Azure AI 모델 유추를 사용하여 채팅 완료를 생성하는 방법
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델에서 채팅 완료 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에서 채팅 완료 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.

채팅 완료 모델 배포. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 채팅 완성 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 Azure AI 유추 패키지를 설치합니다.
pip install -U azure-ai-inference팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
채팅 완료 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
채팅 완료 요청 만들기
다음 예제에서는 모델에 대한 기본 채팅 완료 요청을 만드는 방법을 보여 줍니다.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
참고 항목
일부 모델은 시스템 메시지(role="system")를 지원하지 않습니다. Azure AI 모델 유추 API를 사용하면 시스템 메시지가 사용자 메시지로 변환되는데, 이는 사용 가능한 기능 중 가장 가까운 기능입니다. 이러한 번역은 편의를 위해 제공되지만, 모델이 적절한 신뢰도 수준으로 시스템 메시지의 지침을 따르는지 확인해야 합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
응답의 usage 섹션을 검사하여 프롬프트에 사용된 토큰 수, 생성된 총 토큰 수 및 완료에 사용된 토큰 수를 확인합니다.
콘텐츠 스트리밍
기본적으로 완료 API는 생성된 전체 콘텐츠를 단일 응답으로 반환합니다. 긴 완료를 생성하는 경우 응답을 기다리는 데 몇 초 정도 걸릴 수 있습니다.
생성될 때 가져오기 위해 콘텐츠를 스트리밍할 수 있습니다. 콘텐츠를 스트리밍하면 콘텐츠를 사용할 수 있게 되면 완료 처리를 시작할 수 있습니다. 이 모드는 데이터 전용 서버 전송 이벤트 응답을 다시 스트리밍하는 개체를 반환합니다. 메시지 필드가 아닌 델타 필드에서 청크를 추출합니다.
완성을 스트리밍하려면 모델을 호출할 때 stream=True를 설정합니다.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
출력을 시각화하려면 스트림을 인쇄하는 도우미 함수를 정의합니다.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
스트리밍에서 콘텐츠를 생성하는 방법을 시각화할 수 있습니다.
print_stream(result)
유추 클라이언트에서 지원하는 더 많은 매개 변수 살펴보기
유추 클라이언트에서 지정할 수 있는 다른 매개 변수를 탐색합니다. 지원되는 모든 매개 변수 및 해당 설명서의 전체 목록은 Azure AI 모델 유추 API 참조를 확인하세요.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
일부 모델은 JSON 출력 형식 지정을 지원하지 않습니다. 언제든지 모델에 JSON 출력을 생성하라는 메시지를 표시할 수 있습니다. 그러나 이러한 출력이 유효한 JSON으로 보장되지는 않습니다.
지원되는 매개 변수 목록에 없는 매개 변수를 전달하려면 추가 매개 변수를 사용하여 기본 모델에 전달할 수 있습니다. 모델 추가 매개 변수 전달을 참조하세요.
JSON 출력 만들기
일부 모델은 JSON 출력을 만들 수 있습니다. JSON 모드를 사용하도록 설정하고 모델이 생성하는 메시지가 유효한 JSON임을 보장하려면 response_format을 json_object로 설정합니다. 시스템이나 사용자 메시지를 통해 모델이 직접 JSON을 생성하도록 지시해야 합니다. 또한 생성이 max_tokens를 초과했거나 대화가 최대 컨텍스트 길이를 초과했음을 나타내는 finish_reason="length"인 경우 메시지 콘텐츠가 부분적으로 잘릴 수 있습니다.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
모델에 추가 매개 변수 전달
Azure AI 모델 유추 API를 사용하면 모델에 추가 매개 변수를 전달할 수 있습니다. 다음 코드 예에서는 추가 매개 변수 logprobs를 모델에 전달하는 방법을 보여줍니다.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Azure AI 모델 유추 API에 추가 매개 변수를 전달하기 전에 모델이 이러한 추가 매개 변수를 지원하는지 확인합니다. 기본 모델에 대한 요청이 이루어지면 헤더 extra-parameters의 pass-through 값이 모델에 전달됩니다. 이 값은 모델에 추가 매개 변수를 전달하도록 엔드포인트에 지시합니다. 모델에서 추가 매개 변수를 사용하면 모델이 실제로 매개 변수를 처리할 수 있다고 보장할 수 없습니다. 지원되는 추가 매개 변수를 이해하려면 모델의 설명서를 읽어보세요.
도구 사용
일부 모델은 언어 모델에서 특정 작업을 오프로드해야 하는 경우 특별한 리소스가 될 수 있는 도구 사용을 지원하며, 대신 보다 결정적인 시스템 또는 다른 언어 모델에 의존합니다. Azure AI 모델 유추 API를 사용하면 다음과 같은 방식으로 도구를 정의할 수 있습니다.
다음 코드 예는 두 개의 다른 도시의 항공편 정보를 볼 수 있는 도구 정의를 만듭니다.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
이 예에서 함수의 출력은 선택한 경로에 이용 가능한 항공편이 없으므로, 사용자는 기차를 타는 것을 고려해야 한다는 것입니다.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
참고 항목
일관된 모델을 사용하려면 도구의 응답이 문자열로 형식이 지정된 유효한 JSON 콘텐츠여야 합니다. 도구 형식의 메시지를 구성할 때 응답이 유효한 JSON 문자열인지 확인합니다.
이 함수를 사용하여 모델이 항공편을 예약하도록 합니다.
