Azure Stack Edge Pro에서 GPU 공유를 사용하여 IoT Edge 워크로드 배포
이 문서에서는 컨테이너화된 워크로드가 Azure Stack Edge Pro GPU 디바이스에서 GPU를 공유하는 방법을 설명합니다. 이 방법에는 MPS(다중 프로세스 서비스)를 사용 하도록 설정한 후 IoT Edge 배포를 통해 GPU 워크로드를 지정하는 작업이 포함됩니다.
필수 조건
시작하기 전에 다음 사항을 확인합니다.
활성화되고 컴퓨팅이 구성된 Azure Stack Edge Pro GPU 디바이스에 액세스했습니다. Kubernetes API 엔드포인트가 있으며 디바이스에 액세스하는 클라이언트의
hosts파일에 해당 엔드포인트를 추가했습니다.지원되는 운영 체제를 통해 클라이언트 시스템에 액세스했습니다. Windows 클라이언트를 사용하는 경우 시스템은 PowerShell 5.0 이상을 실행하여 디바이스에 액세스해야 합니다.
로컬 시스템에 다음 배포
json을 저장합니다. 이 파일의 정보를 사용하여 IoT Edge 배포를 실행합니다. 이 배포는 NVIDIA에서 공개적으로 사용할 수 있는 단순 CUDA 컨테이너를 기반으로 합니다.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
GPU 드라이버, CUDA 버전 확인
첫 번째 단계는 필요한 GPU 드라이버 및 UDA 버전이 디바이스에서 실행되고 있는지 확인하는 것입니다.
다음 명령을 실행합니다.
Get-HcsGpuNvidiaSmiNVIDIA smi 출력에서 디바이스의 GPU 버전 및 CUDA 버전을 기록해 둡다. Azure Stack Edge 2102 소프트웨어를 실행하는 경우 이 버전은 다음의 드라이버 버전에 해당합니다.
- GPU 드라이버 버전: 460.32.03
- CUDA 버전: 11.2
출력의 예제는 다음과 같습니다.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>이 세션을 사용하여 문서 전체에서 NVIDIA smi 출력을 볼 수 있으므로 이 세션을 열어 둡니다.
컨텍스트 공유가 없는 배포
이제 다중 프로세스 서비스가 실행 중인 상태가 아니며 컨텍스트 공유가 없는 경우 디바이스에 애플리케이션을 배포할 수 있습니다. 배포는 디바이스에 있는 iotedge 네임스페이스의 Azure Portal을 통해 배포됩니다.
IoT Edge 네임스페이스에서 사용자 만들기
먼저 iotedge 네임스페이스에 연결할 사용자를 만듭니다. IoT Edge 모듈은 iotedge 네임스페이스에 배포됩니다. 자세한 내용은 디바이스의 Kubernetes 네임스페이스를 참조하세요.
사용자를 만들고 사용자에게 iotedge 네임스페이스에 대한 액세스 권한을 부여하려면 다음 단계를 수행합니다.
iotedge네임스페이스에 새 사용자를 만듭니다. 다음 명령을 실행합니다.New-HcsKubernetesUser -UserName <user name>출력의 예제는 다음과 같습니다.
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=일반 텍스트로 표시된 출력을 복사합니다. 로컬 컴퓨터에서 사용자 프로필의
.kube폴더에 config 파일(확장명 없음)로 출력을 저장합니다(예:C:\Users\<username>\.kube).만든 사용자에
iotedge네임스페이스에 대한 액세스 권한을 부여합니다. 다음 명령을 실행합니다.Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>출력의 예제는 다음과 같습니다.
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
자세한 지침은 Azure Stack Edge PRO GPU 디바이스에서 kubectl을 통해 Kubernetes 클러스터에 연결 및 관리를 참조하세요.
포털을 통해 모듈 배포
Azure Portal을 통해 IoT Edge 모듈 배포 n-body 시뮬레이션을 실행하는 공개적으로 사용 가능한 NVIDIA CUDA 샘플 모듈을 배포합니다.
IoT Edge 서비스가 디바이스에서 실행되고 있어야 합니다.
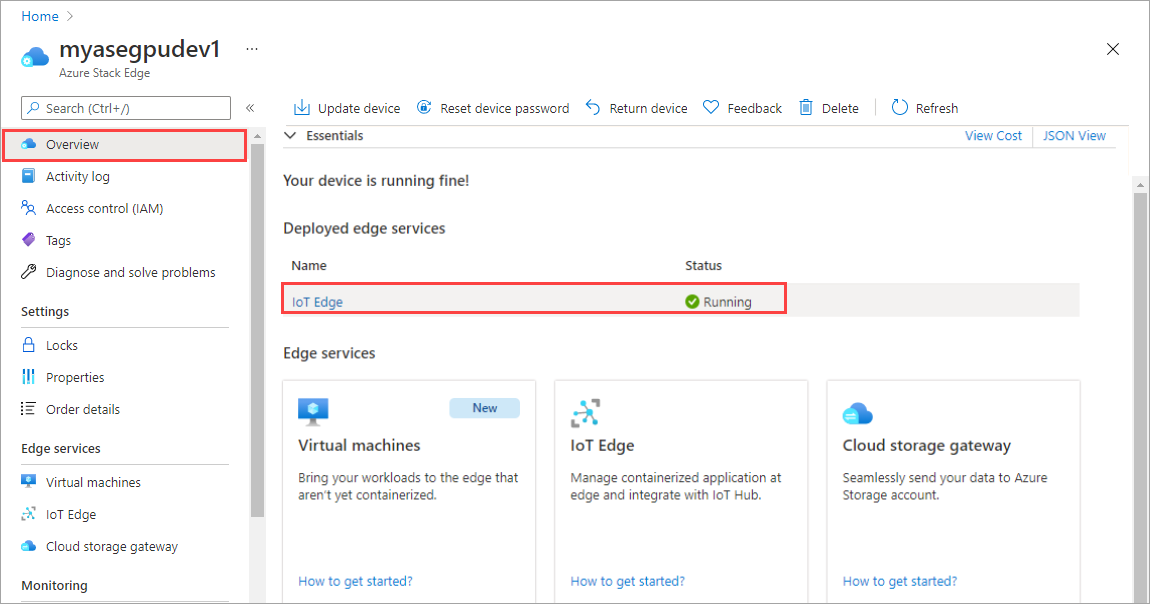
오른쪽 창에서 IoT Edge 타일을 선택합니다. IoT Edge > 속성으로 이동합니다. 오른쪽 창에서 디바이스와 연결된 IoT Hub 리소스를 선택합니다.
