Azure Cosmos DB에 대한 분석 저장소에서 변경 데이터 캡처 시작
적용 대상: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Azure Cosmos DB 분석 저장소의 CDC(변경 데이터 캡처)를 원본으로 사용하여 데이터에 대한 특정 변경 내용을 캡처하기 위해 Azure Data Factory 또는 Azure Synapse Analytics를 사용합니다.
참고 항목
Azure Cosmos DB for MongoDB API에 대한 연결된 서비스 인터페이스는 아직 데이터 흐름에서 사용할 수 없습니다. 하지만 Mongo에 연결된 서비스가 지원될 때까지 "Azure Cosmos DB for NoSQL"에 연결된 서비스 인터페이스와 함께 계정의 문서 엔드포인트를 임시방편으로 사용할 수 있습니다. NoSQL 연결된 서비스에서 "수동으로 입력"을 선택하여 Cosmos DB 계정 정보를 제공하고 MongoDB 엔드포인트(예: mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/) 대신 계정의 문서 엔드포인트(예: https://[your-database-account-uri].documents.azure.com:443/)를 사용합니다.
필수 조건
- 기존 Azure Cosmos DB 계정.
- 기존 Azure 구독이 있는 경우 새 계정을 만듭니다.
- Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- 또는 커밋하기 전에 Azure Cosmos DB 평가판을 사용해 볼 수 있습니다.
분석 저장소 사용
먼저 계정 수준에서 Azure Synapse Link를 사용하도록 설정한 다음 워크로드에 적합한 컨테이너에 대해 분석 저장소를 사용하도록 설정합니다.
Azure Synapse 링크 사용: Azure Cosmos DB 계정에 Azure Synapse Link 사용
컨테이너에 대해 분석 저장소를 사용하도록 설정합니다.
옵션 Guide 특정 새 컨테이너에 대해 사용 새 컨테이너에 대해 Azure Synapse Link 사용 특정 기존 컨테이너에 대해 사용 기존 컨테이너에 대해 Azure Synapse Link 사용
데이터 흐름을 사용하여 대상 Azure 리소스 만들기
분석 저장소의 변경 데이터 캡처 기능은 Azure Data Factory 또는 Azure Synapse Analytics의 데이터 흐름 기능을 통해 사용할 수 있습니다. 이 가이드에서는 Azure Data Factory를 사용합니다.
Important
또는 Azure Synapse Analytics를 사용할 수 있습니다. 아직 없는 경우 Azure Synapse 작업 영역을 만듭니다. 새로 만든 작업 영역 내에서 개발 탭을 선택하고 새 리소스 추가를 선택한 다음 데이터 흐름을 선택합니다.
아직 없는 경우 Azure Data Factory를 만듭니다.
팁
가능하면 Azure Cosmos DB 계정이 있는 동일한 지역에 데이터 팩터리를 만듭니다.
이제 새로 만든 데이터 팩터리를 시작합니다.
데이터 팩터리에서 데이터 흐름 탭을 선택한 다음, 새 데이터 흐름을 선택합니다.
