Direct3D 11 から Direct3D 12 への移植
このセクションでは、カスタム Direct3D 11 グラフィックス エンジンから Direct3D 12 への移植に関するガイダンスをいくつか提供します。
- デバイスの作成
- コミット済みリソース
- 予約済みリソース
- データのアップロード
- シェーダーとシェーダー オブジェクト
- GPU への処理の送信
- CPU または GPU の同期
- リソース バインド
- リソースの状態
- スワップチェーン
- 固定関数のレンダリング
- その他
- 関連トピック
デバイスの作成
Direct3D 11 と Direct3D 12 の両方で、同様のデバイス作成パターンが共有されます。 既存の Direct3D 12 ドライバーはすべて D3D_FEATURE_LEVEL_11_0 以上であるため、以前の機能レベルと関連する制限を無視できます。
また、Direct3D 12 では、DXGI インターフェイスを使用してデバイス情報を明示的に列挙する必要があることに注意してください。 Direct3D 11 では、Direct3D デバイスから DXGI デバイスに戻できます。これは Direct3D 12 ではサポートされていません。
Direct3D 12 で WARP ソフトウェア デバイスを作成するには、 IDXGIFactory4::EnumWarpAdapter から取得した明示的なアダプターを指定します。 Direct3D 12 の WARP デバイスは、 Graphics Tools オプション機能が有効になっているシステムでのみ使用できます。
Note
D3D11CreateDeviceAndSwapChainに相当するものはありません。 Direct3D 11 の場合でも、デバイスとスワップチェーンを個別の手順で作成する方が良い場合が多いため、この関数の使用はお勧めしません。
コミット済みリソース
Direct3D 11 で次のインターフェイスを使用して作成されたオブジェクトは、Direct3D 12 では "コミット済みリソース" と呼ばれるものに変換されます。 コミット済みリソースとは、仮想アドレス空間とそれに関連付けられた物理ページの両方を持つリソースです。 これは、Direct3D 12 の基になっている Microsoft Windows デバイス ドライバー 2 (WDD2) メモリ モデルの概念です。
Direct3D 11 のリソース:
- ID3D11Resource
- ID3D11Buffer および ID3D11Device::CreateBuffer
- ID3D11Texture1D および ID3D11Device:CreateTexture1D
- ID3D11Texture2D および ID3D11Device::CreateTexture2D
- ID3D11Texture3D および ID3D11Device::CreateTexture3D
Direct3D 12 では、これらはすべて、ID3D12Resource と ID3D12Device::CreateCommittedResource で表されます。
予約済みリソース
予約済みリソースは、仮想アドレス空間のみが割り当てられているリソースです。物理メモリは、ID3D12Device::CreateHeap の呼び出しがあるまで割り当てられません。 これは、基本的に、Direct3D 11 のタイル リソースと同じ概念です。
Direct3D 11 でタイル 化されたリソースを設定するために使用されるフラグ (D3D11_RESOURCE_MISC_FLAG) を物理メモリにマップします。
- D3D11_RESOURCE_MISC_TILED
- D3D11_RESOURCE_MISC_TILE_POOL
データのアップロード
Direct3D 11 では、1 つのタイムラインの外観があります ( D3D11_SUBRESOURCE_DATA で初期化されたデータなどのシーケンスの後の呼び出し、 ID3D11DeviceContext::UpdateSubresource への呼び出し、 ID3D11DeviceContext::Map の呼び出しが行われます)。 Direct3D 11 開発者にとっては、作成されるデータのコピーの数は明白ではありません。
