Linux 기반 HDInsight에서 Apache Hadoop 서비스에 힙 덤프 사용
힙 덤프는 덤프가 만들어질 당시의 변수 값을 비롯해 애플리케이션의 메모리에 대한 스냅샷을 포함합니다. 따라서 런타임에 발생하는 문제를 진단하는 데 유용합니다.
Services
다음 서비스에 힙 덤프를 사용할 수 있습니다.
- Apache hcatalog - tempelton
- Apache hive - hiveserver2, metastore, derbyserver
- mapreduce - jobhistoryserver
- Apache yarn - resourcemanager, nodemanager, timelineserver
- Apache hdfs - datanode, secondarynamenode, namenode
HDInsight에서 실행하는 map 및 reduce프로세스에 힙 덤프를 사용할 수도 있습니다.
힙 덤프 구성 이해
힙 덤프를 사용하려면 서비스를 시작할 때 JVM으로 옵션(opts 또는 매개 변수라고도 함)을 전달합니다. 대부분의 Apache Hadoop 서비스에서는 서비스를 시작하는 데 사용하는 셸 스크립트를 수정하여 이러한 옵션을 생략할 수 있습니다.
각 스크립트에는 JVM으로 전달된 옵션을 포함하는 *_OPTS 내보내기가 있습니다. 예를 들어 hadoop-env.sh 스크립트에는 export HADOOP_NAMENODE_OPTS=로 시작하는 줄에 NameNode 서비스에 대한 옵션이 포함되어 있습니다.
map 프로세스와 reduce 프로세스는 MapReduce 서비스의 자식 프로세스이므로 서로 약간 다른 작업입니다. 각 map 또는 reduce 프로세스는 자식 컨테이너에서 실행되며, JVM 옵션이 포함된 두 가지 항목이 있습니다. mapred-site.xml에 포함된 두 항목은 다음과 같습니다.
- mapreduce.admin.map.child.java.opts
- mapreduce.admin.reduce.child.java.opts
참고 항목
Ambari는 클러스터의 노드 간에 변경 내용 복제를 처리하므로 Apache Ambari를 사용하여 스크립트 및 mapred-site.xml 설정을 모두 수정하는 것이 좋습니다. 구체적인 단계는 Apache Ambari 사용 섹션을 참조하세요.
힙 덤프 사용
다음 옵션은 OutOfMemoryError가 발생한 경우 힙 덤프를 사용하도록 설정합니다.
-XX:+HeapDumpOnOutOfMemoryError
+는 이 옵션을 사용하도록 설정했음을 나타냅니다. 기본값은 사용 안 함입니다.
Warning
덤프 파일은 용량이 클 수 있기 때문에 HDInsight의 Hadoop 서비스에는 기본적으로 힙 덤프가 사용되지 않습니다. 문제 해결을 위해 사용하도록 설정한 경우에는 문제를 재현하고 덤프 파일을 수집한 후 사용하지 않도록 설정해야 합니다.
덤프 위치
덤프 파일의 기본 위치는 현재 작업 디렉터리입니다. 다음 옵션을 사용하여 파일이 저장되는 위치를 제어할 수 있습니다.
-XX:HeapDumpPath=/path
예를 들어 -XX:HeapDumpPath=/tmp를 사용하면 덤프가 /tmp 디렉터리에 저장됩니다.
스크립트
OutOfMemoryError 가 발생한 경우 스크립트를 트리거할 수도 있습니다. 예를 들어 오류가 발생했음을 알 수 있도록 알림을 트리거할 수 있습니다. OutOfMemoryError에서 스크립트를 트리거하려면 다음 옵션을 사용합니다.
-XX:OnOutOfMemoryError=/path/to/script
참고 항목
Apache Hadoop은 분산 시스템이므로 사용되는 모든 스크립트는 서비스가 실행되는 클러스터의 모든 노드에 배치되어야 합니다.
또한 스크립트는 서비스 실행 계정에서 액세스할 수 있는 위치에 있어야 하며, 실행 권한을 제공해야 합니다. 예를 들어 /usr/local/bin에 스크립트를 저장하고 chmod go+rx /usr/local/bin/filename.sh를 사용하여 읽기 및 실행 권한을 부여할 수 있습니다.
