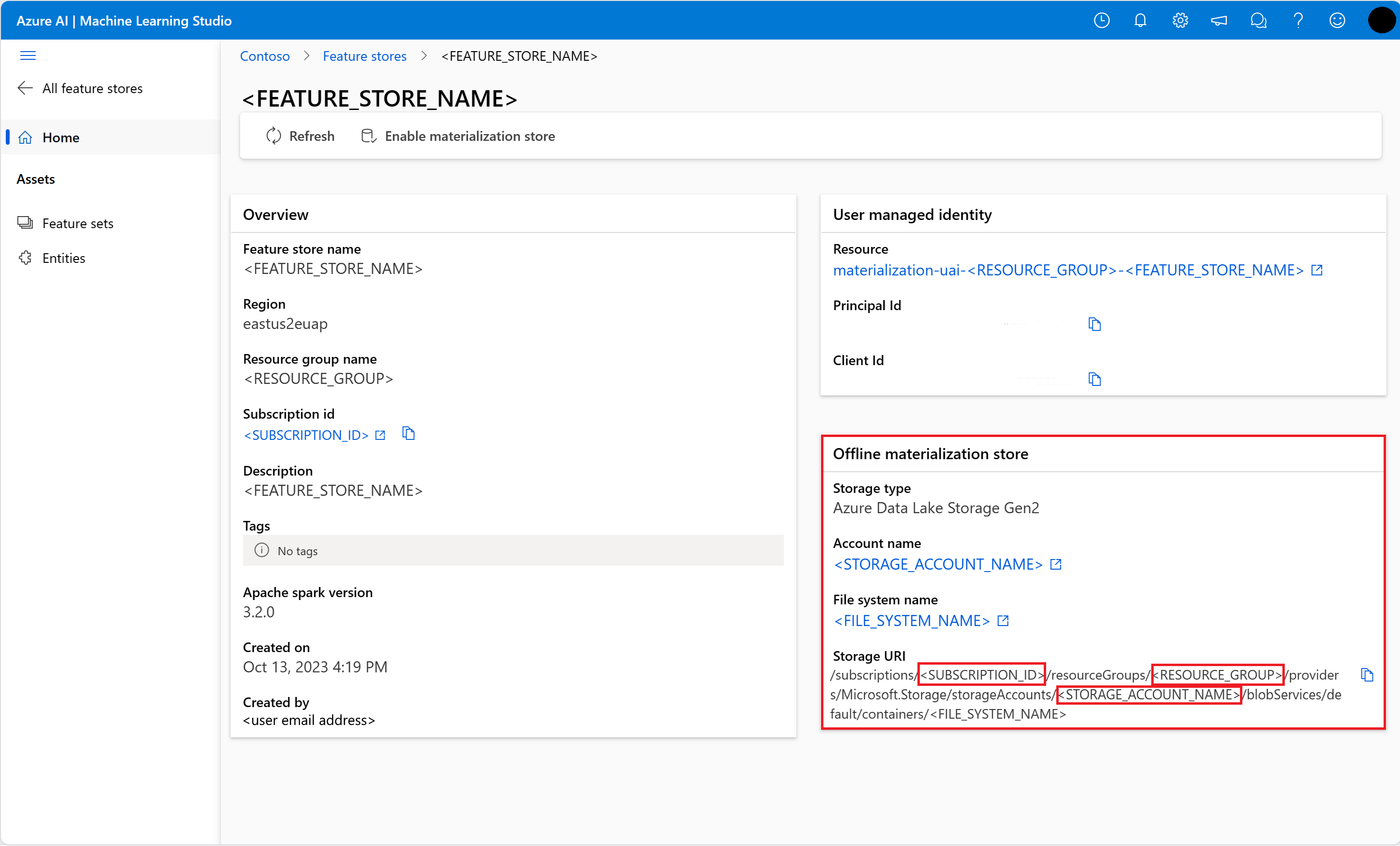
기능 저장소 UI의 기능 저장소 개요 페이지에서 오프라인 구체화 저장소에 대한 정보를 가져옵니다. 오프라인 구체화 저장소 카드에서 스토리지 계정 구독 ID, 스토리지 계정 리소스 그룹 이름 및 오프라인 구체화 저장소의 스토리지 계정 이름 값을 찾을 수 있습니다.