Direct3D 12 には、(マップ可能なメモリからの CopyTextureRegion および CopyBufferRegion の呼び出しによって設定される) GPU タイムラインと (Map の呼び出しによって決定される) CPU タイムラインという 2 つのタイムラインがあります。 共有タイムラインを使用する Updatesubresources というヘルパー関数が (d3dx12.h ファイルで) 提供されています。 このヘルパー関数にはいくつかのバリエーションがあり、ID3D12Device::GetCopyableFootprints を使用するもの、ヒープ割り当てメカニズムを使用するもの、スタック割り当てメカニズムを使用するものがあります。 これらのヘルパー関数は、メモリの中間ステージング領域を介して、GPU と CPU の両方にリソースをコピーします。
通常、GPU と CPU はそれぞれ、独自のタイムラインに関連付けられたリソースの独自のコピーを保持します。 共有タイムラインのアプローチでも、同様に 2 つのコピーが保持されます。
シェーダーとシェーダー オブジェクト
Direct3D 11 では、ID3D11Device 作成メソッドと ID3D11DeviceContext 設定メソッドを使用した、シェーダーおよび状態オブジェクトの作成とこれらのオブジェクトの状態の設定が多数あります。 通常、これらのメソッドに対して大量の呼び出しが行われます。その後、これらは描画時にドライバーによって結合され、適切なパイプライン状態が設定されます。
Direct3D 12 では、このパイプライン状態の設定は、単一のオブジェクト (コンピューティング エンジンの場合は CreateComputePipelineState、グラフィックス エンジンの場合は CreateGraphicsPipelineState) に結合されました。これは、描画呼び出しの前に SetPipelineState の呼び出しでコマンド リストにアタッチされます。
これらの呼び出しは、Direct3D 11 でシェーダー、入力レイアウト、ブレンド状態、ラスタライザーの状態、深度ステンシルの状態などを設定するための個々の呼び出しをすべて置き換えます
- デバイス 11 の方法:
CreateInputLayout、CreateXShader、CreateDepthStencilState、およびCreateRasterizerState。 - デバイス コンテキスト 11 のメソッド:
IASetInputLayout、xxSetShader、OMSetBlendState、OMSetDepthStencilState、およびRSSetState。
Direct3D 12 では以前のコンパイル済みシェーダー BLOB をサポートできますが、シェーダーは FXC/D3DCompile API でシェーダー モデル 5.1 を使用するか、DXIL DXC コンパイラを使用してシェーダー モデル 6 を使用してビルドする必要があります。 シェーダー モデル 6 のサポートは、 CheckFeatureSupport および D3D12_FEATURE_SHADER_MODELで検証する必要があります。
GPU への処理の送信
Direct3D 11 では、実際のところ、どのように処理が送信されるかについてはほとんど制御できません。ID3D11DeviceContext::Flush および IDXGISwapChain1::Present1 の呼び出しによって一部の制御は有効になりますが、大部分はドライバーによって処理されます。
Direct3D 12 では、処理の送信は非常に明示的で、アプリによって制御されます。 処理を送信するための主な構成要素は ID3D12GraphicsCommandList で、これはすべてのアプリ コマンドを記録するために使用されます (そして ID3D11 の遅延コンテキストと概念がよく似ています)。 コマンド リスト用のバッキング ストアは、ID3D12CommandAllocator によって提供されます。これにより、Direct3D 12 ドライバーがコマンド リストの格納に使用する予定のメモリを実際に公開することで、アプリはコマンド リストのメモリ使用率を管理できるようになります。
最後に、ID3D12CommandQueue は先入れ先出しキューで、GPU に送信するコマンド リストの適切な順序を格納します。 GPU で 1 つのコマンド リストが実行が完了したときにのみ、ドライバーによってキューから次のコマンド リストが送信されます。
Direct3D 11 では、コマンド キューの明示的な概念はありません。 Direct3D 12 の一般的なセットアップでは、現在のフレームの現在開いている D3D12_COMMAND_LIST_TYPE_DIRECT コマンド リストは、Direct3D 11 の即時コンテキストに似ています。 これにより、同じ関数の多くが提供されます。
