자습서: Batch Explorer, Storage Explorer 및 Python을 사용하여 Data Factory를 통해 Batch 작업 실행
이 자습서에서는 Azure Batch 워크로드를 실행하는 Azure Data Factory 파이프라인을 만들고 실행하는 과정을 안내합니다. Batch 노드에서 Python 스크립트를 실행하여 Azure Blob Storage 컨테이너에서 CSV(쉼표로 구분된 값) 입력을 가져오고, 데이터를 조작하고, 출력을 다른 스토리지 컨테이너에 씁니다. Batch Explorer를 사용하여 Batch 풀 및 노드를 만들고, Azure Storage Explorer를 사용하여 스토리지 컨테이너 및 파일 작업을 수행합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Batch Explorer를 사용하여 Batch 풀 및 노드를 만듭니다.
- Storage Explorer를 사용하여 스토리지 컨테이너를 만들고 입력 파일을 업로드합니다.
- 입력 데이터를 조작하고 출력을 생성하는 Python 스크립트를 개발합니다.
- Batch 워크로드를 실행하는 Data Factory 파이프라인을 만듭니다.
- Batch Explorer를 사용하여 출력 로그 파일을 살펴봅니다.
필수 조건
- 활성 구독이 있는 Azure 계정. 아직 없는 경우 체험 계정을 만들 수 있습니다.
- 연결된 Azure Storage 계정이 있는 배치 계정. 다음 방법 중 하나를 사용하여 계정을 만들 수 있습니다. Azure Portal | Azure CLI | Bicep | ARM 템플릿 | Terraform.
- Data Factory 인스턴스입니다. 데이터 팩터리를 만들려면 데이터 팩터리 만들기의 지침을 따릅니다.
- Batch Explorer가 다운로드되어 설치되었습니다.
- Storage Explorer가 다운로드되어 설치되었습니다.
- Azure-storage-blob 패키지를 사용하여
pip설치한 Python 3.8 이상. - GitHub에서 다운로드한 iris.csv 입력 데이터 세트.
Batch Explorer를 사용하여 Batch 풀 및 노드 만들기
Batch Explorer를 사용하여 워크로드를 실행할 컴퓨팅 노드 풀을 만듭니다.
Azure 자격 증명을 사용하여 Batch Explorer에 로그인합니다.
배치 계정 선택
