데이터 거버넌스 프로세스
데이터 거버넌스 프로세스에는 네 가지 범주가 있습니다.
| 프로세스 범주 | 프로세스 |
|---|---|
| 데이터 검색 프로세스를 데이터 환경 이해 | 데이터 및 데이터 개체 검색, 매핑 및 카탈로그 프로세스 데이터 품질을 결정하는 데이터 프로파일링 검색 프로세스 중요한 데이터 검색 및 거버넌스 분류 프로세스 엔터프라이즈 전체의 마스터 데이터와 같은 데이터의 사용 및 유지 관리를 이해하기 위해 로그 파일과 같은 CRUD 분석을 위한 데이터 유지 관리 검색 프로세스 |
| 데이터 거버넌스 정의 프로세스 | 비즈니스 용어집에서 마스터 데이터, 데이터 속성 이름, 데이터 무결성 규칙 및 유효한 형식을 포함한 데이터 엔터티를 정의하고, 일반적인 비즈니스 어휘를 생성 및 유지 관리합니다. 엔터프라이즈 전체에서 코드 집합을 표준화하는 참조 데이터 정의 데이터를 제어하는 방법을 결정하기 위해 데이터에 레이블을 지정하는 데이터 거버넌스 분류 체계 정의 데이터 엔터티 및 문서 수명 주기를 제어하는 데이터 거버넌스 정책 및 규칙 정의 성공 메트릭 및 임계값 정의 |
| 데이터 거버넌스 정책 및 규칙 적용 프로세스 | 데이터 거버넌스 정책 및 규칙의 애플리케이션 및 적용을 자동화하는 프로세스 정책 및 규칙을 수동으로 적용하고 강제하는 프로세스 이벤트 기반, 주문형 및 타이머 기반(일괄 처리) 데이터 거버넌스 프로세스는 다음을 제어하기 위해 호출할 수 있는 서비스로 게시됩니다. 데이터 수집 - 카탈로그, 분류, 소유자 할당 및 저장 데이터 품질 데이터 액세스 보안 데이터 개인정보 보호 예를 들어 공유를 비롯한 데이터 사용량 및 허가된 데이터가 승인된 용도로만 사용되는지 확인 마스터 데이터와 같은 데이터 유지 관리 데이터 보존 마스터 데이터 및 참조 데이터 동기화 |
| 모니터링 프로세스 | 데이터 사용 활동, 데이터 품질, 데이터 액세스 보안, 데이터 개인 정보, 데이터 유지 관리 및 데이터 보존 모니터링 및 감사 정책 규칙 위반 탐지 및 해결 모니터링 |
일반적인 비즈니스 어휘는 데이터 카탈로그 내의 비즈니스 용어집에 정의되어야 합니다.
데이터 거버넌스 작업 그룹은 데이터 정의 및 특정 데이터 도메인(예: 고객 또는 공급업체)을 계획하고 개발하며, 진행 상황을 데이터 거버넌스 제어 보드에 업데이트하고, 특정 도메인에 대한 기업 전체의 관리 책임을 관리합니다. 각 작업 그룹은 특정 데이터 엔터티 또는 여러 관련 엔터티와 같은 데이터 주체 영역을 정의해야 합니다. 그런 다음, 정책 및 규칙과 함께 어휘의 여러 데이터 엔터티를 병렬로 작업할 수 있습니다. 자세한 내용은 데이터 거버넌스 역할 및 책임 참조하세요.