액세스 제어에 대한 자세한 내용은 관리되는 네트워크 격리 리소스에 대한 액세스 제어 관리를 참조하세요.
역할 할당을 위해 이 코드 셀을 실행합니다. 사용 권한을 전파하는 데 약간의 시간이 필요할 수 있습니다.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

등록된 기능 집합을 이용하여 학습 데이터 DataFrame을 생성합니다.
관측 데이터를 로드합니다.
관찰 데이터에는 일반적으로 학습 및 유추에 사용되는 코어 데이터가 포함됩니다. 이 데이터는 기능 데이터와 결합되어 전체 학습 데이터 리소스를 만듭니다.
관측 데이터는 이벤트 자체 중에 캡처된 데이터입니다. 여기에는 트랜잭션 ID, 계정 ID, 트랜잭션 금액 값을 포함한 코어 트랜잭션 데이터가 있습니다. 학습에 사용하기 때문에 대상 변수(is_fraud)도 추가됩니다.
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value등록된 기능 집합을 가져오고 해당 기능을 나열합니다.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))학습 데이터의 일부가 될 기능을 선택합니다. 그런 다음 기능 저장소 SDK를 사용하여 학습 데이터 자체를 생성합니다.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value특정 시점 조인은 학습 데이터에 기능을 추가합니다.
transactions 기능 집합에서 오프라인 구체화를 사용하도록 설정합니다.
기능 집합 구체화를 사용하도록 설정한 후에는 백필을 수행할 수 있습니다. 되풀이되는 구체화 작업을 예약할 수도 있습니다. 자세한 내용은 시리즈 리소스의 세 번째 자습서를 참조하세요.
기능 데이터 크기에 따라 yaml 파일에서 spark.sql.shuffle.partitions 설정
spark 구성 spark.sql.shuffle.partitions는 기능 집합이 오프라인 저장소로 구체화될 때 생성되는 parquet 파일 수(일별)에 영향을 줄 수 있는 OPTIONAL 매개 변수입니다. 이 매개 변수의 기본값은 200입니다. 모범 사례로, 작은 parquet 파일을 많이 생성하지 마십시오. 기능 집합 구체화 후 오프라인 기능 검색이 느려지면 오프라인 저장소의 해당 폴더로 이동하여 문제에 작은 parquet 파일(일별)이 너무 많은지 확인하고 이에 따라 이 매개 변수의 값을 조정합니다.
참고 항목
이 Notebook에 사용된 샘플 데이터는 작습니다. 따라서 이 매개 변수는 featureset_asset_offline_enabled.yaml 파일에서 1로 설정됩니다.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())기능 집합 자산을 YAML 리소스로 저장할 수도 있습니다.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)transactions 기능 집합의 백필 데이터
앞부분에서 설명했듯이 구체화는 기능 기간에 대한 기능 값을 계산하고 이러한 계산된 값을 구체화 저장소에 저장합니다. 기능 구체화는 계산된 값의 안정성과 가용성을 높입니다. 이제 모든 기능 쿼리는 구체화 저장소의 값을 사용합니다. 이 단계에서는 18개월의 기능 기간 동안 일회성 백필을 수행합니다.
참고 항목
백필 데이터 기간 값을 결정해야 할 수도 있습니다. 창은 학습 데이터의 창과 일치해야 합니다. 예를 들어 학습에 18개월의 데이터를 사용하려면 18개월 동안의 기능을 검색해야 합니다. 즉, 18개월 기간 동안 백필해야 합니다.
