Azure Data Factory의 통합 런타임
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
IR(Integration Runtime)은 서로 다른 네트워크 환경 간에 다음과 같은 데이터 통합 기능을 제공하기 위해 Azure Data Factory 및 Azure Synapse 파이프라인에서 사용하는 컴퓨팅 인프라입니다.
- Data Flow: 관리되는 Azure 컴퓨팅 환경에서 Data Flow를 실행합니다.
- 데이터 이동: 데이터를 공용 또는 프라이빗 네트워크(온-프레미스 또는 가상 사설망 모두)의 데이터 저장소 간에 복사합니다. 이 서비스는 기본 제공 커넥터, 형식 변환, 열 매핑 및 성능이 뛰어나고 확장성 있는 데이터 전송을 지원합니다.
- 작업 디스패치: Azure Databricks, Azure HDInsight, ML Studio(클래식), Azure SQL Database, SQL Server 등 다양한 컴퓨팅 서비스에서 실행되는 변환 작업을 디스패치하고 모니터링합니다.
- SSIS 패키지 실행: SSIS(SQL Server 통합 서비스) 패키지를 관리되는 Azure 컴퓨팅 환경에서 고유하게 실행합니다.
Data Factory 및 Synapse 파이프라인에서 작업은 수행할 작업을 정의합니다. 연결된 서비스는 대상 데이터 저장소 또는 컴퓨팅 서비스를 정의합니다. 통합 런타임은 작업과 연결된 서비스 간의 브리지를 제공합니다. 이는 연결된 서비스 또는 작업에서 참조하며 작업이 직접 실행되거나 디스패치되는 컴퓨팅 환경을 제공합니다. 이렇게 하면 데이터 저장소 또는 컴퓨팅 서비스와 가장 가까운 지역에서 작업을 수행하여 성능을 극대화하는 동시에 보안 및 규정 준수 요구 사항을 유연하게 충족할 수 있습니다.
통합 런타임은 관리 허브를 통해 Azure Data Factory 및 Azure Synapse UI에서 직접 만들 수 있을 뿐만 아니라 이를 참조하는 모든 작업, 데이터 세트 또는 데이터 흐름에서도 만들 수 있습니다.
통합 런타임 유형
Data Factory는 세 가지 유형의 IR(Integration Runtime)을 제공하며, 데이터 통합 기능 및 원하는 네트워크 환경 요구에 가장 적합한 유형을 선택해야 합니다. IR의 세 가지 유형은 다음과 같습니다.
- Azure
- 자체 호스팅
- Azure-SSIS
참고 항목
Synapse 파이프라인은 현재 Azure 또는 자체 호스팅 통합 런타임만 지원합니다.
다음 테이블은 각 통합 런타임 유형에 대한 기능 및 네트워크 지원을 설명합니다.
| IR 유형 | 공용 네트워크 지원 | 프라이빗 링크 지원 |
|---|---|---|
| Azure | 데이터 흐름 데이터 이동 작업 디스패치 |
데이터 흐름 데이터 이동 작업 디스패치 |
| 자체 호스팅 | 데이터 이동 작업 디스패치 |
데이터 이동 작업 디스패치 |
| Azure-SSIS | SSIS 패키지 실행 | SSIS 패키지 실행 |
참고 항목
아웃바운드 컨트롤은 Azure IR에 대한 서비스에 따라 다릅니다. Synapse에서 작업 영역에는 Azure IR을 사용할 때 관리형 가상 네트워크의 아웃바운드 트래픽을 제한하는 옵션이 있습니다. Data Factory에서는 Azure IR을 사용할 때 아웃바운드 통신을 위해 모든 포트가 열립니다. Azure-SSIS IR은 vNET과 통합하여 아웃바운드 통신 제어를 제공할 수 있습니다.
Azure 통합 런타임
Azure 통합 런타임은 다음을 수행할 수 있습니다.