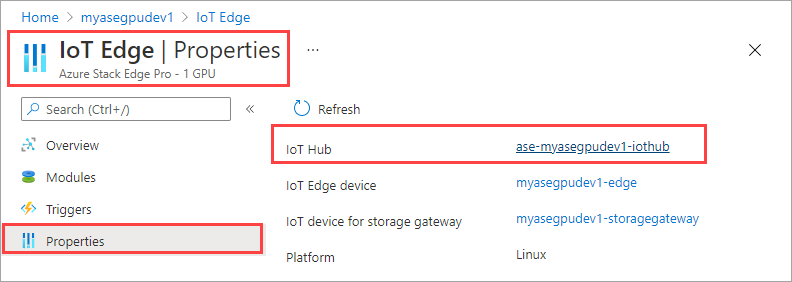
IoT Hub 리소스에서 자동 장치 관리 > IoT Edge로 이동합니다. 오른쪽 창에서 디바이스와 연결된 IoT Edge 디바이스를 선택합니다.
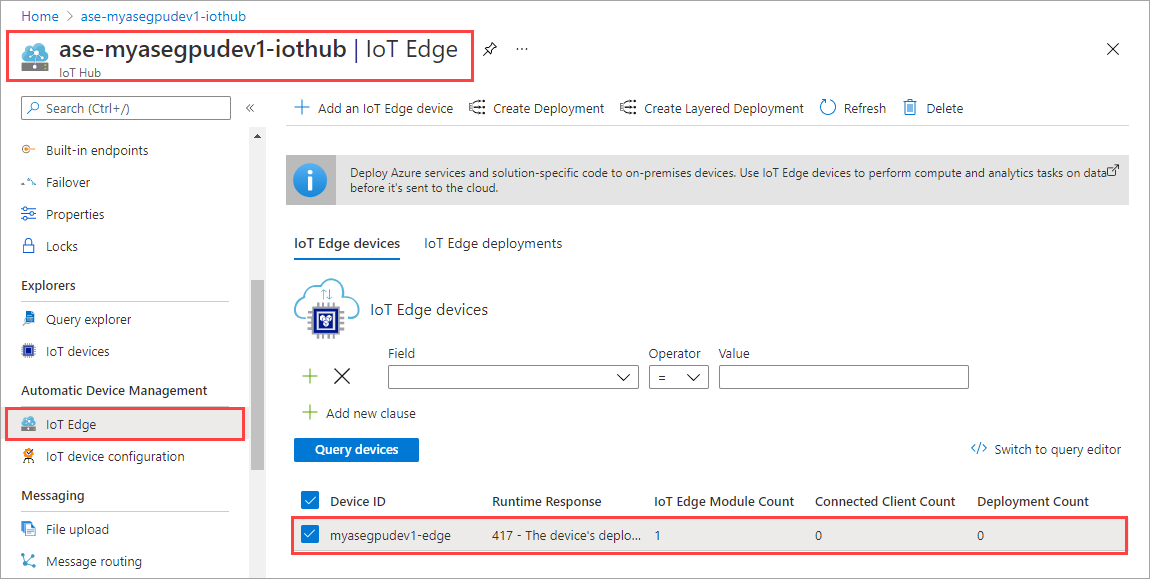
모듈 설정을 선택합니다.
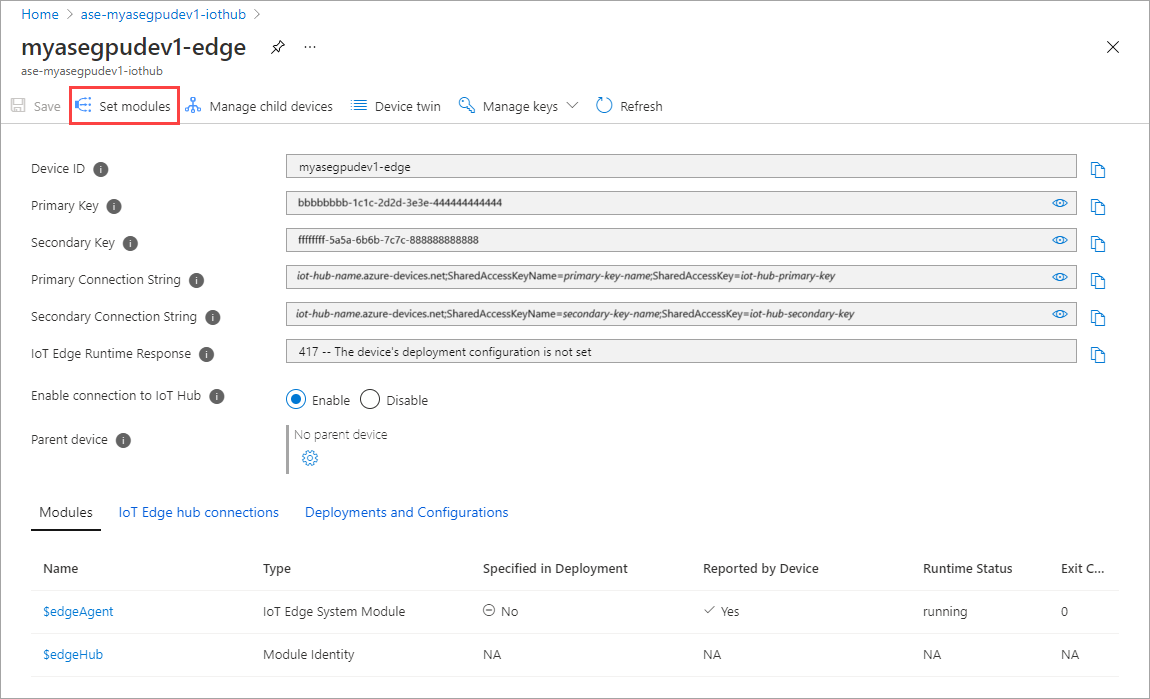
+ 추가 > + IoT Edge 모듈을 선택합니다.