왼쪽 사이드바에서 풀을 선택한 다음 + 아이콘을 선택하여 풀을 추가합니다.
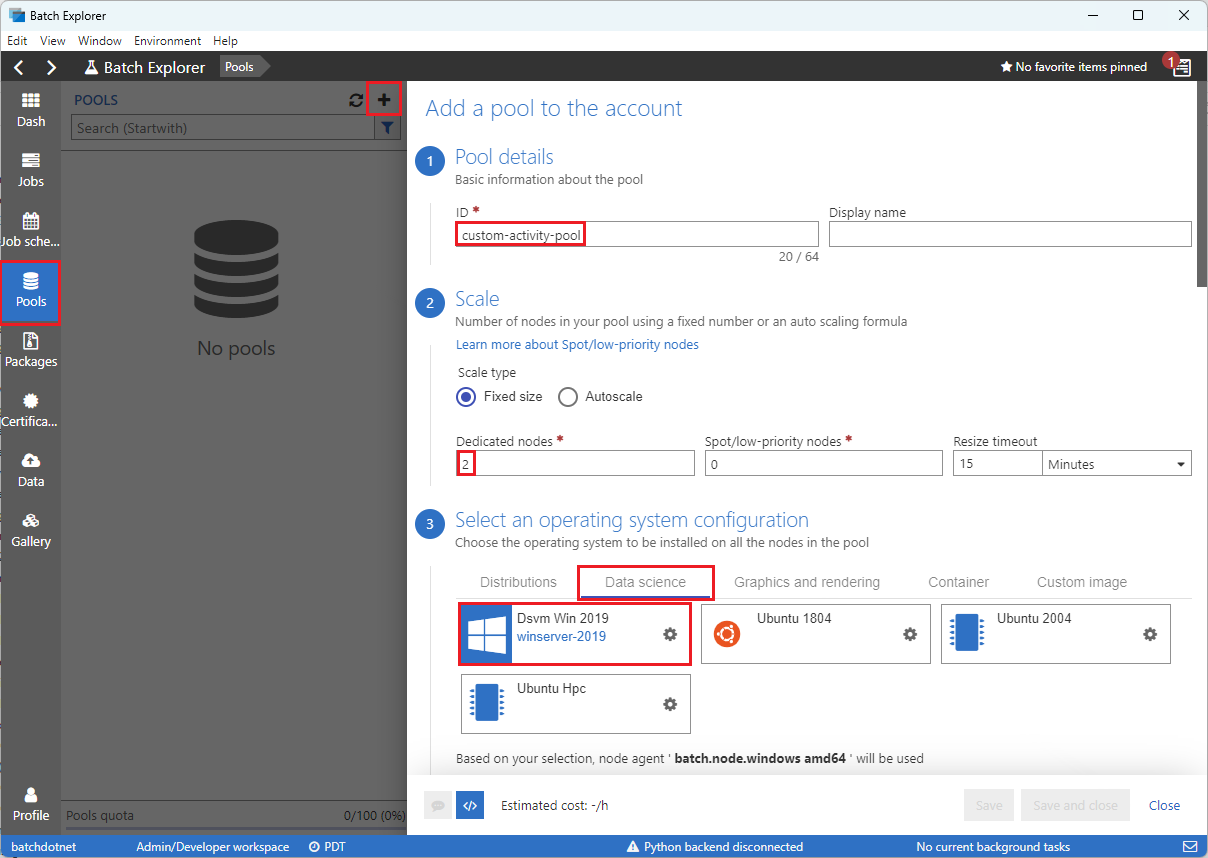
다음과 같이 계정에 풀 추가 양식을 작성합니다.
- ID 아래에 custom-activity-pool을 입력합니다.
- 전용 노드에 2를 입력합니다.
- 운영 체제 구성 선택에서 데이터 과학 탭을 선택한 다음 Dsvm Win 2019를 선택합니다.
- 가상 머신 크기 선택에서 Standard_F2s_v2를 선택합니다.
- 작업 시작에서 시작 태스크 추가를 선택합니다.
태스크 시작 화면의 명령줄에서
cmd /c "pip install azure-storage-blob pandas"를 입력한 다음 선택을 선택합니다. 이 명령은 시작 시 각 노드에azure-storage-blob패키지를 설치합니다.
저장 후 닫기를 선택합니다.

Storage Explorer를 사용하여 Blob 컨테이너 만들기
Storage Explorer를 사용하여 입력 및 출력 파일을 저장하는 Blob 컨테이너를 만든 다음, 입력 파일을 업로드합니다.
- Azure 자격 증명을 사용하여 Storage Explorer에 로그인합니다.
- 왼쪽 사이드바에서 배치 계정에 연결된 스토리지 계정을 찾아서 확장합니다.
- Blob 컨테이너를 마우스 오른쪽 단추로 클릭하고 Blob 컨테이너 만들기를 선택하거나 사이드바 하단의 작업에서 Blob 컨테이너 만들기를 선택합니다.
- 입력 필드에 input을 입력합니다.
- output이라는 또 다른 blob 컨테이너를 만듭니다.
- 입력 컨테이너를 선택한 다음 오른쪽 창에서 업로드>파일 업로드를 선택합니다.
- 파일 업로드 화면의 선택한 파일에서 입력 필드 옆에 있는 줄임표 ...를 선택합니다.
- 다운로드한 iris.csv 파일의 위치를 찾아 열기를 선택한 다음 업로드를 선택합니다.

Python 스크립트 개발
다음 Python 스크립트는 Storage Explorer 입력 컨테이너에서 iris.csv 데이터 세트 파일을 로드하고, 데이터를 조작하고, 결과를 출력 컨테이너에 저장합니다.
스크립트는 배치 계정에 연결된 Azure Storage 계정에 대한 연결 문자열을 사용해야 합니다. 연결 문자열을 가져오려면 다음을 수행합니다.
- Azure Portal에서 배치 계정에 연결된 스토리지 계정의 이름을 검색하고 선택합니다.