- Azure에서 데이터 흐름 실행
- 클라우드 데이터 저장소 간 복사 작업 실행
- 공용 네트워크에서 다음과 같은 변환 작업 디스패치:
- .NET 사용자 지정 작업
- Azure 함수 작업
- Databricks Notebook/ Jar/ Python 작업
- Data Lake Analytics U-SQL 작업
- 메타데이터 가져오기 작업
- HDInsight Hive 작업
- HDInsight Pig 작업
- HDInsight MapReduce 작업
- HDInsight Spark 작업
- HDInsight 스트리밍 작업
- 조회 작업
- Machine Learning Studio(클래식) Batch Execution 작업
- Machine Learning Studio(클래식) 업데이트 리소스 작업
- 저장 프로시저 작업
- 유효성 검사 작업
- 웹 활동
Azure IR 네트워크 환경
Azure 통합 런타임은 공개 액세스 가능한 엔드포인트가 있는 데이터 소스에 연결 및 컴퓨팅 서비스를 지원합니다. 관리형 Virtual Network를 사용하도록 설정하면 Azure Integration Runtime에서 프라이빗 네트워크 환경에서 프라이빗 링크 서비스를 사용하여 데이터 저장소에 연결할 수 있습니다. Synapse에서 작업 영역에는 IR 관리형 가상 네트워크의 아웃바운드 트래픽을 제한하는 옵션이 있습니다. Data Factory에서는 아웃바운드 통신을 위해 모든 포트가 열립니다. Azure-SSIS IR은 vNET과 통합하여 아웃바운드 통신 제어를 제공할 수 있습니다.
Azure IR 컴퓨팅 리소스 및 크기 조정
Azure 통합 런타임은 Azure에서 완전히 관리되고, 서버리스 컴퓨팅을 제공합니다. 인프라 프로비전, 소프트웨어 설치, 패치 또는 용량 크기 조정을 걱정할 필요가 없습니다. 또한 실제 사용 기간에 대해서만 지불합니다.
Azure 통합 런타임은 안전하고 안정적이고 고성능의 방법으로 클라우드 데이터 저장소 간에 데이터를 이동하는 고유 컴퓨팅을 제공합니다. 복사 작업에 사용할 데이터 통합 단위 수를 설정할 수 있으며, Azure IR의 컴퓨팅 크기는 Azure Integration Runtime의 크기를 명시적으로 조정할 필요 없이 그에 따라 탄력적으로 스케일 업됩니다.
작업 디스패치는 작업을 대상 컴퓨팅 서비스에 경로 설정하는 간단한 작업이므로 이 시나리오를 위해 컴퓨팅 크기를 확장할 필요가 없습니다.
Azure IR 만들기 및 구성에 대한 자세한 내용은 Azure IR 만들기 및 구성 방법을 참조하세요.
참고 항목
Azure 통합 런타임에는 데이터 흐름을 실행하는 데 사용되는 기본 컴퓨팅 인프라를 정의하는 데이터 흐름 런타임과 관련된 속성이 있습니다.
자체 호스팅 통합 런타임
자체 호스팅 IR로 다음을 수행할 수 있습니다.
- 클라우드 데이터 저장소와 프라이빗 네트워크의 데이터 저장소 간에 복사 작업을 실행합니다.
- 온-프레미스 또는 Azure Virtual Network의 컴퓨팅 리소스에 대해 다음과 같은 변환 작업을 디스패치합니다.
- Azure 함수 작업
- 사용자 지정 작업(Azure Batch에서 실행)
- Data Lake Analytics U-SQL 작업
- 메타데이터 가져오기 작업
- HDInsight Hive 작업(BYOC-Bring Your Own Cluster)
- HDInsight Pig 작업(BYOC)
- HDInsight MapReduce 작업(BYOC)
- HDInsight Spark 작업(BYOC)
- HDInsight 스트리밍 작업 (BYOC)
- 조회 작업
- Machine Learning Studio(클래식) Batch Execution 작업
- Machine Learning Studio(클래식) 업데이트 리소스 작업
- Machine Learning Execute Pipeline 작업
- 저장 프로시저 작업
- 유효성 검사 작업
- 웹 활동
참고 항목
자체 호스팅 통합 런타임을 사용하여 SAP Hana, MySQL 등과 같은 사용자 고유의 드라이버를 사용(bring-your-own driver)해야 하는 데이터 저장소를 지원합니다. 자세한 내용은 지원되는 데이터 원본을 참조하세요.
참고 항목
JRE(Java Runtime Environment)는 자체 호스팅 IR의 종속성입니다. JRE가 동일한 호스트에 설치되어 있는지 확인하세요.