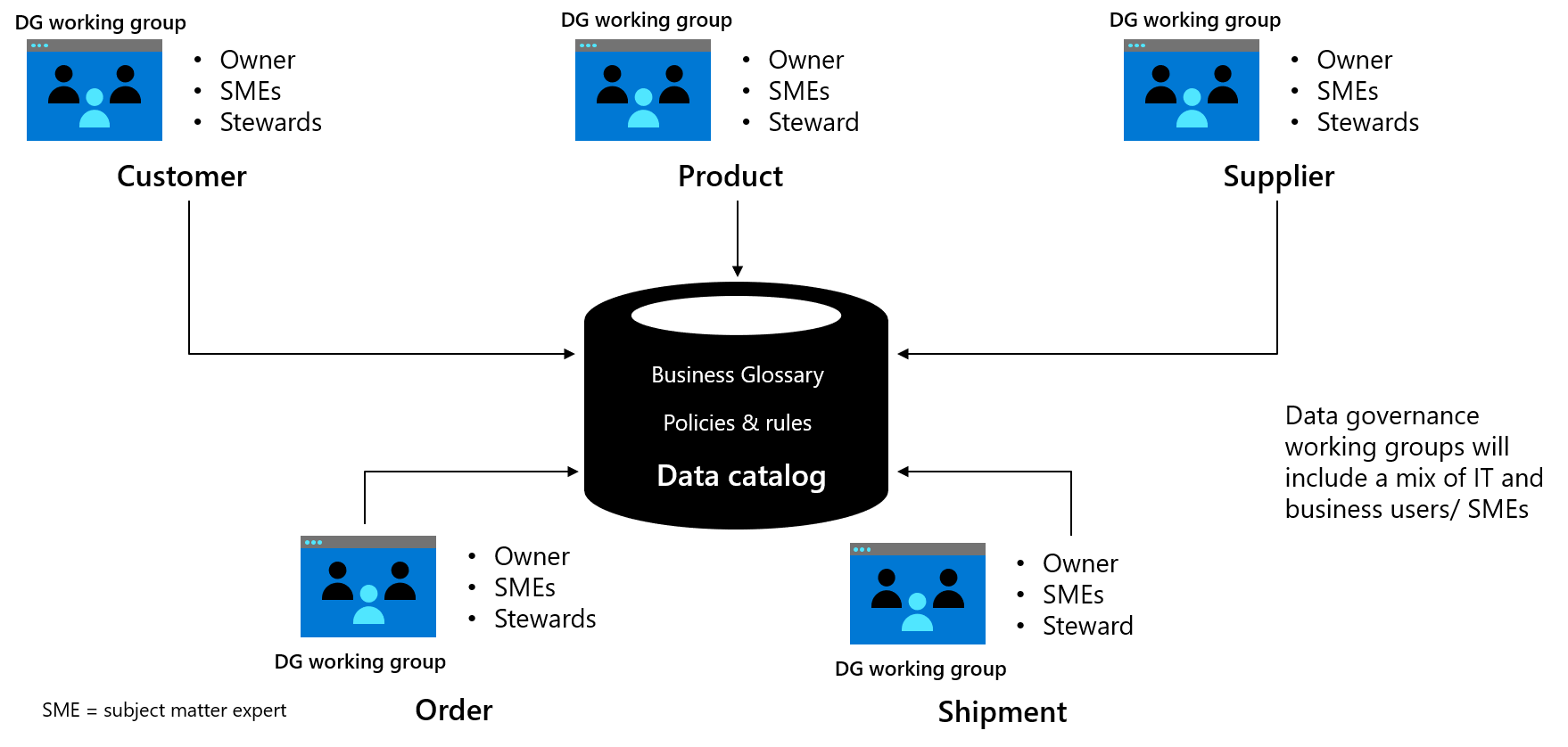 그림 1: 예제 데이터 거버넌스 작업 그룹
그림 1: 예제 데이터 거버넌스 작업 그룹
카탈로그 비즈니스 용어집을 다른 기술과 통합하여 모든 기술에 일관된 공통 데이터 이름을 가져와야 합니다. 통합할 다른 기술의 예는 다음과 같습니다.
- ETL(추출, 변환, 로드) 도구
- 데이터 모델링 도구
- BI 도구, 데이터베이스 관리 시스템
- 마스터 데이터 관리
- 데이터 가상화 도구
- 소프트웨어 개발 도구
일반적인 비즈니스 어휘를 만드는 좋은 방법은 데이터 개념 모델을 개발하는 것입니다. 이 모델은 하향식 접근 방식을 사용하여 일반적인 비즈니스 어휘에서 데이터 엔터티로 사용할 수 있는 데이터 개념을 식별합니다. 그런 다음 각 데이터 개념(엔터티) 또는 관련 데이터 개념 그룹(주체 영역)에 서로 다른 데이터 거버넌스 작업 그룹을 할당할 수 있습니다. 이러한 작업 그룹은 환경 전반에 걸쳐 다양한 데이터 엔터티를 제어할 책임이 있습니다.