새로 만든 데이터 흐름에 고유한 이름을 지정합니다. 이 예제에서 데이터 흐름의 이름은
cosmoscdc입니다.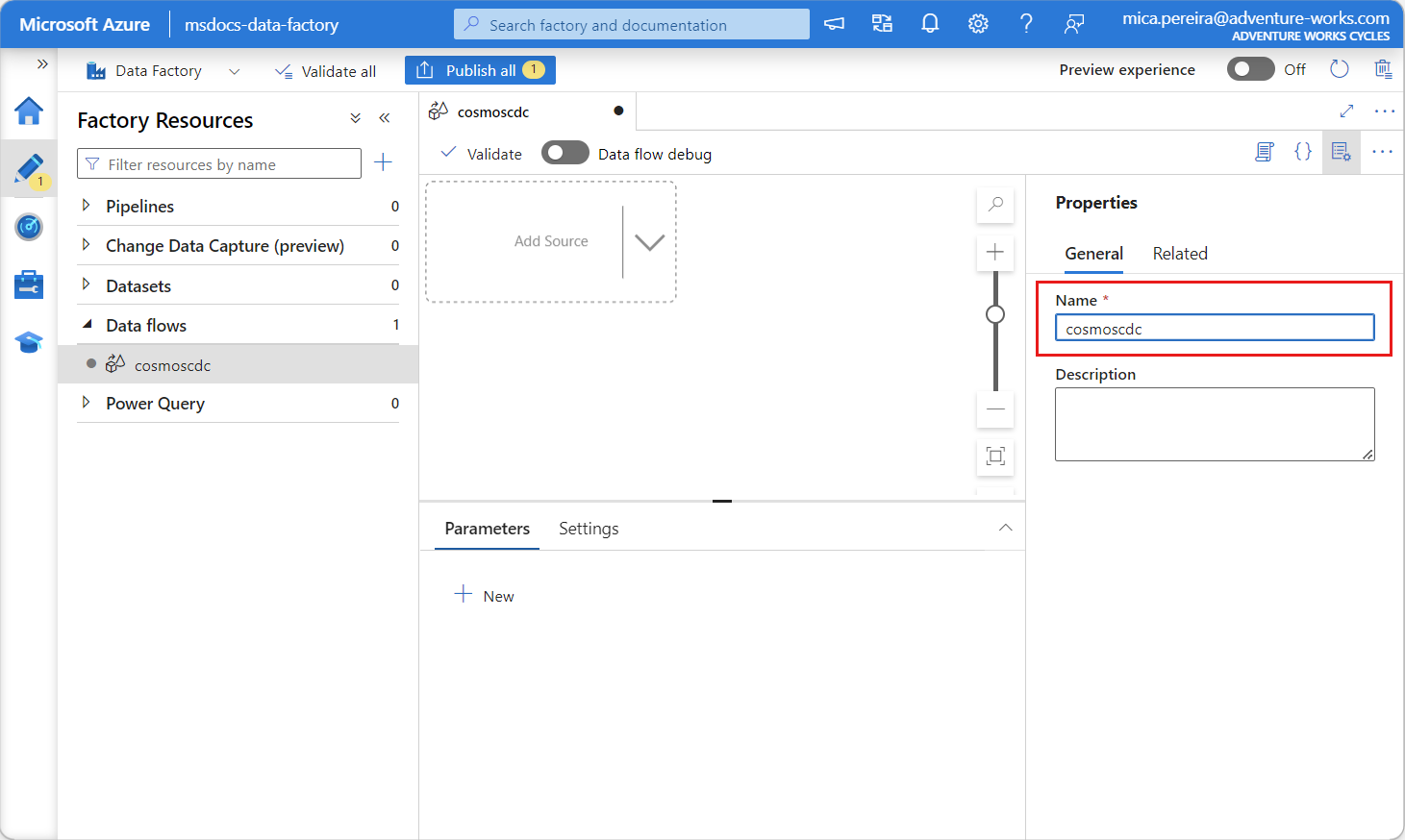

분석 저장소 컨테이너에 대한 원본 설정 구성
이제 Azure Cosmos DB 계정의 분석 저장소에서 데이터를 흐를 원본을 만들고 구성합니다.
원본 추가를 선택합니다.
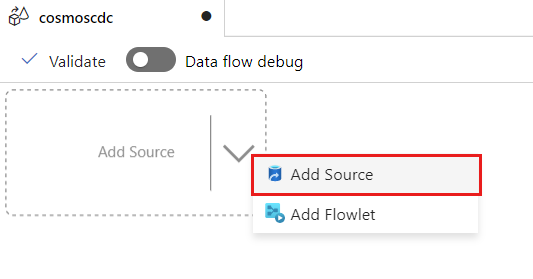
출력 스트림 이름 필드에 cosmos를 입력합니다.
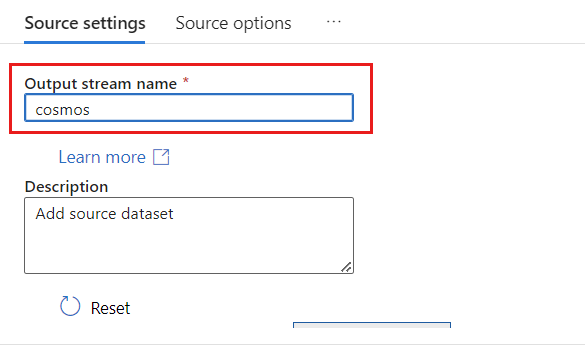
원본 유형 섹션에서 인라인을 선택합니다.
