Azure SQL Managed Instance에 대한 장애 조치(failover) 그룹 구성
적용 대상: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 Azure Portal 및 Azure PowerShell을 사용하여 Azure SQL Managed Instance에 대한 장애 조치(failover) 그룹을 구성하는 방법을 설명합니다.
장애 조치(failover) 그룹 내에서 두 인스턴스를 생성하는 엔드투엔드 PowerShell 스크립트의 경우 PowerShell을 사용하여 장애 조치(failover) 그룹에 인스턴스 추가를 검토하세요.
필수 조건
장애 조치(failover) 그룹을 구성하려면 주 인스턴스로 사용하려는 적절한 권한 및 SQL 관리형 인스턴스가 이미 있어야 합니다. 시작하려면 인스턴스 만들기를 검토하세요.
보조 인스턴스 및 장애 조치(failover) 그룹을 만들기 전에 제한 사항을 검토해야 합니다.
구성 요구 사항
주 및 보조 SQL Managed Instance 간에 장애 조치(failover) 그룹을 구성하려면 다음 요구 사항을 고려합니다.
- 보조 관리형 인스턴스는 비어 있어야 하며, 사용자 데이터베이스를 포함하지 않아야 합니다.
- 두 인스턴스는 같은 서비스 계층이어야 하고 스토리지 크기는 같아야 합니다. 필수는 아니지만 보조 인스턴스가 최대 작업 기간을 포함하여 주 인스턴스에서 복제되는 변경 내용을 지속적으로 처리할 수 있도록 두 인스턴스의 컴퓨팅 크기가 같도록 하는 것이 좋습니다.
- 주 인스턴스의 가상 네트워크에 대한 IP 주소 범위는 보조 관리형 인스턴스에 대한 가상 네트워크의 주소 범위나 주 또는 보조 가상 네트워크와 피어링되는 다른 가상 네트워크와 겹치지 않아야 합니다.
- 두 인스턴스는 모두 동일한 DNS 영역에 있어야 합니다. 보조 관리형 인스턴스를 생성할 때 주 인스턴스의 DNS 영역 ID를 지정해야 합니다. 그렇지 않으면 각 가상 네트워크에서 첫 번째 인스턴스가 생성되고 동일한 서브넷의 다른 모든 인스턴스에 같은 ID가 할당될 때 영역 ID는 임의의 문자열로 생성됩니다. ID가 할당되면 DNS 영역을 수정할 수 없습니다.
- 두 인스턴스의 서브넷에 대한 NSG(네트워크 보안 그룹) 규칙은 두 인스턴스 간의 통신을 지원하려면 포트 5022 및 포트 범위 11000-11999에 대해 열린 인바운드 및 아웃바운드 TCP 연결이 있어야 합니다.
- 성능상의 이유로 관리되는 인스턴스를 쌍으로 연결된 지역에 배포해야 합니다. 지리적으로 쌍을 이루는 지역에 있는 관리형 인스턴스는 쌍을 이루지 않는 지역에 비해 지리적 복제 속도가 훨씬 더 빨라질 수 있습니다.
- 두 인스턴스 모두 동일한 업데이트 정책을 사용해야 합니다.
보조 인스턴스 만들기
보조 인스턴스를 만들 때 주 인스턴스의 IP 주소 공간 범위와 겹치지 않는 IP 주소 공간이 있는 가상 네트워크를 사용해야 합니다. 또한 새 보조 인스턴스를 구성할 때 주 인스턴스의 영역 ID를 지정해야 합니다.
Azure Portal 및 PowerShell을 사용하여 보조 가상 네트워크를 구성하고 보조 인스턴스를 만들 수 있습니다.
가상 네트워크 만들기
Azure Portal에서 보조 인스턴스의 가상 네트워크를 생성하려면 다음 단계를 수행합니다.
주 인스턴스의 주소 공간을 확인합니다. Azure Portal에서 주 인스턴스의 가상 네트워크 리소스로 이동하여 설정 아래에서 주소 공간을 선택합니다. 주소 범위 아래 범위를 확인합니다.
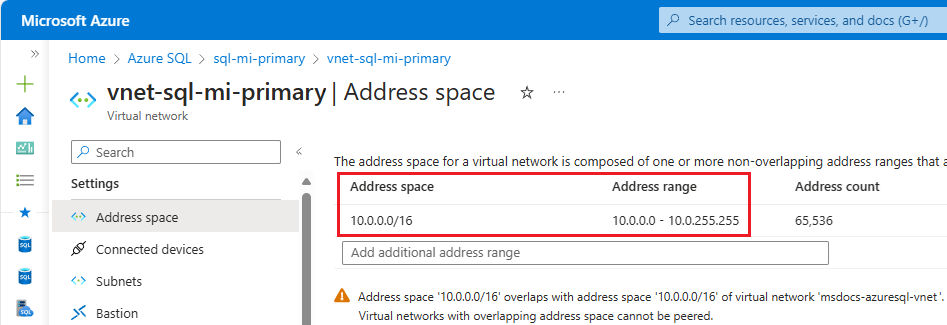
가상 네트워크 만들기 페이지로 이동하여 보조 인스턴스에 사용할 새 가상 네트워크를 만듭니다.
가상 네트워크 만들기 페이지의 기본 사항 탭에서 다음을 수행합니다.
- 보조 인스턴스에 사용할 리소스 그룹을 선택합니다. 없는 경우 새 항목을 만듭니다.
- 가상 네트워크의 이름(예:
vnet-sql-mi-secondary)을 입력합니다. - 주 인스턴스가 있는 지역과 쌍 을 이루는 지역을 선택합니다.
가상 네트워크 만들기 페이지의 IP 주소 탭에서 다음을 수행합니다.
- 주소 공간 삭제를 사용하여 기존 IPv4 주소 공간을 삭제합니다.
- 주소 공간이 삭제된 후 IPv4 주소 공간 추가를 선택하여 새 공간을 추가한 다음, 주 인스턴스의 가상 네트워크에서 사용하는 주소 공간과 다른 IP 주소 공간을 제공합니다. 예를 들어 현재 주 인스턴스에서 10.0.0.16의 주소 공간을 사용하는 경우 보조 인스턴스에 사용하려는 가상 네트워크의 주소 공간에 대하여
10.1.0.0/16을 입력합니다. - + 서브넷 추가를 사용하여 기본값이 있는 기본 서브넷을 추가합니다.
- + 서브넷 추가를 사용하여 기본 서브넷 과 다른 주소 범위를 사용하여 보조 인스턴스 전용의
ManagedInstance라는 이름의 빈 서브넷을 추가합니다. 예를 들어 주 인스턴스에서 주소 범위 10.0.0.0 - 10.0.255.255를 사용하는 경우 보조 인스턴스의 서브넷에 대하여10.1.1.0 - 10.1.1.255의 서브넷 범위를 제공합니다.
