マルチエンジン同期
ほとんどの最新の GPU には、特殊な機能を提供する複数の独立したエンジンが含まれています。 多くの場合、1 つ以上の専用コピー エンジンとコンピューティング エンジンがあり、通常は 3D エンジンとは異なります。 これらの各エンジンは、互いに並列でコマンドを実行できます。 Direct3D 12 では、キューとコマンド リストを使用して、3D、コンピューティング、およびコピー エンジンにきめ細かくアクセスできます。
GPU エンジン
次の図は、タイトルの CPU スレッドを示しています。それぞれが 1 つ以上のコピー、コンピューティング、および 3D キューを設定しています。 3D キューは、3 つの GPU エンジンすべてを駆動できます。コンピューティング キューは、コンピューティング エンジンとコピー エンジンを駆動できます。とコピー キューは単にコピー エンジンです。
異なるスレッドによってキューが設定されるため、実行順序を簡単に保証することはできません。そのため、タイトルで必要な場合は同期メカニズムが必要になります。
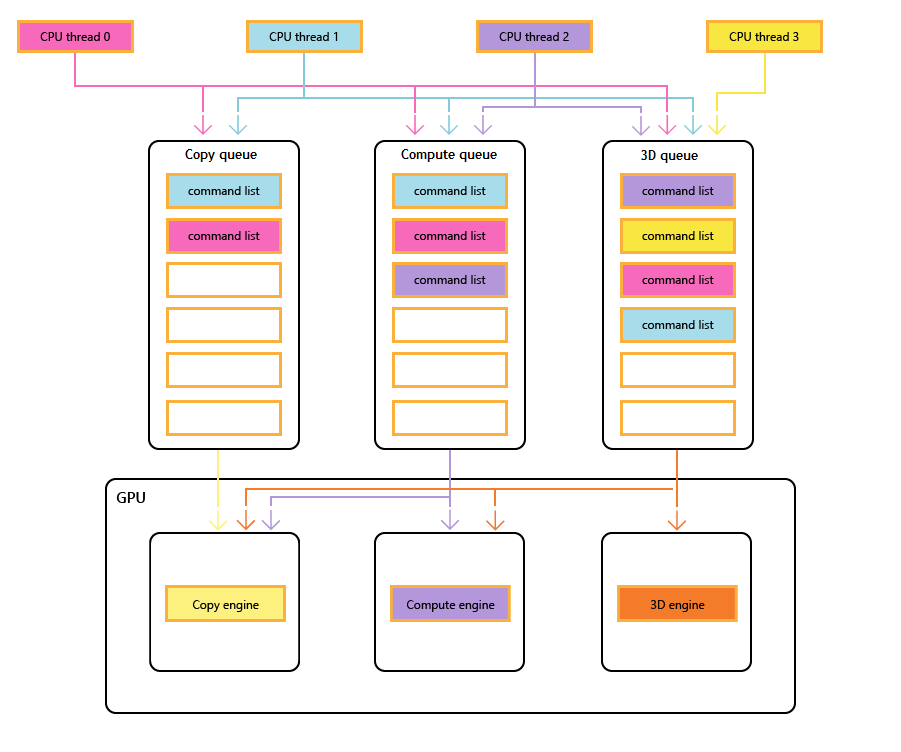
次の図は、必要に応じてエンジン間同期を含め、タイトルが複数の GPU エンジン間で作業をスケジュールする方法を示しています。エンジン間の依存関係を持つエンジンごとのワークロードを示しています。 この例では、コピー エンジンは最初にレンダリングに必要なジオメトリをコピーします。 3D エンジンは、これらのコピーが完了するまで待機し、ジオメトリに対する事前パスをレンダリングします。 その後、これはコンピューティング エンジンによって使用されます。 ディスパッチコンピューティング エンジンの結果は、コピー エンジンに対するいくつかのテクスチャ コピー操作と共に、最終的な Draw 呼び出しのために 3D エンジンによって使用されます。
次の擬似コードは、タイトルがこのようなワークロードを送信する方法を示しています。
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
次の擬似コードは、リング バッファーを介してヒープのようなメモリ割り当てを実現するために、コピー エンジンと 3D エンジンの間の同期を示しています。 タイトルには、並列処理の最大化 (大きなバッファー経由) とメモリ消費量と待機時間の削減 (小さなバッファー経由) の間で適切なバランスを選択できる柔軟性があります。
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
マルチエンジンのシナリオ
Direct3D 12 を使用すると、予期しない同期の遅延が原因で誤って非効率性に陥らないようにすることができます。 また、必要な同期をより確実に決定できる、より高いレベルで同期を導入することもできます。 マルチエンジンが対処する 2 つ目の問題は、コストの高い操作をより明示的にすることです。これには、複数のカーネル コンテキスト間の同期のために従来コストが高かった 3D とビデオの間の遷移が含まれます。
特に、Direct3D 12 では次のシナリオに対処できます。
- 非同期で優先順位の低い GPU 作業。 これにより、優先順位の低い GPU 作業とアトミック操作を同時に実行できます。これにより、1 つの GPU スレッドが、ブロックせずに別の同期されていないスレッドの結果を使用できるようになります。
- 優先度の高いコンピューティング作業。 バックグラウンド コンピューティングを使用すると、3D レンダリングを中断して、少量の優先度の高いコンピューティング作業を行うことができます。 この作業の結果は、CPU での追加処理のために早期に取得できます。
- バックグラウンド コンピューティング作業。 コンピューティング ワークロード用に優先順位の低い個別のキューを使用すると、アプリケーションは予備の GPU サイクルを利用して、プライマリ レンダリング (またはその他) のタスクに悪影響を与えることなくバックグラウンド計算を実行できます。 バックグラウンド タスクには、リソースの展開やシミュレーションやアクセラレーション構造の更新が含まれる場合があります。 バックグラウンド タスクは、フォアグラウンド作業のストールや低速化を回避するために、CPU 上で頻繁に (フレームあたり約 1 回) 同期する必要があります。