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
응답을 검사하여 도구를 호출해야 하는지 확인할 수 있습니다. 도구를 호출해야 하는지 확인하려면 최종 원인을 조사합니다. 여러 가지 도구 형식이 표시될 수 있다는 점에 유념해야 합니다. 이 예에서는 function 형식의 도구를 보여 줍니다.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
계속하려면 이 메시지를 채팅 기록에 추가합니다.
messages.append(
response_message
)
이제 도구 호출을 처리하기 위해 적절한 함수를 호출할 때입니다. 다음 코드 조각은 응답에 표시된 모든 도구 호출을 반복하고 적절한 매개 변수로 해당 함수를 호출합니다. 응답은 채팅 기록에도 추가됩니다.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
모델의 응답을 확인합니다.
response = client.complete(
messages=messages,
tools=tools,
)
콘텐츠 안전 적용
Azure AI 모델 유추 API는 Azure AI 콘텐츠 안전을 지원합니다. Azure AI 콘텐츠 안전이 켜져 있는 배포를 사용하는 경우 입력 및 출력은 유해한 콘텐츠의 출력을 감지하고 방지하기 위한 분류 모델의 앙상블을 통과합니다. 콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
다음 예제에서는 모델이 입력 프롬프트에서 유해한 콘텐츠를 감지하고 콘텐츠 안전이 사용하도록 설정된 경우 이벤트를 처리하는 방법을 보여 줍니다.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
팁
Azure AI 콘텐츠 안전 설정을 구성하고 제어하는 방법에 대한 자세한 내용은 Azure AI 콘텐츠 안전 설명서를 확인하세요.
이미지와 함께 채팅 완료 사용
일부 모델은 텍스트와 이미지에서 추론하고 두 종류의 입력을 기반으로 텍스트 완성을 생성할 수 있습니다. 이 섹션에서는 채팅 방식으로 비전에 대한 일부 모델의 기능을 탐색합니다.
Important
일부 모델은 채팅 대화의 각 턴에 대해 하나의 이미지만 지원하며 마지막 이미지만 컨텍스트에 유지됩니다. 여러 이미지를 추가하면 오류가 발생합니다.
이 기능을 보려면 이미지를 다운로드하고 정보를 base64 문자열로 인코딩합니다. 결과 데이터는 데이터 URL 내에 있어야 합니다.
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
이미지 시각화:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

이제 이미지를 사용하여 채팅 완료 요청을 만듭니다.
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
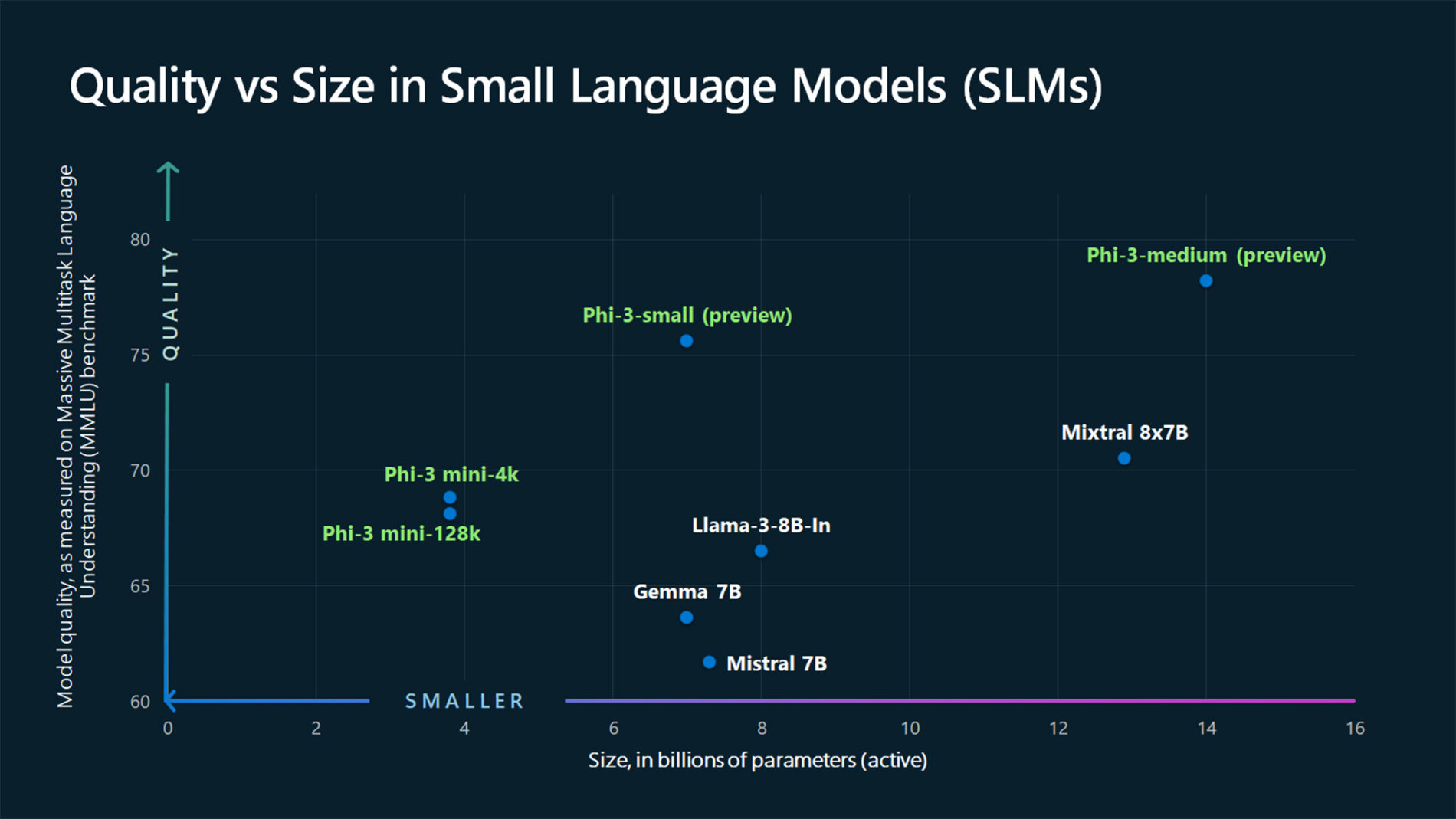
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델에서 채팅 완료 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에서 채팅 완료 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
채팅 완료 모델 배포. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 채팅 완성 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 JavaScript용 Azure 유추 라이브러리를 설치합니다.