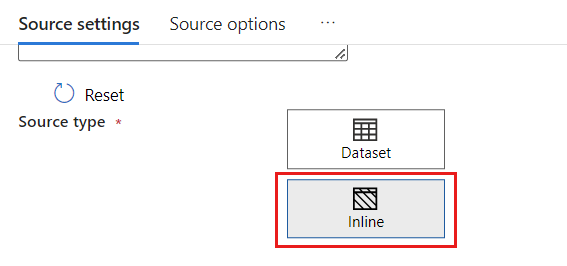
데이터 세트 필드에서 Azure - Azure Cosmos DB for NoSQL을 선택합니다.
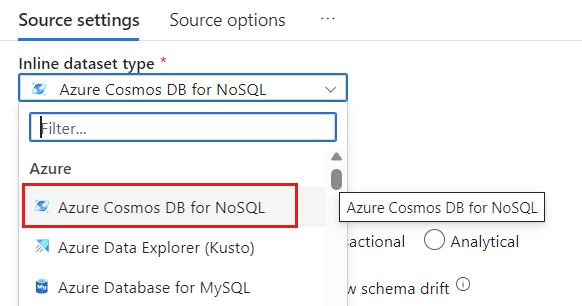
cosmoslinkedservice라는 계정에 대한 새 연결된 서비스를 만듭니다. 새 연결된 서비스 팝업 대화 상자에서 기존 Azure Cosmos DB for NoSQL 계정을 선택한 다음 확인을 선택합니다. 이 예제에서는 이름이
msdocs-cosmos-source인 기존 Azure Cosmos DB for NoSQL 계정과cosmicworks데이터베이스를 선택합니다.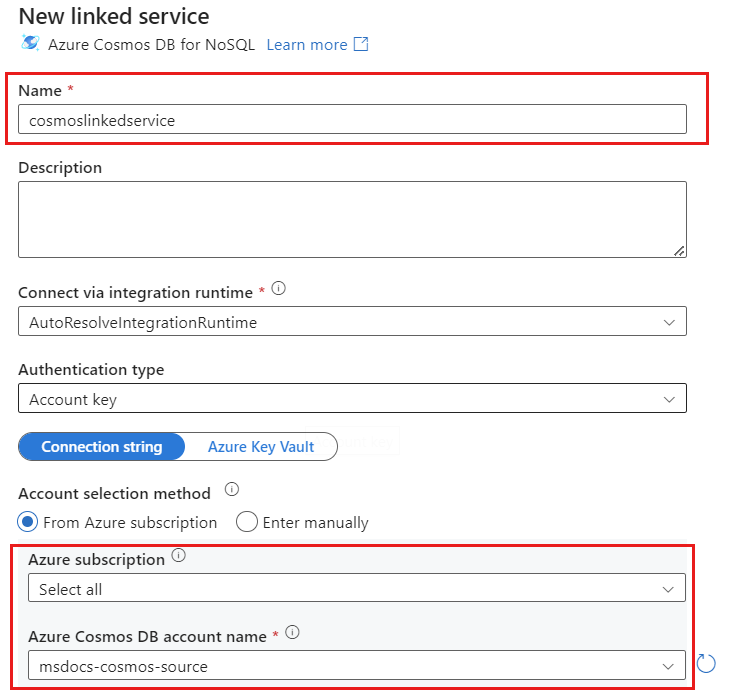
저장 유형에 대해 분석을 선택합니다.
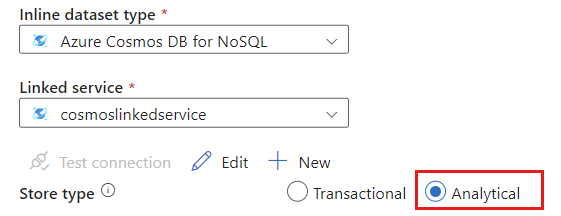
원본 옵션 탭을 선택합니다.
