빠른 시작: 사용자 지정 텍스트 분류
이 문서를 사용하여 텍스트 분류를 위한 사용자 지정 모델을 학습시킬 수 있는 사용자 지정 텍스트 분류 프로젝트를 만드는 작업을 시작합니다. 모델은 특정 작업을 수행하도록 학습된 AI 소프트웨어입니다. 이 시스템의 경우 모델은 텍스트를 분류하고 태그가 지정된 데이터에서 학습하여 학습됩니다.
사용자 지정 텍스트 분류는 두 가지 유형의 프로젝트를 지원합니다.
- 단일 레이블 분류 - 데이터 세트의 각 문서에 대해 단일 클래스를 할당할 수 있습니다. 예를 들어 영화 스크립트는 "Romance" 또는 "Comedy"로만 분류할 수 있습니다.
- 다중 레이블 분류 - 데이터 세트의 각 문서에 대해 다중 클래스를 할당할 수 있습니다. 예를 들어 영화 스크립트는 "Comedy" 또는 "Romance" 및 "Comedy"로 분류될 수 있습니다.
이 빠른 시작에서는 영화 스크립트를 하나 이상의 범주로 분류할 수 있는 다중 레이블 분류를 빌드하기 위해 제공된 샘플 데이터 세트를 사용하거나, 과학 논문의 추상화를 정의된 도메인 중 하나로 분류할 수 있는 단일 레이블 분류 데이터 세트를 사용할 수 있습니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
새 Azure AI 언어 리소스 및 Azure Storage 계정을 만듭니다.
사용자 지정 텍스트 분류를 사용하려면 먼저 프로젝트를 만들고 모델 학습을 시작하는 데 필요한 자격 증명을 제공할 Azure AI 언어 리소스를 만들어야 합니다. 또한 모델을 빌드하는 데 사용할 데이터 세트를 업로드할 수 있는 Azure 스토리지 계정이 필요합니다.
Important
빠르게 시작하려면 이 문서에 제공된 단계를 사용하여 새 Azure AI 언어 리소스를 만드는 것이 좋습니다. 이 문서의 단계를 사용하면 언어 리소스와 스토리지 계정을 동시에 만들 수 있으므로 나중에 만드는 것보다 쉽습니다.
사용하려는 기존 리소스가 있는 경우 스토리지 계정에 연결해야 합니다.
Azure Portal에서 새 리소스 만들기
새로운 Azure AI 언어 리소스를 생성하려면 Azure portal로 이동하세요.
표시되는 창의 사용자 지정 기능에서 사용자 지정 텍스트 분류 및 사용자 지정 명명된 엔터티 인식을 선택합니다. 화면 하단에서 계속해서 리소스 만들기를 선택합니다.
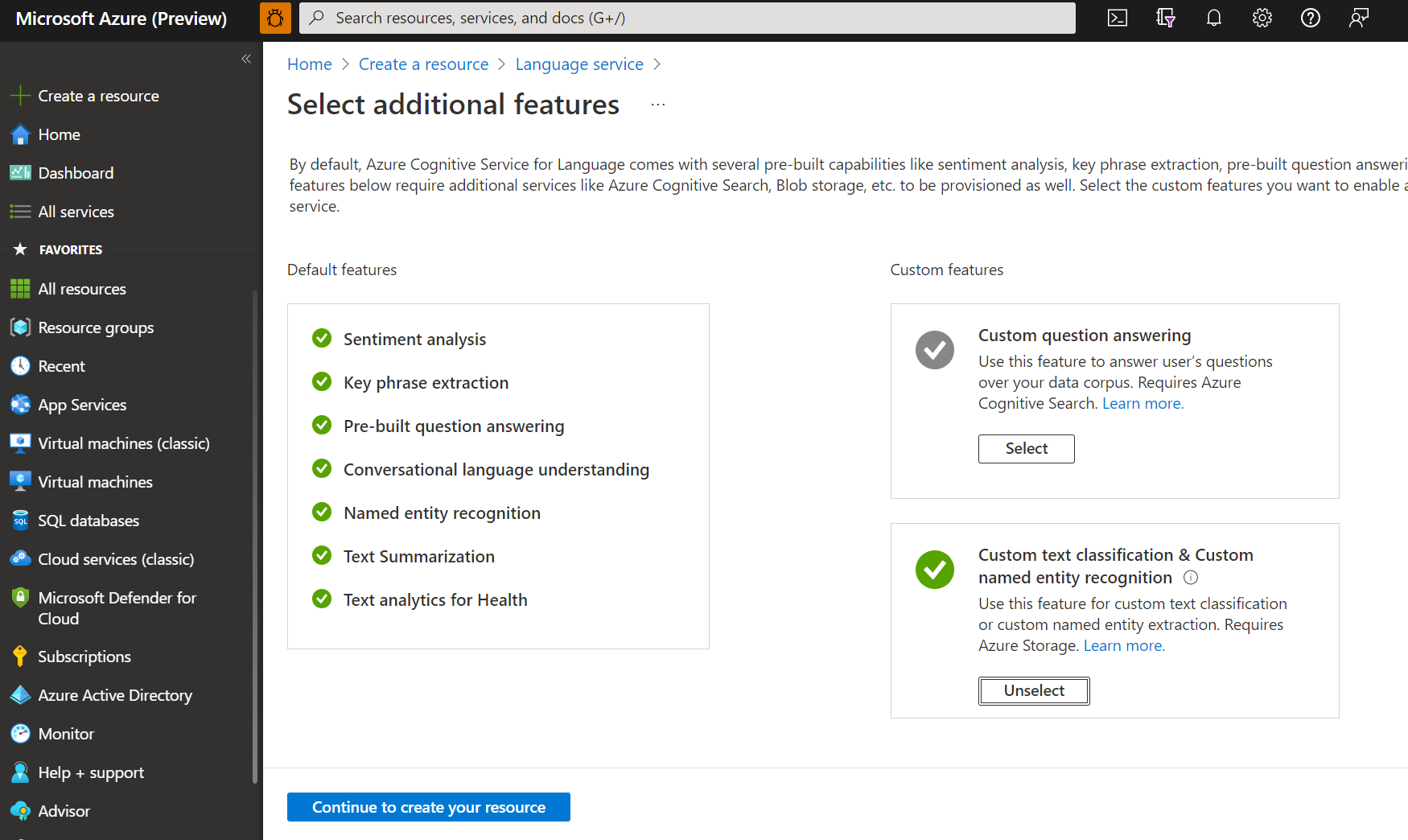
다음 세부 정보를 사용하여 언어 리소스를 만듭니다.
이름 필수 값 구독 Azure 구독. Resource group 리소스를 포함할 리소스 그룹입니다. 기존 리소스 그룹을 사용하거나 새로 만들 수 있습니다. 지역 지원되는 지역 중 하나입니다. 예를 들어 "미국 서부 2"로 선택합니다. 이름 리소스의 이름입니다. 가격 책정 계층 지원되는 가격 책정 계층 중 하나입니다. 무료(F0) 계층을 사용하여 서비스를 사용해 볼 수 있습니다. "로그인 계정이 선택한 스토리지 계정의 리소스 그룹 소유자가 아닙니다"라는 메시지가 표시되면 언어 리소스를 만들기 전에 계정에 리소스 그룹에 대한 소유자 역할이 할당되어 있어야 합니다. 도움이 필요하면 Azure 구독 소유자에게 문의합니다.
리소스 그룹을 검색하고 연결된 구독에 대한 링크에 따라 Azure 구독 소유자를 확인할 수 있습니다. 다음 작업:
- 액세스 제어(IAM) 탭 선택
- 역할 할당 선택
- 역할:소유자로 필터링합니다.
사용자 지정 텍스트 분류 및 사용자 지정 명명된 엔터티 인식 섹션에서 기존 스토리지 계정을 선택하거나 새 스토리지 계정을 선택합니다. 이러한 값은 시작하는 데 도움이 되며, 반드시 프로덕션 환경에서 사용하려는 스토리지 계정 값은 아닙니다. 프로젝트를 빌드하는 동안 대기 시간을 방지하려면 언어 리소스와 동일한 지역의 스토리지 계정에 연결합니다.