자체 호스팅 IR 네트워크 환경
퍼블릭 클라우드 환경에서 직접 볼 수 없는 프라이빗 네트워크 환경에서 데이터 통합을 안전하게 수행하려면 자체 호스팅 IR을 방화벽 내 또는 VPN(가상 사설망) 내의 온-프레미스 환경에 설치할 수 있습니다. 자체 호스팅 통합 런타임은 인터넷에 대한 아웃바운드 HTTP 기반 연결만 만듭니다.
자체 호스팅 IR 컴퓨팅 리소스 및 크기 조정
자체 호스팅 IR은 온-프레미스 컴퓨터 또는 프라이빗 네트워크 내의 가상 머신에 설치합니다. 현재 자체 호스팅 IR은 Windows 운영 체제에서만 지원됩니다.
고가용성과 확장성을 위해 논리 인스턴스를 활성-활성 모드의 여러 온-프레미스 컴퓨터와 연결하여 자체 호스팅 IR을 확장할 수 있습니다. 자세한 내용은 자체 호스팅 IR을 만들고 구성하는 방법 문서를 참조하세요.
Azure-SSIS Integration Runtime
기존 SSIS 워크로드를 올리고 이동하려면 SSIS 패키지를 고유하게 실행하는 Azure-SSIS IR을 만들 수 있습니다.
Azure-SSIS IR 네트워크 환경
Azure SSIS IR은 공용 네트워크 또는 프라이빗 네트워크에서 프로비전할 수 있습니다. 온-프레미스 데이터 액세스는 Azure-SSIS IR을 온-프레미스 네트워크에 연결된 가상 네트워크에 조인하여 지원됩니다.
Azure-SSIS IR 컴퓨팅 리소스 및 크기 조정
Azure-SSIS IR은 SSIS 패키지만 전적으로 실행하는 Azure VM의 완전 관리형 클러스터입니다. SSIS 프로젝트/패키지(SSISDB) 카탈로그에 자신만의 Azure SQL Database 또는 SQL Managed Instance를 가져올 수 있습니다. 노드 크기를 지정하여 컴퓨팅 능력을 확장하고 클러스터의 노드 수를 지정하여 확장할 수 있습니다. Azure-SSIS Integration Runtime 실행 비용은 요구 사항에 따라 중지했다가 시작하여 관리할 수 있습니다.
자세한 내용은 Azure-SSIS IR을 만들고 구성하는 방법을 참조하세요. 만들어지면 SSIS 온-프레미스를 사용하는 것처럼 SSDT(SQL Server Data Tools) 및 SSMS(SQL Server Management Studio)와 같은 친숙한 도구를 사용하여 기존 SSIS 패키지를 전혀 변경하지 않거나 조금만 변경하여 배포하고 관리할 수 있습니다.
Azure-SSIS 런타임에 대한 자세한 내용은 다음 문서를 참조하세요.
- 자습서: Azure에 SSIS 패키지 배포. 이 문서는 Azure-SSIS IR을 만들고 Azure SQL Database를 사용하여 SSIS 카탈로그를 호스트하는 단계별 지침을 제공합니다.
- 방법: Azure-SSIS 통합 런타임 만들기. 이 문서에서는 자습서를 확장하여 SQL Managed Instance를 사용하고 IR을 가상 네트워크에 조인하는 방법에 대한 지침을 제공합니다.
- Azure-SSIS IR 모니터링. 이 문서는 Azure-SSIS IR에 대한 정보를 검색하는 방법을 보여주고 반환된 정보의 상태에 대한 설명을 제공합니다.
- Azure-SSIS IR 관리. 이 문서는 Azure-SSIS IR을 중지, 시작 또는 제거하는 방법을 설명합니다. 또한 IR에 노드를 추가하여 Azure-SSIS IR 규모를 확장하는 방법을 보여줍니다.
- Azure-SSIS IR을 가상 네트워크에 조인. 이 문서에서는 Azure-SSIS IR을 Azure 가상 네트워크에 조인하는 방법에 대한 개념 정보를 제공합니다. 또한 Azure Portal을 사용하여 가상 네트워크를 구성하고 Azure-SSIS IR을 조인하는 단계를 제공합니다.