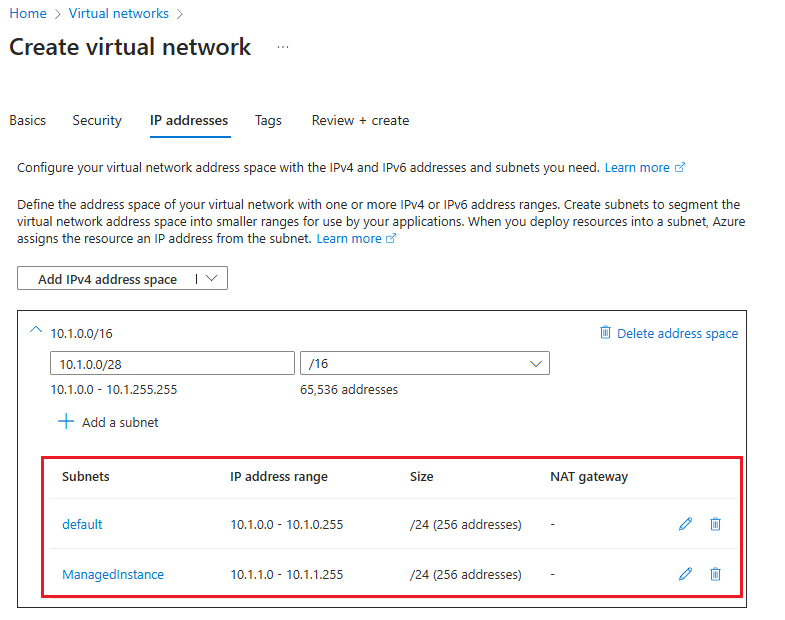
검토 + 만들기를 사용하여 설정을 검토한 다음 만들기를 선택하여 새 가상 네트워크를 생성합니다.

보조 인스턴스 만들기
가상 네트워크가 준비된 후 다음 단계를 수행하여 Azure Portal에서 보조 인스턴스를 생성합니다.
Azure Portal의 Azure SQL Managed Instance 만들기로 이동합니다.
Azure SQL Managed Instance 만들기 페이지의 기본 탭에서 다음을 수행합니다.
- 주 인스턴스와 쌍을 이루는 보조 인스턴스의 지역을 선택합니다.
- 주 인스턴스의 서비스 계층과 일치하는 서비스 계층을 선택합니다.
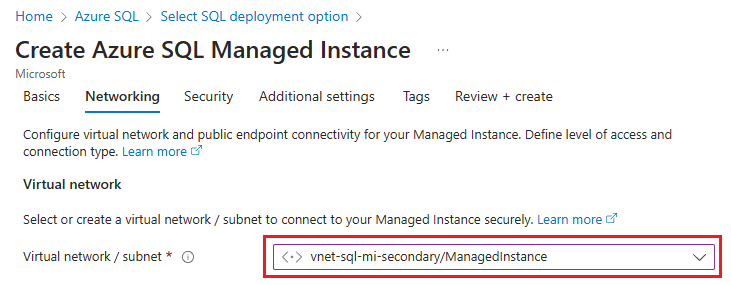
Azure SQL Managed Instance 만들기 페이지의 네트워킹 탭에서 가상 네트워크/서브넷 아래의 드롭다운 목록을 사용하여 이전에 만든 가상 네트워크 및 서브넷을 선택합니다.
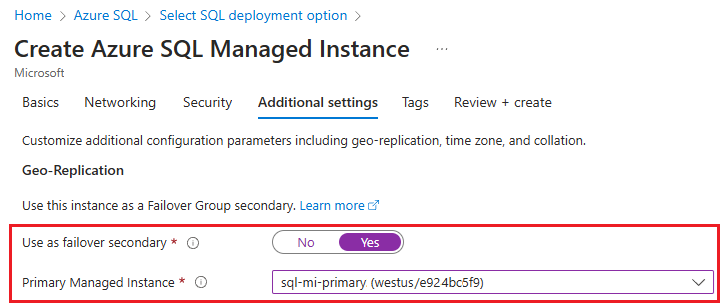
Azure SQL Managed Instance 만들기 페이지의 추가 설정 탭에서 예를 선택하여 장애 조치(failover)를 보조로 사용한 다음 드롭다운 목록에서 적절한 주 인스턴스를 선택합니다.
비즈니스 요구 사항에 따라 인스턴스의 나머지 부분을 구성한 다음 검토 + 만들기를 사용하여 인스턴스를 만듭니다.

인스턴스 간 연결 설정
중단 없는 지역에서 복제 트래픽 흐름의 경우 주 인스턴스와 보조 인스턴스를 호스팅하는 가상 네트워크 서브넷 간의 연결을 설정해야 합니다. 서로 다른 Azure 지역의 관리형 인스턴스 간을 연결하는 여러 가지 방법이 있으며, 다음을 포함합니다.
- 전역 가상 네트워크 피어링
- Azure ExpressRoute
- VPN 게이트웨이
글로벌 가상 네트워크 피어링은 장애 조치(failover) 그룹의 두 인스턴스 간에 연결을 설정하는 가장 성능이 뛰어나고 강력한 방법으로 권장됩니다. 글로벌 가상 네트워크 피어링에서는 Microsoft 백본 인프라를 사용하여 피어링된 가상 네트워크 사이에 대기 시간이 짧고 대역폭이 높은 프라이빗 연결을 제공합니다. 피어링된 가상 네트워크 간의 통신에 공용 인터넷, 게이트웨이, 또는 추가 암호화가 필요하지 않습니다.
중요
추가 네트워킹 디바이스가 포함된 인스턴스를 연결하는 또 다른 방법이 있지만 연결 또는 복제 속도 문제 해결이 복잡해지고 네트워크 관리자의 적극적인 참여가 요구되며 해결 시간이 상당히 길어질 수 있습니다.
인스턴스 간의 연결을 제공하기 위해 권장 글로벌 가상 네트워크 피어링 외에 다른 메커니즘을 사용하는 경우 다음을 확인해야 합니다.
- 방화벽 또는 NVA(네트워크 가상 어플라이언스) 등의 네트워킹 디바이스는 포트 5022(TCP) 및 포트 범위 11000-11999에 대한 인바운드 및 아웃바운드 연결의 트래픽을 차단하지 않습니다.
- 라우팅이 제대로 구성되어 있고 비대칭 라우팅이 방지됩니다.
- 허브 및 스포크 네트워크 토폴로지 교차 지역에 장애 조치(failover) 그룹을 배포하는 경우 연결 및 복제 속도 문제를 피하려면 복제 트래픽은 허브 네트워크를 통해 지시되지 않고 두 관리형 인스턴스 서브넷 간에 직접 이동해야 합니다.