원본 옵션 내에서 대상 컨테이너를 선택하고 데이터 흐름 디버그를 사용하도록 설정합니다. 이 예제에서 컨테이너의 이름은
products입니다.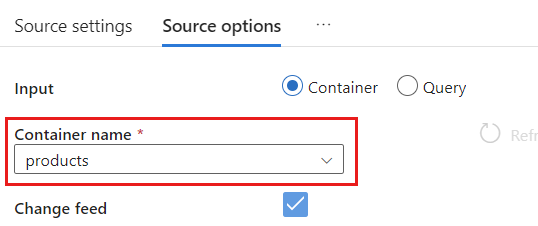
데이터 흐름 디버그를 선택합니다. 데이터 흐름 디버그 설정 팝업 대화 상자에서 기본 옵션을 유지하고 확인을 선택합니다.
원본 옵션 탭에는 사용하도록 설정할 수 있는 다른 옵션도 포함되어 있습니다. 이 표에서는 이러한 옵션에 대해 설명합니다.
| 옵션 | 설명 |
|---|---|
| 중간 업데이트 캡처 | 변경 데이터 캡처 읽기 간의 중간 변경 내용을 포함하여 항목에 대한 변경 기록을 캡처하려는 경우 이 옵션을 사용하도록 설정합니다. |
| 삭제 캡처 | 사용자가 삭제한 레코드를 캡처하고 싱크에 적용하려면 이 옵션을 사용하도록 설정합니다. 삭제는 Azure Data Explorer 및 Azure Cosmos DB 싱크에 적용할 수 없습니다. |
| 트랜잭션 저장소 TTL 캡처 | Azure Cosmos DB 트랜잭션 저장소(TTL 삭제된 레코드)를 캡처하고 싱크에 적용하려면 이 옵션을 사용하도록 설정합니다. TTL 삭제는 Azure Data Explorer 및 Azure Cosmos DB 싱크에 적용할 수 없습니다. |
| 일괄 처리 크기(바이트) | 이 설정은 실제로 기가바이트입니다. 변경 데이터 캡처 피드를 일괄 처리하려면 크기를 기가바이트 단위로 지정합니다 |
| 추가 구성 | 추가 Azure Cosmos DB 분석 저장소 구성 및 해당 값입니다. (예: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
원본 옵션 작업
Capture intermediate updates, Capture Deltes 및 Capture Transactional store TTLs 옵션 중 하나를 선택하면 CDC 프로세스가 싱크의 __usr_opType 필드를 만들고 다음 값으로 채웁니다.
| 값 | 설명 | 옵션 |
|---|---|---|
| 1 | UPDATE | 중간 업데이트 캡처 |
| 2 | 삽입 | 삽입에 대한 옵션은 없으며 기본적으로 켜져 있습니다. |
| 3 | USER_DELETE | 삭제 캡처 |
| 4 | TTL_DELETE | 트랜잭션 저장소 TTL 캡처 |
TTL 삭제 레코드와 사용자 또는 애플리케이션이 삭제한 문서를 구별해야 하는 경우 Capture intermediate updates 및 Capture Transactional store TTLs 옵션을 모두 선택해야 합니다. 그런 다음, 비즈니스 요구 사항에 따라 __usr_opType을 사용하도록 CDC 프로세스, 애플리케이션 또는 쿼리를 조정해야 합니다.
팁
"중간 업데이트 캡처" 옵션을 선택한 상태에서 다운스트림 소비자가 업데이트 순서를 복원해야 하는 경우에는 시스템 타임스탬프 _ts 필드를 순서 필드로 사용할 수 있습니다.
업데이트 및 삭제 작업에 대한 싱크 설정 만들기 및 구성
먼저 간단한 Azure Blob Storage 싱크를 만든 다음 특정 작업으로만 데이터를 필터링하도록 싱크를 구성합니다.
아직 없는 경우 Azure Blob Storage 계정 및 컨테이너를 만듭니다. 다음 예제에서는
msdocsblobstorage계정과output컨테이너를 사용합니다.팁
가능하면 Azure Cosmos DB 계정이 있는 동일한 지역에 스토리지 계정을 만듭니다.