npm install @azure-rest/ai-inference팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
채팅 완료 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
채팅 완료 요청 만들기
다음 예제에서는 모델에 대한 기본 채팅 완료 요청을 만드는 방법을 보여 줍니다.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
참고 항목
일부 모델은 시스템 메시지(role="system")를 지원하지 않습니다. Azure AI 모델 유추 API를 사용하면 시스템 메시지가 사용자 메시지로 변환되는데, 이는 사용 가능한 기능 중 가장 가까운 기능입니다. 이러한 번역은 편의를 위해 제공되지만, 모델이 적절한 신뢰도 수준으로 시스템 메시지의 지침을 따르는지 확인해야 합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
응답의 usage 섹션을 검사하여 프롬프트에 사용된 토큰 수, 생성된 총 토큰 수 및 완료에 사용된 토큰 수를 확인합니다.
콘텐츠 스트리밍
기본적으로 완료 API는 생성된 전체 콘텐츠를 단일 응답으로 반환합니다. 긴 완료를 생성하는 경우 응답을 기다리는 데 몇 초 정도 걸릴 수 있습니다.
생성될 때 가져오기 위해 콘텐츠를 스트리밍할 수 있습니다. 콘텐츠를 스트리밍하면 콘텐츠를 사용할 수 있게 되면 완료 처리를 시작할 수 있습니다. 이 모드는 데이터 전용 서버 전송 이벤트 응답을 다시 스트리밍하는 개체를 반환합니다. 메시지 필드가 아닌 델타 필드에서 청크를 추출합니다.
완성을 스트리밍하려면 모델을 호출할 때 .asNodeStream()을 사용합니다.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
스트리밍에서 콘텐츠를 생성하는 방법을 시각화할 수 있습니다.
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
유추 클라이언트에서 지원하는 더 많은 매개 변수 살펴보기
유추 클라이언트에서 지정할 수 있는 다른 매개 변수를 탐색합니다. 지원되는 모든 매개 변수 및 해당 설명서의 전체 목록은 Azure AI 모델 유추 API 참조를 확인하세요.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
일부 모델은 JSON 출력 형식 지정을 지원하지 않습니다. 언제든지 모델에 JSON 출력을 생성하라는 메시지를 표시할 수 있습니다. 그러나 이러한 출력이 유효한 JSON으로 보장되지는 않습니다.
지원되는 매개 변수 목록에 없는 매개 변수를 전달하려면 추가 매개 변수를 사용하여 기본 모델에 전달할 수 있습니다. 모델 추가 매개 변수 전달을 참조하세요.
JSON 출력 만들기
일부 모델은 JSON 출력을 만들 수 있습니다. JSON 모드를 사용하도록 설정하고 모델이 생성하는 메시지가 유효한 JSON임을 보장하려면 response_format을 json_object로 설정합니다. 시스템이나 사용자 메시지를 통해 모델이 직접 JSON을 생성하도록 지시해야 합니다. 또한 생성이 max_tokens를 초과했거나 대화가 최대 컨텍스트 길이를 초과했음을 나타내는 finish_reason="length"인 경우 메시지 콘텐츠가 부분적으로 잘릴 수 있습니다.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
모델에 추가 매개 변수 전달
Azure AI 모델 유추 API를 사용하면 모델에 추가 매개 변수를 전달할 수 있습니다. 다음 코드 예에서는 추가 매개 변수 logprobs를 모델에 전달하는 방법을 보여줍니다.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Azure AI 모델 유추 API에 추가 매개 변수를 전달하기 전에 모델이 이러한 추가 매개 변수를 지원하는지 확인합니다. 기본 모델에 대한 요청이 이루어지면 헤더 extra-parameters의 pass-through 값이 모델에 전달됩니다. 이 값은 모델에 추가 매개 변수를 전달하도록 엔드포인트에 지시합니다. 모델에서 추가 매개 변수를 사용하면 모델이 실제로 매개 변수를 처리할 수 있다고 보장할 수 없습니다. 지원되는 추가 매개 변수를 이해하려면 모델의 설명서를 읽어보세요.
도구 사용
일부 모델은 언어 모델에서 특정 작업을 오프로드해야 하는 경우 특별한 리소스가 될 수 있는 도구 사용을 지원하며, 대신 보다 결정적인 시스템 또는 다른 언어 모델에 의존합니다. Azure AI 모델 유추 API를 사용하면 다음과 같은 방식으로 도구를 정의할 수 있습니다.