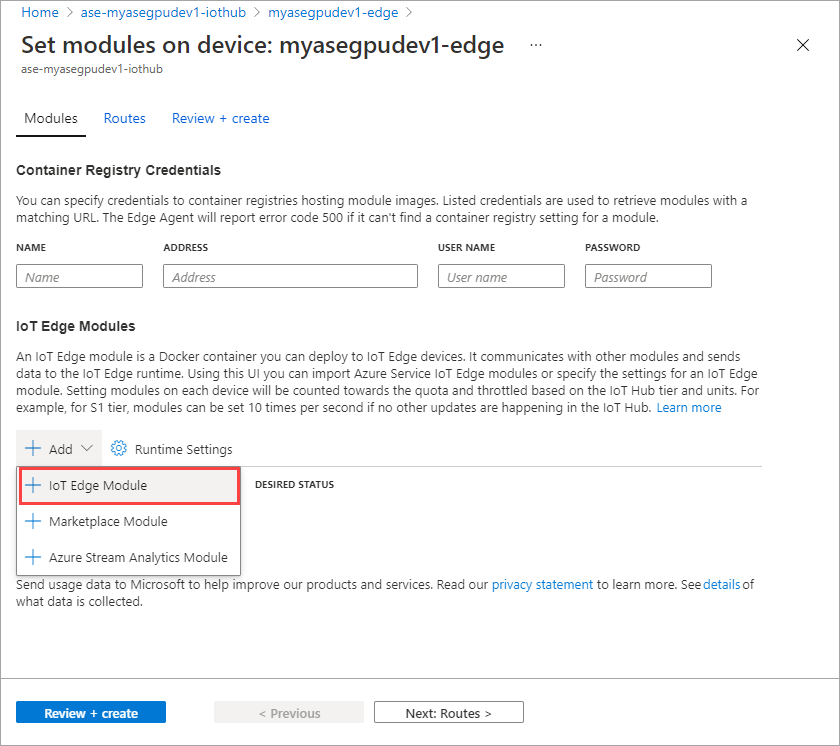
모듈 설정 탭에 IoT Edge 모듈 이름과 이미지 URI를 입력합니다. 이미지 끌어오기 정책을 생성 시로 설정합니다.
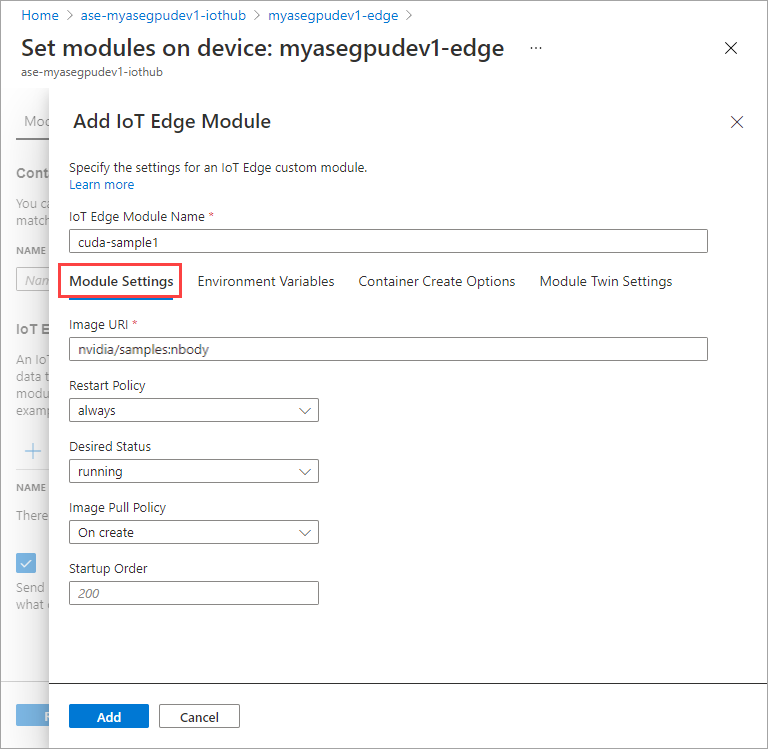
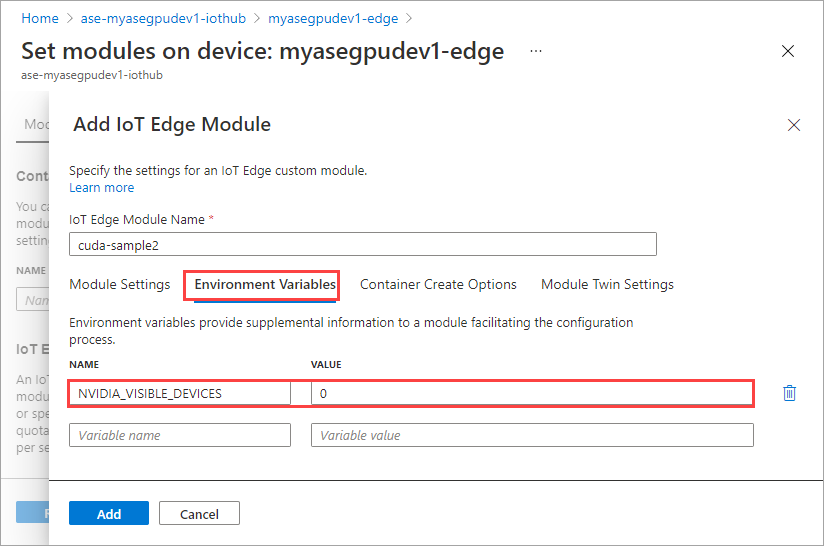
환경 변수 탭에서 NVIDIA_VISIBLE_DEVICES 를 0으로 지정합니다.