이 문서에서는 Azure Portal과 PowerShell을 사용하여 두 인스턴스의 네트워크 간에 글로벌 가상 네트워크 피어링을 구성하는 방법을 안내합니다.
Azure Portal에서 주 관리되는 인스턴스의 가상 네트워크 리소스로 이동합니다.
설정에서 피어링을 선택하여 피어링 페이지를 연 다음 명령 모음에서 + 추가를 사용하여 피어링 추가 페이지를 엽니다.
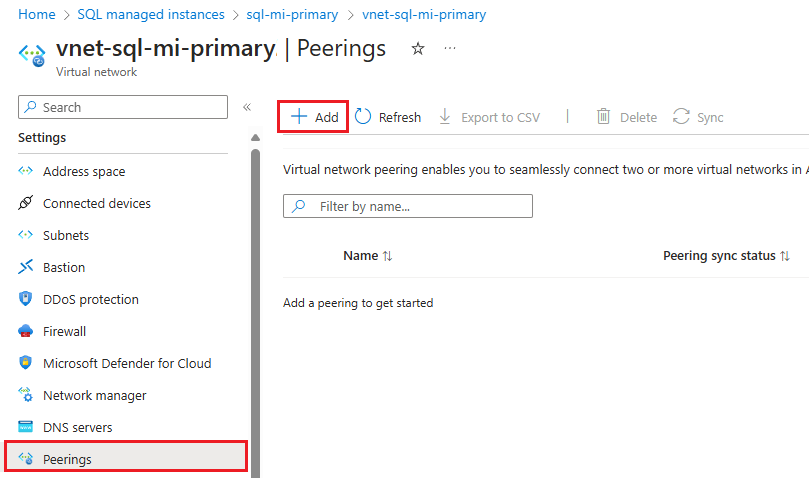
피어링 추가 페이지에서 다음 설정을 위한 값을 입력하거나 선택합니다.
설정 설명 원격 가상 네트워크 요약 피어링 링크 이름 피어링의 이름은 가상 네트워크 내에서 고유해야 합니다. 이 문서에서는 Fog-peering을 사용합니다.가상 네트워크 배포 모델 리소스 관리자를 선택합니다. 리소스 ID를 알고 있음 리소스 ID를 알지 못하면 이 상자를 선택 취소 상태로 둘 수 있습니다. 구독 드롭다운 목록에서 구독을 선택합니다. 가상 네트워크 드롭다운 목록에서 보조 인스턴스의 가상 네트워크를 선택합니다. 원격 가상 네트워크 피어링 설정 '보조 가상 네트워크'가 '기본 가상 네트워크'에 액세스하도록 허용 두 네트워크 간의 통신을 허용하려면 확인란을 선택합니다. 가상 네트워크 간의 통신을 사용하도록 설정하면 두 가상 네트워크 중 하나에 연결된 리소스가 동일한 가상 네트워크에 연결된 것처럼 동일한 대역폭 및 대기 시간으로 서로 통신할 수 있습니다. 두 가상 네트워크의 리소스 간 모든 통신은 Azure 프라이빗 네트워크를 통해 이루어집니다. '보조 가상 네트워크'가 '기본 가상 네트워크'에서 전달된 트래픽을 수신하도록 허용 이 확인란을 선택하거나 선택 취소할 수 있습니다. 이 가이드에서는 둘 다 가능합니다. 자세한 내용은 피어링 만들기를 참조하세요. '보조 가상 네트워크'의 게이트웨이 또는 경로 서버가 트래픽을 '기본 가상 네트워크'로 전달하도록 허용 이 확인란을 선택하거나 선택 취소할 수 있습니다. 이 가이드에서는 둘 다 가능합니다. 자세한 내용은 피어링 만들기를 참조하세요. '보조 가상 네트워크'를 사용하여 '기본 가상 네트워크의 원격 게이트웨이 또는 경로 서버' 사용 이 확인란을 선택하지 않은 상태로 둡니다. 사용 가능한 다른 옵션에 대한 자세한 내용은 피어링 만들기를 참조하세요. 로컬 가상 네트워크 요약 피어링 링크 이름 원격 가상 네트워크에 사용되는 동일한 피어링 이름입니다. 이 문서에서는 Fog-peering을 사용합니다.'기본 가상 네트워크'가 '보조 가상 네트워크'에 액세스하도록 허용 두 네트워크 간의 통신을 허용하려면 확인란을 선택합니다. 가상 네트워크 간의 통신을 사용하도록 설정하면 두 가상 네트워크 중 하나에 연결된 리소스가 동일한 가상 네트워크에 연결된 것처럼 동일한 대역폭 및 대기 시간으로 서로 통신할 수 있습니다. 두 가상 네트워크의 리소스 간 모든 통신은 Azure 프라이빗 네트워크를 통해 이루어집니다. '주 가상 네트워크'가 '보조 가상 네트워크'에서 전달된 트래픽을 수신하도록 허용 이 확인란을 선택하거나 선택 취소할 수 있습니다. 이 가이드에서는 둘 다 가능합니다. 자세한 내용은 피어링 만들기를 참조하세요. '기본 가상 네트워크'의 게이트웨이 또는 경로 서버가 트래픽을 '보조 가상 네트워크'로 전달하도록 허용 이 확인란을 선택하거나 선택 취소할 수 있습니다. 이 가이드에서는 둘 다 가능합니다. 자세한 내용은 피어링 만들기를 참조하세요. '주 가상 네트워크'를 사용하여 '보조 가상 네트워크의 원격 게이트웨이 또는 경로 서버'를 사용하도록 설정 이 확인란을 선택하지 않은 상태로 둡니다. 사용 가능한 다른 옵션에 대한 자세한 내용은 피어링 만들기를 참조하세요. 추가를 사용하여 선택한 가상 네트워크로 피어링을 구성하고, 두 네트워크가 연결되어 있음을 보여주는 피어링 페이지로 자동으로 다시 이동합니다.