Apache Ambari 사용
서비스에 대한 구성을 수정하려면 다음 단계를 사용합니다.
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net로 이동합니다. 여기서CLUSTERNAME은 클러스터의 이름입니다.왼쪽의 목록을 사용하여 수정할 서비스 영역을 선택합니다. 예를 들어 HDFS를 선택합니다. 가운데 영역에서 Configs 탭을 선택합니다.

Filter... 항목에 opts를 입력합니다. 이 텍스트가 포함된 항목만 표시됩니다.
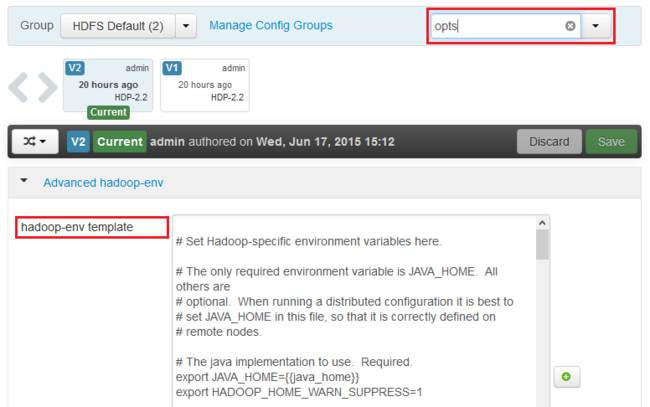
힙 덤프를 사용할 서비스에 대한 *_OPTS 항목을 찾아서 사용할 옵션을 추가합니다. 다음 이미지에서는 HADOOP_NAMENODE_OPTS 항목에
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/를 추가했습니다.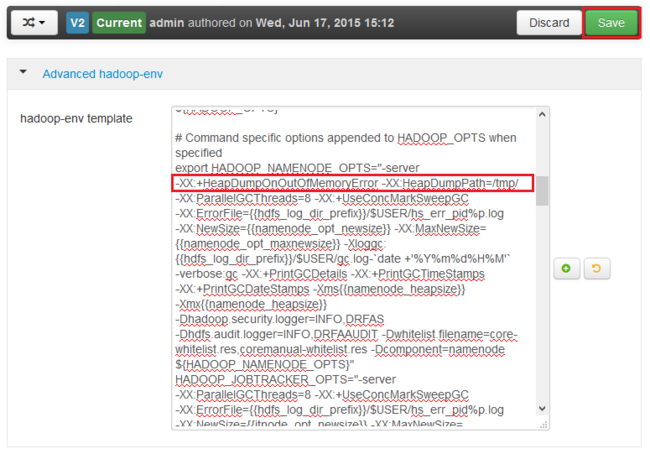
참고 항목
map 또는 reduce 자식 프로세스에 힙 덤프를 사용할 경우 mapreduce.admin.map.child.java.opts 및 mapreduce.admin.reduce.child.java.opts 필드를 찾습니다.
Save 단추를 사용하여 변경 내용을 저장합니다. 변경 내용을 설명하는 간단한 메모를 입력할 수 있습니다.
변경 내용이 적용되면 하나 이상의 서비스 옆에 다시 시작 필요 아이콘이 표시됩니다.
다시 시작해야 하는 각 서비스를 선택하고 Service Actions 단추를 사용하여 Turn On Maintenance Mode를 지정합니다. 유지 관리 모드에서는 다시 시작할 때 서비스에서 경고가 표시되지 않습니다.
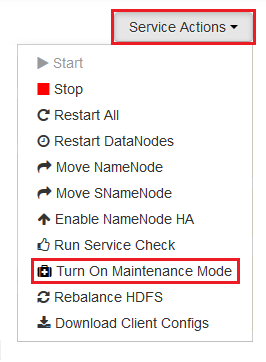
유지 관리 모드를 설정한 후에는 Restart 단추를 사용하여 서비스에 대해 Restart All Effected를 지정합니다.
참고 항목
Restart 단추의 항목은 서비스마다 다를 수 있습니다.
서비스가 다시 시작되면 Service Actions 단추를 사용하여 Turn Off Maintenance Mode를 지정합니다. 그러면 Ambari에서 서비스에 대한 경고 모니터링을 재개합니다.