관리 기능 저장소의 최상위 엔터티 이해
이 문서에서는 관리 기능 저장소의 최상위 엔터티를 설명합니다.
관리되는 네트워크 격리 대한 자세한 내용은 관리되는 네트워크 격리 리소스를 방문하세요.
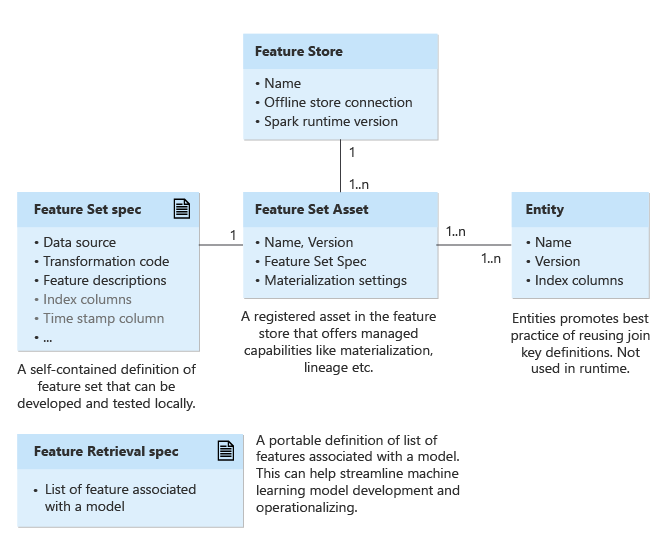
기능 저장소
기능 저장소를 통해 기능 집합을 만들고 관리할 수 있습니다. 기능 집합은 기능 컬렉션입니다. 필요에 따라 구체화 저장소(오프라인 저장소 연결)를 기능 저장소와 연결하여 기능을 정기적으로 사전 계산하고 유지할 수 있습니다. 이 방법을 사용하면 학습 또는 유추 중에 기능을 더 빠르고 안정적으로 검색할 수 있습니다.
구성에 대한 자세한 내용은 CLI(v2) 기능 저장소 YAML 스키마 리소스를 참조하세요.
엔터티
엔터티는 엔터프라이즈의 논리 엔터티에 대한 인덱스 열을 캡슐화합니다. 엔터티의 예로는 계정 엔터티, 고객 엔터티 등이 있습니다. 엔터티는 동일한 논리 엔터티를 사용하는 기능 집합에서 동일한 인덱스 열 정의를 사용하는 것이 가장 좋습니다.
엔터티는 일반적으로 한 번 만든 다음 기능 집합에서 다시 사용됩니다. 엔터티에는 버전이 지정됩니다.
구성에 대한 자세한 내용은 CLI(v2) 기능 엔터티 YAML 스키마 리소스를 참조하세요.
기능 집합 사양 및 자산
기능 집합은 원본 시스템 데이터에 대한 변환 애플리케이션에서 생성된 기능의 컬렉션입니다. 함수 집합은 원본, 변환 함수 및 구체화 설정을 캡슐화합니다. 현재 PySpark 기능 변환 코드를 지원합니다.
먼저 기능 집합 사양을 만듭니다. 기능 집합 사양은 로컬에서 개발하고 테스트할 수 있는 기능 집합의 독립적인 정의입니다.
기능 집합 사양은 일반적으로 다음 매개 변수로 구성됩니다.
source: 이 기능은 어떤 원본에 매핑되나요?transformation(선택 사항): 기능을 만들기 위해 원본 데이터에 적용되는 변환 논리입니다. 당사의 경우 지원되는 컴퓨팅으로 Spark를 사용합니다.index_columns및timestamp_column을 나타내는 열의 이름: 이 이름은 사용자가 기능 데이터를 관측 데이터와 조인하려고 할 때 필요합니다(나중에 자세히 설명).materialization_settings(선택 사항): 효율적인 검색을 위해 구체화 저장소에 기능 값을 캐시하려는 경우 필요합니다.
로컬/개발 환경에서 기능 집합 사양을 개발하고 테스트한 후 기능 저장소에 기능 집합 자산으로 사양을 등록할 수 있습니다. 기능 집합 자산은 관리되는 기능(예: 버전 관리 및 구체화)을 제공합니다.
기능 집합 YAML 사양에 대한 자세한 내용은 CLI(v2) 기능 집합 사양 YAML 스키마 리소스를 참조하세요.
기능 검색 사양
기능 검색 사양은 모델과 연결된 기능 목록의 이식 가능한 정의입니다. 이는 기계 학습 모델 개발 및 운영을 간소화하는 데 도움이 될 수 있습니다. 기능 검색 사양은 일반적으로 학습 파이프라인에 대한 입력입니다. 학습 데이터를 생성하는 데 도움이 됩니다. 모델을 사용하여 패키지할 수 있습니다. 또한 유추 단계에서는 이 단계를 사용하여 기능을 조회합니다. 이는 기계 학습 수명 주기의 모든 단계를 통합합니다. 실험하고 배포하는 동안 학습 및 유추 파이프라인에 대한 변경 내용을 최소화할 수 있습니다.
기능 검색 사양 및 기본 제공 기능 검색 구성 요소의 사용은 선택 사항입니다. 원하는 경우 get_offline_features() API를 직접 사용할 수 있습니다.
기능 검색 YAML 사양에 대한 자세한 내용은 CLI(v2) 기능 검색 사양 YAML 스키마 리소스를 참조하세요.