- データのストリーミングとアップロード。 最初のデータとリソースの更新の D3D11 の概念は、別のコピー キューによって置き換えられます。 アプリケーションは Direct3D 12 モデルの詳細を担当しますが、この責任にはパワーが伴います。 アプリケーションは、アップロード データのバッファリングに費やされるシステム メモリの量を制御できます。 アプリは、同期するタイミングと方法 (CPU と GPU、ブロックと非ブロック) を選択でき、進行状況を追跡し、キューに登録された作業の量を制御できます。
- 並列処理の増加。 アプリケーションは、フォアグラウンド作業用に個別のキューがある場合に、バックグラウンド ワークロード (ビデオ デコードなど) に深いキューを使用できます。
Direct3D 12 では、コマンド キューの概念は、アプリケーションによって送信されたほぼシリアルな作業シーケンスの API 表現です。 バリアやその他の手法を使用すると、この作業をパイプラインで実行することも、順序を外して実行することもできますが、アプリケーションには完了タイムラインが 1 つだけ表示されます。 これは、D3D11 の即時コンテキストに対応します。
同期 API
デバイスとキュー
Direct3D 12 デバイスには、さまざまな種類と優先順位のコマンド キューを作成および取得するメソッドがあります。 ほとんどのアプリケーションでは、既定のコマンド キューを使用する必要があります。これは、他のコンポーネントによる共有使用が許可されるためです。 追加のコンカレンシー要件を持つアプリケーションでは、追加のキューを作成できます。 キューは、使用するコマンド リストの種類によって指定されます。
ID3D12Deviceの次の作成方法を参照してください。
- CreateCommandQueue: Direct3D 12_COMMAND_QUEUE_DESC構造体の情報に基づいてコマンド キューを作成します。
- CreateCommandList: Direct3D 12_COMMAND_LIST_TYPE種類のコマンド リストを作成します。
- CreateFence: Direct3D 12_FENCE_FLAGSのフラグ示すフェンスを作成します。 フェンスは、キューの同期に使用されます。
すべての種類 (3D、コンピューティング、コピー) のキューは同じインターフェイスを共有し、すべてコマンド リスト ベースです。
ID3D12CommandQueueの次のメソッドを参照してください。
- ExecuteCommandLists: 実行するコマンド リストの配列を送信します。 ID3D12CommandListによって定義されている各コマンド リスト。
- シグナル: キュー (GPU 上で実行中) が特定のポイントに達したときにフェンス値を設定します。
- 待機: キューは、指定したフェンスが指定した値に達するまで待機します。
バンドルはどのキューでも使用されないため、この種類を使用してキューを作成できないことに注意してください。
フェンス
マルチエンジン API には、フェンスを使用して作成および同期するための明示的な API が用意されています。 フェンスは、UINT64 値によって制御される同期コンストラクトです。 フェンスの値は、アプリケーションによって設定されます。 シグナル操作では、フェンスの値が変更され、フェンスが要求された値以上に達するまで待機操作がブロックされます。 フェンスが特定の値に達すると、イベントが発生する可能性があります。
ID3D12Fence インターフェイスのメソッドを参照してください。
- GetCompletedValue: フェンスの現在の値を返します。
- SetEventOnCompletion: フェンスが指定された値に達するとイベントが発生します。
- 信号: フェンスを指定された値に設定します。
フェンスを使用すると、現在のフェンス値への CPU アクセスと、CPU の待機とシグナルが許可されます。
ID3D12Fence インターフェイスの Signal メソッドは、CPU 側からフェンスを更新します。 この更新は直ちに行われます。 ID3D12CommandQueue の Signal メソッドは、GPU 側からフェンスを更新します。 この更新は、コマンド キューに対する他のすべての操作が完了した後に発生します。
マルチエンジン セットアップ内のすべてのノードは、適切な値に達したフェンスを読み取って対応できます。
アプリケーションは独自のフェンス値を設定します。適切な開始点は、フレームごとに 1 回フェンスを増やすことです。