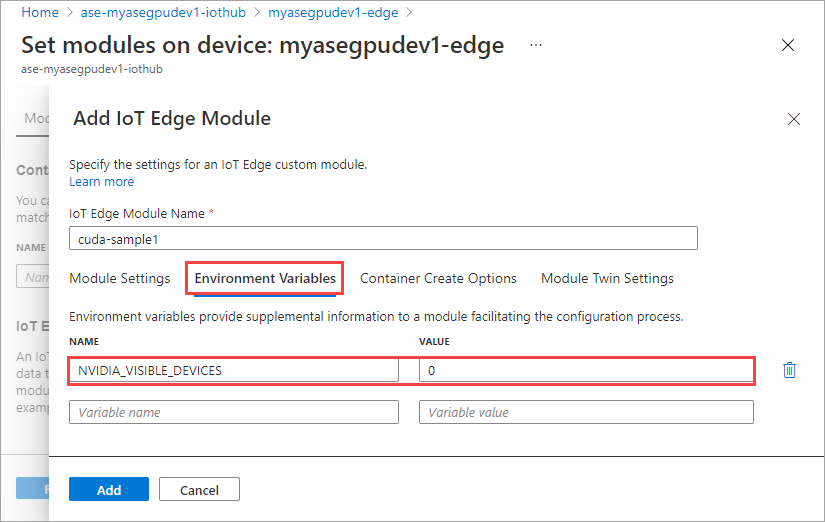
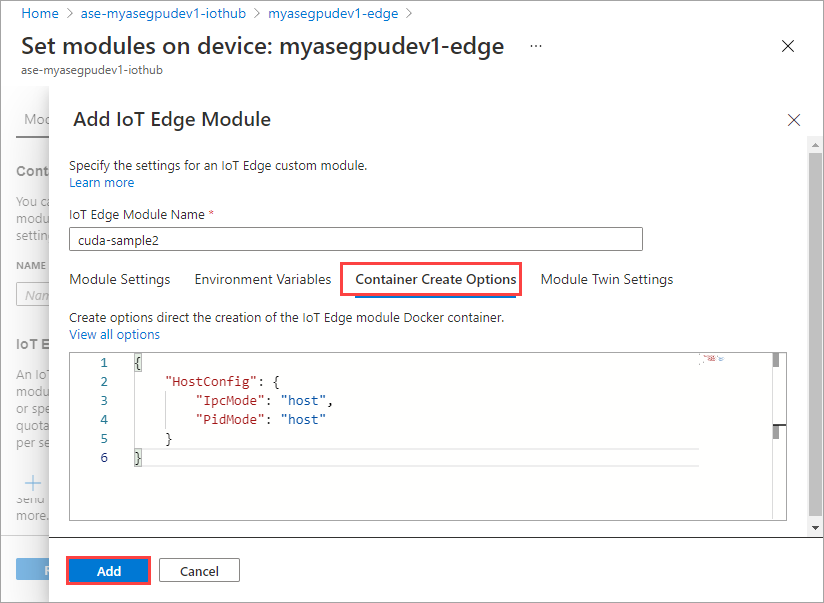
컨테이너 만들기 옵션 탭에 다음 옵션을 제공합니다.
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }옵션은 다음과 같이 표시됩니다.
추가를 선택합니다.
추가한 모듈은 실행 중으로 표시되어야 합니다.
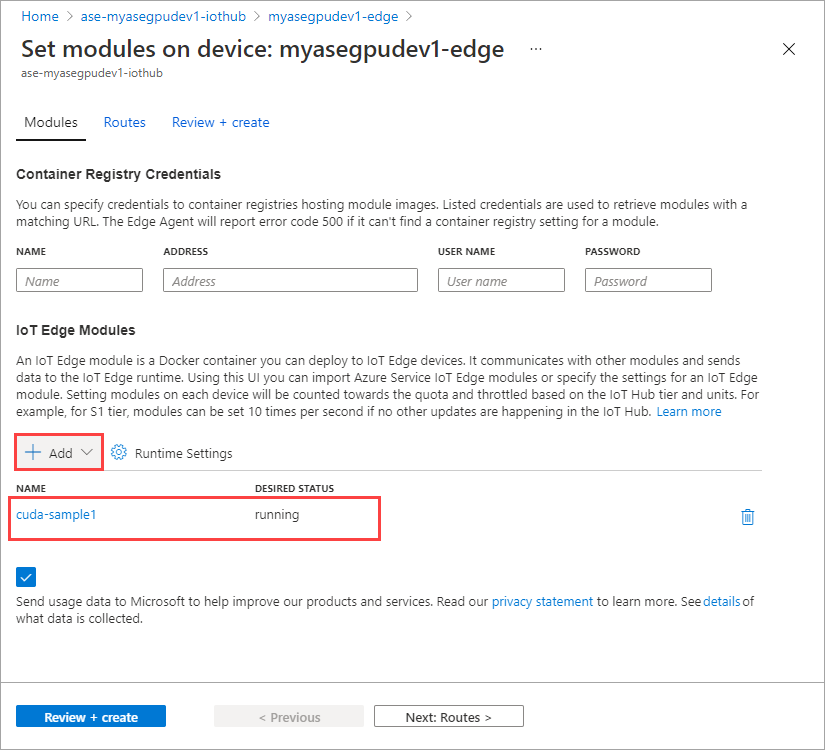
첫 번째 모듈을 추가할 때 수행한 모듈을 추가하려면 모든 단계를 반복합니다. 이 예제에서는 모듈 이름을