- 스토리지 계정 페이지의 보안 + 네트워킹 아래 왼쪽 탐색 메뉴에서 액세스 키를 선택합니다.
- key1에서 연결 문자열 옆에 있는 표시를 선택한 다음 복사 아이콘을 선택하여 연결 문자열을 복사합니다.
연결 문자열을 다음 스크립트에 붙여넣고 <storage-account-connection-string> 자리 표시자를 바꿉니다. 스크립트를 main.py라는 파일로 저장합니다.
Important
프로덕션 용도로 앱 원본에 계정 키를 노출하지 않는 것이 좋습니다. 자격 증명에 대한 액세스를 제한하고 변수나 구성 파일을 사용하여 코드에서 이를 참조해야 합니다. Azure Key Vault에 Batch 및 스토리지 계정 키를 저장하는 것이 가장 좋습니다.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Azure Blob Storage 작업에 대한 자세한 내용은 Azure Blob Storage 설명서를 참조 하세요.
스크립트를 로컬에서 실행하여 기능을 테스트하고 유효성을 검사합니다.
python main.py
스크립트는 Species = setosa인 데이터 레코드만 포함하는 iris_setosa.csv라는 출력 파일을 생성해야 합니다. 올바르게 작동하는지 확인한 후 main.py 스크립트 파일을 Storage Explorer input 컨테이너에 업로드합니다.
Data Factory 파이프라인 설정
Python 스크립트를 사용하는 Data Factory 파이프라인을 만들고 유효성을 검사합니다.
계정 정보 가져오기
Data Factory 파이프라인은 Batch 및 스토리지 계정 이름, 계정 키 값 및 배치 계정 엔드포인트를 사용합니다. Azure Portal에서 이 정보를 가져오려면:
Azure Search 창에서 배치 계정 이름을 검색하고 선택합니다.
배치 계정 페이지의 왼쪽 탐색 메뉴에서 키를 선택합니다.
키 페이지에서 다음 값을 복사합니다.
- Batch 계정
- 계정 엔드포인트
- 기본 액세스 키
- 스토리지 계정 이름
- Key1
파이프라인 만들기 및 실행
Azure Data Factory Studio가 아직 시작되지 않은 경우 Azure Portal의 Data Factory 페이지에서 Launch 스튜디오를 선택합니다.
Data Factory Studio의 왼쪽 탐색 메뉴에서 작성자 연필 아이콘을 선택합니다.
팩터리 리소스에서 + 아이콘을 선택한 다음 파이프라인을 선택합니다.
오른쪽의 속성 창에서 파이프라인 이름을 Python 실행으로 변경합니다.
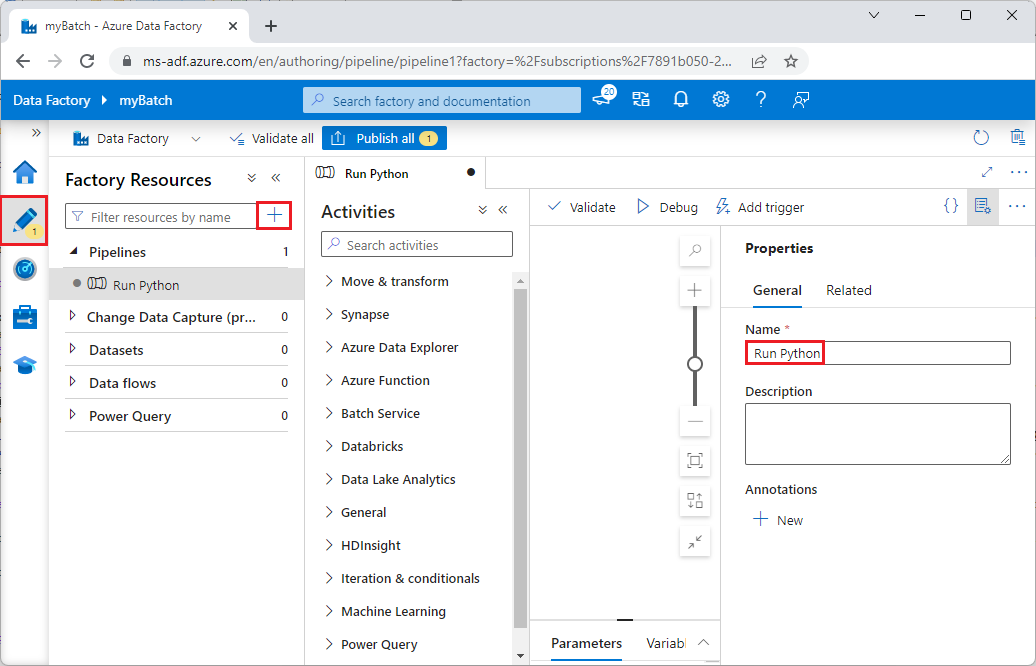
작업 창에서 Batch 서비스를 확장하고 사용자 지정 작업을 파이프라인 디자이너 화면으로 끌어옵니다.