| D3D11DeviceContext | ID3D12GraphicsCommand List |
|---|---|
| ClearDepthStencilView | ClearDepthStencilView |
| ClearRenderTargetView | ClearRenderTargetView |
| ClearUnorderedAccess* | ClearUnorderedAccess* |
| Draw、DrawInstanced | DrawInstanced |
| DrawIndexed、DrawIndexedInstanced | DrawIndexedInstanced |
| 出荷 | 出荷 |
| IASetInputLayout、xxSetShader など | SetPipelineState |
| OMSetBlendState | OMSetBlendFactor |
| OMSetDepthStencilState | OMSetStencilRef |
| OMSetRenderTargets | OMSetRenderTargets |
| RSSetViewports | RSSetViewports |
| RSSetScissorRects | RSSetScissorRects |
| IASetPrimitiveTopology | IASetPrimitiveTopology |
| IASetVertexBuffers | IASetVertexBuffers |
| IASetIndexBuffer | IASetIndexBuffer |
| ResolveSubresource | ResolveSubresource |
| CopySubresourceRegion | CopyBufferRegion |
| UpdateSubresource | CopyTextureRegion |
| CopyResource | CopyResource |
Note
D3D12_COMMAND_LIST_TYPE_BUNDLEで作成されたコマンド リストは、遅延コンテキストと同じになります。 Direct3D 12 では、immediate コンテキストの一部の機能にアクセスする機能もサポートD3D12_COMMAND_LIST_TYPE_COPYおよびD3D12_COMMAND_LIST_TYPE_COMPUTEコマンド リストの種類を介したレンダリングと同時に実行できます。
CPU または GPU の同期
Direct3D 11 では、CPU または GPU の同期はほぼ自動で行われ、アプリが物理メモリの状態を管理する必要はありませんでした。
Direct3D 12 では、アプリが 2 つのタイムライン (CPU と GPU) を明示的に管理する必要があります。 そのためには、GPU が必要とするリソースとその期間についての情報をアプリが管理する必要があります。 これはまた、GPU がリソースの使用を終了するまでリソース (コミット済みリソース、ヒープ、コマンド アロケーターなど) の内容が変更されないことをアプリが保証する責任があることも意味します。
タイムラインを同期するための主要なオブジェクトは、ID3D12Fence オブジェクトです。 フェンスの操作はかなり簡単で、GPU がタスクを完了したときに通知できるようにします。 GPU と CPU はどちらもシグナルを送信することができ、どちらもフェンスを待機することができます。
通常のアプローチでは、実行のためにコマンド リストを送信すると、完了時 (GPU によるデータの読み取りが完了したとき) にフェンス シグナルが GPU によって送信され、CPU がそのリソースを再利用または破棄できるようになります。
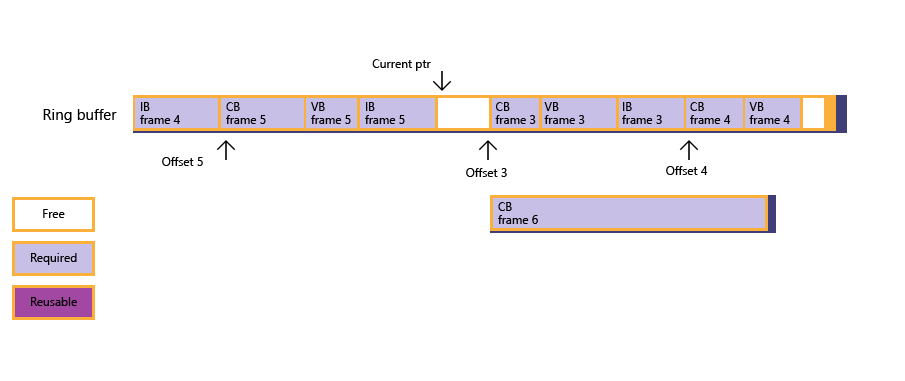
Direct3D 11 では、 ID3D11DeviceContext::Map フラグD3D11_MAP_WRITE_DISCARD基本的に各リソースは、アプリが書き込むことができるメモリの無限の供給として扱われます ("名前の変更" と呼ばれるプロセス)。 Direct3D 12 では、このプロセスはやはり明示的です。追加のメモリを割り当てる必要があり、フェンスを使用して操作を同期する必要があります。 (大きなバッファーで構成される) リング バッファーは、これに適した手法である可能性があります。「フェンス ベースのリソース管理」のリング バッファーのシナリオを参照してください。
リソース バインド