다음 코드 예는 두 개의 다른 도시의 항공편 정보를 볼 수 있는 도구 정의를 만듭니다.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
이 예에서 함수의 출력은 선택한 경로에 이용 가능한 항공편이 없으므로, 사용자는 기차를 타는 것을 고려해야 한다는 것입니다.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
참고 항목
일관된 모델을 사용하려면 도구의 응답이 문자열로 형식이 지정된 유효한 JSON 콘텐츠여야 합니다. 도구 형식의 메시지를 구성할 때 응답이 유효한 JSON 문자열인지 확인합니다.
이 함수를 사용하여 모델이 항공편을 예약하도록 합니다.
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
응답을 검사하여 도구를 호출해야 하는지 확인할 수 있습니다. 도구를 호출해야 하는지 확인하려면 최종 원인을 조사합니다. 여러 가지 도구 형식이 표시될 수 있다는 점에 유념해야 합니다. 이 예에서는 function 형식의 도구를 보여 줍니다.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
계속하려면 이 메시지를 채팅 기록에 추가합니다.
messages.push(response_message);
이제 도구 호출을 처리하기 위해 적절한 함수를 호출할 때입니다. 다음 코드 조각은 응답에 표시된 모든 도구 호출을 반복하고 적절한 매개 변수로 해당 함수를 호출합니다. 응답은 채팅 기록에도 추가됩니다.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
모델의 응답을 확인합니다.
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
콘텐츠 안전 적용
Azure AI 모델 유추 API는 Azure AI 콘텐츠 안전을 지원합니다. Azure AI 콘텐츠 안전이 켜져 있는 배포를 사용하는 경우 입력 및 출력은 유해한 콘텐츠의 출력을 감지하고 방지하기 위한 분류 모델의 앙상블을 통과합니다. 콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
다음 예제에서는 모델이 입력 프롬프트에서 유해한 콘텐츠를 감지하고 콘텐츠 안전이 사용하도록 설정된 경우 이벤트를 처리하는 방법을 보여 줍니다.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
팁
Azure AI 콘텐츠 안전 설정을 구성하고 제어하는 방법에 대한 자세한 내용은 Azure AI 콘텐츠 안전 설명서를 확인하세요.
이미지와 함께 채팅 완료 사용
일부 모델은 텍스트와 이미지에서 추론하고 두 종류의 입력을 기반으로 텍스트 완성을 생성할 수 있습니다. 이 섹션에서는 채팅 방식으로 비전에 대한 일부 모델의 기능을 탐색합니다.
Important
일부 모델은 채팅 대화의 각 턴에 대해 하나의 이미지만 지원하며 마지막 이미지만 컨텍스트에 유지됩니다. 여러 이미지를 추가하면 오류가 발생합니다.
이 기능을 보려면 이미지를 다운로드하고 정보를 base64 문자열로 인코딩합니다. 결과 데이터는 데이터 URL 내에 있어야 합니다.
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
이미지 시각화:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
이제 이미지를 사용하여 채팅 완료 요청을 만듭니다.
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델에서 채팅 완료 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에서 채팅 완료 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
채팅 완료 모델 배포. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 채팅 완성 모델을 추가하는 읽기가 없는 경우
프로젝트에 Azure AI 유추 패키지를 추가합니다.
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
Entra ID를 사용하는 경우 다음 패키지도 필요합니다.
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>다음 네임스페이스를 가져옵니다.
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
채팅 완료 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
채팅 완료 요청 만들기
다음 예제에서는 모델에 대한 기본 채팅 완료 요청을 만드는 방법을 보여 줍니다.
참고 항목
일부 모델은 시스템 메시지(role="system")를 지원하지 않습니다. Azure AI 모델 유추 API를 사용하면 시스템 메시지가 사용자 메시지로 변환되는데, 이는 사용 가능한 기능 중 가장 가까운 기능입니다. 이러한 번역은 편의를 위해 제공되지만, 모델이 적절한 신뢰도 수준으로 시스템 메시지의 지침을 따르는지 확인해야 합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
응답의 usage 섹션을 검사하여 프롬프트에 사용된 토큰 수, 생성된 총 토큰 수 및 완료에 사용된 토큰 수를 확인합니다.
콘텐츠 스트리밍
기본적으로 완료 API는 생성된 전체 콘텐츠를 단일 응답으로 반환합니다. 긴 완료를 생성하는 경우 응답을 기다리는 데 몇 초 정도 걸릴 수 있습니다.
생성될 때 가져오기 위해 콘텐츠를 스트리밍할 수 있습니다. 콘텐츠를 스트리밍하면 콘텐츠를 사용할 수 있게 되면 완료 처리를 시작할 수 있습니다. 이 모드는 데이터 전용 서버 전송 이벤트 응답을 다시 스트리밍하는 개체를 반환합니다. 메시지 필드가 아닌 델타 필드에서 청크를 추출합니다.
스트리밍에서 콘텐츠를 생성하는 방법을 시각화할 수 있습니다.
유추 클라이언트에서 지원하는 더 많은 매개 변수 살펴보기
유추 클라이언트에서 지정할 수 있는 다른 매개 변수를 탐색합니다. 지원되는 모든 매개 변수 및 해당 설명서의 전체 목록은 Azure AI 모델 유추 API 참조를 확인하세요. 일부 모델은 JSON 출력 형식 지정을 지원하지 않습니다. 언제든지 모델에 JSON 출력을 생성하라는 메시지를 표시할 수 있습니다. 그러나 이러한 출력이 유효한 JSON으로 보장되지는 않습니다.
지원되는 매개 변수 목록에 없는 매개 변수를 전달하려면 추가 매개 변수를 사용하여 기본 모델에 전달할 수 있습니다. 모델 추가 매개 변수 전달을 참조하세요.