Azure Data Factory로 돌아가서
cosmos원본에서 캡처한 변경 데이터에 대한 새 싱크를 만듭니다.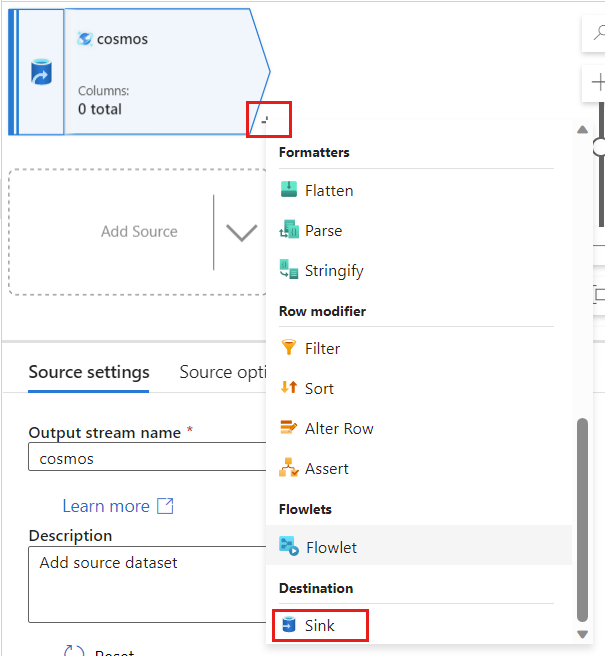
보고서의 고유 이름을 지정합니다. 이 예제에서 싱크의 이름은
storage입니다.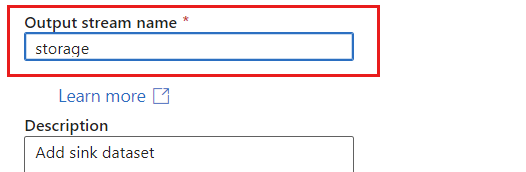
싱크 유형 섹션에서 인라인을 선택합니다. 데이터 세트 필드에서 델타를 선택합니다.
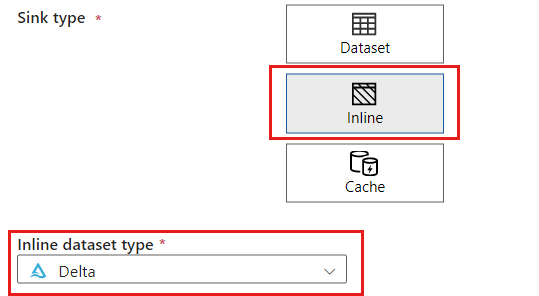
storagelinkedservice라는 Azure Blob Storage를 사용하여 계정에 대한 새 연결된 서비스를 만듭니다. 새 연결된 서비스 팝업 대화 상자에서 기존 Azure Blob 스토리지 계정을 선택한 다음 확인을 선택합니다. 이 예제에서는 이름이
msdocsblobstorage인 기존 Azure Blob Storage 계정을 선택합니다.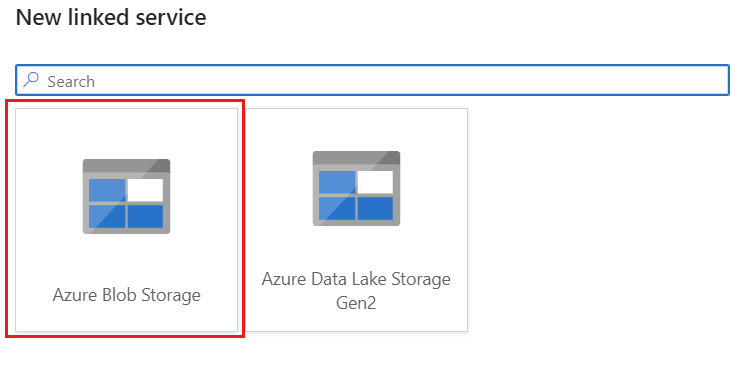
설정 탭을 선택합니다.
설정 내에서 폴더 경로를 Blob 컨테이너의 이름으로 설정합니다. 이 예제에서 컨테이너의 이름은
output입니다.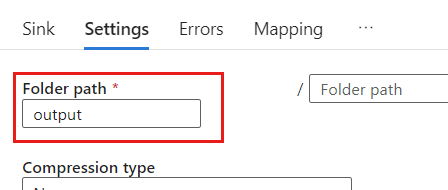
Update 메서드 섹션을 찾아 삭제 및 업데이트 작업만 허용하도록 선택 항목을 변경합니다. 또한
{_rid}필드를 고유 식별자로 사용하여 키 열을 열 목록으로 지정합니다.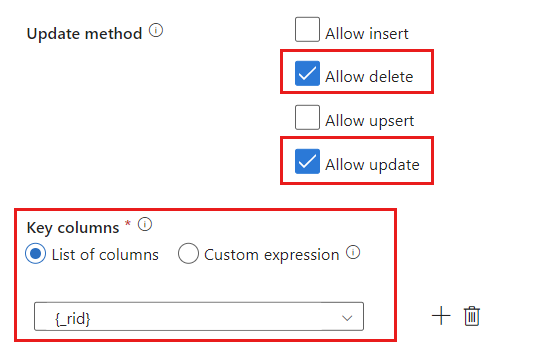
유효성 검사를 선택하여 오류 또는 누락이 발생하지 않았는지 확인합니다. 그런 다음, 게시를 선택하여 데이터 흐름을 게시합니다.