일반적인 비즈니스 어휘를 빌드할 때 데이터 카탈로그 소프트웨어를 사용하여 여러 데이터 저장소에 존재하는 데이터를 자동으로 검색할 수 있습니다. 이 소프트웨어는 상향식 접근 방식인 특정 데이터 엔터티와 관련된 모든 특성을 식별하는 데 도움이 됩니다.
여러 작업 그룹은 데이터 개념 모델의 하향식 접근 방식과 자동화된 데이터 검색의 상향식 접근 방식을 결합하여 일반적인 비즈니스 어휘를 빠르게 증분 방식으로 빌드할 수 있습니다.
자동화된 데이터 검색에 데이터 카탈로그를 사용하면 서로 다른 데이터를 일반적인 어휘에 매핑할 수 있습니다. 데이터 카탈로그는 기업 전체에서 비즈니스 용어집의 각 특정 데이터 엔터티에 대한 데이터가 어디에 있는지 이해하는 데 도움이 될 수 있습니다.
수명 주기의 여러 지점에서 데이터를 제어하는 정책 및 규칙
데이터 거버넌스 정책은 무결성, 품질, 액세스 보안, 개인 정보 보호 및 데이터 보존을 제어하는 일련의 규칙을 설명합니다. 다음과 같은 다양한 유형의 정책이 있습니다.
- 유효한 값, 참조 무결성과 같은 데이터 무결성 정책
- 데이터 표준화, 정리 및 일치 규칙을 사용하는 데이터 품질 정책
- 액세스 보안 및 데이터 개인 정보 보호 규칙이 있는 데이터 보호 정책
- 보존, 보관 및 백업 규칙을 사용하여 수명 주기를 관리하는 데이터 보존 정책입니다. 여러 법적 관할권에서 동일한 데이터를 제어하려면 여러 버전의 정책이 필요할 수 있습니다.
데이터 기밀성 분류 체계 5가지 분류 수준이 있습니다.
- 공공의
- 내부 사용만
- 기밀
- 중요한 개인 데이터
- 제한
이 분류 체계를 정책 및 규칙과 결합하여 데이터를 제어합니다. 각 5개 수준을 사용하여 중요한 개인 데이터와 같은 데이터에 레이블을 지정합니다. 중요한 개인 데이터에 대한 규칙을 만들고 이러한 규칙을 정책에 연결하면 중요한 개인 데이터에 대한 정책을 만듭니다. 중요한 개인 데이터 레이블에 정책을 연결한 다음 중요한 개인 데이터 레이블을 데이터에 연결할 수 있습니다. 이러한 방식으로 중요한 개인 데이터로 레이블이 지정된 모든 데이터에는 동일한 정책 및 규칙이 적용됩니다. 이 프로세스는 태그 기반 정책 관리이라고 합니다. 개별 규칙 또는 정책을 독립적으로 변경할 수 있으므로 유연합니다. 중요한 개인 데이터에 레이블이 지정된 모든 데이터는 새 규칙의 적용을 받습니다. 민감한 개인정보 레이블을 데이터에서 분리하여 대신 기밀 레이블을 사용할 수 있습니다. 이 경우 데이터는 즉시 기밀 레이블과 연결된 새 정책 및 규칙 집합의 적용을 받습니다.
데이터 거버넌스 분류 체계의 각 클래스에 대한 정책 및 규칙을 데이터 카탈로그에 정의한 후에는 API를 통해 데이터 카탈로그의 다른 기술로 전달하여 적용할 수 있습니다. 대신, 여러 데이터 저장소에 연결할 수 있는 공통 데이터 관리 플랫폼은 잠재적으로 이를 적용할 수 있습니다.
그런 다음 수명 주기 동안 데이터 품질, 개인 정보 보호, 액세스 보안, 사용, 유지 관리 및 특정 데이터 엔터티의 보존을 모니터링할 수 있어야 합니다.