JSON 출력 만들기
일부 모델은 JSON 출력을 만들 수 있습니다. JSON 모드를 사용하도록 설정하고 모델이 생성하는 메시지가 유효한 JSON임을 보장하려면 response_format을 json_object로 설정합니다. 시스템이나 사용자 메시지를 통해 모델이 직접 JSON을 생성하도록 지시해야 합니다. 또한 생성이 max_tokens를 초과했거나 대화가 최대 컨텍스트 길이를 초과했음을 나타내는 finish_reason="length"인 경우 메시지 콘텐츠가 부분적으로 잘릴 수 있습니다.
모델에 추가 매개 변수 전달
Azure AI 모델 유추 API를 사용하면 모델에 추가 매개 변수를 전달할 수 있습니다. 다음 코드 예에서는 추가 매개 변수 logprobs를 모델에 전달하는 방법을 보여줍니다.
Azure AI 모델 유추 API에 추가 매개 변수를 전달하기 전에 모델이 이러한 추가 매개 변수를 지원하는지 확인합니다. 기본 모델에 대한 요청이 이루어지면 헤더 extra-parameters의 pass-through 값이 모델에 전달됩니다. 이 값은 모델에 추가 매개 변수를 전달하도록 엔드포인트에 지시합니다. 모델에서 추가 매개 변수를 사용하면 모델이 실제로 매개 변수를 처리할 수 있다고 보장할 수 없습니다. 지원되는 추가 매개 변수를 이해하려면 모델의 설명서를 읽어보세요.
도구 사용
일부 모델은 언어 모델에서 특정 작업을 오프로드해야 하는 경우 특별한 리소스가 될 수 있는 도구 사용을 지원하며, 대신 보다 결정적인 시스템 또는 다른 언어 모델에 의존합니다. Azure AI 모델 유추 API를 사용하면 다음과 같은 방식으로 도구를 정의할 수 있습니다.
다음 코드 예는 두 개의 다른 도시의 항공편 정보를 볼 수 있는 도구 정의를 만듭니다.
이 예에서 함수의 출력은 선택한 경로에 이용 가능한 항공편이 없으므로, 사용자는 기차를 타는 것을 고려해야 한다는 것입니다.
참고 항목
일관된 모델을 사용하려면 도구의 응답이 문자열로 형식이 지정된 유효한 JSON 콘텐츠여야 합니다. 도구 형식의 메시지를 구성할 때 응답이 유효한 JSON 문자열인지 확인합니다.
이 함수를 사용하여 모델이 항공편을 예약하도록 합니다.
응답을 검사하여 도구를 호출해야 하는지 확인할 수 있습니다. 도구를 호출해야 하는지 확인하려면 최종 원인을 조사합니다. 여러 가지 도구 형식이 표시될 수 있다는 점에 유념해야 합니다. 이 예에서는 function 형식의 도구를 보여 줍니다.
계속하려면 이 메시지를 채팅 기록에 추가합니다.
이제 도구 호출을 처리하기 위해 적절한 함수를 호출할 때입니다. 다음 코드 조각은 응답에 표시된 모든 도구 호출을 반복하고 적절한 매개 변수로 해당 함수를 호출합니다. 응답은 채팅 기록에도 추가됩니다.
모델의 응답을 확인합니다.
콘텐츠 안전 적용
Azure AI 모델 유추 API는 Azure AI 콘텐츠 안전을 지원합니다. Azure AI 콘텐츠 안전이 켜져 있는 배포를 사용하는 경우 입력 및 출력은 유해한 콘텐츠의 출력을 감지하고 방지하기 위한 분류 모델의 앙상블을 통과합니다. 콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
다음 예제에서는 모델이 입력 프롬프트에서 유해한 콘텐츠를 감지하고 콘텐츠 안전이 사용하도록 설정된 경우 이벤트를 처리하는 방법을 보여 줍니다.
팁
Azure AI 콘텐츠 안전 설정을 구성하고 제어하는 방법에 대한 자세한 내용은 Azure AI 콘텐츠 안전 설명서를 확인하세요.
이미지와 함께 채팅 완료 사용
일부 모델은 텍스트와 이미지에서 추론하고 두 종류의 입력을 기반으로 텍스트 완성을 생성할 수 있습니다. 이 섹션에서는 채팅 방식으로 비전에 대한 일부 모델의 기능을 탐색합니다.
Important
일부 모델은 채팅 대화의 각 턴에 대해 하나의 이미지만 지원하며 마지막 이미지만 컨텍스트에 유지됩니다. 여러 이미지를 추가하면 오류가 발생합니다.
이 기능을 보려면 이미지를 다운로드하고 정보를 base64 문자열로 인코딩합니다. 결과 데이터는 데이터 URL 내에 있어야 합니다.
이미지 시각화:
이제 이미지를 사용하여 채팅 완료 요청을 만듭니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델에서 채팅 완료 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에서 채팅 완료 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
채팅 완료 모델 배포. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 채팅 완성 모델을 추가하는 읽기가 없는 경우
다음 명령을 사용하여 Azure AI 유추 패키지를 설치합니다.
dotnet add package Azure.AI.Inference --prerelease팁
Azure AI 유추 패키지 및 참조에 대해 자세히 알아보세요.