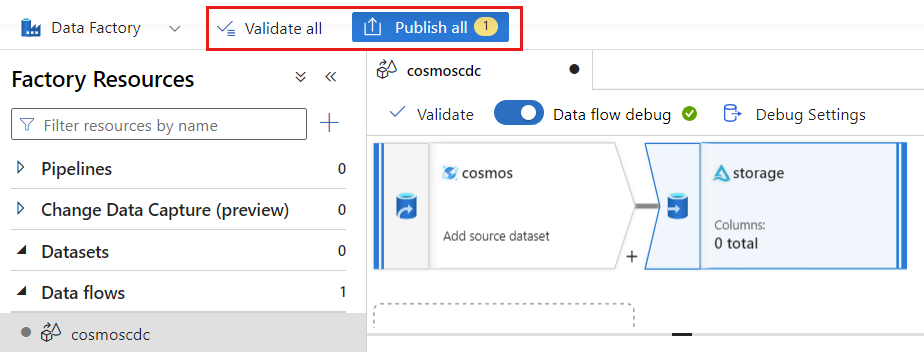
변경 데이터 캡처 실행 예약
데이터 흐름이 게시된 후 새 파이프라인을 추가하여 데이터를 이동하고 변환할 수 있습니다.
새 파이프라인 만들기. 리소스에 고유한 이름을 지정합니다. 이 예제에서 파이프라인의 이름은
cosmoscdcpipeline입니다.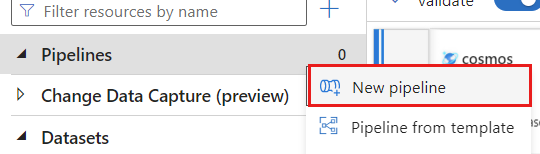
활동 섹션에서 이동 및 변환 옵션을 확장한 다음 데이터 흐름을 선택합니다.
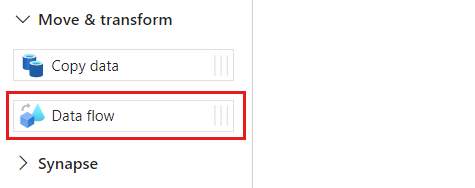
데이터 흐름 활동에 고유한 이름을 지정합니다. 이 예제에서 작업의 이름은
cosmoscdcactivity입니다.설정 탭에서 이 가이드의 앞부분에서 만든
cosmoscdc데이터 흐름을 선택합니다. 그런 다음, 데이터 볼륨 및 워크로드에 필요한 대기 시간을 기준으로 컴퓨팅 크기를 선택합니다.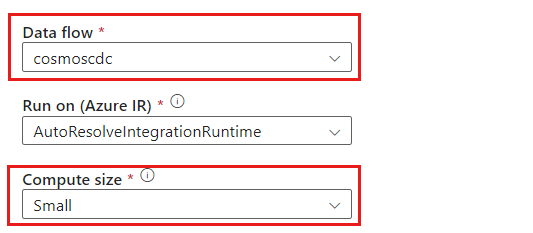
팁
100GB보다 큰 증분 데이터 크기의 경우 코어 수가 32개(+드라이버 코어 16개)인 사용자 지정 크기를 사용하는 것이 좋습니다.