cuda-sample2로 제공합니다.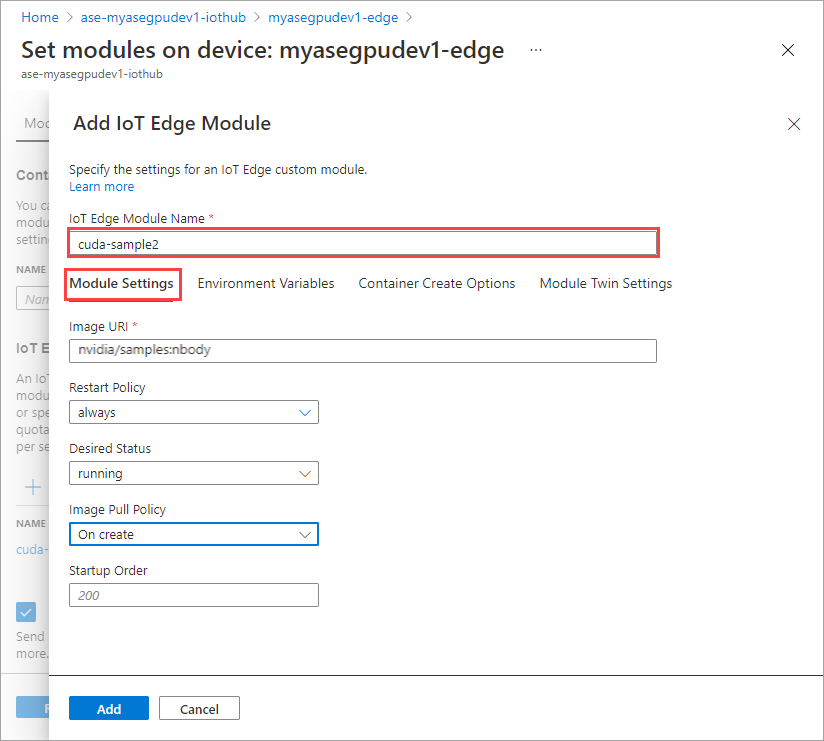
두 모듈이 같은 GPU를 공유하므로 동일한 환경 변수를 사용합니다.
첫 번째 모듈에 제공한 것과 동일한 컨테이너 만들기 옵션을 사용하고 추가를 선택합니다.
모듈 설정 페이지에서 검토 + 만들기를 선택한 다음, 만들기를 선택합니다.
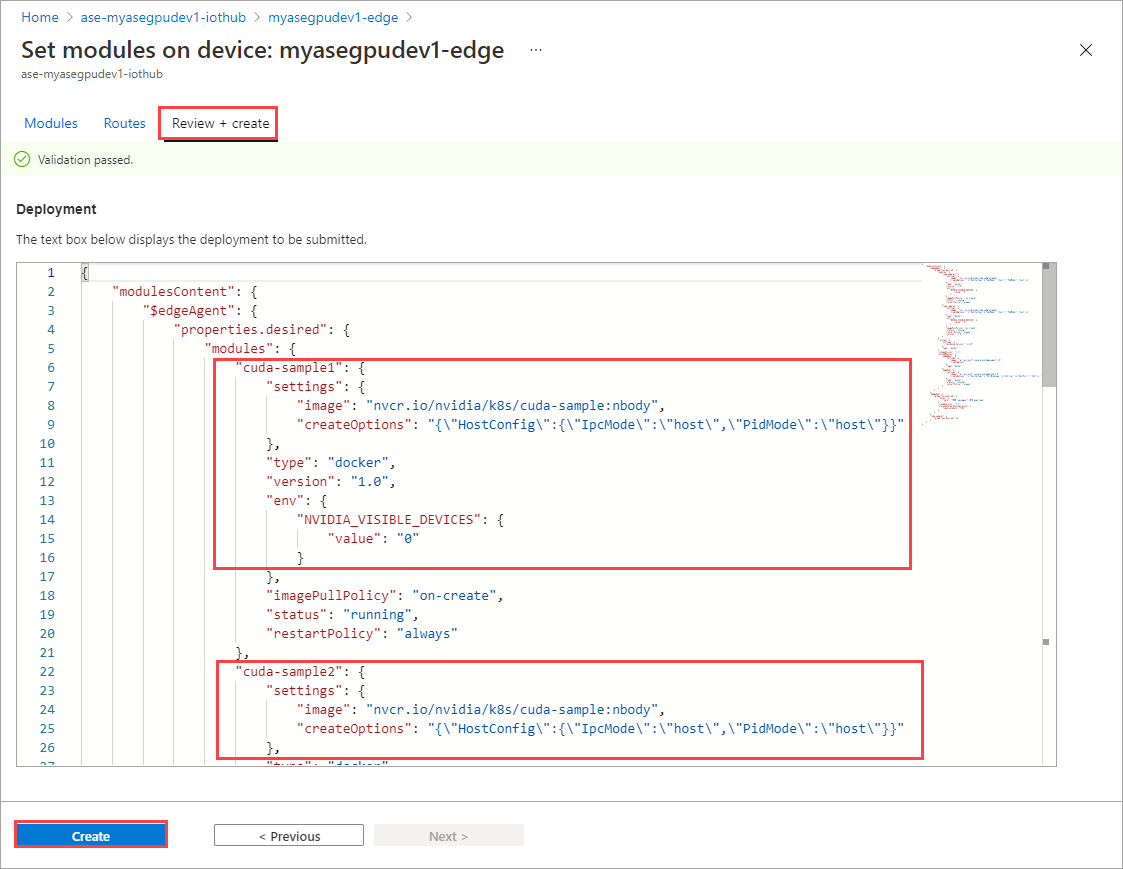
이제 두 모듈의 런타임 상태가 실행 중으로 표시되어야 합니다.