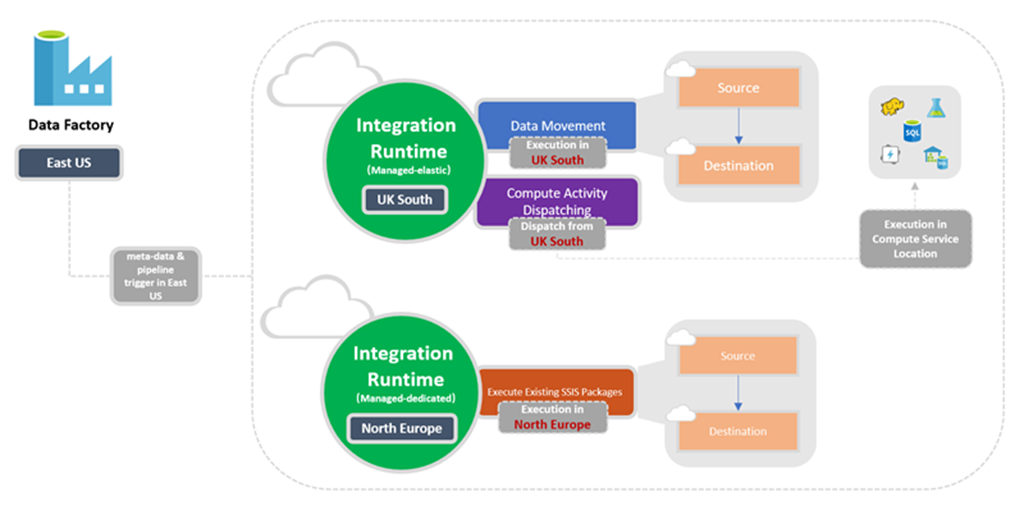
통합 런타임 위치
팩터리 위치와 IR 위치 사이의 관계
Data Factory 또는 Synapse 작업 영역의 인스턴스를 만들 때 해당 위치를 지정해야 합니다. 인스턴스에 대한 메타데이터가 여기에 저장되고 파이프라인의 트리거가 여기서 시작됩니다. 메타데이터는 선택한 지역에만 저장되고 다른 지역에는 저장되지 않습니다.
한편 파이프라인은 다른 Azure 지역의 데이터 저장소 및 컴퓨팅 서비스에 액세스하여 데이터 저장소 간에 데이터를 이동하거나 컴퓨팅 서비스를 사용하여 데이터를 처리할 수 있습니다. 이 동작은 데이터 준수, 효율성 및 네트워크 송신 비용 절감을 위해 전역적으로 사용할 수 있는 IR을 통해 실현됩니다.
IR 위치는 백 엔드 컴퓨팅의 위치와 데이터 이동, 작업 디스패치 및 SSIS 패키지 실행이 수행되는 위치를 정의합니다. IR 위치는 이 위치가 속한 Data Factory의 위치와 다를 수 있습니다.
Azure IR 위치
Azure IR의 위치 지역을 설정할 수 있으며, 이 경우 선택한 지역에서 작업 실행 또는 디스패치가 수행됩니다.
기본값은 공용 네트워크에서 Azure IR을 자동으로 확인하는 것입니다. 이 옵션을 사용하여:
복사 작업의 경우 싱크 데이터 저장소의 위치를 자동으로 검색한 다음, 동일한 지역(사용 가능한 경우) 또는 동일한 지리적 위치 내의 가장 가까운 지역에서 IR을 사용하려고 합니다. 싱크 데이터 저장소의 지역을 검색할 수 없는 경우 Data Factory 지역의 IR이 대신 사용됩니다.
예를 들어 Data Factory 또는 Synapse 작업 영역이 미국 동부에 만들어졌습니다.
- 데이터를 미국 서부의 Azure Blob에 복사할 때 Blob이 미국 서부에 있는 것으로 검색되면 복사 작업은 미국 서부의 IR에서 실행됩니다. 지역 검색에 실패하는 경우 복사 작업은 미국 동부의 IR에서 실행됩니다.
- 데이터를 지역이 검색되지 않는 Salesforce에 복사하는 경우 복사 작업은 미국 동부의 IR에서 실행됩니다.