이 코드 셀은 정의된 기능 기간에 대한 현재 상태 None 또는 Incomplete에 따라 데이터를 구체화합니다.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])팁
timestamp열은yyyy-MM-ddTHH:mm:ss.fffZ형식을 따라야 합니다.feature_window_start_time및feature_window_end_time세분성은 초로 제한됩니다.datetime개체에 제공된 모든 밀리초는 무시됩니다.- 구체화 작업은 기능 기간의 데이터가 백필 작업을 제출하는 동안 정의된
data_status와 일치하는 경우에만 제출됩니다.
기능 집합에서 샘플 데이터를 인쇄합니다. 출력 정보에는 데이터가 구체화 저장소에서 검색되었음을 표시합니다. get_offline_features() 메서드는 학습 및 유추 데이터를 검색했습니다. 또한 기본적으로 구체화 저장소를 사용합니다.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))오프라인 기능 구체화에 대한 추가 탐색
구체화 작업 UI에서 기능 집합에 대한 기능 구체화 상태를 탐색할 수 있습니다.
왼쪽 창에서 기능 저장소를 선택합니다.
액세스 가능한 기능 저장소 목록에서 백필을 수행한 기능 저장소를 선택합니다.
구체화 작업 탭을 선택합니다.
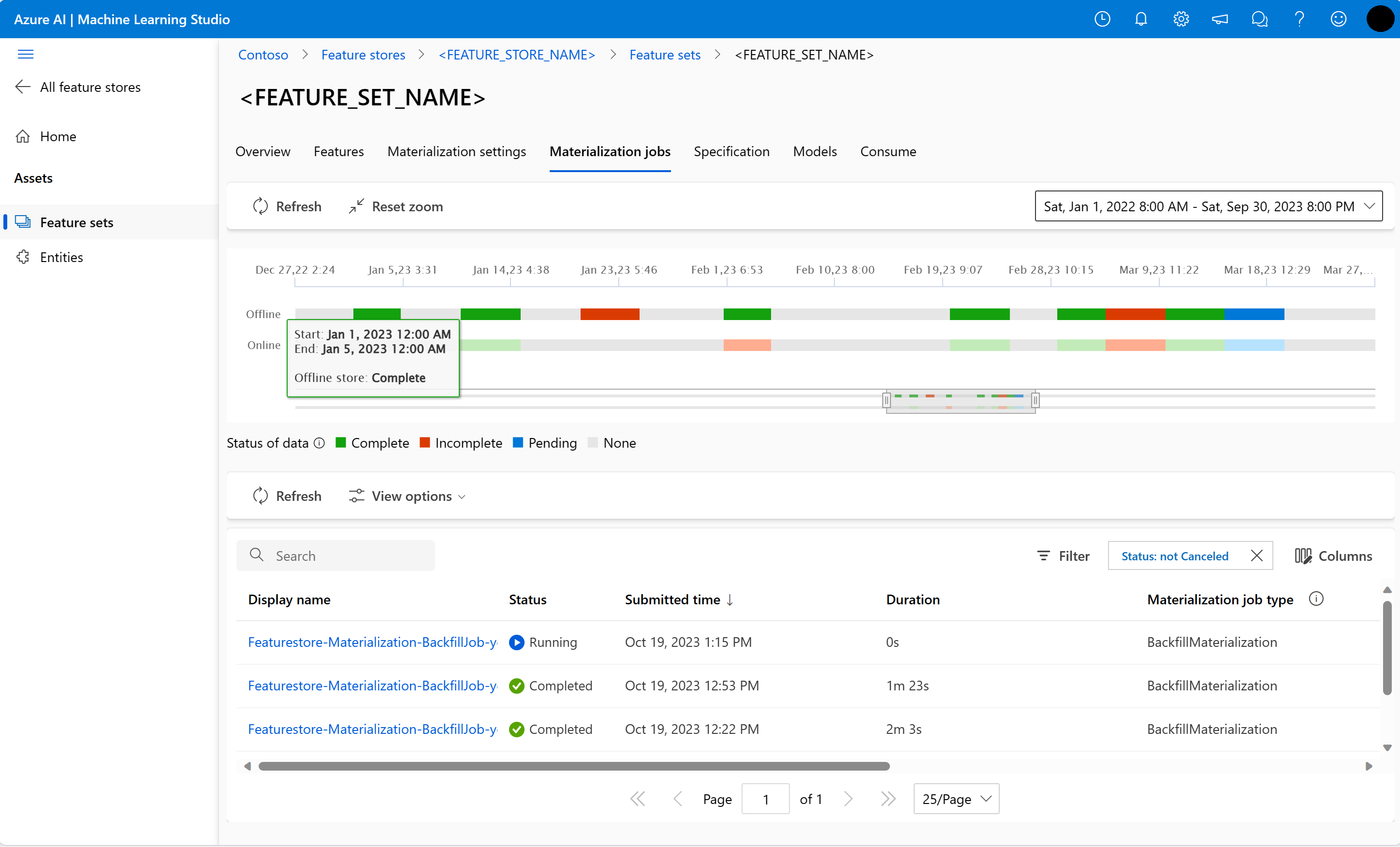

데이터 구체화 상태는 다음과 같습니다.