Entra ID를 사용하는 경우 다음 패키지도 필요합니다.
dotnet add package Azure.Identity
채팅 완료 사용
먼저 모델을 사용할 클라이언트를 만듭니다. 다음 코드는 환경 변수에 저장된 엔드포인트 URL과 키를 사용합니다.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 다음 코드 조각을 사용하여 클라이언트를 만들 수 있습니다.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
채팅 완료 요청 만들기
다음 예제에서는 모델에 대한 기본 채팅 완료 요청을 만드는 방법을 보여 줍니다.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
참고 항목
일부 모델은 시스템 메시지(role="system")를 지원하지 않습니다. Azure AI 모델 유추 API를 사용하면 시스템 메시지가 사용자 메시지로 변환되는데, 이는 사용 가능한 기능 중 가장 가까운 기능입니다. 이러한 번역은 편의를 위해 제공되지만, 모델이 적절한 신뢰도 수준으로 시스템 메시지의 지침을 따르는지 확인해야 합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
응답의 usage 섹션을 검사하여 프롬프트에 사용된 토큰 수, 생성된 총 토큰 수 및 완료에 사용된 토큰 수를 확인합니다.
콘텐츠 스트리밍
기본적으로 완료 API는 생성된 전체 콘텐츠를 단일 응답으로 반환합니다. 긴 완료를 생성하는 경우 응답을 기다리는 데 몇 초 정도 걸릴 수 있습니다.
생성될 때 가져오기 위해 콘텐츠를 스트리밍할 수 있습니다. 콘텐츠를 스트리밍하면 콘텐츠를 사용할 수 있게 되면 완료 처리를 시작할 수 있습니다. 이 모드는 데이터 전용 서버 전송 이벤트 응답을 다시 스트리밍하는 개체를 반환합니다. 메시지 필드가 아닌 델타 필드에서 청크를 추출합니다.
완성을 스트리밍하려면 모델을 호출할 때 CompleteStreamingAsync 메서드를 사용합니다. 이 예제에서는 호출이 비동기 메서드로 래핑됩니다.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
출력을 시각화하려면 콘솔에서 스트림을 인쇄하는 비동기 메서드를 정의합니다.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
스트리밍에서 콘텐츠를 생성하는 방법을 시각화할 수 있습니다.
StreamMessageAsync(client).GetAwaiter().GetResult();
유추 클라이언트에서 지원하는 더 많은 매개 변수 살펴보기
유추 클라이언트에서 지정할 수 있는 다른 매개 변수를 탐색합니다. 지원되는 모든 매개 변수 및 해당 설명서의 전체 목록은 Azure AI 모델 유추 API 참조를 확인하세요.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
일부 모델은 JSON 출력 형식 지정을 지원하지 않습니다. 언제든지 모델에 JSON 출력을 생성하라는 메시지를 표시할 수 있습니다. 그러나 이러한 출력이 유효한 JSON으로 보장되지는 않습니다.
지원되는 매개 변수 목록에 없는 매개 변수를 전달하려면 추가 매개 변수를 사용하여 기본 모델에 전달할 수 있습니다. 모델 추가 매개 변수 전달을 참조하세요.
JSON 출력 만들기
일부 모델은 JSON 출력을 만들 수 있습니다. JSON 모드를 사용하도록 설정하고 모델이 생성하는 메시지가 유효한 JSON임을 보장하려면 response_format을 json_object로 설정합니다. 시스템이나 사용자 메시지를 통해 모델이 직접 JSON을 생성하도록 지시해야 합니다. 또한 생성이 max_tokens를 초과했거나 대화가 최대 컨텍스트 길이를 초과했음을 나타내는 finish_reason="length"인 경우 메시지 콘텐츠가 부분적으로 잘릴 수 있습니다.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
모델에 추가 매개 변수 전달
Azure AI 모델 유추 API를 사용하면 모델에 추가 매개 변수를 전달할 수 있습니다. 다음 코드 예에서는 추가 매개 변수 logprobs를 모델에 전달하는 방법을 보여줍니다.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Azure AI 모델 유추 API에 추가 매개 변수를 전달하기 전에 모델이 이러한 추가 매개 변수를 지원하는지 확인합니다. 기본 모델에 대한 요청이 이루어지면 헤더 extra-parameters의 pass-through 값이 모델에 전달됩니다. 이 값은 모델에 추가 매개 변수를 전달하도록 엔드포인트에 지시합니다. 모델에서 추가 매개 변수를 사용하면 모델이 실제로 매개 변수를 처리할 수 있다고 보장할 수 없습니다. 지원되는 추가 매개 변수를 이해하려면 모델의 설명서를 읽어보세요.
도구 사용
일부 모델은 언어 모델에서 특정 작업을 오프로드해야 하는 경우 특별한 리소스가 될 수 있는 도구 사용을 지원하며, 대신 보다 결정적인 시스템 또는 다른 언어 모델에 의존합니다. Azure AI 모델 유추 API를 사용하면 다음과 같은 방식으로 도구를 정의할 수 있습니다.
다음 코드 예는 두 개의 다른 도시의 항공편 정보를 볼 수 있는 도구 정의를 만듭니다.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
이 예에서 함수의 출력은 선택한 경로에 이용 가능한 항공편이 없으므로, 사용자는 기차를 타는 것을 고려해야 한다는 것입니다.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
참고 항목
일관된 모델을 사용하려면 도구의 응답이 문자열로 형식이 지정된 유효한 JSON 콘텐츠여야 합니다. 도구 형식의 메시지를 구성할 때 응답이 유효한 JSON 문자열인지 확인합니다.
이 함수를 사용하여 모델이 항공편을 예약하도록 합니다.
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
응답을 검사하여 도구를 호출해야 하는지 확인할 수 있습니다. 도구를 호출해야 하는지 확인하려면 최종 원인을 조사합니다. 여러 가지 도구 형식이 표시될 수 있다는 점에 유념해야 합니다. 이 예에서는 function 형식의 도구를 보여 줍니다.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
계속하려면 이 메시지를 채팅 기록에 추가합니다.