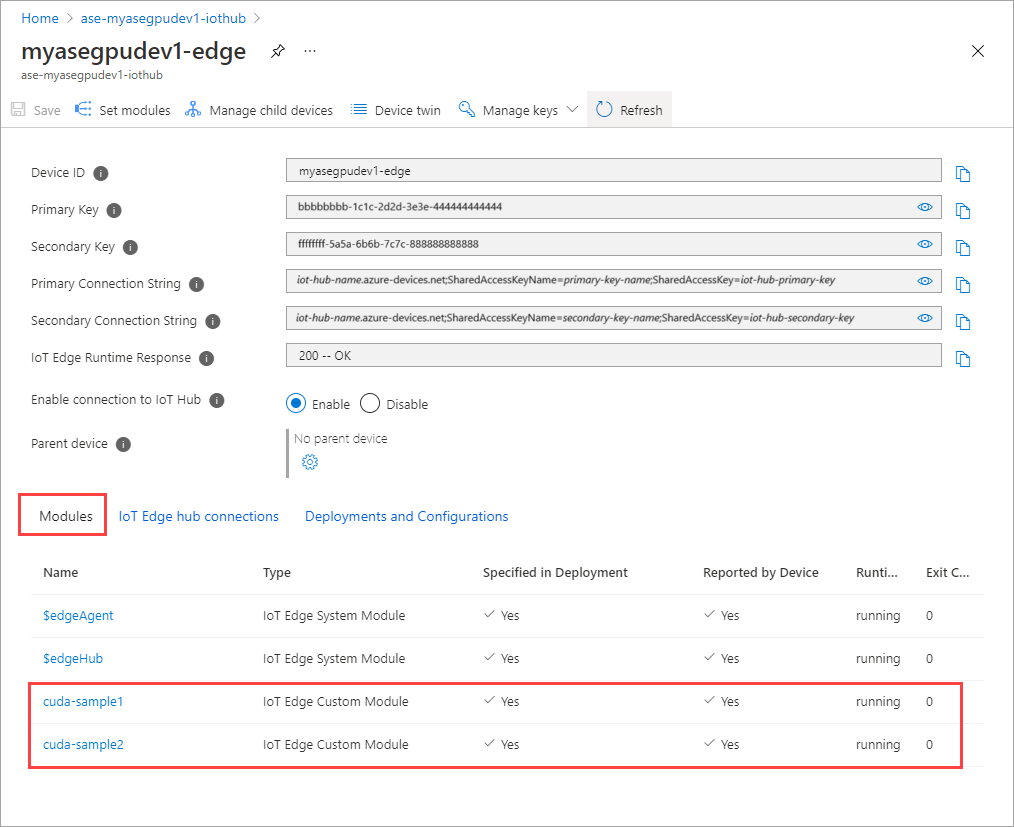
워크로드 배포 모니터링
새 PowerShell 세션을 엽니다.
iotedge네임스페이스에 실행 중인 Pod를 나열합니다. 다음 명령을 실행합니다.kubectl get pods -n iotedge출력의 예제는 다음과 같습니다.
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>디바이스에서 실행되는 두 개의 Pod에는
cuda-sample1-97c494d7f-lnmns와cuda-sample2-d9f6c4688-2rld9이 있습니다.두 컨테이너가 모두 n-body 시뮬레이션을 실행하는 동안 NVIDIA smi 출력에서 GPU 사용률을 확인합니다. 디바이스의 PowerShell 인터페이스로 이동하고
Get-HcsGpuNvidiaSmi를 실행합니다.다음은 두 개의 컨테이너가 n-body 시뮬레이션을 실행하는 경우의 출력 예제입니다.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>GPU 0에서 다체(n-body) 시뮬레이션을 사용하여 실행되는 두 개의 컨테이너를 볼 수 있습니다. 해당 메모리 사용을 볼 수도 있습니다.