- 완료(녹색)
- 미완료(빨간색)
- 보류 중(파란색)
- 없음(회색)
데이터 간격은 동일한 데이터 구체화 상태를 가진 데이터의 연속 부분을 나타냅니다. 예를 들어 이전 스냅샷에는 오프라인 구체화 저장소에 16개의 데이터 간격이 있습니다.
데이터에는 최대 2,000개의 데이터 간격이 있을 수 있습니다. 데이터에 2,000개가 넘는 데이터 간격이 포함된 경우 새 기능 집합 버전을 만듭니다.
단일 백필 작업에서 둘 이상의 데이터 상태 목록(예:
["None", "Incomplete"])을 제공할 수 있습니다.백필하는 동안 정의된 기능 기간에 속하는 각 데이터 간격에 대해 새 구체화 작업이 제출됩니다.
구체화 작업이 보류 중이거나 아직 백필되지 않은 데이터 간격 동안 해당 작업이 실행 중인 경우 해당 데이터 간격 동안 새 작업이 제출되지 않습니다.
실패한 구체화 작업을 다시 시도할 수 있습니다.
참고 항목
실패한 구체화 작업의 작업 ID를 가져오려면 다음을 수행합니다.
- 기능 집합 구체화 작업 UI로 이동합니다.
- 상태가 실패인 특정 작업의 표시 이름을 선택합니다.
- 작업 개요 페이지에 있는 이름 속성 아래에서 작업 ID를 찾습니다.
Featurestore-Materialization-으로 시작합니다.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
오프라인 구체화 저장소 업데이트
- 오프라인 구체화 저장소를 기능 저장소 수준에서 업데이트해야 하는 경우 기능 저장소의 모든 기능 집합은 오프라인 구체화를 사용하지 않도록 설정되어 있어야 합니다.
- 기능 집합에서 오프라인 구체화를 사용하지 않도록 설정하면 오프라인 구체화 저장소에서 이미 구체화된 데이터의 구체화 상태가 다시 설정됩니다. 다시 설정은 이미 구체화된 데이터를 사용할 수 없게 렌더링합니다. 오프라인 구체화를 사용하도록 설정한 후 구체화 작업을 다시 제출해야 합니다.
이 자습서에서는 기능 저장소의 기능을 사용하여 학습 데이터를 빌드하고, 오프라인 기능 저장소로 구체화를 사용하도록 설정하고, 백필을 수행했습니다. 다음으로, 이러한 기능을 사용하여 모델 학습을 실행합니다.
정리
시리즈의 다섯 번째 자습서에서는 리소스를 삭제하는 방법을 설명합니다.
다음 단계
- 시리즈의 다음 자습서인 기능을 사용하여 모델 실험 및 학습을 참조하세요.
- 기능 저장소 개념 및 관리 기능 저장소의 최상위 항목에 대해 알아봅니다.
- 관리 기능 저장소에 대한 ID 및 액세스 제어에 대해 알아봅니다.
- 관리 기능 저장소 문제 해결 가이드를 확인합니다.
- YAML 참조를 확인합니다.