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
이제 도구 호출을 처리하기 위해 적절한 함수를 호출할 때입니다. 다음 코드 조각은 응답에 표시된 모든 도구 호출을 반복하고 적절한 매개 변수로 해당 함수를 호출합니다. 응답은 채팅 기록에도 추가됩니다.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
모델의 응답을 확인합니다.
response = client.Complete(requestOptions);
콘텐츠 안전 적용
Azure AI 모델 유추 API는 Azure AI 콘텐츠 안전을 지원합니다. Azure AI 콘텐츠 안전이 켜져 있는 배포를 사용하는 경우 입력 및 출력은 유해한 콘텐츠의 출력을 감지하고 방지하기 위한 분류 모델의 앙상블을 통과합니다. 콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
다음 예제에서는 모델이 입력 프롬프트에서 유해한 콘텐츠를 감지하고 콘텐츠 안전이 사용하도록 설정된 경우 이벤트를 처리하는 방법을 보여 줍니다.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
팁
Azure AI 콘텐츠 안전 설정을 구성하고 제어하는 방법에 대한 자세한 내용은 Azure AI 콘텐츠 안전 설명서를 확인하세요.
이미지와 함께 채팅 완료 사용
일부 모델은 텍스트와 이미지에서 추론하고 두 종류의 입력을 기반으로 텍스트 완성을 생성할 수 있습니다. 이 섹션에서는 채팅 방식으로 비전에 대한 일부 모델의 기능을 탐색합니다.
Important
일부 모델은 채팅 대화의 각 턴에 대해 하나의 이미지만 지원하며 마지막 이미지만 컨텍스트에 유지됩니다. 여러 이미지를 추가하면 오류가 발생합니다.
이 기능을 보려면 이미지를 다운로드하고 정보를 base64 문자열로 인코딩합니다. 결과 데이터는 데이터 URL 내에 있어야 합니다.
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
이미지 시각화:
이제 이미지를 사용하여 채팅 완료 요청을 만듭니다.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure AI 서비스에서 Azure AI 모델 유추에 배포된 모델에서 채팅 완료 API를 사용하는 방법을 설명합니다.
필수 조건
애플리케이션에서 채팅 완료 모델을 사용하려면 다음이 필요합니다.
Azure 구독 GitHub 모델을 사용하는 경우 환경을 업그레이드하고 프로세스에서 Azure 구독을 만들 수 있습니다. 이 경우 GitHub 모델에서 Azure AI 모델 유추로 업그레이드를 읽습니다.
Azure AI 서비스 리소스입니다. 자세한 내용은 Azure AI Services 리소스 만들기를 참조 하세요.
엔드포인트 URL 및 키입니다.
- 채팅 완료 모델 배포. Azure AI 서비스에 모델을 추가하고 구성하여 리소스에 채팅 완성 모델을 추가하는 읽기가 없는 경우
채팅 완료 사용
텍스트 포함을 사용하려면 기본 URL에 추가된 경로 /chat/completions 와 표시된 자격 증명 api-key을 사용합니다.
Authorization 헤더는 형식 Bearer <key>으로도 지원됩니다.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Microsoft Entra ID 지원을 사용하여 리소스를 구성한 경우 헤더에 토큰을 Authorization 전달합니다.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
채팅 완료 요청 만들기
다음 예제에서는 모델에 대한 기본 채팅 완료 요청을 만드는 방법을 보여 줍니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
참고 항목
일부 모델은 시스템 메시지(role="system")를 지원하지 않습니다. Azure AI 모델 유추 API를 사용하면 시스템 메시지가 사용자 메시지로 변환되는데, 이는 사용 가능한 기능 중 가장 가까운 기능입니다. 이러한 번역은 편의를 위해 제공되지만, 모델이 적절한 신뢰도 수준으로 시스템 메시지의 지침을 따르는지 확인해야 합니다.
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
응답의 usage 섹션을 검사하여 프롬프트에 사용된 토큰 수, 생성된 총 토큰 수 및 완료에 사용된 토큰 수를 확인합니다.
콘텐츠 스트리밍
기본적으로 완료 API는 생성된 전체 콘텐츠를 단일 응답으로 반환합니다. 긴 완료를 생성하는 경우 응답을 기다리는 데 몇 초 정도 걸릴 수 있습니다.
생성될 때 가져오기 위해 콘텐츠를 스트리밍할 수 있습니다. 콘텐츠를 스트리밍하면 콘텐츠를 사용할 수 있게 되면 완료 처리를 시작할 수 있습니다. 이 모드는 데이터 전용 서버 전송 이벤트 응답을 다시 스트리밍하는 개체를 반환합니다. 메시지 필드가 아닌 델타 필드에서 청크를 추출합니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
스트리밍에서 콘텐츠를 생성하는 방법을 시각화할 수 있습니다.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
스트림의 마지막 메시지는 생성 프로세스가 중지되는 이유를 나타내는 finish_reason이 설정되었습니다.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
유추 클라이언트에서 지원하는 더 많은 매개 변수 살펴보기
유추 클라이언트에서 지정할 수 있는 다른 매개 변수를 탐색합니다. 지원되는 모든 매개 변수 및 해당 설명서의 전체 목록은 Azure AI 모델 유추 API 참조를 확인하세요.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
일부 모델은 JSON 출력 형식 지정을 지원하지 않습니다. 언제든지 모델에 JSON 출력을 생성하라는 메시지를 표시할 수 있습니다. 그러나 이러한 출력이 유효한 JSON으로 보장되지는 않습니다.