フェンス 巻き戻される場合があります。 つまり、フェンス値だけをインクリメントする必要はありません。 Signal 操作が 2 つの異なるコマンド キューにエンキューされている場合、または 2 つの CPU スレッドが両方ともフェンスで Signal を呼び出している場合は、最後に完了した Signal を判断する競合が発生する可能性があるため、どのフェンス値が残っているかを判断できます。 フェンスが巻き戻された場合、新しい待機 (setEventOnCompletion 要求 を含む) は新しい低いフェンス値と比較されるため、フェンス値が満たすのに十分な高さであったとしても、満たされない可能性があります。 未処理の待機を満たす値と満たされない値の間で競合が発生した場合、待機 は、後に残っている値に関係なく満た。
フェンス API は強力な同期機能を提供しますが、問題のデバッグが困難な可能性があります。 各フェンスは、信号機間の競合を防ぐために、1 つのタイムラインでの進行状況を示すためにのみ使用することをお勧めします。
コマンド リストのコピーと計算
3 種類のコマンド リストはすべて ID3D12GraphicsCommandList インターフェイスを使用しますが、コピーとコンピューティングでは、メソッドのサブセットのみがサポートされています。
コマンド リストのコピーと計算には、次のメソッドを使用できます。
- 閉じる
- CopyBufferRegion
- CopyResourceの
- CopyTextureRegion
- CopyTiles
- リセット
- ResourceBarrier
コンピューティング コマンド リストでは、次のメソッドを使用することもできます。
- ClearStateの
- ClearUnorderedAccessViewFloatの
- ClearUnorderedAccessViewUintの
- DiscardResourceの
- ディスパッチ
- ExecuteIndirectをする
- SetComputeRoot32BitConstantの
- SetComputeRoot32BitConstantsの
- SetComputeRootConstantBufferViewの
- SetComputeRootDescriptorTableの
- SetComputeRootShaderResourceViewの
- SetComputeRootSignatureの
- SetComputeRootUnorderedAccessViewの
- SetDescriptorHeaps
- SetPipelineStateの
- SetPredicationの
- EndQueryの
SetPipelineStateを呼び出すときは、コンピューティング コマンド リストコンピューティング PSO を設定する必要があります。
バンドルは、コマンド リストまたはキューのコンピューティングやコピーでは使用できません。
パイプラインコンピューティングとグラフィックスの例
この例では、フェンス同期を使用して、キューでグラフィックス処理によって使用される (pComputeQueueによって参照される) キューにコンピューティング処理のパイプラインを作成する方法を示 pGraphicsQueue。 コンピューティングとグラフィックスの作業は、複数のフレームから計算処理の結果を消費するグラフィックス キューと共にパイプライン化され、CPU イベントを使用して、キューに登録された全体的な作業の合計を調整します。
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
このパイプライン処理をサポートするには、コンピューティング キューからグラフィックス キュー ComputeGraphicsLatency+1 渡されるデータの異なるコピーのバッファーが存在する必要があります。 コマンド リストでは、バッファー内のデータの適切な "バージョン" から読み取りと書き込みを行うには、UAV と間接参照を使用する必要があります。 計算キューは、フレーム N+ComputeGraphicsLatencyを書き込む前に、グラフィックス キューがフレーム N のデータからの読み取りを完了するまで待機する必要があります。
CPU に対して処理されるコンピューティング キューの量は、必要なバッファリングの量に直接依存しないことに注意してください。ただし、使用可能なバッファー領域の量を超える GPU 処理をキューに入れた場合の価値は低くなります。
間接参照を回避する別のメカニズムとして、"名前が変更された" 各バージョンのデータに対応する複数のコマンド リストを作成する方法があります。 次の例では、前の例を拡張しながらこの手法を使用して、コンピューティング キューとグラフィックス キューをより非同期的に実行できるようにします。
非同期コンピューティングとグラフィックスの例