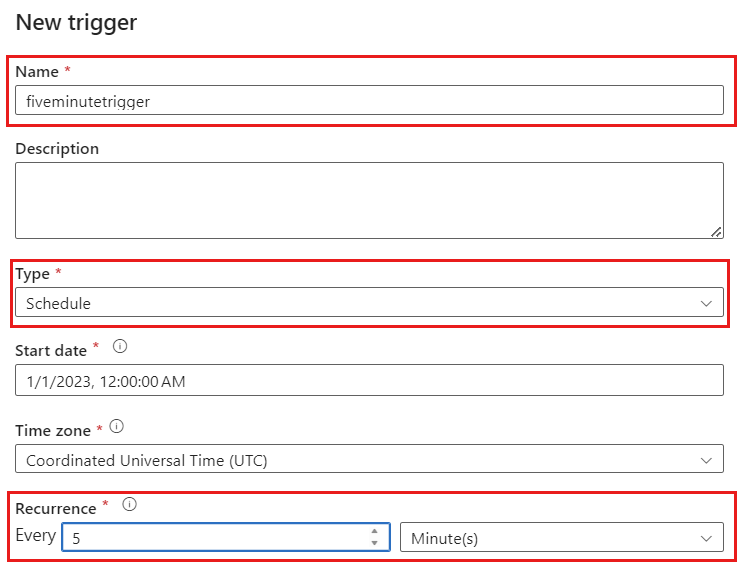
트리거 추가를 선택합니다. 워크로드에 적합한 주기로 실행되도록 이 파이프라인을 예약합니다. 이 예제에서는 파이프라인이 5분마다 실행되도록 구성됩니다.
참고 항목
변경 데이터 캡처 실행에 대한 최소 되풀이 기간은 1분입니다.
유효성 검사를 선택하여 오류 또는 누락이 발생하지 않았는지 확인합니다. 그런 다음, 게시를 선택하여 파이프라인을 게시합니다.
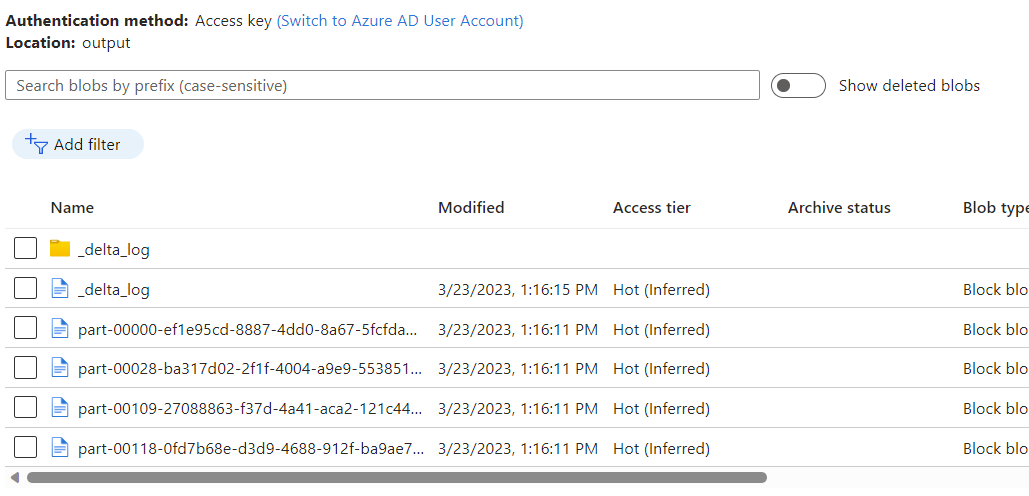
Azure Cosmos DB 분석 저장소 변경 데이터 캡처를 사용하여 데이터 흐름의 출력으로 Azure Blob Storage 컨테이너에 배치된 데이터를 관찰합니다.
참고 항목
초기 클러스터 시작 시간은 최대 3분이 걸릴 수 있습니다. 후속 변경 데이터 캡처 실행에서 클러스터 시작 시간을 방지하려면 데이터 흐름 클러스터 TL(Time to Live) 값을 구성합니다. 통합 런타임 및 TTL에 대한 자세한 내용은 Azure Data Factory의 통합 런타임을 참조하세요.
동시 작업
원본 옵션의 일괄 처리 크기 또는 싱크가 변경 스트림을 수집하는 속도가 느린 경우 동시에 여러 작업이 실행될 수 있습니다. 이 상황을 방지하려면 파이프라인 설정에서 동시성 옵션을 1로 설정하여 현재 실행이 완료될 때까지 새 실행이 트리거되지 않도록 합니다.