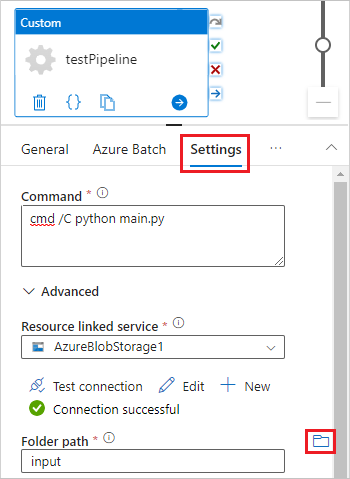
디자이너 캔버스 아래의 일반 탭에서 이름 아래에 testPipeline을 입력합니다.
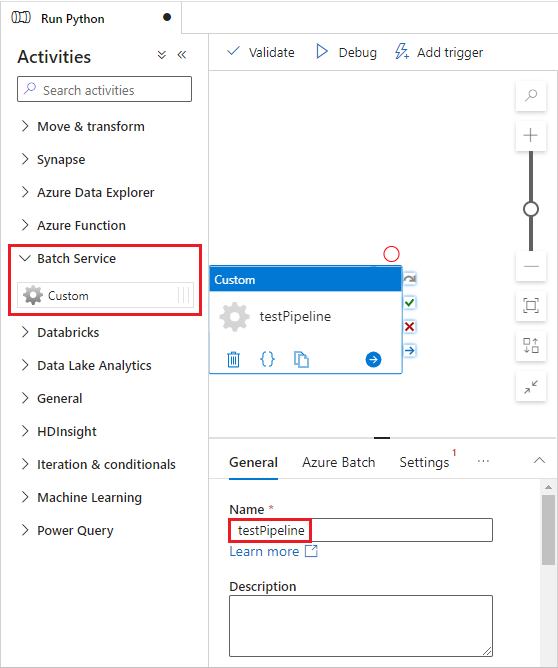
Azure Batch 탭을 선택한 다음 새로 만들기를 선택합니다.
다음과 같이 새 연결된 서비스 양식을 작성합니다.
- 이름: AzureBatch1과 같은 연결된 서비스의 이름을 입력합니다.
- 액세스 키: 배치 계정에서 복사한 기본 액세스 키를 입력합니다.
- 계정 이름: 배치 계정 이름을 입력합니다.
- Batch URL: 배치 계정에서 복사한 계정 엔드포인트를 입력합니다(예:
https://batchdotnet.eastus.batch.azure.com). - 풀 이름: Batch Explorer에서 만든 풀인 custom-activity-pool을 입력합니다.
- 스토리지 계정 연결 서비스 이름: 새로 만들기를 선택합니다. 다음 화면에서 AzureBlobStorage1과 같은 연결된 스토리지 서비스의 이름을 입력하고 Azure 구독 및 연결된 스토리지 계정을 선택한 다음 만들기를 선택합니다.
Batch 새 연결된 서비스 화면 하단에서 연결 테스트를 선택합니다. 연결에 성공하면 만들기를 선택합니다.