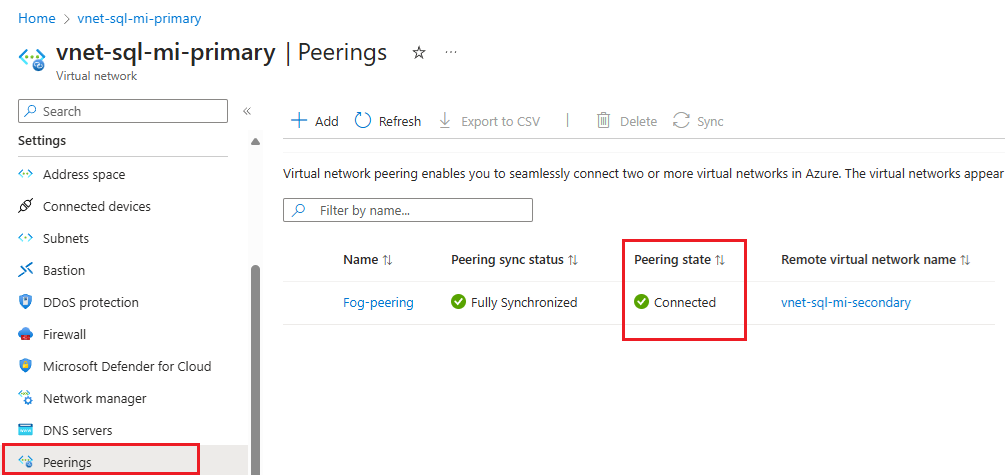
포트 및 NSG 규칙 구성
선택한 두 인스턴스 간 연결 메커니즘에 관계없이 네트워크는 지역 복제 트래픽 흐름에 대한 다음 요구 사항을 충족해야 합니다.
- 관리형 인스턴스 서브넷에 할당된 경로 테이블 및 네트워크 보안 그룹은 피어링된 두 가상 네트워크에서 공유되지 않습니다.
- 각 인스턴스를 호스트하는 두 서브넷에 대한 NSG(네트워크 보안 그룹) 규칙은 포트 5022의 다른 인스턴스에 대한 인바운드 및 아웃바운드 트래픽과 포트 범위 11000-11999를 모두 허용합니다.
Azure Portal 및 PowerShell을 사용하여 포트 통신 및 NSG 규칙을 구성할 수 있습니다.
Azure Portal에서 NSG(네트워크 보안 그룹) 포트를 열려면 다음 단계를 수행합니다.
기본 인스턴스에 대한 네트워크 보안 그룹 리소스로 이동합니다.
설정 아래에서 인바운드 보안 규칙을 선택합니다. 포트 5022 및 범위 11000-11999에 대해 트래픽을 허용하는 규칙이 이미 있는지 확인합니다. 규칙이 있는 경우 원본이 비즈니스 요구 사항을 충족하는 경우 이 단계를 건너뜁니다. 규칙이 없거나 다른 원본(예: 더 안전한 IP 주소)을 사용하려는 경우 기존 규칙을 삭제한 다음 명령 모음에서 + 추가를 선택하여 인바운드 보안 규칙 추가 창을 엽니다.
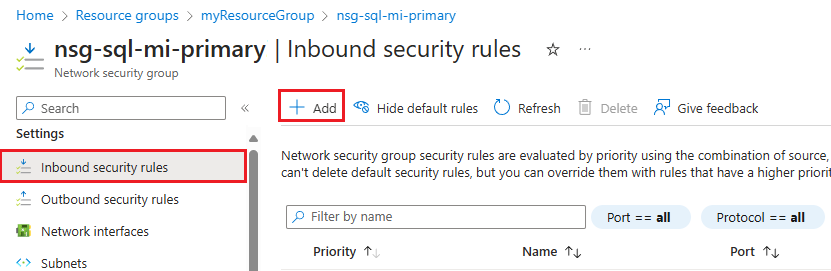
인바운드 보안 규칙 추가 창에서 다음 설정에 대한 값을 입력하거나 선택합니다.
설정 권장되는 값 설명 원본 IP 주소 또는 서비스 태그 통신 원본에 대한 필터입니다. IP 주소가 가장 안전하며 프로덕션 환경에 권장됩니다. 서비스 태그는 개발 및 테스팅 환경에 적합합니다. 원본 서비스 태그 서비스 태그를 원본으로 선택한 경우 원본 태그로 VirtualNetwork를 제공합니다.기본 태그는 IP 주소의 범주를 나타내는 미리 정의된 식별자입니다. VirtualNetwork 태그는 모든 가상 및 로컬 네트워크 주소 공간을 나타냅니다. 원본 IP 주소 IP 주소를 원본으로 선택한 경우 보조 인스턴스의 IP 주소를 제공합니다. CIDR 표기법(예: 192.168.99.0/24 또는 2001:1234::/64) 또는 IP 주소(예: 192.168.99.0 또는 2001:1234::)를 사용하여 주소 범위를 제공합니다. IPv4 또는 IPv6를 사용하여 쉼표로 구분된 IP 주소 및/또는 주소 범위 목록을 제공해도 됩니다. 원본 포트 범위 5022 이는 이 규칙이 허용되는 포트 트래픽을 지정합니다. 서비스 사용자 지정 서비스는 이 규칙의 대상 프로토콜 및 포트 범위를 지정합니다. 대상 포트 범위 5022 이는 이 규칙이 허용되는 포트 트래픽을 지정합니다. 이 포트는 원본 포트 범위와 일치해야 합니다. 작업 허용 지정된 포트에서 통신을 허용합니다. 프로토콜 TCP 포트 통신에 대한 프로토콜을 결정합니다. 우선 순위 1200 규칙은 우선 순위대로 처리됩니다. 숫자가 작을수록 우선 순위가 높습니다. 속성 allow_geodr_inbound 규칙 이름입니다. 설명 선택 사항 설명을 제공하거나 이 필드를 비워 두도록 선택할 수 있습니다. 추가를 선택하여 설정을 저장하고 새 규칙을 추가합니다.
이러한 단계를 반복하여 allow_redirect_inbound 같은 이름과 5022 규칙보다 약간 높은 우선 순위를 가진 포트 범위
11000-11999에 대한 또 다른 인바운드 보안 규칙을 추가합니다(예:1100).설정에서 아웃바운드 보안 규칙을 선택합니다. 포트 5022 및 범위 11000-11999에 대해 트래픽을 허용하는 규칙이 이미 있는지 확인합니다. 규칙이 있는 경우 원본이 비즈니스 요구 사항을 충족하는 경우 이 단계를 건너뜁니다. 규칙이 없거나 다른 원본(예: 더 안전한 IP 주소)을 사용하려는 경우 기존 규칙을 삭제한 다음 명령 모음에서 + 추가를 선택하여 아웃바운드 보안 규칙 추가 창을 엽니다.
아웃바운드 보안 규칙 추가 창에서 포트 5022에 대해 동일한 구성과 인바운드 포트의 경우와 동일한 범위
11000-11999를 사용합니다.보조 인스턴스에 대한 네트워크 보안 그룹으로 이동하고 두 네트워크 보안 그룹에 다음 규칙이 있도록 다음 단계를 반복합니다.
- 포트 5022에서 인바운드 트래픽 허용
- 포트 범위
11000-11999에서 인바운드 트래픽 허용 - 포트 5022에서 아웃바운드 트래픽 허용
- 포트 범위
11000-11999에서 아웃바운드 트래픽 허용
장애 조치 그룹 만들기
Azure Portal 또는 PowerShell을 사용하여 관리형 인스턴스에 대한 장애 조치 그룹을 만듭니다.