시뮬레이션이 완료되면 NVIDIA smi 출력은 디바이스에서 실행 중인 프로세스가 없음을 표시합니다.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>다체(n-body) 시뮬레이션이 완료되면 로그를 확인하여 배포 세부 정보와 시뮬레이션을 완료하는 데 필요한 시간을 파악합니다.
첫 번째 컨테이너의 예제 출력은 다음과 같습니다.
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>두 번째 컨테이너의 예제 출력은 다음과 같습니다.
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>모듈 배포를 중지합니다. 디바이스에 대한 IoT Hub 리소스에서 다음을 수행합니다.
자동 디바이스 배포 > IoT Edge로 이동합니다. 디바이스에 해당하는 IoT Edge 디바이스를 선택합니다.
모듈 설정으로 이동하고 모듈을 선택합니다.
모듈 탭에서 모듈을 선택합니다.
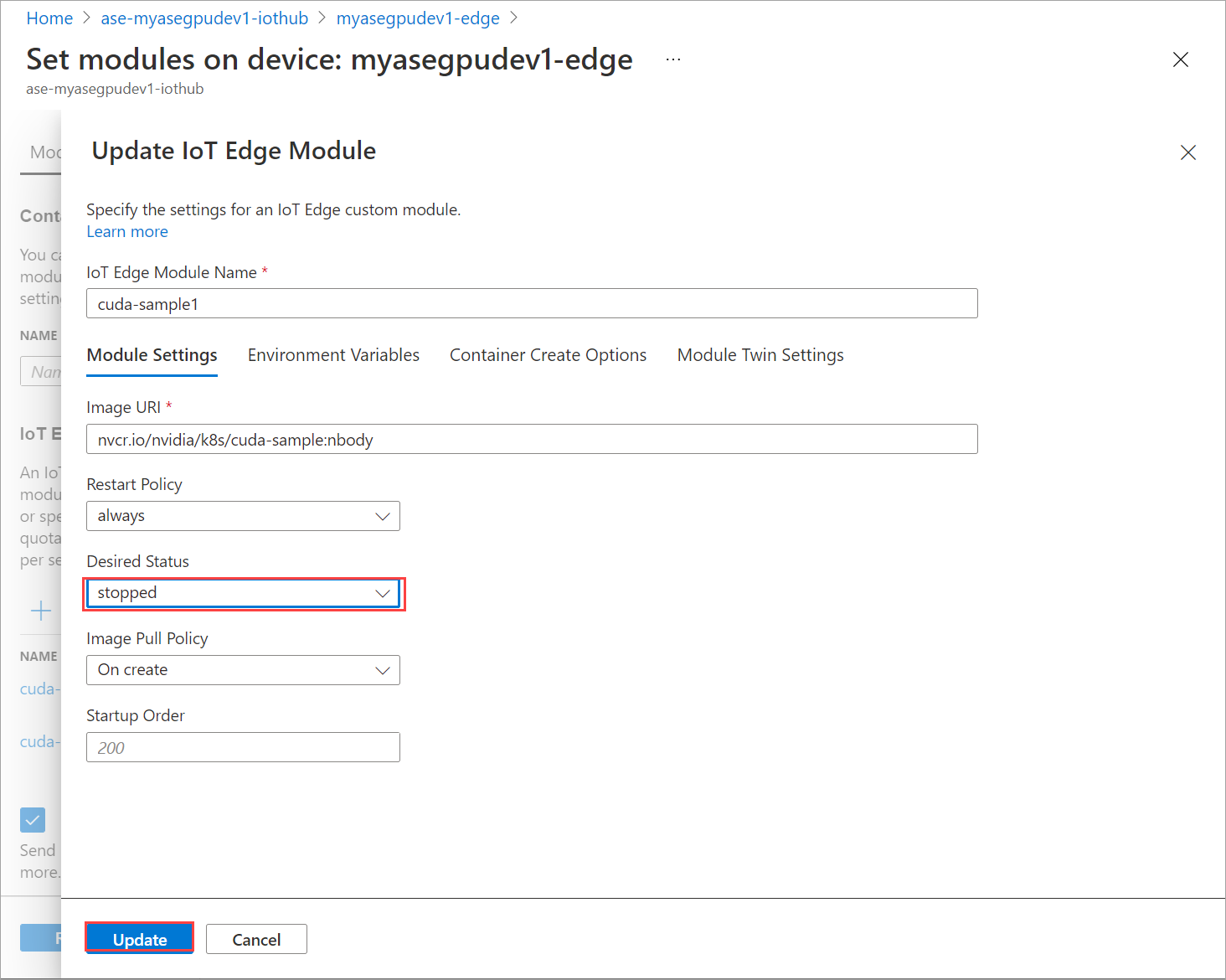
모듈 설정 탭에서 원하는 상태를 중지됨으로 설정합니다. 업데이트를 선택합니다.
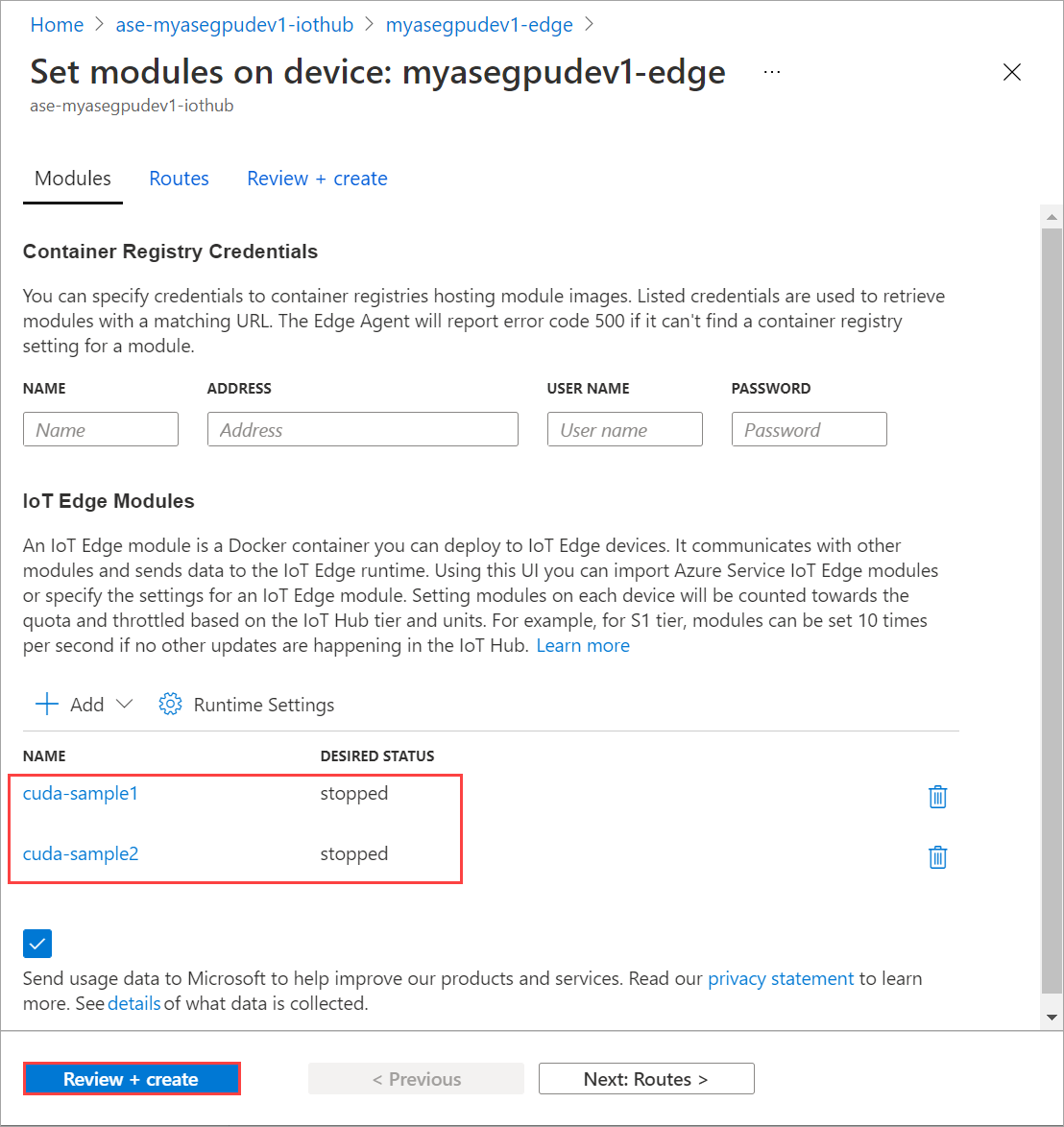
단계를 반복하여 디바이스에 배포된 두 번째 모듈을 중지합니다. 검토 + 생성를 선택한 다음, 생성를 선택합니다. 그러면 배포가 업데이트됩니다.