스토리지 계정 값 권장 값 스토리지 계정 이름 임의의 이름 Storage 계정 유형 표준 LRS 책임 있는 AI 알림이 선택되어 있는지 확인합니다. 페이지 아래쪽에서 검토 + 만들기를 선택합니다.

Blob 컨테이너에 샘플 데이터 업로드
Azure 스토리지 계정을 만들고 언어 리소스에 연결한 후에는 컨테이너의 루트 디렉터리에 샘플 데이터 세트의 문서를 업로드해야 합니다. 이러한 문서는 모델을 학습시키는 데 사용됩니다.
.zip 파일을 열고 문서가 포함된 폴더를 추출합니다.
제공된 샘플 데이터 세트에는 약 200개의 문서가 포함되어 있으며, 각 문서는 영화에 대한 요약입니다. 각 문서는 다음 클래스 중 하나 이상에 속합니다.
- “Mystery”
- “Drama”
- “Thriller”
- “Comedy”
- “Action”
Azure Portal에서 생성된 스토리지 계정으로 이동하고 선택합니다. 스토리지 계정을 클릭하고 모든 필드에 대해 필터링에 스토리지 계정 이름을 입력하면 됩니다.
리소스 그룹이 표시되지 않으면 구독 같음 필터가 모두로 설정되어 있는지 확인합니다.
스토리지 계정에서 데이터 스토리지 아래에 있는 왼쪽 메뉴에서 컨테이너를 선택합니다. 표시된 화면에서 + 컨테이너를 선택합니다. 컨테이너에 example-data 이름을 지정하고 기본 공개 액세스 수준을 그대로 둡니다.
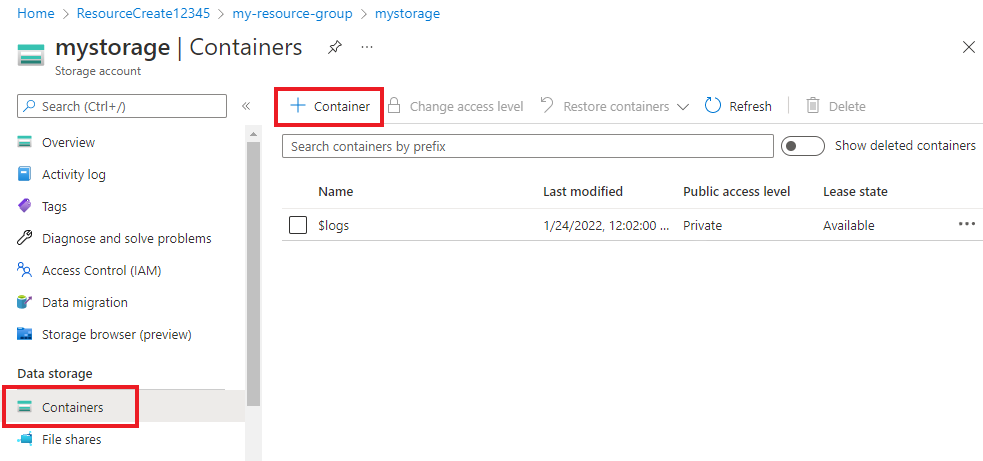
컨테이너를 만든 후 선택합니다. 그런 다음 업로드 버튼을 선택하여 이전에 다운로드한
.txt및.json파일을 선택합니다.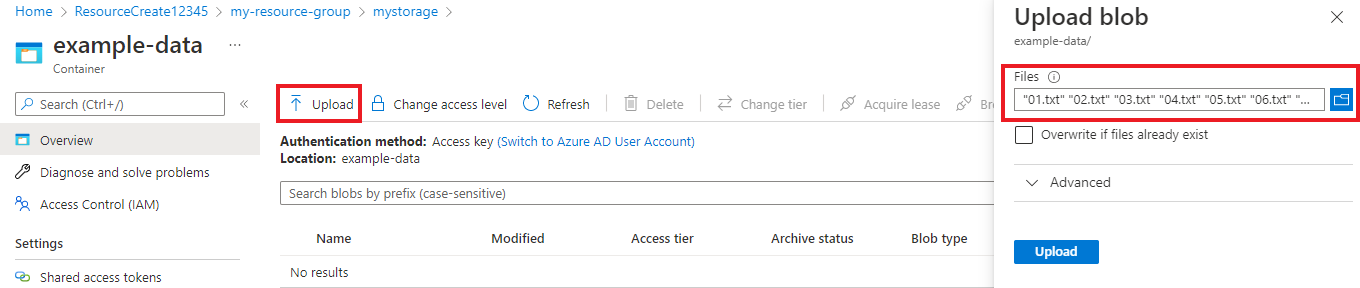


사용자 지정 텍스트 분류 프로젝트 만들기
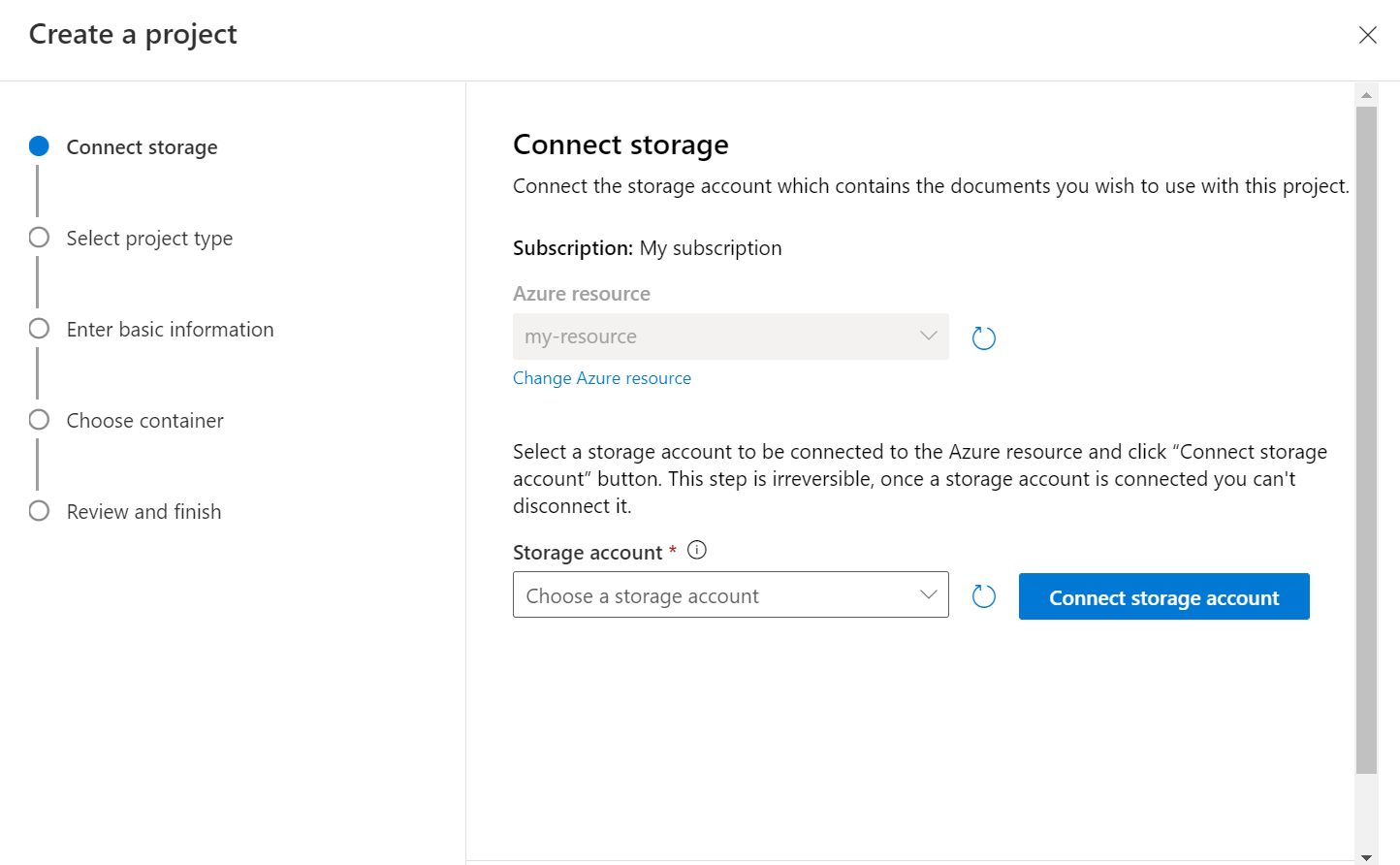
리소스 및 스토리지 컨테이너가 구성되면 새 사용자 지정 텍스트 분류 프로젝트를 만듭니다. 프로젝트는 데이터를 기반으로 하는 사용자 지정 ML 모델을 빌드하기 위한 작업 영역입니다. 사용자 및 사용 중인 언어 리소스에 대해 액세스 권한이 있는 다른 사용자만 프로젝트에 액세스할 수 있습니다.