Azure Portal을 사용하여 SQL Managed Instance에 대한 장애 조치 그룹을 만듭니다.
Azure Portal의 왼쪽 메뉴에서 Azure SQL을 선택합니다. Azure SQL이 목록에 없는 경우 모든 서비스를 선택한 다음, 검색 상자에 Azure SQL을 입력합니다. (선택 사항) Azure SQL 옆의 별표를 선택하여 왼쪽 탐색에 즐겨찾기 항목으로 추가합니다.
장애 조치 그룹에 추가하려는 주 관리형 인스턴스를 선택합니다.
데이터 관리에서 장애 조치(failover) 그룹을 선택한 다음 그룹 추가를 사용하여 인스턴스 장애 조치(failover) 그룹 페이지를 엽니다.
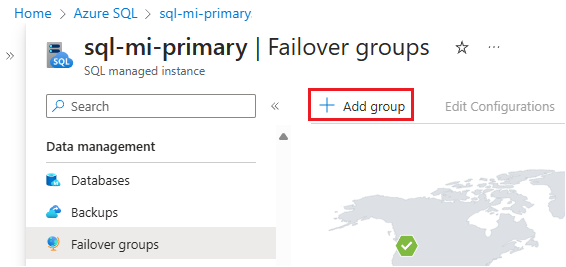
인스턴스 장애 조치(failover) 그룹 페이지에서 다음을 수행합니다.
- 주 관리형 인스턴스가 미리 선택되어 있습니다.
- 장애 조치(failover) 그룹 이름 아래에 장애 조치(failover) 그룹의 이름을 입력합니다.
- 보조 관리형 인스턴스아래의 장애 조치(failover) 그룹에서 보조 인스턴스로 사용하려는 관리형 인스턴스를 선택합니다.
- 드롭다운 목록에서 읽기/쓰기 장애 조치(failover) 정책을 선택합니다. 장애 조치(failover)를 제어하려면 수동이 좋습니다.
- 재해 복구에만 이 복제본(replica)을 사용하려는 경우가 아니면 장애 조치(failover) 사용을 해제로 둡니다.
- 만들기를 사용하여 설정을 저장하고 장애 조치(failover) 그룹을 만듭니다.
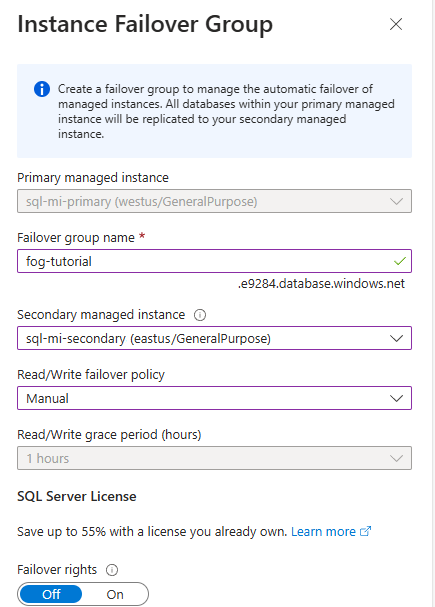
장애 조치(failover) 그룹 배포가 시작된 후 장애 조치(failover) 그룹 페이지로 돌아갑니다. 배포가 완료된 후 페이지가 새로 고쳐지고 새 장애 조치(failover) 그룹이 표시됩니다.
테스트 장애 조치
Azure Portal 또는 PowerShell을 사용하여 장애 조치 그룹의 장애 조치를 테스트합니다.
참고 항목
인스턴스가 다른 구독 또는 리소스 그룹에 있는 경우 보조 인스턴스에서 장애 조치(failover)를 시작합니다.
Azure Portal을 사용하여 장애 조치(failover) 그룹의 장애 조치를 테스트합니다.
Azure Portal 내의 주 또는 보조 관리형 인스턴스로 이동합니다.
데이터 관리에서 장애 조치(failover) 그룹을 선택합니다.
장애 조치(failover) 그룹 창에서 어떤 인스턴스가 주 인스턴스이고 어떤 인스턴스가 보조 인스턴스인지 확인합니다.
장애 조치(failover) 그룹 창의 명령 모음에서 장애 조치(Failover)를 선택합니다. 연결이 끊어지는 TDS 세션에 대한 경고에서 예를 선택하고 라이선싱 영향을 확인합니다.
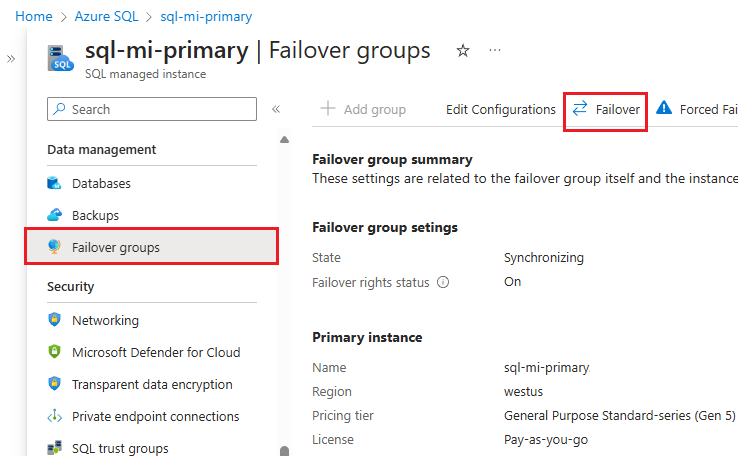
장애 조치(failover) 그룹 창에서 장애 조치(failover)가 성공한 후 인스턴스는 역할을 전환하여 이전 보조가 새 기본이 되고 이전 기본이 새 보조가 됩니다.
Important
역할이 전환되지 않은 경우 인스턴스와 관련 NSG 및 방화벽 규칙 간의 연결을 확인합니다. 역할이 전환된 후에만 다음 단계를 진행합니다.
(선택 사항) 장애 조치(failover) 그룹 창에서 장애 조치(failover)를 사용하여 원래 기본이 다시 기본이 되도록 역할을 다시 전환합니다.

기존 장애 조치(failover) 그룹 수정
Azure Portal, PowerShell, Azure CLI 및 REST API를 사용하여 장애 조치(failover) 정책을 변경하는 등 기존 장애 조치(failover) 그룹을 수정할 수 있습니다.
Azure Portal을 사용하여 기존 장애 조치(failover) 그룹을 수정하려면 다음 단계를 수행합니다.
Azure Portal에서 SQL Managed Instance로 이동합니다.
데이터 관리에서 장애 조치(failover) 그룹을 선택하여 장애 조치(failover) 그룹 창을 엽니다.