Direct3D 11 のビュー (シェーダー リソース ビュー、レンダー ターゲット ビューなど) の大部分は、Direct3D 12 において記述子の概念に置き換えられました。 作成メソッドは Direct3D 12 にも存在します (CreateShaderResourceView、CreateRenderTargetView など)。これらは、記述子ヒープが作成された後、データをヒープに書き込むために呼び出されます。 Direct3D 12 でのバインドは、ルート署名で記述された記述子ハンドルによって処理され、SetGraphicsRootDescriptorTable または SetComputeRootDescriptorTable メソッドを使用して送信されます。
ルート署名は、ルート署名スロット番号と記述子テーブル間のマッピングを詳細に記述します。この場合、記述子テーブルには、頂点シェーダー、ピクセル シェーダー、およびその他のシェーダー (定数バッファー、シェーダー リソース ビュー、サンプラーなど) が使用できるリソースへの参照を含めることができます。 この柔軟性により、Direct3D 12 では HLSL レジスタ空間と API バインド空間が切り離されます。これは、これらの空間の間に 1 対 1 のマッピングがある Direct3D 11 と異なる点です。
このシステムの裏に隠された意味の 1 つとして、アプリには記述子テーブルの名前を変更する役割があります。これにより、開発者は、描画呼び出しごとに記述子を 1 つであっても変更するパフォーマンス コストを理解できます。
Direct3D 12 の新機能として、どの記述子をどのシェーダー ステージ間で共有するかをアプリが制御できます。 Direct3D 11 では、UAV などのリソースは、すべてのシェーダー ステージの間で共有されます。 特定のシェーダー ステージに対して記述子を無効にできるようにすることで、無効にされた記述子によって使用されていたレジスタを、特定のシェーダー ステージに対して有効になっている記述子で使用できるようになります。
次の表にルート署名の例を示します。
| ルート パラメーター スロット | 記述子テーブル エントリ |
|---|---|
| 0 | VS 記述子範囲 b0 から b13 |
| 1 | VS 記述子範囲 t0 から t127 |
| 2 | VS 記述子範囲 s0 から s16 |
| 3 | PS 記述子範囲 b0 から b13 |
| ... | |
| 14 | DS 記述子範囲 s0 から 16 |
| 15 | 共有記述子範囲 u0 から u63 |
リソースの状態
Direct3D 11 では、リソースの状態は、アプリではなくドライバーによって管理されます。
Direct3D 12 では、リソースの状態管理はアプリの役割となり、コマンド リストの記録の完全な並列処理を可能にします。その結果、アプリは、コマンド リストの (並列実行可能な) 記録タイムラインと、(順次処理である必要がある) 実行タイムラインを処理する必要があります。
リソースの状態遷移は、ResourceBarrier メソッドによって処理されます。 このアプリは、本来、リソースの使用状況が変更されたときにドライバーに通知する必要があります。 たとえば、レンダー ターゲットとして使用されているリソースが次の描画呼び出し時に頂点シェーダーへの入力として使用される場合、頂点シェーダーを処理する前にレンダー ターゲット操作を完了するために、GPU 操作の短い停止が必要になる場合があります。
このシステムにより、グラフィックス パイプラインのきめ細かな同期 (GPU 停止) に加え、キャッシュのフラッシュ、そして場合によってはメモリ レイアウトの変更 (レンダー ターゲット ビューから深度ステンシル ビューへの圧縮解除など) が可能になります。
これは、"遷移バリア" と呼ばれます。 他の種類のバリアもあります。Direct3D 11 の ID3D11DeviceContext2::TiledResourceBarrier では、同じ物理メモリを 2 つの異なるタイル リソースで使用することが可能になりました。 Direct3D 12 では、これは "エイリアシング バリア" と呼ばれます。 エイリアシング バリアは、Direct3D 12 のタイル リソースと配置済みリソースの両方に使用できます。 さらに、UAV バリアがあります。 Direct3D 11 では、UAV のすべてのディスパッチ操作と描画操作は、これらの操作をパイプライン化または並列化できる場合でも、シリアル化する必要があります。 Direct3D 12 では、UAV バリアを追加することでこの制限が解除されています。 UAV バリアにより、UAV 操作が順次実行されるようになるため、2 番目の操作で最初の操作の完了が求められる場合は、このバリアの追加することによって 2 番目の操作を強制的に待機するようになります。 UAV の既定値の動作は、できる限り早く処理を進行させるという単純なものです。