팁
엄격한 데이터 규정 준수 요구 사항이 있고 데이터가 특정 지리적 위치를 벗어나지 않도록 해야 하는 경우 명시적으로 특정 지역에서 Azure IR을 만들고 ConnectVia 속성을 사용하여 연결된 서비스에서 이 IR을 가리킬 수 있습니다. 예를 들어 영국 남부의 Blob 데이터를 영국 남부의 Azure Synapse 작업 영역으로 복사하고 데이터가 영국을 벗어나지 않도록 하려면 영국 남부에서 Azure IR을 만들고 두 연결된 서비스를 이 IR에 연결합니다.
조회/GetMetadata/삭제 작업 실행(파이프라인 작업), 변환 작업 디스패치(외부 작업) 및 작성 작업(테스트 연결, 폴더 목록 및 테이블 목록 찾아보기, 데이터 미리 보기)의 경우 Data Factory 또는 Synapse 작업 영역과 동일한 지역의 IR이 사용됩니다.
Data Flow의 경우 Data Factory 또는 Synapse 작업 영역 지역의 IR이 사용됩니다.
팁
가능한 경우 데이터 흐름이 해당 데이터 저장소와 동일한 지역에서 실행되도록 하는 것이 가장 좋습니다. 이를 위해 Azure IR에 대한 자동 확인(데이터 저장소 위치가 Data Factory 또는 Synapse 작업 영역 위치와 동일한 경우)을 사용하거나 새 Azure IR 인스턴스를 데이터 저장소와 동일한 지역에 만들어 데이터 흐름을 실행하면 됩니다.
Azure IR에 대한 자동 확인이 포함된 관리형 Virtual Network를 사용하도록 설정하면 Data Factory 또는 Synapse 작업 영역 지역의 IR이 사용됩니다.
Data Factory Studio 또는 Synapse Studio의 파이프라인 작업 모니터링 보기 또는 작업 모니터링 페이로드에서 작업 실행 중에 적용되는 IR 위치를 모니터링할 수 있습니다.
자체 호스팅 IR 위치
자체 호스팅 IR은 논리적으로 Data Factory 또는 Synapse 작업 영역에 등록되며 해당 기능을 지원하기 위해 사용되는 컴퓨팅은 사용자가 제공합니다. 따라서 자체 호스팅 IR에 대한 명시적 위치 속성은 없습니다.
데이터 이동을 수행하기 위해 사용하는 경우 자체 호스팅 IR은 소스에서 데이터를 추출하고 대상에 씁니다.
Azure-SSIS IR 위치
참고 항목
Azure-SSIS 통합 런타임은 현재 Synapse 파이프라인에서 지원되지 않습니다.
Azure SSIS IR에 적합한 위치 선택은 ETL(추출-변환-로드) 워크플로에서 고성능을 달성하기 위해 필수적입니다.
- Azure-SSIS IR의 위치가 Data Factory의 위치와 같을 필요는 없지만, SSISDB가 있는 사용자 고유의 Azure SQL Database 또는 SQL Managed Instance의 위치와 같아야 합니다. 이렇게 하면 Azure SSIS 통합 런타임에서 서로 다른 위치 간에 과도한 트래픽을 발생시키지 않고 SSISDB에 쉽게 액세스할 수 있습니다.
- 기존 Azure SQL Database 또는 SQL Managed Instance는 없지만 온-프레미스 데이터 소스/대상이 있는 경우 온-프레미스 네트워크에 연결된 가상 네트워크의 같은 위치에 새 Azure SQL Database 또는 SQL Managed Instance를 만들어야 합니다. 이렇게 하면 새 Azure SQL Database 또는 SQL Managed Instance를 사용하여 Azure-SSIS IR을 만들고 해당 가상 네트워크에 조인할 수 있습니다. 모든 항목이 동일한 위치에 있으므로 데이터 이동 및 관련 비용을 최소화하면서 성능을 최대화합니다.
- 기존 Azure SQL Database 또는 SQL Managed Instance의 위치가 온-프레미스 네트워크에 연결된 가상 네트워크의 위치와 같지 않은 경우 먼저 기존 Azure SQL Database 또는 SQL Managed Instance를 사용하여 Azure-SSIS IR을 만들고 같은 위치에 있는 다른 가상 네트워크에 조인합니다. 그런 다음, 서로 다른 위치 간의 가상 네트워크 연결에 대한 가상 네트워크를 구성합니다.
다음 다이어그램에서는 Data Factory 및 해당 통합 런타임에 대한 위치 설정을 보여 줍니다.