次の例では、グラフィックスをコンピューティング キューから非同期にレンダリングできます。 2 つのステージの間には、まだ一定量のバッファーデータがありますが、グラフィックス処理は独立して進行し、グラフィックス作業がキューに置かれたときに CPU で知られているコンピューティング ステージの最も up-to日付の結果を使用します。 これは、ユーザー入力などの別のソースによってグラフィックス作業が更新されている場合に便利です。 グラフィックスの ComputeGraphicsLatency フレームを一度に稼働させるには、複数のコマンド リストが必要です。また、UpdateGraphicsCommandList 関数は、最新の入力データを含むようにコマンド リストを更新し、適切なバッファーからコンピューティング データから読み取ることを表します。
コンピューティング キューは引き続きグラフィックス キューがパイプ バッファーで終了するまで待機する必要がありますが、グラフィックス読み取りのコンピューティング処理の進行状況と一般的なグラフィックスの進行状況を追跡できるように、3 番目のフェンス (pGraphicsComputeFence) が導入されます。 これは、連続するグラフィックス フレームが同じコンピューティング結果から読み取られたり、計算結果をスキップしたりする可能性があるという事実を反映しています。 より効率的だが少し複雑な設計では、単一のグラフィックス フェンスのみを使用し、各グラフィックス フレームで使用されるコンピューティング フレームへのマッピングを格納します。
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
マルチキュー リソース アクセス
複数のキュー上のリソースにアクセスするには、アプリケーションが次の規則に従う必要があります。
リソース アクセス (Direct3D 12_RESOURCE_STATES参照) は、キュー オブジェクトではなくキューの種類クラスによって決定されます。 キューには 2 種類のクラスがあります。Compute/3D キューは 1 つの型クラスで、Copy は 2 番目の型クラスです。 そのため、1 つの 3D キューのNON_PIXEL_SHADER_RESOURCE状態に対する障壁を持つリソースは、ほとんどの書き込みをシリアル化する必要がある同期要件に従って、任意の 3D またはコンピューティング キューでその状態で使用できます。 2 つの型クラス (COPY_SOURCE と COPY_DEST) 間で共有されるリソースの状態は、型クラスごとに異なる状態と見なされます。 そのため、リソースがコピー キュー上のCOPY_DESTに移行する場合、3D またはコンピューティング キューからコピー先としてアクセスすることはできません。その逆も同様です。
まとめるとします。
- キュー "object" は任意の単一キューです。
- キュー "type" は、Compute、3D、Copy の 3 つのいずれかです。
- キューの "型クラス" は、Compute/3D と Copy の 2 つのいずれかです。
初期状態として使用される COPY フラグ (COPY_DESTおよびCOPY_SOURCE) は、3D/Compute 型クラスの状態を表します。 コピー キューで最初にリソースを使用するには、COMMON 状態で開始する必要があります。 COMMON 状態は、暗黙的な状態遷移を使用して、コピー キューのすべての使用法に使用できます。
リソースの状態はすべてのコンピューティング キューと 3D キューで共有されますが、異なるキューで同時にリソースに書き込むことは許可されていません。 ここで "同時に" とは、同期されていないことを意味します。一部のハードウェアでは、同期されていない実行は不可能です。 次の規則が適用されます。
- 一度に 1 つのリソースに書き込むことができるキューは 1 つだけです。
- ライターによって変更されたバイトを読み取らない限り、複数のキューがリソースから読み取ることができます (同時に書き込まれるバイトを読み取ると未定義の結果が生成されます)。
- 別のキューが書き込まれたバイトを読み取ったり、書き込みアクセスを行ったりするには、フェンスを使用して書き込み後に同期する必要があります。
表示されるバック バッファーは、Direct3D 12_RESOURCE_STATE_COMMON状態である必要があります。
関連トピック
リソース バリアを使用して Direct3D 12 でリソースの状態を同期する
Direct3D 12 でのメモリ管理の