ワークロードを並列化できる場合は、明らかにパフォーマンスが向上します。
スワップチェーン
Direct3D 11 と 12 の両方のスワップ チェーンの基礎として、DXGI スワップ チェーンがあります。 Direct3D 11 には、シーケンシャル、DISCARD、FLIP_SEQUENTIALの 3 種類のスワップ チェーンがあります。 Direct3D 12 には、FLIP_SEQUENTIALとFLIP_DISCARDの 2 種類があります。 前述のように、 IDXGIFactory4 以降を使用してスワップチェーンを明示的に作成し、任意のアダプター列挙に同じインターフェイスを使用する必要があります。
Direct3D 11 には、バック バッファーの自動ローテーションがあります。バック バッファー 0 に必要なレンダー ターゲット ビューは 1 つだけです。 Direct3D 12 では、バッファーのローテーションは明示的で、それぞれのバック バッファーに対してレンダー ターゲット ビューが必要です。 レンダリング先を選択するには、IDXGISwapChain3::GetCurrentBackBufferIndex メソッドを使用します。 繰り返しになりますが、この柔軟性の向上により、さらに大規模な並列化が可能になります。
Note
アプリケーションを設定する方法は多数ありますが、一般に、アプリケーションにはスワップ チェーン バッファーごとに 1 つの ID3D12CommandAllocator があります。 これにより、GPU が前のフレームをレンダリングしている間、アプリケーションは次のフレームのコマンド セットの構築に進むことができます。
固定関数のレンダリング
Direct3D 11 には、(完全なミップ チェーンを作成する) GenerateMips や (アプリからの追加の入力なしにストリーム出力をシェーダー入力として使用する) DrawAuto など、より高いレベルのさまざまな操作を単純化するメソッドがいくつかありました。 これらのメソッドは Direct3D 12 には用意されていません。このアプリでは、これらの操作を処理するために、それを実行するシェーダーを作成する必要があります。
その他
次の表は、Direct3D 11 と 12 の間で類似していながらも同じではない機能をいくつか示しています。
| Direct3D 11 | Direct3D 12 |
|---|---|
| ID3D11Query | ID3D12QueryHeap では、クエリをグループ化できるためコストを削減できます。 |
| ID3D11Predicate | 完全に透過的なバッファーにデータを格納することで、プレディケーションが可能になりました。 Direct3D 11 の ID3D11Predicate オブジェクトは ID3D12Resource::Map に置き換えられます。これは、ResolveQueryData の呼び出しおよびデータの準備が整うのを待つためのフェンスを使用した GPU 同期操作の後に実行する必要があります。 「プレディケーション」を参照してください。 |
| UAV/SO 非表示カウンター | アプリには、SO/UAV カウンターの割り当てと管理を行う役割があります。 「ストリーム出力カウンター」および「UAV カウンター」を参照してください。 |
| リソースの動的 MinLOD (最小詳細レベル) | これは、SRV 記述子の静的 MinLOD に移動されました。 |
| Draw*Indirect/DispatchIndirect | 描画間接メソッドはすべて、1 つの ExecuteIndirect メソッドに統合されました。 |
| DepthStencil 形式はインタリーブ形式です | DepthStencil 形式は平面形式です。 たとえば、深度 24 ビット、ステンシル 8 ビットの形式は、Direct3D 11 では 24/8/24/8... 形式で格納されますが、Direct3D 12 では 24/24/24 ... の後に 8/8/8... が続く形式になります。 D3D12 では各プレーンはそれ自身のサブリソースであることに注意してください (「Subresources (サブリソース)」を参照)。 |
| ResizeTilePool | 予約済みリソースを複数のヒープにマップすることができます。 D3D11 でタイル プールが拡張されるような状況において、D3D12 では代わりに追加のヒープを割り当てることができます。 |