장애 조치(failover) 그룹 창의 명령 모음에서 구성 편집을 선택하여 장애 조치(failover) 그룹 편집 창을 엽니다.
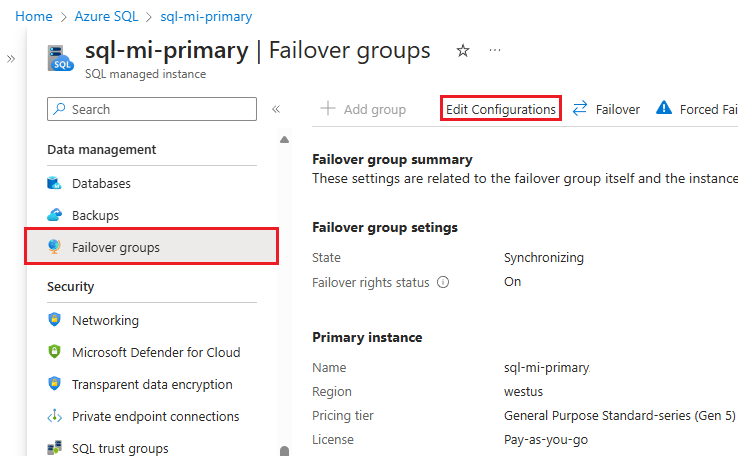
수신기 엔드포인트 찾기
장애 조치(failover) 그룹을 구성한 후 애플리케이션이 장애 조치(failover) 이후 주 인스턴스에 계속 연결되도록 읽기/쓰기 수신기 엔드포인트를 가리킬 수 있게 애플리케이션에 대한 연결 문자열을 업데이트합니다. 수신기 엔드포인트를 사용하면 트래픽이 항상 현재 기본으로 라우팅되므로 장애 조치(failover) 그룹이 장애 조치(failover)될 때마다 연결 문자열을 수동으로 업데이트할 필요가 없습니다. 읽기 전용 워크로드를 읽기 전용 수신기 엔드포인트로 가리킬 수도 있습니다.
Important
인스턴스별 연결 문자열 사용하여 장애 조치(failover) 그룹의 인스턴스에 연결하는 것은 지원되지만 권장되지 않습니다. 대신 수신기 엔드포인트를 사용합니다.
Azure Portal에서 수신기 엔드포인트를 찾으려면 SQL Managed Instance로 이동하고 데이터 관리 아래에서 장애 조치(failover) 그룹을 선택합니다.
아래로 스크롤하여 수신기 엔드포인트를 찾습니다.
fog-name.dns-zone.database.windows.net형식의 읽기/쓰기 수신기 엔드포인트는 트래픽을 주 인스턴스로 라우팅합니다.fog-name.secondary.dns-zone.database.windows.net형식의 읽기 전용 수신기 엔드포인트는 트래픽을 보조 인스턴스로 라우팅합니다.

다른 구독의 인스턴스 간에 장애 조치(failover) 그룹 만들기
구독이 같은 Microsoft Entra 테넌트에 연결되어 있는 한, 다른 두 구독에서 SQL Managed Instance 간에 장애 조치(failover) 그룹을 생성할 수 있습니다.
- PowerShell API를 사용할 때 보조 SQL Managed Instance의
PartnerSubscriptionId매개 변수를 지정하여 수행할 수 있습니다. - REST API를 사용하는 경우
properties.managedInstancePairs매개 변수에 포함된 각 인스턴스 ID는 고유한 구독 ID를 사용할 수 있습니다. - Azure Portal은 다른 구독에서 장애 조치(failover) 그룹 생성을 지원하지 않습니다.
Important
Azure Portal은 다른 구독에서 장애 조치(failover) 그룹 만들기를 지원하지 않습니다. 여러 구독 및/또는 리소스 그룹에 걸친 장애 조치(failover) 그룹의 경우 주 SQL Managed Instance에서 Azure Portal을 통해 수동으로 장애 조치를 시작할 수 없습니다. 대신 지역 보조 인스턴스에서 시작합니다.
중요한 데이터 손실 방지
광역 네트워크의 높은 대기 시간으로 인해 지역 복제에는 비동기 복제 메커니즘이 사용됩니다. 비동기 복제를 사용하면 주 데이터베이스에서 오류가 발생할 때 데이터가 손실될 가능성이 있습니다. 중요한 트랜잭션을 데이터 손실로부터 보호하려면 애플리케이션 개발자는 트랜잭션을 커밋한 후 즉시 sp_wait_for_database_copy_sync 시스템 프로시저를 호출하면 됩니다. sp_wait_for_database_copy_sync를 호출하면 마지막으로 커밋된 트랜잭션이 보조 데이터베이스의 트랜잭션 로그로 전송되어 강화될 때까지 호출 스레드가 차단됩니다. 그러나 전송된 트랜잭션이 보조 데이터베이스에서 재생(다시 실행)될 때까지 기다리지는 않습니다. sp_wait_for_database_copy_sync의 범위는 특정 지역 복제 링크로 한정됩니다. 주 데이터베이스에 대한 연결 권한이 있는 모든 사용자는 이 프로시저를 호출할 수 있습니다.
참고
sp_wait_for_database_copy_sync는 특정 트랜잭션의 지역 장애 조치(failover) 후 데이터 손실을 방지하지만, 읽기 액세스에 대한 전체 동기화를 보장하지는 않습니다. sp_wait_for_database_copy_sync 프로시저를 호출하면 상당한 지연이 발생할 수 있으며, 호출 당시 주 데이터베이스에서 아직 전송되지 않은 트랜잭션 로그의 크기에 따라 지연 시간이 달라집니다.
보조 지역 변경
인스턴스 A는 주 인스턴스이고, 인스턴스 B는 기존 보조 인스턴스이며, 인스턴스 C는 세 번째 영역의 새 보조 인스턴스라고 가정해 보겠습니다. 전환을 수행하려면 다음 단계를 수행합니다.
- A와 크기가 같고 DNS 영역이 같은 인스턴스 C를 만듭니다.
- 인스턴스 A와 B 사이의 장애 조치(failover) 그룹을 삭제합니다. 이 시점에 장애 조치(failover) 그룹 수신기의 SQL 별칭이 삭제되고 게이트웨이가 장애 조치(failover) 그룹 이름을 인식하지 못하기 때문에 로그인 시도에 실패하기 시작합니다. 보조 데이터베이스는 주 데이터베이스에서 연결을 끊고 읽기/쓰기 데이터베이스가 됩니다.
- 인스턴스 A와 C 간에 이름이 같은 장애 조치(failover) 그룹을 생성합니다. 장애 조치(failover) 그룹 구성 가이드의 지침을 따릅니다. 데이터 크기 작업이며, 인스턴스 A의 모든 데이터베이스가 시드되고 동기화되면 완료됩니다.