지원되는 매개 변수 목록에 없는 매개 변수를 전달하려면 추가 매개 변수를 사용하여 기본 모델에 전달할 수 있습니다. 모델 추가 매개 변수 전달을 참조하세요.
JSON 출력 만들기
일부 모델은 JSON 출력을 만들 수 있습니다. JSON 모드를 사용하도록 설정하고 모델이 생성하는 메시지가 유효한 JSON임을 보장하려면 response_format을 json_object로 설정합니다. 시스템이나 사용자 메시지를 통해 모델이 직접 JSON을 생성하도록 지시해야 합니다. 또한 생성이 max_tokens를 초과했거나 대화가 최대 컨텍스트 길이를 초과했음을 나타내는 finish_reason="length"인 경우 메시지 콘텐츠가 부분적으로 잘릴 수 있습니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
모델에 추가 매개 변수 전달
Azure AI 모델 유추 API를 사용하면 모델에 추가 매개 변수를 전달할 수 있습니다. 다음 코드 예에서는 추가 매개 변수 logprobs를 모델에 전달하는 방법을 보여줍니다.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Azure AI 모델 유추 API에 추가 매개 변수를 전달하기 전에 모델이 이러한 추가 매개 변수를 지원하는지 확인합니다. 기본 모델에 대한 요청이 이루어지면 헤더 extra-parameters의 pass-through 값이 모델에 전달됩니다. 이 값은 모델에 추가 매개 변수를 전달하도록 엔드포인트에 지시합니다. 모델에서 추가 매개 변수를 사용하면 모델이 실제로 매개 변수를 처리할 수 있다고 보장할 수 없습니다. 지원되는 추가 매개 변수를 이해하려면 모델의 설명서를 읽어보세요.
도구 사용
일부 모델은 언어 모델에서 특정 작업을 오프로드해야 하는 경우 특별한 리소스가 될 수 있는 도구 사용을 지원하며, 대신 보다 결정적인 시스템 또는 다른 언어 모델에 의존합니다. Azure AI 모델 유추 API를 사용하면 다음과 같은 방식으로 도구를 정의할 수 있습니다.
다음 코드 예는 두 개의 다른 도시의 항공편 정보를 볼 수 있는 도구 정의를 만듭니다.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
이 예에서 함수의 출력은 선택한 경로에 이용 가능한 항공편이 없으므로, 사용자는 기차를 타는 것을 고려해야 한다는 것입니다.
참고 항목
일관된 모델을 사용하려면 도구의 응답이 문자열로 형식이 지정된 유효한 JSON 콘텐츠여야 합니다. 도구 형식의 메시지를 구성할 때 응답이 유효한 JSON 문자열인지 확인합니다.
이 함수를 사용하여 모델이 항공편을 예약하도록 합니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
응답을 검사하여 도구를 호출해야 하는지 확인할 수 있습니다. 도구를 호출해야 하는지 확인하려면 최종 원인을 조사합니다. 여러 가지 도구 형식이 표시될 수 있다는 점에 유념해야 합니다. 이 예에서는 function 형식의 도구를 보여 줍니다.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
계속하려면 이 메시지를 채팅 기록에 추가합니다.
이제 도구 호출을 처리하기 위해 적절한 함수를 호출할 때입니다. 다음 코드 조각은 응답에 표시된 모든 도구 호출을 반복하고 적절한 매개 변수로 해당 함수를 호출합니다. 응답은 채팅 기록에도 추가됩니다.
모델의 응답을 확인합니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
콘텐츠 안전 적용
Azure AI 모델 유추 API는 Azure AI 콘텐츠 안전을 지원합니다. Azure AI 콘텐츠 안전이 켜져 있는 배포를 사용하는 경우 입력 및 출력은 유해한 콘텐츠의 출력을 감지하고 방지하기 위한 분류 모델의 앙상블을 통과합니다. 콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
다음 예제에서는 모델이 입력 프롬프트에서 유해한 콘텐츠를 감지하고 콘텐츠 안전이 사용하도록 설정된 경우 이벤트를 처리하는 방법을 보여 줍니다.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
팁
Azure AI 콘텐츠 안전 설정을 구성하고 제어하는 방법에 대한 자세한 내용은 Azure AI 콘텐츠 안전 설명서를 확인하세요.
이미지와 함께 채팅 완료 사용
일부 모델은 텍스트와 이미지에서 추론하고 두 종류의 입력을 기반으로 텍스트 완성을 생성할 수 있습니다. 이 섹션에서는 채팅 방식으로 비전에 대한 일부 모델의 기능을 탐색합니다.
Important
일부 모델은 채팅 대화의 각 턴에 대해 하나의 이미지만 지원하며 마지막 이미지만 컨텍스트에 유지됩니다. 여러 이미지를 추가하면 오류가 발생합니다.
이 기능을 보려면 이미지를 다운로드하고 정보를 base64 문자열로 인코딩합니다. 결과 데이터는 데이터 URL 내에 있어야 합니다.
팁
스크립팅 또는 프로그래밍 언어를 사용하여 데이터 URL을 생성해야 합니다. 이 자습서에서는 JPEG 형식의 이 샘플 이미지를 사용합니다. 데이터 URL의 형식은 다음과 같습니다. data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
{kind=link}
이미지 시각화:
이제 이미지를 사용하여 채팅 완료 요청을 만듭니다.
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
응답은 다음과 같습니다. 여기서 모델의 사용 통계를 볼 수 있습니다.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}