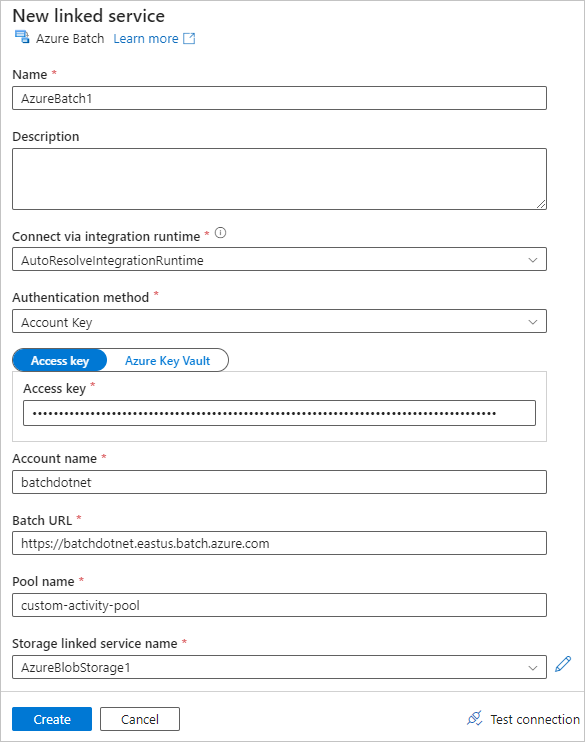
설정 탭을 선택하고 다음 설정을 입력하거나 선택합니다.
- 명령:
cmd /C python main.py를 입력합니다. - 리소스 연결 서비스: AzureBlobStorage1과 같이 만든 연결 스토리지 서비스를 선택하고 연결을 테스트하여 성공하는지 확인합니다.
- 폴더 경로: 폴더 아이콘을 선택한 다음 입력 컨테이너를 선택하고 확인을 선택합니다. Python 스크립트가 실행되기 전에 이 폴더의 파일이 컨테이너에서 풀 노드로 다운로드됩니다.
- 명령:
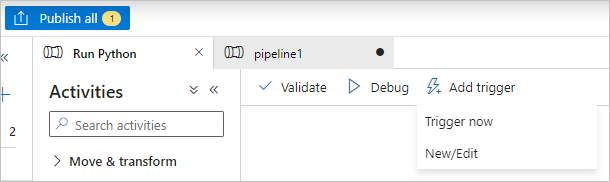
파이프라인 도구 모음에서 유효성 검사을 선택하여 파이프라인의 유효성을 검사합니다.
디버그를 선택하여 파이프라인을 테스트하고 올바르게 작동하는지 확인합니다.
파이프라인을 게시하려면 모두 게시를 선택합니다.
트리거 추가를 선택한 다음 지금 트리거를 선택하여 파이프라인을 실행하거나 새로 만들기/편집을 선택하여 예약합니다.

Batch Explorer를 사용하여 로그 파일 보기
파이프라인 실행 시 경고나 오류가 발생하는 경우 Batch Explorer를 사용하여 stdout.txt 및 stderr.txt 출력 파일에서 자세한 내용을 확인할 수 있습니다.
- Batch Explorer의 왼쪽 사이드바에서 작업을 선택합니다.
- adfv2-custom-activity-pool 작업을 선택합니다.
- 오류 종료 코드가 있는 태스크를 선택합니다.
- 문제를 조사하고 진단하려면 stdout.txt 및 stderr.txt 파일을 확인합니다.
리소스 정리
배치 계정, 작업 및 태스크는 무료이지만 컴퓨팅 노드는 작업을 실행하지 않는 경우에도 요금이 발생합니다. 필요한 경우에만 노드 풀을 할당하고 작업이 끝나면 풀을 삭제하는 것이 가장 좋습니다. 풀을 삭제하면 노드의 모든 태스크 출력과 노드 자체가 삭제됩니다.
입력 파일 및 출력 파일은 스토리지 계정에 남아 있으며 요금이 발생할 수 있습니다. 파일이 더 이상 필요하지 않으면 파일이나 컨테이너를 삭제할 수 있습니다. 배치 계정 또는 연결된 스토리지 계정이 더 이상 필요하지 않으면 삭제할 수 있습니다.
다음 단계
이 자습서에서는 Batch Explorer, Storage Explorer 및 Data Factory와 함께 Python 스크립트를 사용하여 Batch 워크로드를 실행하는 방법을 알아보았습니다. Data Factory에 대한 자세한 내용은 Azure Data Factory란?를 참조하세요.