Language Studio에 로그인합니다. 구독 및 언어 리소스를 선택할 수 있는 창이 표시됩니다. 언어 리소스를 선택합니다.
Language Studio의 텍스트 분류 섹션 아래에서 사용자 지정 텍스트 분류를 선택합니다.

프로젝트 페이지의 상단 메뉴에서 새 프로젝트 만들기를 선택합니다. 프로젝트를 만들면 레이블을 데이터에 지정하고, 모델을 학습시키고, 평가하고, 향상시키고, 배포할 수 있습니다.
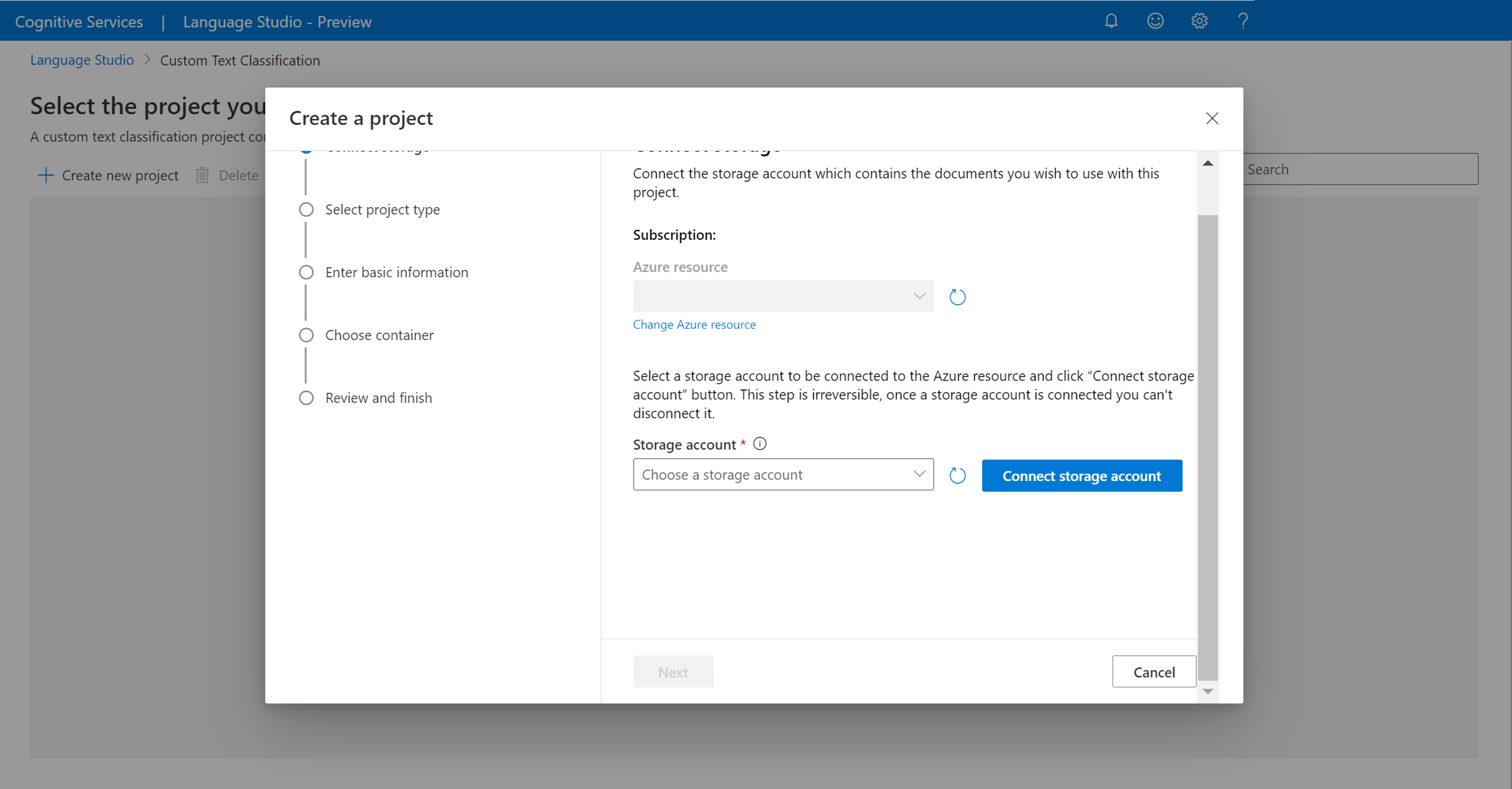
새 프로젝트 만들기를 클릭하면 스토리지 계정을 연결할 수 있는 창이 나타납니다. 스토리지 계정을 이미 연결한 경우 연결된 스토리지 계정이 표시됩니다. 그렇지 않은 경우 표시되는 드롭다운에서 스토리지 계정을 선택하고 스토리지 계정 연결을 선택합니다. 그러면 스토리지 계정에 필요한 역할이 설정됩니다. 스토리지 계정에 대한 소유자로 할당되지 않은 경우 이 단계에서 오류가 반환될 수 있습니다.
참고 항목
- 사용하는 각 새 언어 리소스에 대해 이 단계를 한 번만 수행하면 됩니다.
- 이 프로세스는 되돌릴 수 없으며, 스토리지 계정을 언어 리소스에 연결하면 나중에 해당 연결을 끊을 수 없습니다.
- 언어 리소스는 하나의 스토리지 계정에만 연결할 수 있습니다.
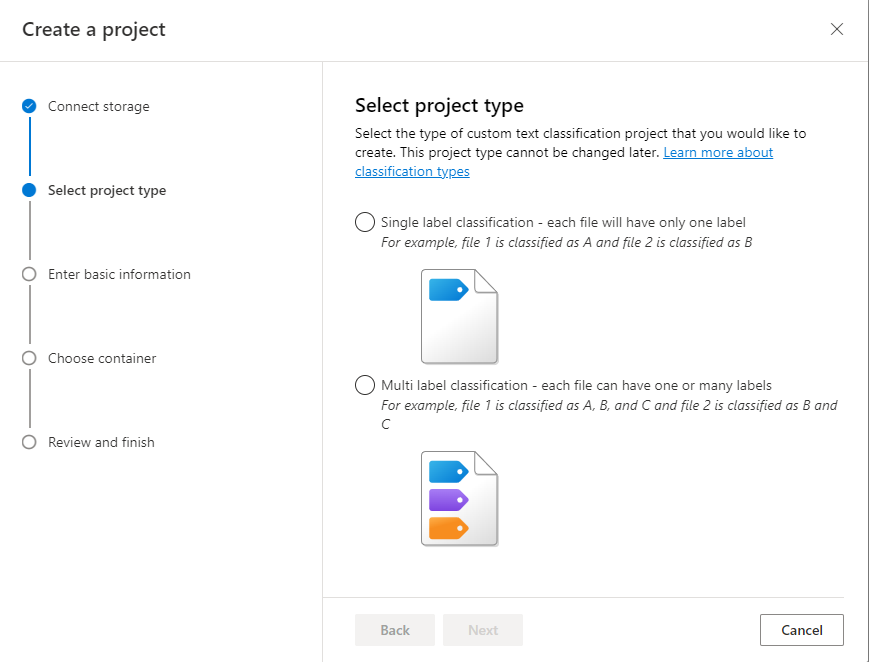
프로젝트 형식을 선택합니다. 각 문서가 하나 이상의 클래스에 속할 수 있는 다중 레이블 분류 프로젝트를 만들거나, 각 문서가 하나의 클래스에만 속할 수 있는 단일 레이블 분류 프로젝트를 만들 수 있습니다. 선택한 형식은 나중에 변경할 수 없습니다. 프로젝트 형식에 대한 자세한 정보
프로젝트에 있는 문서의 이름, 설명 및 언어를 포함한 프로젝트 정보를 입력합니다. 예제 데이터 세트를 사용하는 경우 영어를 선택합니다. 프로젝트 이름은 나중에 변경할 수 없습니다. 다음을 선택합니다.
팁
데이터 세트는 완전히 동일한 언어로 되어 있지 않아도 됩니다. 지원되는 언어가 서로 다른 여러 문서가 있을 수 있습니다. 데이터 세트에 다른 언어의 문서가 포함되어 있거나 런타임 중에 다른 언어의 텍스트가 필요한 경우 프로젝트에 대한 기본 정보를 입력할 때 다국어 데이터 세트 사용 옵션을 선택합니다. 이 옵션은 나중에 프로젝트 설정 페이지에서 사용하도록 설정할 수 있습니다.
데이터 세트를 업로드한 컨테이너를 선택합니다.
참고 항목
이미 레이블을 데이터에 지정한 경우 지원되는 형식을 따르는지 확인하고, 예, 이미 레이블을 내 문서에 지정하고 JSON 레이블 파일의 형식을 지정했습니다를 선택하고, 아래의 드롭다운 메뉴에서 레이블 파일을 선택합니다.
예제 데이터 세트 중 하나를 사용하는 경우 포함된
webOfScience_labelsFile또는movieLabelsjson 파일을 사용합니다. 그런 후 다음을 선택합니다.입력한 데이터를 검토하고, 프로젝트 만들기를 선택합니다.




모델 학습
일반적으로 프로젝트를 만든 후에는 계속해서 프로젝트에 연결된 컨테이너에 있는 문서에 레이블 지정을 시작합니다. 이 빠른 시작에서는 레이블이 지정된 샘플 데이터 세트를 가져오고 샘플 JSON 레이블 파일을 사용하여 프로젝트를 초기화했습니다.
Language Studio 내에서 모델 학습을 시작하려면 다음을 수행합니다.
왼쪽 메뉴에서 학습 작업을 선택합니다.
상단 메뉴에서 학습 작업 시작을 선택합니다.
새 모델 학습을 선택하고, 텍스트 상자에서 모델 이름을 입력합니다. 또한 이 옵션을 선택하고 드롭다운 메뉴에서 덮어쓰려는 모델을 선택하면 기존 모델을 덮어쓸 수 있습니다. 학습된 모델을 덮어쓰는 것은 되돌릴 수 없지만, 새 모델을 배포할 때까지 배포된 모델에는 영향을 주지 않습니다.
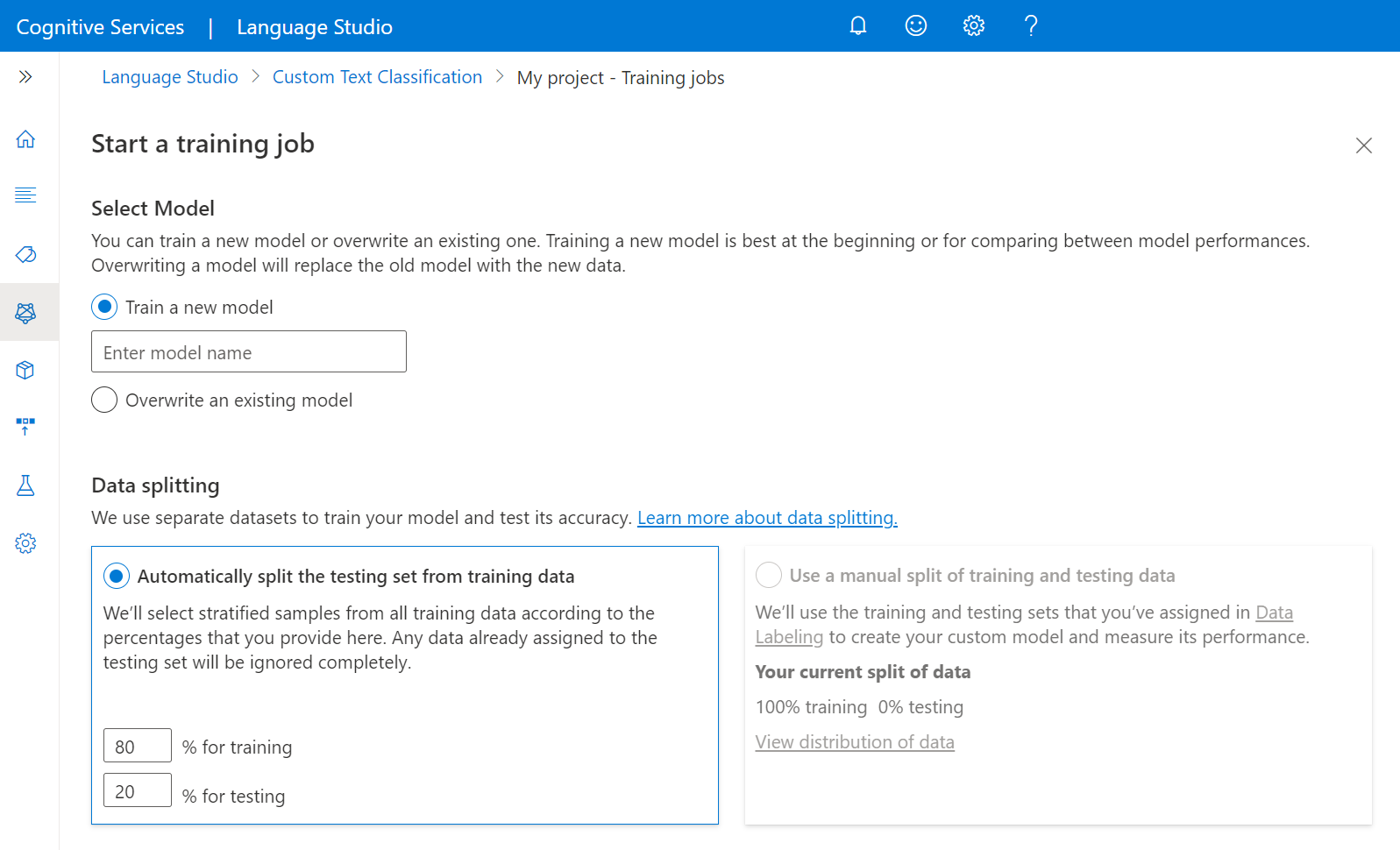
데이터 분할 방법을 선택합니다. 학습 데이터에서 자동으로 테스트 세트 분할을 선택할 수 있습니다. 여기서 시스템은 지정된 백분율에 따라 레이블이 지정된 데이터를 학습 세트와 테스트 세트 간에 분할합니다. 또는 학습 및 테스트 데이터에 대한 수동 분할을 사용할 수 있습니다. 이 옵션은 데이터 레이블 지정 중에 문서를 테스트 세트에 추가한 경우에만 사용할 수 있습니다. 데이터 분할에 대한 자세한 내용은 모델 학습 방법을 참조하세요.
학습 단추를 선택합니다.
목록에서 학습 작업 ID를 선택하면 이 작업에 대한 학습 진행률, 작업 상태 및 기타 세부 정보를 확인할 수 있는 사이드 창이 표시됩니다.
참고 항목
- 성공적으로 완료된 학습 작업만 모델을 생성합니다.
- 모델 학습 시간은 레이블이 지정된 데이터의 크기에 따라 몇 분에서 몇 시간이 걸릴 수 있습니다.
- 한 번에 하나의 학습 작업만 실행할 수 있습니다. 실행 중인 작업이 완료될 때까지 동일한 프로젝트 내에서 다른 학습 작업을 시작할 수 없습니다.

모델 배포
일반적으로 모델을 학습시킨 후 평가 세부 정보를 검토하고 필요한 경우 개선합니다. 이 빠른 시작에서는 모델을 배포하고 Language Studio에서 사용해 볼 수 있도록 하거나, 예측 API를 호출할 수 있습니다.
Language Studio 내에서 모델을 배포하려면:
왼쪽 메뉴에서 모델 배포를 선택합니다.
새 배포 작업을 시작하려면 배포 추가를 선택합니다.
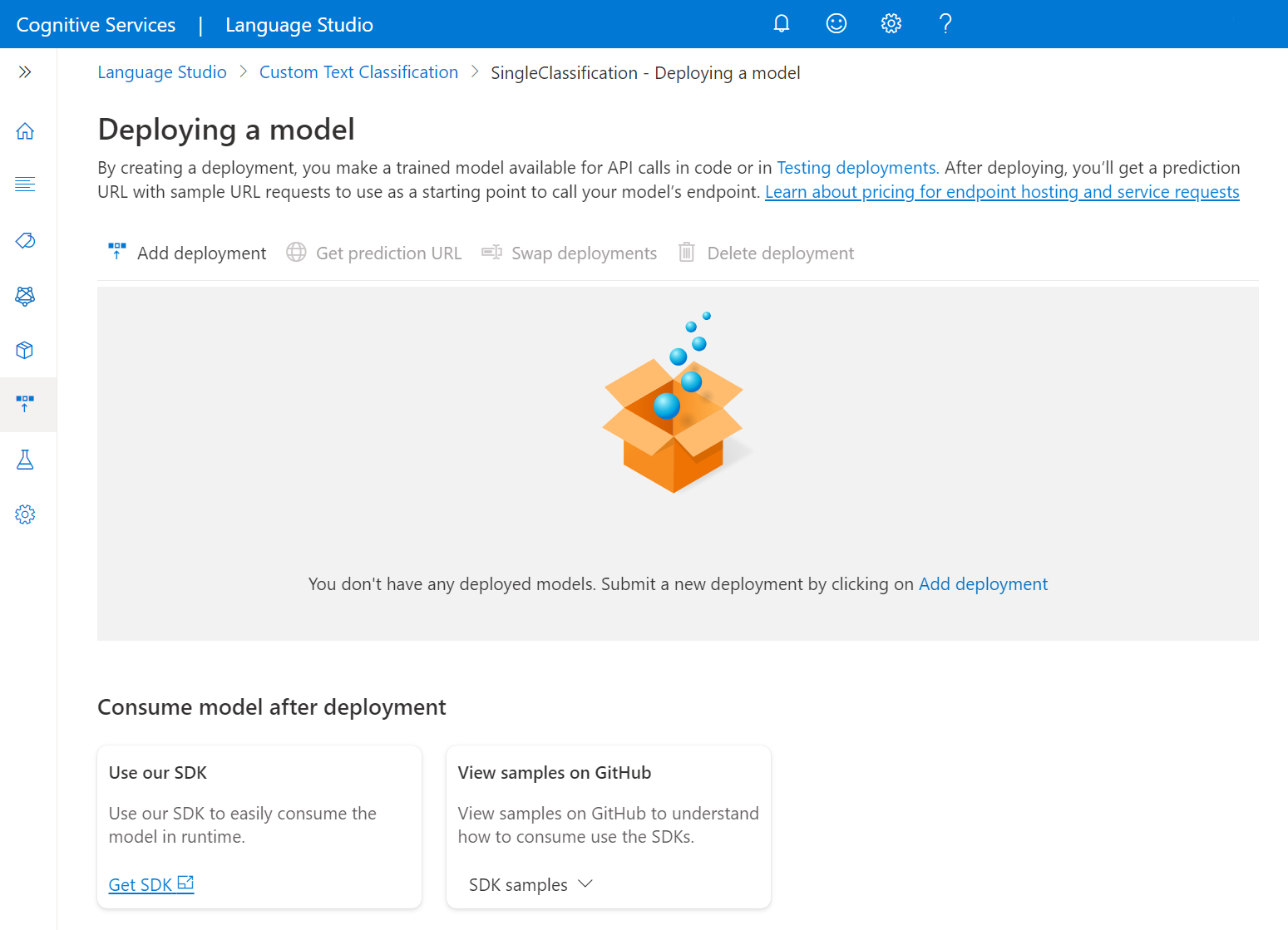
새 배포 만들기를 선택하여 새 배포를 만들고 아래 드롭다운에서 학습된 모델을 할당합니다. 이 옵션을 선택하여 기존 배포를 덮어쓰고 아래 드롭다운에서 할당할 학습된 모델을 선택할 수도 있습니다.
참고 항목
기존 배포를 덮어쓸 때는 예측 API 호출을 변경할 필요가 없지만 새로 할당된 모델을 기반으로 결과를 얻을 수 있습니다.
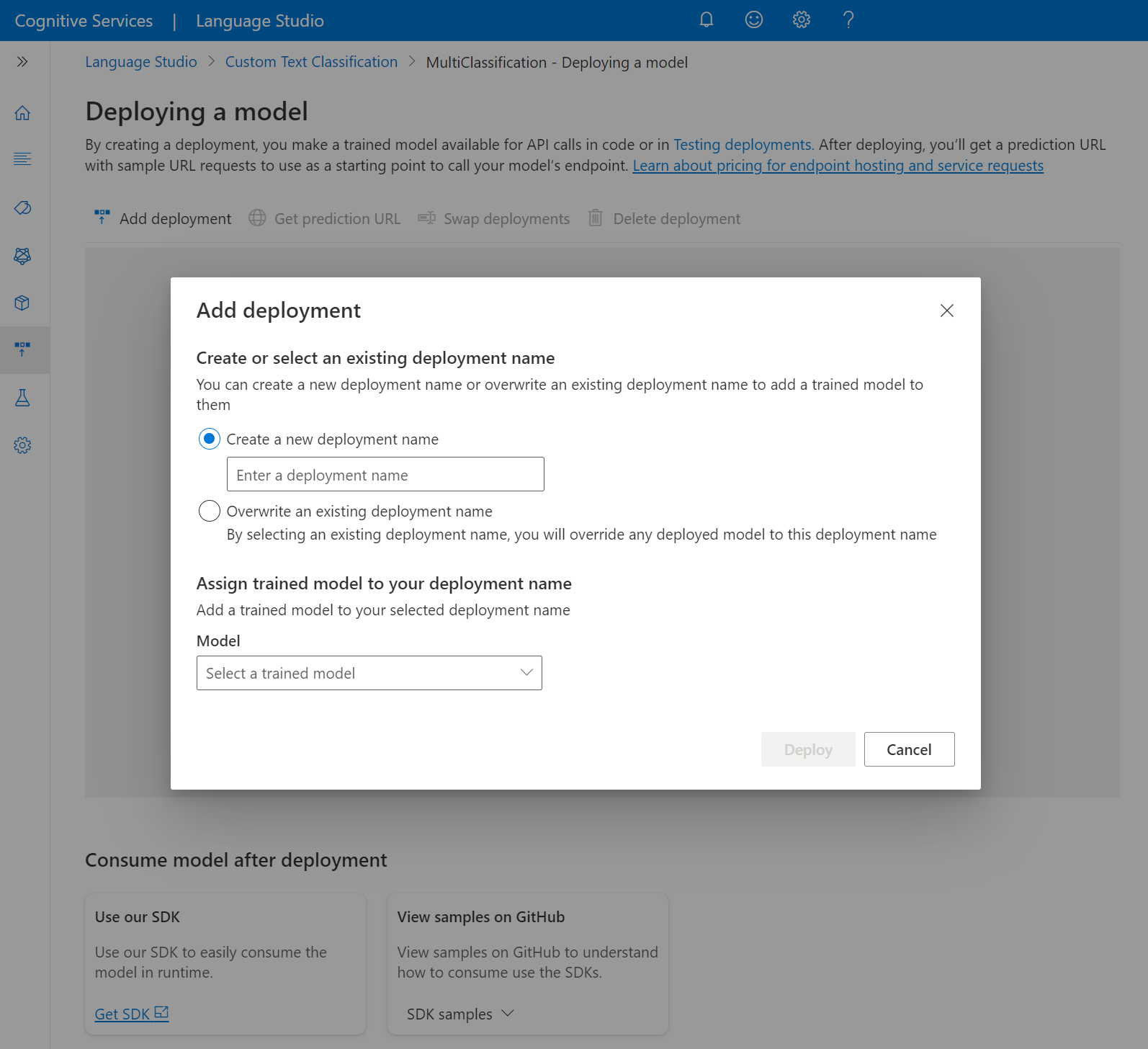
배포를 선택하여 배포 작업을 시작합니다.
배포에 성공하면 만료 날짜가 옆에 표시됩니다. 배포 만료는 배포된 모델을 예측에 사용할 수 없게 되는 때이며, 일반적으로 학습 구성이 만료된 후 12개월 후에 발생합니다.


모델 테스트
모델을 배포한 후 이 모델을 사용하여 예측 API를 통해 텍스트 분류를 시작할 수 있습니다. 이 빠른 시작에서는 Language Studio를 사용하여 사용자 지정 텍스트 분류 작업을 제출하고 결과를 시각화합니다. 이전에 다운로드한 샘플 데이터 세트에서 이 단계에서 사용할 수 있는 몇 가지 테스트 문서를 찾을 수 있습니다.
Language Studio 내에서 배포된 모델을 테스트하려면:
화면 왼쪽의 메뉴에서 배포 테스트를 선택합니다.
테스트할 배포를 선택합니다. 배포에 할당된 모델만 테스트할 수 있습니다.
다국어 프로젝트의 경우 언어 드롭다운을 사용하여 테스트할 텍스트의 언어를 선택합니다.
드롭다운에서 쿼리/테스트하려는 배포를 선택합니다.
요청에 제출할 텍스트를 입력하거나 사용할
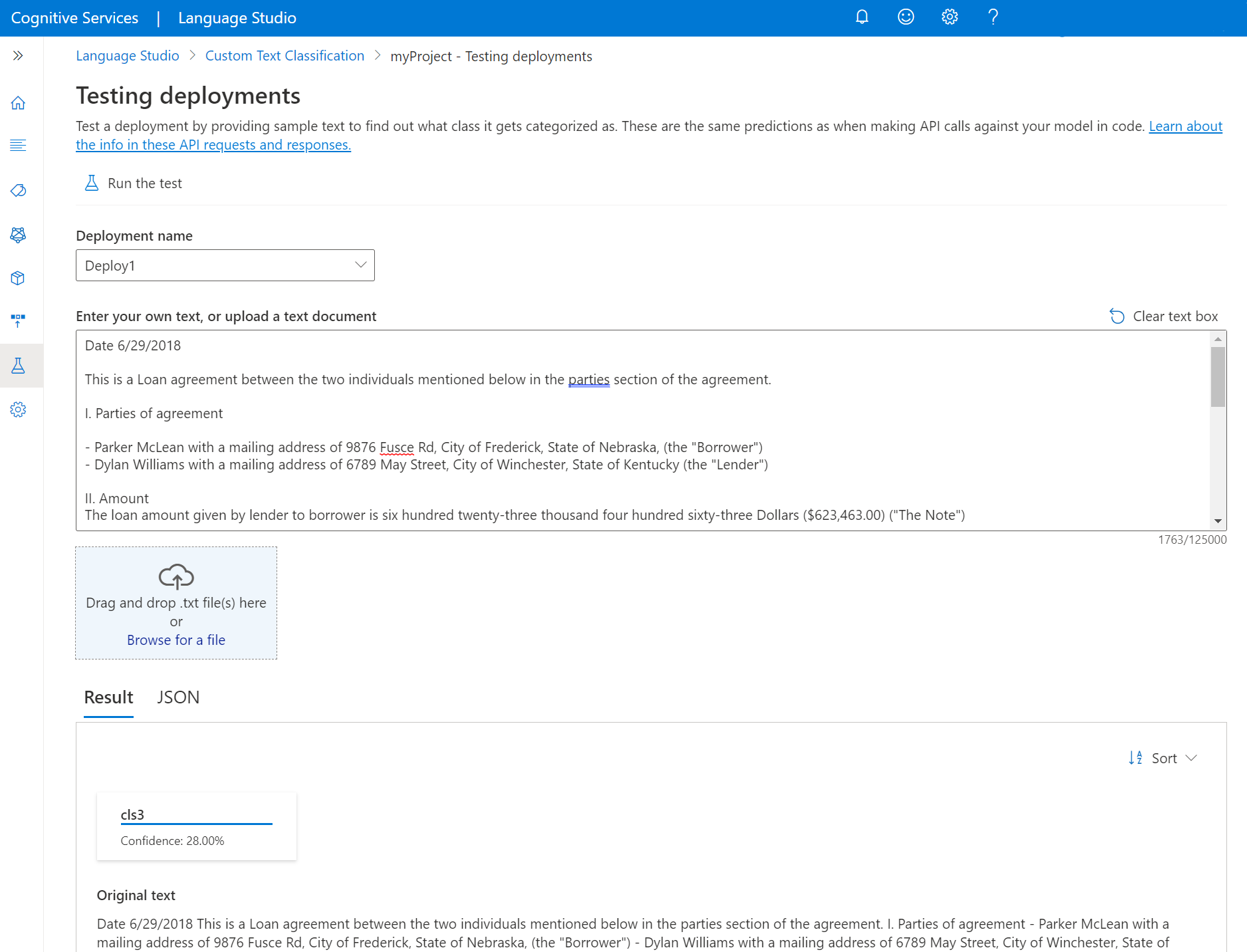
.txt문서를 업로드합니다. 데이터 예 세트 중 하나를 사용하는 경우 포함된 .txt 파일 중 하나를 사용할 수 있습니다.상단 메뉴에서 테스트 실행을 선택합니다.
결과 탭에서 텍스트의 예측 클래스를 볼 수 있습니다. JSON 탭에서 JSON 응답을 볼 수도 있습니다. 다음 예제는 단일 레이블 분류 프로젝트에 대한 것입니다. 다중 레이블 분류 프로젝트는 결과에서 둘 이상의 클래스를 반환할 수 있습니다.

프로젝트 정리
프로젝트가 더 이상 필요하지 않은 경우 언어 스튜디오를 사용하여 프로젝트를 삭제할 수 있습니다. 상단의 사용자 지정 텍스트 분류를 선택한 다음, 삭제하려는 프로젝트를 선택합니다. 상단 메뉴에서 삭제를 선택하여 프로젝트를 삭제합니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
새 Azure AI 언어 리소스 및 Azure Storage 계정을 만듭니다.
사용자 지정 텍스트 분류를 사용하려면 먼저 프로젝트를 만들고 모델 학습을 시작하는 데 필요한 자격 증명을 제공할 Azure AI 언어 리소스를 만들어야 합니다. 또한 모델을 빌드하는 데 사용할 데이터 세트를 업로드할 수 있는 Azure 스토리지 계정이 필요합니다.
Important
빠르게 시작하려면 이 문서에 제공된 단계를 사용하여 새 Azure AI 언어 리소스를 만드는 것이 좋습니다. 이렇게 하면 언어 리소스를 만들고 동시에 스토리지 계정을 생성 및/또는 연결할 수 있습니다. 이는 수행하는 것보다 쉽습니다. 나중에요.
사용하려는 기존 리소스가 있는 경우 스토리지 계정에 연결해야 합니다.
Azure Portal에서 새 리소스 만들기
새로운 Azure AI 언어 리소스를 생성하려면 Azure portal로 이동하세요.
표시되는 창의 사용자 지정 기능에서 사용자 지정 텍스트 분류 및 사용자 지정 명명된 엔터티 인식을 선택합니다. 화면 하단에서 계속해서 리소스 만들기를 선택합니다.
다음 세부 정보를 사용하여 언어 리소스를 만듭니다.
이름 필수 값 구독 Azure 구독. Resource group 리소스를 포함할 리소스 그룹입니다. 기존 리소스 그룹을 사용하거나 새로 만들 수 있습니다. 지역 지원되는 지역 중 하나입니다. 예를 들어 "미국 서부 2"로 선택합니다. 이름 리소스의 이름입니다. 가격 책정 계층 지원되는 가격 책정 계층 중 하나입니다. 무료(F0) 계층을 사용하여 서비스를 사용해 볼 수 있습니다. "로그인 계정이 선택한 스토리지 계정의 리소스 그룹 소유자가 아닙니다"라는 메시지가 표시되면 언어 리소스를 만들기 전에 계정에 리소스 그룹에 대한 소유자 역할이 할당되어 있어야 합니다. 도움이 필요하면 Azure 구독 소유자에게 문의합니다.
리소스 그룹을 검색하고 연결된 구독에 대한 링크에 따라 Azure 구독 소유자를 확인할 수 있습니다. 다음 작업:
- 액세스 제어(IAM) 탭 선택
- 역할 할당 선택
- 역할:소유자로 필터링합니다.
사용자 지정 텍스트 분류 및 사용자 지정 명명된 엔터티 인식 섹션에서 기존 스토리지 계정을 선택하거나 새 스토리지 계정을 선택합니다. 이러한 값은 시작하는 데 도움이 되며, 반드시 프로덕션 환경에서 사용하려는 스토리지 계정 값은 아닙니다. 프로젝트를 빌드하는 동안 대기 시간을 방지하려면 언어 리소스와 동일한 지역의 스토리지 계정에 연결합니다.
스토리지 계정 값 권장 값 스토리지 계정 이름 임의의 이름 Storage 계정 유형 표준 LRS 책임 있는 AI 알림이 선택되어 있는지 확인합니다. 페이지 아래쪽에서 검토 + 만들기를 선택합니다.
Blob 컨테이너에 샘플 데이터 업로드
Azure 스토리지 계정을 만들고 언어 리소스에 연결한 후에는 컨테이너의 루트 디렉터리에 샘플 데이터 세트의 문서를 업로드해야 합니다. 이러한 문서는 모델을 학습시키는 데 사용됩니다.
.zip 파일을 열고 문서가 포함된 폴더를 추출합니다.
제공된 샘플 데이터 세트에는 약 200개의 문서가 포함되어 있으며, 각 문서는 영화에 대한 요약입니다. 각 문서는 다음 클래스 중 하나 이상에 속합니다.
- “Mystery”
- “Drama”
- “Thriller”
- “Comedy”
- “Action”
Azure Portal에서 생성된 스토리지 계정으로 이동하고 선택합니다. 스토리지 계정을 클릭하고 모든 필드에 대해 필터링에 스토리지 계정 이름을 입력하면 됩니다.
리소스 그룹이 표시되지 않으면 구독 같음 필터가 모두로 설정되어 있는지 확인합니다.
스토리지 계정에서 데이터 스토리지 아래에 있는 왼쪽 메뉴에서 컨테이너를 선택합니다. 표시된 화면에서 + 컨테이너를 선택합니다. 컨테이너에 example-data 이름을 지정하고 기본 공개 액세스 수준을 그대로 둡니다.
컨테이너를 만든 후 선택합니다. 그런 다음 업로드 버튼을 선택하여 이전에 다운로드한
.txt및.json파일을 선택합니다.
리소스 키 및 엔드포인트 가져오기
Azure Portal에서 스토리지 계정 개요 페이지로 이동합니다.
왼쪽 메뉴에서 키 및 엔드포인트를 선택합니다. API 요청에 엔드포인트와 키를 사용합니다.

사용자 지정 텍스트 분류 프로젝트 만들기
리소스 및 스토리지 컨테이너가 구성되면 새 사용자 지정 텍스트 분류 프로젝트를 만듭니다. 프로젝트는 데이터를 기반으로 하는 사용자 지정 ML 모델을 빌드하기 위한 작업 영역입니다. 사용자 및 사용 중인 언어 리소스에 대해 액세스 권한이 있는 다른 사용자만 프로젝트에 액세스할 수 있습니다.
프로젝트 가져오기 작업 트리거
다음 URL, 헤더 및 JSON 본문을 사용하여 레이블 파일을 가져오는 POST 요청을 제출합니다. 레이블 파일이 허용되는 형식을 따르는지 확인합니다.
이름이 같은 프로젝트가 이미 있는 경우 해당 프로젝트의 데이터가 바뀝니다.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트에 대한 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
본문
요청에 다음 JSON을 사용합니다. 아래의 자리 표시자 값을 자신의 값으로 바꿉니다.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| 키 | 자리 표시자 | 값 | 예제 |
|---|---|---|---|
| api-version | {API-VERSION} |
호출하는 API의 버전입니다. 여기서 사용되는 버전은 URL에서 동일한 API 버전이어야 합니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
| projectName | {PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
| projectKind | customMultiLabelClassification |
프로젝트 종류입니다. | customMultiLabelClassification |
| 언어 | {LANGUAGE-CODE} |
프로젝트에 사용되는 문서의 언어 코드를 지정하는 문자열입니다. 프로젝트가 다국어 프로젝트인 경우 대부분의 문서에 대한 언어 코드를 선택합니다. 다국어 지원에 대한 자세한 내용은 언어 지원을 참조하세요. | en-us |
| 다국어 | true |
데이터 세트에 여러 언어로 된 문서를 포함할 수 있고 모델을 배포할 때 지원되는 모든 언어로 모델을 쿼리할 수 있는 부울 값입니다(반드시 학습 문서에 포함되지는 않음). 다국어 지원에 대한 자세한 내용은 언어 지원을 참조하세요. | true |
| storageInputContainerName | {CONTAINER-NAME} |
문서를 업로드한 Azure Storage 컨테이너의 이름입니다. | myContainer |
| 클래스 | [] | 프로젝트에 있는 모든 클래스를 포함하는 배열입니다. 문서를 분류할 클래스는 다음과 같습니다. | [] |
| 문서 | [] | 프로젝트의 모든 문서 및 이 문서에 대한 레이블이 지정된 클래스를 포함하는 배열입니다. | [] |
| location | {DOCUMENT-NAME} |
스토리지 컨테이너에 있는 문서의 위치입니다. 모든 문서가 컨테이너의 루트에 있으므로 문서 이름이어야 합니다. | doc1.txt |
| 데이터 세트 | {DATASET} |
학습 전에 분할할 때 이 문서가 이동하는 테스트 세트입니다. 데이터 분할에 대한 자세한 내용은 모델 학습 방법을 참조하세요. 이 필드에 사용할 수 있는 값은 Train 및 Test입니다. |
Train |
API 요청을 보내면 작업이 올바르게 제출되었음을 나타내는 202 응답을 받게 됩니다. 응답 헤더에서 operation-location 값을 추출합니다. 다음과 같이 형식이 지정됩니다.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
이 작업은 비동기식이므로 {JOB-ID}은 요청을 식별하는 데 사용됩니다. 이 URL을 사용하여 가져오기 작업 상태를 가져옵니다.
이 요청에 대한 가능한 오류 시나리오:
- 선택한 리소스에 스토리지 계정에 대한 적절한 권한이 없습니다.
- 지정한
storageInputContainerName이 없습니다. - 잘못된 언어 코드가 사용되었거나 언어 코드 형식이 문자열이 아닌 경우입니다.
multilingual값은 부울이 아닌 문자열입니다.
가져오기 작업 상태 가져오기
다음 GET 요청을 사용하여 프로젝트 가져오기의 상태를 가져옵니다. 아래의 자리 표시자 값을 자신의 값으로 바꿉니다.
요청 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{JOB-ID} |
모델의 학습 상태를 찾기 위한 ID입니다. 이 값은 이전 단계에서 받은 location 헤더 값에 있습니다. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
모델 학습
일반적으로 프로젝트를 만든 후에는 계속해서 프로젝트에 연결된 컨테이너에 있는 문서에 태그를 지정하기 시작합니다. 이 빠른 시작에서는 샘플 태그가 지정된 데이터 세트를 가져오고 샘플 JSON 태그 파일을 사용하여 프로젝트를 초기화했습니다.
모델 학습 시작
프로젝트를 가져온 후 모델 학습을 시작할 수 있습니다.
학습 작업을 제출하려면 다음 URL, 헤더 및 JSON 본문을 사용하여 POST 요청을 제출합니다. 아래의 자리 표시자 값을 자신의 값으로 바꿉니다.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
요청 본문
요청 본문에서 다음 JSON을 사용합니다. 학습이 완료되면 모델이 {MODEL-NAME}으로 지정됩니다. 성공적인 학습 작업만 모델을 생성합니다.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| 키 | 자리 표시자 | 값 | 예제 |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
성공적으로 학습되면 모델에 할당할 모델 이름입니다. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
이는 모델을 학습시키는 데 사용할 모델 버전입니다. | 2022-05-01 |
| evaluationOptions | 데이터를 학습 세트 및 테스트 세트 간에 분할하는 옵션입니다. | {} |
|
| kind | percentage |
분할 방법입니다. 가능한 값은 percentage 또는 manual입니다. 자세한 내용은 모델 학습 방법을 참조하세요. |
percentage |
| trainingSplitPercentage | 80 |
학습 세트에 포함할 태그가 지정된 데이터의 백분율입니다. 권장 값은 80입니다. |
80 |
| testingSplitPercentage | 20 |
테스트 세트에 포함할 태그가 지정된 데이터의 백분율입니다. 권장 값은 20입니다. |
20 |
참고 항목
Kind가 percentage로 설정되고 두 백분율의 합계가 100이어야 하는 경우에만 trainingSplitPercentage 및 testingSplitPercentage가 필요합니다.
API 요청을 보내면 작업이 올바르게 제출되었음을 나타내는 202 응답을 받게 됩니다. 응답 헤더에서 location 값을 추출합니다. 다음과 같이 형식이 지정됩니다.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
이 작업은 비동기이므로 {JOB-ID}가 요청을 식별하는 데 사용됩니다. 이 URL을 사용하여 학습 상태를 가져올 수 있습니다.
학습 작업 상태 가져오기
학습은 10~30분 정도 걸릴 수 있습니다. 다음 요청을 사용하여 성공적으로 완료될 때까지 학습 작업의 상태를 계속 폴링할 수 있습니다.
다음 GET 요청을 사용하여 모델의 학습 진행률에 대한 상태를 가져옵니다. 아래의 자리 표시자 값을 자신의 값으로 바꿉니다.
요청 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{JOB-ID} |
모델의 학습 상태를 찾기 위한 ID입니다. 이 값은 이전 단계에서 받은 location 헤더 값에 있습니다. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 내용은 모델 수명 주기를 참조하세요. | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
응답 본문
요청을 보내면 다음과 같은 응답이 수신됩니다.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
모델 배포
일반적으로 모델을 학습시킨 후 평가 세부 정보를 검토하고 필요한 경우 개선합니다. 이 빠른 시작에서는 모델을 배포하고 Language Studio에서 사용해 볼 수 있도록 하거나, 예측 API를 호출할 수 있습니다.
배포 작업 제출
다음 URL, 헤더 및 JSON 본문을 사용하여 PUT 요청을 제출하여 배포 작업을 제출합니다. 아래의 자리 표시자 값을 자신의 값으로 바꿉니다.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{DEPLOYMENT-NAME} |
배포의 이름입니다. 이 값은 대/소문자를 구분합니다. | staging |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
요청 본문
요청 본문에서 다음 JSON을 사용합니다. 배포에 할당할 모델의 이름을 사용합니다.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| 키 | 자리 표시자 | 값 | 예제 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
배포에 할당될 모델 이름입니다. 성공적으로 학습된 모델만 할당할 수 있습니다. 이 값은 대/소문자를 구분합니다. | myModel |
API 요청을 보내면 작업이 올바르게 제출되었음을 나타내는 202 응답을 받게 됩니다. 응답 헤더에서 operation-location 값을 추출합니다. 다음과 같이 형식이 지정됩니다.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
이 작업은 비동기이므로 {JOB-ID}가 요청을 식별하는 데 사용됩니다. 이 URL을 사용하여 배포 상태를 가져올 수 있습니다.
배포 작업 상태 가져오기
다음 GET 요청을 사용하여 배포 작업의 상태를 쿼리합니다. 이전 단계에서 받은 URL을 사용하거나 아래 자리 표시자 값을 자신의 값으로 바꿀 수 있습니다.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트의 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{DEPLOYMENT-NAME} |
배포의 이름입니다. 이 값은 대/소문자를 구분합니다. | staging |
{JOB-ID} |
모델의 학습 상태를 찾기 위한 ID입니다. 이는 이전 단계에서 받은 location 헤더 값에 있습니다. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
Ocp-Apim-Subscription-Key |
리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
응답 본문
요청을 보내면 다음과 같은 응답을 받게 됩니다. status 매개 변수가 "succeeded"로 변경될 때까지 이 엔드포인트를 계속 폴링합니다. 요청의 성공을 나타내는 200 코드를 확인해 야 합니다.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
텍스트 분류
모델을 성공적으로 배포한 후 이 모델을 사용하여 예측 API를 통해 텍스트 분류를 시작할 수 있습니다. 이전에 다운로드한 샘플 데이터 세트에서 이 단계에서 사용할 수 있는 몇 가지 테스트 문서를 찾을 수 있습니다.
사용자 지정 텍스트 분류 작업 제출
이 POST 요청을 사용하여 텍스트 분류 작업을 시작합니다.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 내용은 모델 수명 주기를 참조하세요. | 2022-05-01 |
헤더
| 키 | 값 |
|---|---|
| Ocp-Apim-Subscription-Key | 이 API에 대한 액세스를 제공하는 키입니다. |
본문
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| 키 | 자리 표시자 | 값 | 예제 |
|---|---|---|---|
displayName |
{JOB-NAME} |
작업 이름입니다. | MyJobName |
documents |
, , | 작업을 실행할 문서 목록입니다. | [{},{}] |
id |
{DOC-ID} |
문서 이름 또는 ID입니다. | doc1 |
language |
{LANGUAGE-CODE} |
문서의 언어 코드를 지정하는 문자열입니다. 이 키를 지정하지 않으면 서비스는 프로젝트를 만드는 동안 선택한 프로젝트의 기본 언어를 가정합니다. 지원되는 언어 코드 목록은 언어 지원을 참조하세요. | en-us |
text |
{DOC-TEXT} |
작업을 실행할 작업을 문서화합니다. | Lorem ipsum dolor sit amet |
tasks |
수행하려는 작업 목록입니다. | [] |
|
taskName |
CustomMultiLabelClassification | 작업 이름 | CustomMultiLabelClassification |
parameters |
작업에 전달할 매개 변수 목록입니다. | ||
project-name |
{PROJECT-NAME} |
프로젝트에 대한 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
배포의 이름입니다. 이 값은 대/소문자를 구분합니다. | prod |
응답
성공을 나타내는 202 응답을 받게 됩니다. 응답 헤더에서 operation-location을 추출합니다.
operation-location 형식은 다음과 같습니다.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
이 URL을 사용하여 작업 완료 상태를 쿼리하고 작업이 완료되면 결과를 가져올 수 있습니다.
작업 결과 가져오기
다음 GET 요청을 사용하여 텍스트 분류 작업의 상태/결과를 쿼리합니다.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 모델 버전에 대한 값입니다. | 2022-05-01 |
헤더
| 키 | 값 |
|---|---|
| Ocp-Apim-Subscription-Key | 이 API에 대한 액세스를 제공하는 키입니다. |
응답 본문
응답은 다음 매개 변수가 포함된 JSON 문서입니다.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
리소스 정리
프로젝트가 더 이상 필요하지 않은 경우 다음과 같은 DELETE 요청을 사용하여 삭제할 수 있습니다. 자리 표시자 값을 사용자 고유의 값으로 바꿉니다.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 자리 표시자 | 값 | 예제 |
|---|---|---|
{ENDPOINT} |
API 요청을 인증하기 위한 엔드포인트입니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
프로젝트에 대한 이름입니다. 이 값은 대/소문자를 구분합니다. | myProject |
{API-VERSION} |
호출하는 API의 버전입니다. 여기서 참조되는 값은 릴리스된 최신 버전에 대한 값입니다. 사용 가능한 다른 API 버전에 대한 자세한 정보 | 2022-05-01 |
헤더
다음 헤더를 사용하여 요청을 인증합니다.
| 키 | 값 |
|---|---|
| Ocp-Apim-Subscription-Key | 리소스의 키입니다. API 요청을 인증하는 데 사용됩니다. |
API 요청을 보내면 성공을 나타내는 202 응답을 받게 됩니다. 이는 프로젝트가 삭제되었음을 의미합니다. 작업의 상태를 확인하는 데 사용되는 Operation-Location 헤더가 포함된 성공적인 호출 결과.
다음 단계
사용자 지정 텍스트 분류 모델을 만든 후에는 다음을 수행할 수 있습니다.
고유한 사용자 지정 텍스트 분류 프로젝트를 만들기 시작할 때 방법 문서를 사용하여 모델 개발에 대해 더 자세히 알아봅니다.