- 불필요한 요금을 방지하기 위해 필요하지 않은 경우 인스턴스 B를 삭제합니다.
참고
2단계 이후 3단계가 완료될 때까지 인스턴스 A의 데이터베이스는 인스턴스 A의 치명적인 실패로부터 보호되지 않은 상태로 유지됩니다.
주 지역 변경
인스턴스 A는 주 인스턴스이고, 인스턴스 B는 기존 보조 인스턴스이며, 인스턴스 C는 세 번째 영역의 새 주 인스턴스라고 가정해 보겠습니다. 전환을 수행하려면 다음 단계를 수행합니다.
- B와 크기가 같고 DNS 영역이 같은 인스턴스 C를 만듭니다.
- 인스턴스 B에서 수동 장애 조치(failover)를 시작하여 새 기본으로 만듭니다. 인스턴스 A는 자동으로 새 보조 인스턴스가 됩니다.
- 인스턴스 A와 B 사이의 장애 조치(failover) 그룹을 삭제합니다. 이 시점에는 장애 조치(failover) 그룹 엔드포인트를 사용한 로그인 시도가 실패하기 시작합니다. A의 보조 데이터베이스는 주 데이터베이스와의 연결을 끊고 읽기/쓰기 데이터베이스가 됩니다.
- 인스턴스 B와 C 간에 이름이 같은 장애 조치(failover) 그룹을 만듭니다. 이는 데이터 크기 작업이며 인스턴스 B의 모든 데이터베이스가 시드되고 인스턴스 C와 동기화될 때 완료됩니다. 이 시점에서 로그인 시도가 있으면 실패를 중지합니다.
- 수동으로 장애 조치(failover)하여 C 인스턴스를 주 역할로 전환합니다. 인스턴스 B는 자동으로 새 보조 인스턴스가 됩니다.
- 불필요한 요금을 방지하기 위해 필요하지 않은 경우 인스턴스 A를 삭제합니다.
주의
3단계 이후 4단계가 완료될 때까지 인스턴스 A의 데이터베이스는 인스턴스 A의 치명적인 실패로부터 보호되지 않은 상태로 유지됩니다.
Important
장애 조치 그룹을 삭제하면 수신기 엔드포인트의 DNS 레코드도 삭제됩니다. 이 시점에는 다른 사람이 같은 이름을 사용하는 장애 조치(failover) 그룹을 만들 가능성이 있습니다. 장애 조치(failover) 그룹 이름은 전역적으로 고유해야 하기 때문에 동일한 이름을 다시 사용할 수 없습니다. 이 위험을 최소화하려면 일반 장애 조치(failover) 그룹 이름을 사용하지 마세요.
업데이트 정책 변경
장애 조치(failover) 그룹의 인스턴스에는 일치하는 업데이트 정책이 있어야 합니다. 장애 조치(failover) 그룹의 일부인 인스턴스에서 항상 최신 업데이트 정책을 사용하도록 설정하려면 먼저 보조 인스턴스에서 항상 최신 업데이트 정책을 사용하도록 설정하고 변경 내용이 적용될 때까지 기다린 다음 주 인스턴스에 대한 정책을 업데이트합니다.
장애 조치(failover) 그룹의 주 인스턴스에 대한 업데이트 정책을 변경하면 인스턴스가 다른 로컬 노드(장애 조치(failover) 그룹에 속하지 않는 인스턴스의 관리 작업과 유사하게)로 장애 조치(failover)되지만 장애 조치(failover) 그룹이 장애 조치(failover)되지는 않고 주 인스턴스가 주 역할로 유지됩니다.
주의
업데이트된 정책이 항상 최신으로 변경되면 SQL Server 2022 업데이트 정책으로 다시 변경할 수 없습니다.
시스템 데이터베이스의 개체에 종속된 시나리오 사용
시스템 데이터베이스는 장애 조치(failover) 그룹의 보조 인스턴스에 복제되지 않습니다. 시스템 데이터베이스의 개체에 따라 달라지는 시나리오를 지원하려면 보조 인스턴스에서 동일한 개체를 만들고 주 인스턴스와 동기화 상태를 유지해야 합니다.
예를 들어 보조 인스턴스에서 같은 로그인을 사용하려는 경우 같은 SID를 사용하여 해당 로그인을 만들어야 합니다.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
자세한 내용은 로그인 및 에이전트 작업의 복제를 참조하세요.
인스턴스 속성 및 보존 정책 인스턴스 동기화
장애 조치(failover) 그룹의 인스턴스는 별도의 Azure 리소스로 남아 있으며, 주 인스턴스 구성의 변경 내용은 보조 인스턴스에 자동으로 복제되지 않습니다. 모든 관련 변경을 주 인스턴스와 보조 인스턴스 모두에서 수행해야 합니다. 예를 들어 주 인스턴스에서 백업 스토리지 중복 또는 장기 백업 보존 정책을 변경하는 경우 보조 인스턴스에서도 변경해야 합니다.
인스턴스 크기 조정
주 인스턴스 및 보조 인스턴스를 동일한 서비스 계층 내의 다른 컴퓨팅 크기 또는 다른 서비스 계층으로 스케일 업하거나 스케일 다운할 수 있습니다. 동일한 서비스 계층 내에서 스케일 업할 때에는 지역 보조 위치부터 스케일 업한 다음, 주 위치를 스케일 업하는 것이 좋습니다. 동일한 서비스 계층 내에서 스케일 다운할 때에는 역순으로 합니다. 주 위치부터 스케일 다운한 다음, 보조 위치를 스케일 다운합니다. 인스턴스를 다른 서비스 계층으로 스케일링할 때 동일한 순서를 따릅니다.
이 순서는 더 낮은 SKU의 지역 보조 데이터베이스가 오버로드되어 업그레이드 또는 다운그레이드 프로세스 중에 다시 시딩해야 하는 문제를 방지하기 위해 권장됩니다.
사용 권한
장애 조치 그룹의 사용 권한은 Azure RBAC(Azure 역할 기반 액세스 제어)를 통해 관리합니다.
주 및 보조 관리되는 인스턴스의 리소스 그룹으로 범위가 지정된 SQL Managed Instance 기여자 역할은 장애 조치(failover) 그룹에서 모든 관리 작업을 수행하기에 충분합니다.