사용할 IR 결정
하나의 작업이 둘 이상의 통합 런타임 유형과 연결되는 경우 그중 하나로 확인합니다. 자체 호스팅 통합 런타임은 관리형 가상 네트워크를 사용하는 Azure Data Factory 또는 Synapse 작업 영역 인스턴스의 Azure 통합 런타임보다 우선적으로 적용됩니다. 그리고 후자는 글로벌 Azure 통합 런타임보다 우선적으로 적용됩니다.
예를 들어 하나의 복사 작업은 원본에서 싱크로 데이터를 복사하는 데 사용됩니다. 글로벌 Azure 통합 런타임은 원본에 연결된 서비스와 연결되고 Azure Data Factory 관리형 가상 네트워크의 Azure 통합 런타임은 싱크에 대한 연결된 서비스와 연결됩니다. 결과적으로 원본 및 싱크 연결된 서비스 모두에서 Azure Data Factory 관리형 가상 네트워크의 Azure 통합 런타임을 사용합니다. 그러나 자체 호스팅 통합 런타임에서 원본에 대한 연결된 서비스를 연결하는 경우 원본 및 싱크 연결된 서비스 모두에서 자체 호스팅 통합 런타임을 사용합니다.
복사 활동
복사 작업에는 데이터 흐름의 방향을 정의하기 위해 원본 및 싱크 연결된 서비스가 모두 필요합니다. 다음 논리를 사용하여 복사를 수행하는 데 사용하는 통합 런타임 인스턴스를 결정합니다.
- 두 클라우드 데이터 원본 간 복사: 원본 및 싱크 연결된 서비스 모두에서 Azure IR을 사용하는 경우 지역별 Azure IR(지정된 경우)이 사용되거나 통합 런타임 위치 섹션에서 설명한 대로 자동 확인 IR(기본값) 옵션이 선택된 경우 Azure IR의 위치가 자동으로 결정됩니다.
- 클라우드 데이터 원본과 프라이빗 네트워크의 데이터 원본 간 복사: 원본 또는 싱크 연결된 서비스 중 하나에서 자체 호스팅 IR을 가리키는 경우 해당 자체 호스 IR에서 복사 작업이 실행됩니다.
- 프라이빗 네트워크의 두 데이터 원본 간 복사: 원본 및 싱크 연결된 서비스 모두에서 통합 런타임의 동일한 인스턴스를 가리켜야 하며 해당 IR이 복사 작업을 실행하는 데 사용됩니다.
조회 및 GetMetadata 작업
조회 및 GetMetadata 작업은 데이터 저장소 연결된 서비스와 연결된 통합 런타임에서 실행됩니다.
외부 변환 작업
외부 컴퓨팅 엔진을 활용하는 각 외부 변환 작업에는 통합 런타임을 가리키는 대상 컴퓨팅 연결된 서비스가 있습니다. 이 IR 인스턴스는 외부에서 직접 코딩한 변환 작업이 디스패치되는 위치를 결정합니다.
데이터 흐름 활동
Data Flow 작업은 연결된 Azure 통합 런타임에서 실행됩니다. 데이터 흐름에서 활용하는 Spark 컴퓨팅은 Azure IR의 데이터 흐름 속성에 따라 결정되며 서비스에서 완전히 관리됩니다.
CI/CD의 통합 런타임
통합 런타임은 자주 변경되지 않으며 CI/CD의 모든 단계에서 유사합니다. Data Factory를 사용하려면 CI/CD의 모든 단계에서 동일한 이름 및 유형의 통합 런타임이 있어야 합니다. 모든 단계에서 통합 런타임을 공유하려면 공유 통합 런타임을 포함하기 위해 전용 팩터리를 사용하는 것이 좋습니다. 그러면 모든 환경에서 이 공유 팩터리를 연결된 통합 런타임 유형으로 사용할 수 있습니다.
관련 콘텐츠
다음 문서를 참조하세요.
- 새 Azure Integration Runtime 만들기
- 자체 호스팅 통합 런타임 만들기
- Azure-SSIS 통합 런타임을 만듭니다. 이 문서에서는 자습서를 확장하여 SQL Managed Instance를 사용하고 IR을 가상 네트워크에 조인하는 방법에 대한 지침을 제공합니다.