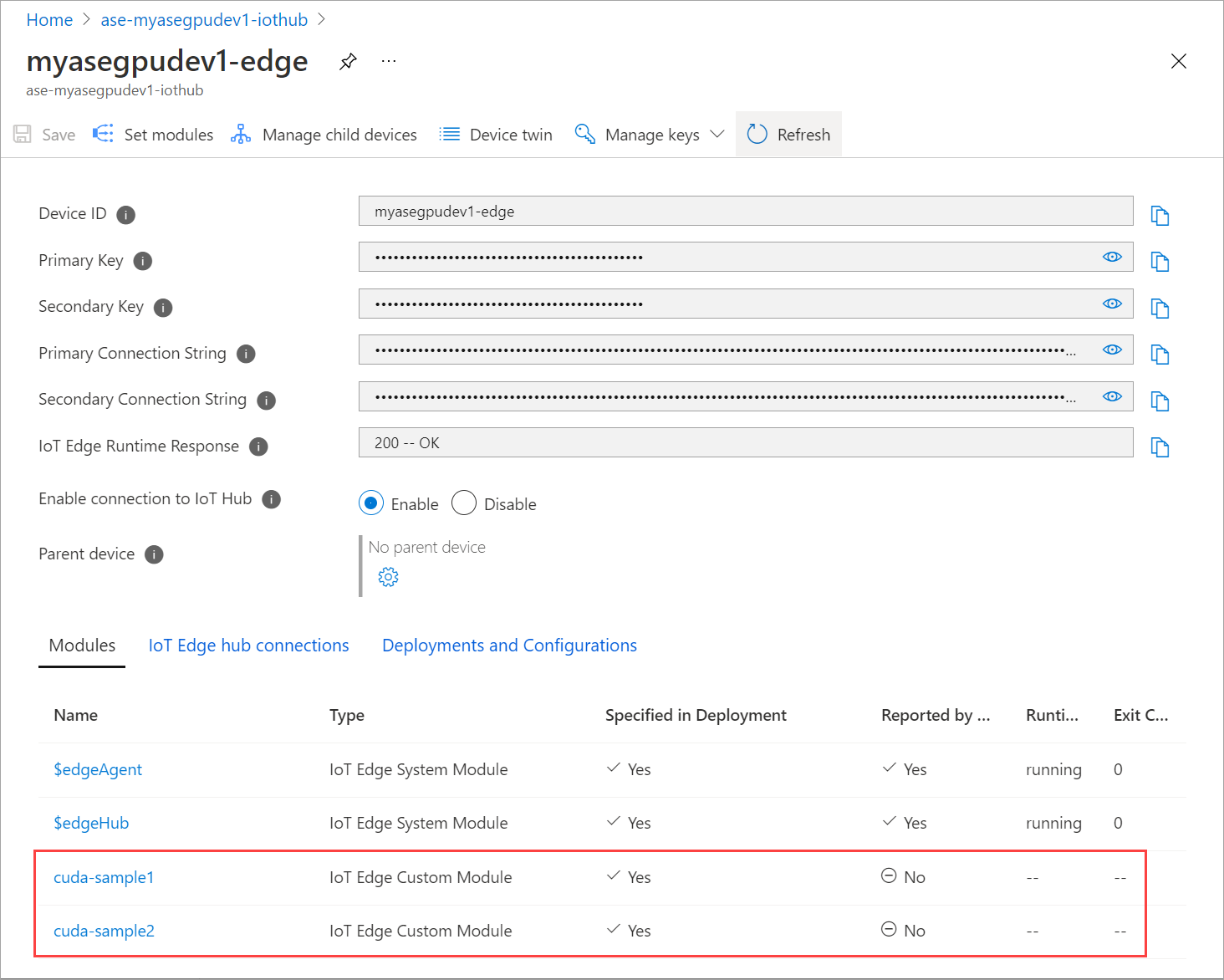
모듈 설정 페이지를 여러 번 새로 고칩니다. 모듈 런타임 상태가 중지됨으로 표시될 때까지 수행합니다.
컨텍스트 공유를 사용하여 배포
이제 디바이스에서 MP를 실행하는 경우 두 개의 CUDA 컨테이너에 다체(n-body) 시뮬레이션을 배포할 수 있습니다. 먼저 디바이스에서 MP를 사용하도록 설정합니다.
디바이스에서 MPS를 사용하도록 설정하려면
Start-HcsGpuMPS명령을 실행합니다.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>디바이스의 PowerShell 인터페이스에서 NVIDIA smi 출력을 가져옵니다. 디바이스에서
nvidia-cuda-mps-server프로세스 또는 MPS 서비스가 실행되는 것을 볼 수 있습니다.출력의 예제는 다음과 같습니다.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi이전에 중지한 모듈을 배포합니다. 모듈 설정을 통해 원하는 상태를 실행 중으로 설정합니다.
출력의 예제는 다음과 같습니다.
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>모듈이 배포되어 디바이스에서 실행되는지를 확인할 수 있습니다.
모듈이 배포되면 다체(n-body) 시뮬레이션도 두 컨테이너에서 실행을 시작합니다. 다음은 첫 번째 컨테이너에서 시뮬레이션이 완료된 경우의 예제 출력입니다.
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>다음은 두 번째 컨테이너에서 시뮬레이션이 완료된 경우의 예제 출력입니다.
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>두 컨테이너가 모두 n-body 시뮬레이션을 실행할 때 디바이스의 PowerShell 인터페이스에서 NVIDIA smi 출력을 가져옵니다. 다음은 예제 출력입니다. 세 가지 프로세스가 있습니다.
nvidia-cuda-mps-server프로세스(C 형식)는 MPS 서비스에 해당하고/tmp/nbody프로세스(M + C 형식)는 모듈에서 배포한 다체(n-body) 워크로드에 해당합니다.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi