Azure AI 모델 유추를 사용하여 포함을 생성하는 방법
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델과 함께 포함 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에 포함 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
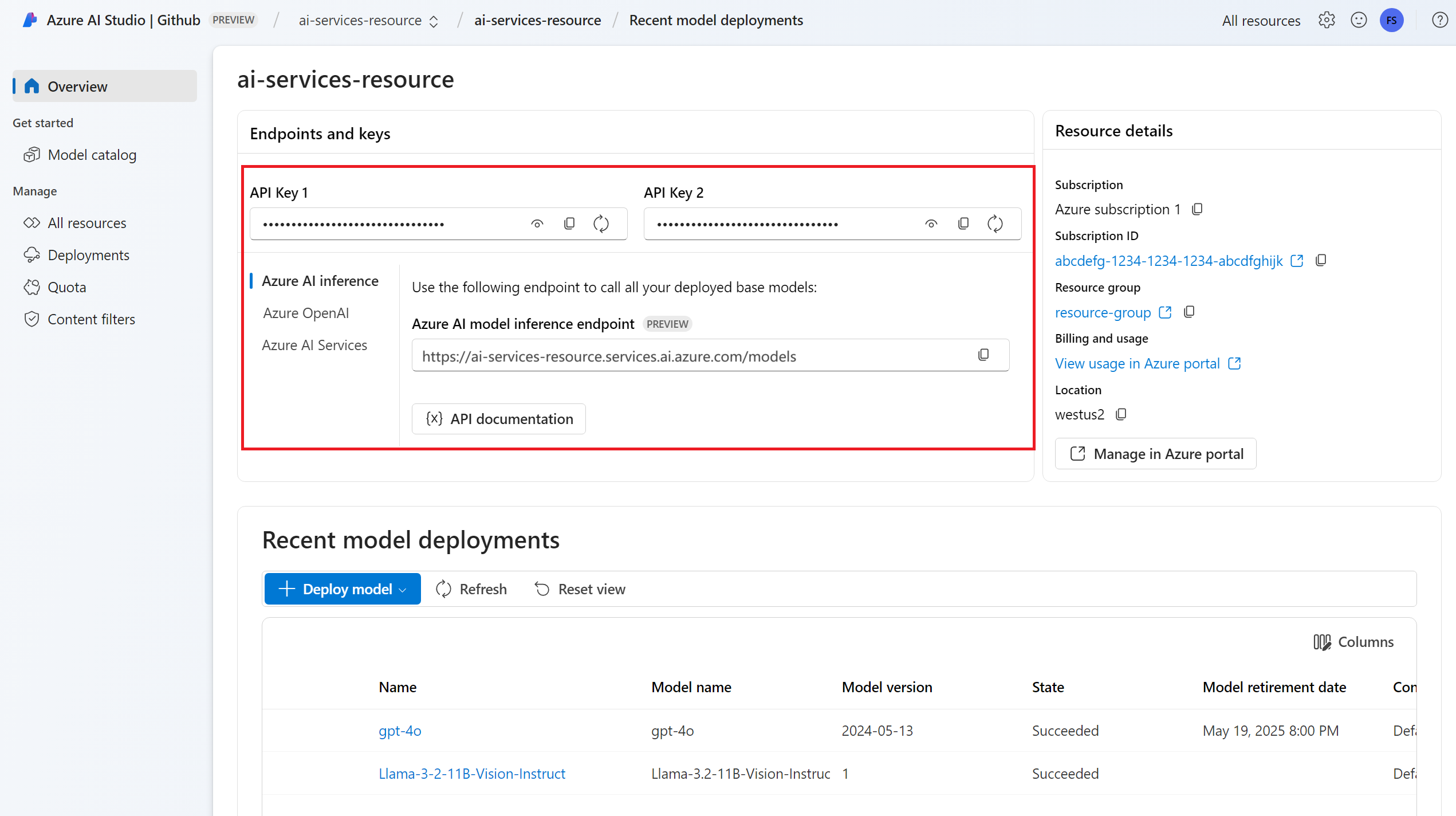

embeddings 모델 배포입니다. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 embeddings 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 Azure AI 유추 패키지를 설치합니다.
pip install -U azure-ai-inference팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
포함 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
포함 만들기
포함 요청을 만들어 모델의 출력을 확인합니다.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
팁
요청을 만들 때 모델에 대한 토큰의 입력 제한을 고려합니다. 텍스트의 큰 부분을 포함해야 하는 경우 청크 분할 전략이 필요합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
입력 배치에서 포함을 계산하는 것이 유용할 수 있습니다. 매개 변수 inputs은/는 각 문자열이 다른 입력인 문자열 목록일 수 있습니다. 차례로 응답은 포함 목록으로, 각 포함은 동일한 위치에 있는 입력에 해당합니다.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
팁
요청 일괄 처리를 만들 때 각 모델에 대한 일괄 처리 제한을 고려합니다. 대부분의 모델에는 1024 일괄 처리 제한이 있습니다.
포함 차원 지정
포함의 차원 수를 지정할 수 있습니다. 다음 예제 코드에서는 1024 차원의 포함을 만드는 방법을 보여 줍니다. 모든 포함 모델이 요청의 차원 수를 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
다양한 유형의 포함 만들기
일부 모델은 사용 계획에 따라 동일한 입력에 대해 여러 포함을 생성할 수 있습니다. 이 기능을 사용하면 RAG 패턴에 대해 좀 더 정확한 포함을 검색할 수 있습니다.
다음 예제에서는 벡터 데이터베이스에 저장될 문서에 대한 포함을 만드는 데 사용되는 포함을 만드는 방법을 보여 줍니다.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
이러한 문서를 검색하는 쿼리를 실행할 때 다음 코드 조각을 사용하여 쿼리에 대한 포함을 만들고 검색 성능을 극대화할 수 있습니다.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
모든 포함 모델이 요청의 입력 형식을 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다. 기본적으로 형식 Text 의 포함이 반환됩니다.
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델과 함께 포함 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에 포함 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
embeddings 모델 배포입니다. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 embeddings 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 JavaScript용 Azure 유추 라이브러리를 설치합니다.
npm install @azure-rest/ai-inference팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
포함 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
포함 만들기
포함 요청을 만들어 모델의 출력을 확인합니다.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
팁
요청을 만들 때 모델에 대한 토큰의 입력 제한을 고려합니다. 텍스트의 큰 부분을 포함해야 하는 경우 청크 분할 전략이 필요합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
입력 배치에서 포함을 계산하는 것이 유용할 수 있습니다. 매개 변수 inputs은/는 각 문자열이 다른 입력인 문자열 목록일 수 있습니다. 차례로 응답은 포함 목록으로, 각 포함은 동일한 위치에 있는 입력에 해당합니다.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
팁
요청 일괄 처리를 만들 때 각 모델에 대한 일괄 처리 제한을 고려합니다. 대부분의 모델에는 1024 일괄 처리 제한이 있습니다.
포함 차원 지정
포함의 차원 수를 지정할 수 있습니다. 다음 예제 코드에서는 1024 차원의 포함을 만드는 방법을 보여 줍니다. 모든 포함 모델이 요청의 차원 수를 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
다양한 유형의 포함 만들기
일부 모델은 사용 계획에 따라 동일한 입력에 대해 여러 포함을 생성할 수 있습니다. 이 기능을 사용하면 RAG 패턴에 대해 좀 더 정확한 포함을 검색할 수 있습니다.
다음 예제에서는 벡터 데이터베이스에 저장될 문서에 대한 포함을 만드는 데 사용되는 포함을 만드는 방법을 보여 줍니다.
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
이러한 문서를 검색하는 쿼리를 실행할 때 다음 코드 조각을 사용하여 쿼리에 대한 포함을 만들고 검색 성능을 극대화할 수 있습니다.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
모든 포함 모델이 요청의 입력 형식을 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다. 기본적으로 형식 Text 의 포함이 반환됩니다.
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델과 함께 포함 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에 포함 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
embeddings 모델 배포입니다. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 embeddings 모델을 추가하는 읽기가 없는 경우
프로젝트에 Azure AI 유추 패키지를 추가합니다.
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
Entra ID를 사용하는 경우 다음 패키지도 필요합니다.
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>다음 네임스페이스를 가져옵니다.
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
포함 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
포함 만들기
포함 요청을 만들어 모델의 출력을 확인합니다.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
팁
요청을 만들 때 모델에 대한 토큰의 입력 제한을 고려합니다. 텍스트의 큰 부분을 포함해야 하는 경우 청크 분할 전략이 필요합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
입력 배치에서 포함을 계산하는 것이 유용할 수 있습니다. 매개 변수 inputs은/는 각 문자열이 다른 입력인 문자열 목록일 수 있습니다. 차례로 응답은 포함 목록으로, 각 포함은 동일한 위치에 있는 입력에 해당합니다.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
팁
요청 일괄 처리를 만들 때 각 모델에 대한 일괄 처리 제한을 고려합니다. 대부분의 모델에는 1024 일괄 처리 제한이 있습니다.
포함 차원 지정
포함의 차원 수를 지정할 수 있습니다. 다음 예제 코드에서는 1024 차원의 포함을 만드는 방법을 보여 줍니다. 모든 포함 모델이 요청의 차원 수를 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다.
다양한 유형의 포함 만들기
일부 모델은 사용 계획에 따라 동일한 입력에 대해 여러 포함을 생성할 수 있습니다. 이 기능을 사용하면 RAG 패턴에 대해 좀 더 정확한 포함을 검색할 수 있습니다.
다음 예제에서는 벡터 데이터베이스에 저장될 문서에 대한 포함을 만드는 데 사용되는 포함을 만드는 방법을 보여 줍니다.
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
이러한 문서를 검색하는 쿼리를 실행할 때 다음 코드 조각을 사용하여 쿼리에 대한 포함을 만들고 검색 성능을 극대화할 수 있습니다.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
모든 포함 모델이 요청의 입력 형식을 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다. 기본적으로 형식 Text 의 포함이 반환됩니다.
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델과 함께 포함 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에 포함 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
embeddings 모델 배포입니다. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 embeddings 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 Azure AI 유추 패키지를 설치합니다.
dotnet add package Azure.AI.Inference --prerelease팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
Entra ID를 사용하는 경우 다음 패키지도 필요합니다.
dotnet add package Azure.Identity
포함 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
포함 만들기
포함 요청을 만들어 모델의 출력을 확인합니다.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
팁
요청을 만들 때 모델에 대한 토큰의 입력 제한을 고려합니다. 텍스트의 큰 부분을 포함해야 하는 경우 청크 분할 전략이 필요합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
입력 배치에서 포함을 계산하는 것이 유용할 수 있습니다. 매개 변수 inputs은/는 각 문자열이 다른 입력인 문자열 목록일 수 있습니다. 차례로 응답은 포함 목록으로, 각 포함은 동일한 위치에 있는 입력에 해당합니다.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
팁
요청 일괄 처리를 만들 때 각 모델에 대한 일괄 처리 제한을 고려합니다. 대부분의 모델에는 1024 일괄 처리 제한이 있습니다.
포함 차원 지정
포함의 차원 수를 지정할 수 있습니다. 다음 예제 코드에서는 1024 차원의 포함을 만드는 방법을 보여 줍니다. 모든 포함 모델이 요청의 차원 수를 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다.
다양한 유형의 포함 만들기
일부 모델은 사용 계획에 따라 동일한 입력에 대해 여러 포함을 생성할 수 있습니다. 이 기능을 사용하면 RAG 패턴에 대해 좀 더 정확한 포함을 검색할 수 있습니다.
다음 예제에서는 벡터 데이터베이스에 저장될 문서에 대한 포함을 만드는 데 사용되는 포함을 만드는 방법을 보여 줍니다.
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
이러한 문서를 검색하는 쿼리를 실행할 때 다음 코드 조각을 사용하여 쿼리에 대한 포함을 만들고 검색 성능을 극대화할 수 있습니다.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
모든 포함 모델이 요청의 입력 형식을 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다. 기본적으로 형식 Text 의 포함이 반환됩니다.
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델과 함께 포함 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에 포함 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
- embeddings 모델 배포입니다. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 embeddings 모델을 추가하는 읽기가 없는 경우
포함 사용
텍스트 포함을 사용하려면 기본 URL에 추가된 경로 /embeddings 와 표시된 자격 증명 api-key을 사용합니다.
Authorization 헤더는 형식 Bearer <key>으로도 지원됩니다.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 헤더에 토큰을 Authorization 전달합니다.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
포함 만들기
포함 요청을 만들어 모델의 출력을 확인합니다.
{
"input": [
"The ultimate answer to the question of life"
]
}
팁
요청을 만들 때 모델에 대한 토큰의 입력 제한을 고려합니다. 텍스트의 큰 부분을 포함해야 하는 경우 청크 분할 전략이 필요합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
입력 배치에서 포함을 계산하는 것이 유용할 수 있습니다. 매개 변수 inputs은/는 각 문자열이 다른 입력인 문자열 목록일 수 있습니다. 차례로 응답은 포함 목록으로, 각 포함은 동일한 위치에 있는 입력에 해당합니다.
{
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
팁
요청 일괄 처리를 만들 때 각 모델에 대한 일괄 처리 제한을 고려합니다. 대부분의 모델에는 1024 일괄 처리 제한이 있습니다.
포함 차원 지정
포함의 차원 수를 지정할 수 있습니다. 다음 예제 코드에서는 1024 차원의 포함을 만드는 방법을 보여 줍니다. 모든 포함 모델이 요청의 차원 수를 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다.
{
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
다양한 유형의 포함 만들기
일부 모델은 사용 계획에 따라 동일한 입력에 대해 여러 포함을 생성할 수 있습니다. 이 기능을 사용하면 RAG 패턴에 대해 좀 더 정확한 포함을 검색할 수 있습니다.
다음 예제에서는 벡터 데이터베이스에 저장될 문서에 대한 포함을 만드는 데 사용되는 포함을 만드는 방법을 보여 줍니다.
{
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
이러한 문서를 검색하는 쿼리를 실행할 때 다음 코드 조각을 사용하여 쿼리에 대한 포함을 만들고 검색 성능을 극대화할 수 있습니다.
{
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
모든 포함 모델이 요청의 입력 형식을 나타내는 것을 지원하지 않으며 이러한 경우 422 오류가 반환됩니다. 기본적으로 형식 Text 의 포함이 반환됩니다.