다음 표에서는 장애 조치(failover) 그룹의 관리 작업에 필요한 최소 사용 권한 및 각각의 최소 필수 범위 수준에 대한 세부적인 보기를 제공합니다.
| 관리 작업 | 사용 권한 | 범위 |
|---|---|---|
| 장애 조치(failover) 그룹 만들기/업데이트 | Microsoft.Sql/locations/instanceFailoverGroups/write |
주 및 보조 관리되는 인스턴스의 리소스 그룹 |
| 장애 조치(failover) 그룹 만들기/업데이트 | Microsoft.Sql/managedInstances/write |
주 및 보조 관리되는 인스턴스 |
| 장애 조치(failover) 그룹의 장애 조치(failover) | Microsoft.Sql/locations/instanceFailoverGroups/failover/action |
주 및 보조 관리되는 인스턴스의 리소스 그룹 |
| 장애 조치(failover) 그룹의 강제 장애 조치(failover) | Microsoft.Sql/locations/instanceFailoverGroups/forceFailoverAllowDataLoss/action |
주 및 보조 관리되는 인스턴스의 리소스 그룹 |
| 장애 조치(failover) 그룹 삭제 | Microsoft.Sql/locations/instanceFailoverGroups/delete |
주 및 보조 관리되는 인스턴스의 리소스 그룹 |
제한 사항
새 장애 조치(failover) 그룹을 만들 때 다음 제한 사항을 고려합니다.
- 동일한 Azure 지역에 있는 두 개의 인스턴스 간에 장애 조치(failover) 그룹을 만들 수 없습니다.
- 인스턴스는 언제든지 하나의 장애 조치(failover) 그룹에만 참여할 수 있습니다.
- 서로 다른 Azure 테넌트에서 속하는 두 인스턴스 간에 장애 조치(failover) 그룹을 만들 수 없습니다.
- 서로 다른 리소스 그룹 또는 구독에서 두 인스턴스 간 장애 조치(failover) 그룹을 만드는 것은 Azure Portal 또는 Azure CLI가 아닌 Azure PowerShell 또는 REST API에서만 지원됩니다. 장애 조치(failover) 그룹이 만들어지면 Azure Portal에 표시되고 모든 작업은 Azure Portal 또는 Azure CLI에서 지원됩니다. 보조 인스턴스에서 장애 조치(failover)를 시작해야 합니다.
- 모든 데이터베이스의 초기 시드가 7일 이내에 완료되지 않으면 장애 조치(failover) 그룹 생성이 실패하고 성공적으로 복제된 모든 데이터베이스가 보조 인스턴스에서 삭제됩니다.
- 관리형 인스턴스 링크로 구성된 인스턴스를 사용하여 장애 조치(failover) 그룹을 만드는 것은 현재 지원되지 않습니다.
- 인스턴스 중 하나라도 인스턴스 풀에 있으면 인스턴스 간에 장애 조치(Failover) 그룹을 만들 수 없습니다.
- LRS(Log Replay Service)를 사용하여 Azure SQL Managed Instance로 마이그레이션된 데이터베이스는 컷오버 단계가 실행될 때까지 장애 조치(failover) 그룹에 추가할 수 없습니다.
장애 조치(failover) 그룹을 사용하는 경우 다음 제한 사항을 고려하십시오.
- 장애 조치 그룹의 이름을 바꿀 수 없습니다. 그룹을 삭제하고 다른 이름으로 다시 만들어야 합니다.
- 장애 조치(failover) 그룹에는 정확히 두 개의 관리되는 인스턴스가 포함됩니다. 장애 조치(failover) 그룹에 인스턴스를 추가하는 것은 지원되지 않습니다.
- 전체 백업은 다음 상황에 자동으로 수행됩니다.
- 초기 시드 전에 초기 시드 프로세스의 시작을 눈에 띄게 지연할 수 있습니다.
- 장애 조치(failover) 후 후속 장애 조치(failover)를 지연하거나 방지할 수 있습니다.
- 장애 조치(failover) 그룹의 인스턴스는 데이터베이스 이름 바꾸기가 지원되지 않습니다. 데이터베이스의 이름을 변경하려면 장애 조치(failover) 그룹을 일시적으로 삭제해야 합니다.
- 시스템 데이터베이스는 장애 조치 그룹의 보조 인스턴스에 복제되지 않습니다. 따라서 서버 로그인 및 에이전트 작업과 같은 시스템 데이터베이스의 개체에 의존하는 시나리오에서는 보조 인스턴스에서 개체를 수동으로 만들고 주 인스턴스에서 변경한 후 수동으로 동기화를 유지해야 합니다. 유일한 예외는 장애 조치(failover) 그룹을 만드는 동안 보조 인스턴스에 자동으로 복제되는 SQL Managed Instance용 SMK(서비스 마스터 키)입니다. 그러나 주 인스턴스에서 SMK의 이후 변경 사항은 보조 인스턴스로 복제되지 않습니다. 자세히 알아보려면 시스템 데이터베이스의 개체에 따라 시나리오를 활성화하는 방법을 참조하세요.
- 장애 조치(failover) 그룹 내 인스턴스의 경우 서비스 계층을 차세대 범용 계층에서 또는 차세대 범용 계층으로 변경하는 작업은 지원되지 않습니다. 두 복제본(replica) 중 하나라도 수정하기 전에 먼저 장애 조치(failover) 그룹을 삭제한 다음, 변경 내용을 적용한 후 장애 조치(failover) 그룹을 다시 만들어야 합니다.
- 장애 조치(failover) 그룹의 SQL Managed Instance에는 동일한 업데이트 정책이 있어야 하지만 장애 조치(failover) 그룹 내의 인스턴스에 대한 업데이트 정책을 변경할 수 있습니다.
프로그래밍 방식으로 장애 조치(failover) 그룹 관리
Azure PowerShell, Azure CLI 및 REST API를 사용하여 프로그래밍 방식으로 장애 조치(failover) 그룹을 관리할 수도 있습니다. 다음 표는 사용 가능한 명령의 집합을 보여줍니다. 장애 조치 그룹은 관리를 위해 Azure SQL Database REST API 및 Azure PowerShell cmdlet을 비롯한 Azure Resource Manager API 집합을 포함합니다. 이러한 API는 리소스 그룹을 사용해야 하며 Azure RBAC(Azure 역할 기반 액세스 제어)를 지원합니다. 액세스 역할을 구현하는 방법에 관한 자세한 내용은 Azure RBAC(Azure 역할 기반 액세스 제어)를 참조하세요.
| Cmdlet | 설명 |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | 장애 조치 그룹을 만들고 주 인스턴스와 보조 인스턴스 모두에 등록합니다 |
| Set-AzSqlDatabaseInstanceFailoverGroup | 장애 조치 그룹의 구성 수정 |
| Get-AzSqlDatabaseInstanceFailoverGroup | 장애 조치 그룹의 구성 검색 |
| Switch-AzSqlDatabaseInstanceFailoverGroup | 장애 조치 그룹을 보조 인스턴스로 장애 조치하도록 트리거 |
| Remove-AzSqlDatabaseInstanceFailoverGroup | 장애 조치(failover) 그룹을 제거합니다. |