フェンス ベースのリソース管理
フェンスを使用して GPU の進行状況を追跡することで、リソース データの有効期間を管理する方法について説明します。 メモリは、メモリ内 (アップロード ヒープ用のリング バッファーの実装など) の空き領域の使用可能性を慎重に管理するフェンスを使って効率的に再利用できます。
リング バッファーのシナリオ
以下は、アプリでアップロード ヒープ メモリに関するめったにない需要が発生した例です。
リング バッファーは、アップロード ヒープを管理する方法の 1 つです。 リング バッファーは、次のいくつかのフレームに必要なデータを保持します。 アプリは、現在のデータ入力ポインター、各フレームを記録するフレーム オフセット キュー、およびそのフレームのリソース データの開始オフセットを保持します。
アプリは、フレームごとに GPU にデータをアップロードするために、バッファーに基づいてリング バッファーを作成します。 現在、フレーム 2 がレンダリング済みで、リング バッファーはフレーム 4 のデータをラップし、フレーム 5 に必要なすべてのデータが用意されています。フレーム 6 に必要な大きな定数バッファーをサブ割り当てする必要があります。
図 1: アプリが定数バッファーのサブ割り当てを行おうとしますが、十分な空きメモリが見つかりません。
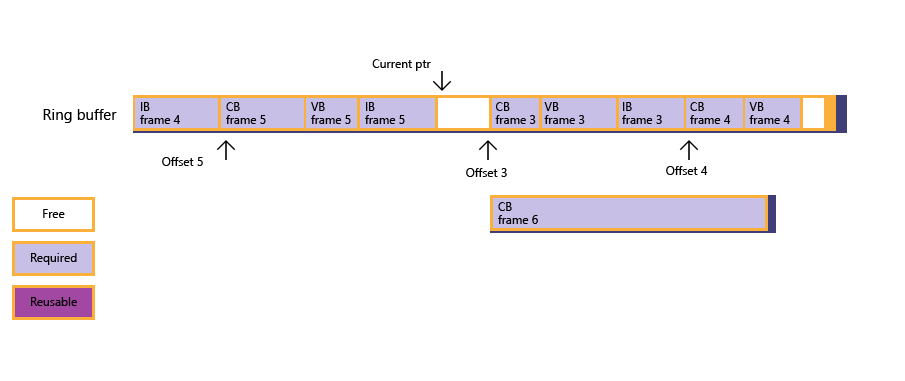
図 2: アプリは、フェンス ポーリングを通じて、フレーム 3 がレンダリング済みであることを検出します。その後、フレーム オフセット キューが更新され、リング バッファーの現在の状態が続けて更新されます。ただし、空きメモリは、依然として定数バッファーに対応できるほど大きくはありません。
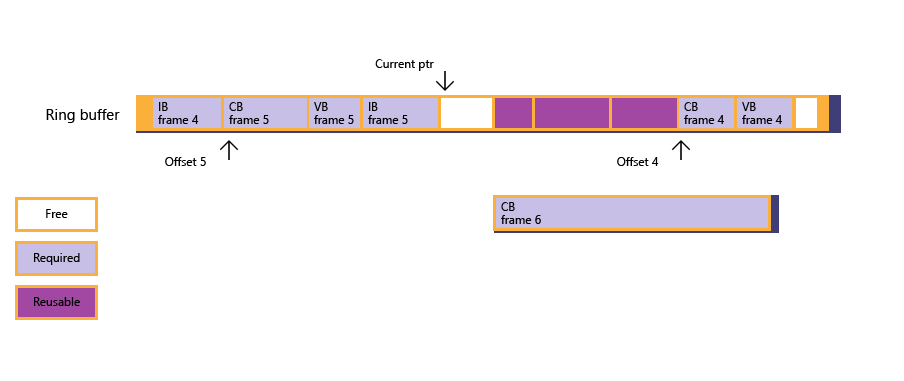
図 3: この状況で、フレーム 4 がレンダリングされるまで CPU は (フェンス待機を通じて) それ自体をブロックします。これにより、フレーム 4 に対してサブ割り当てされていたメモリが解放されます。
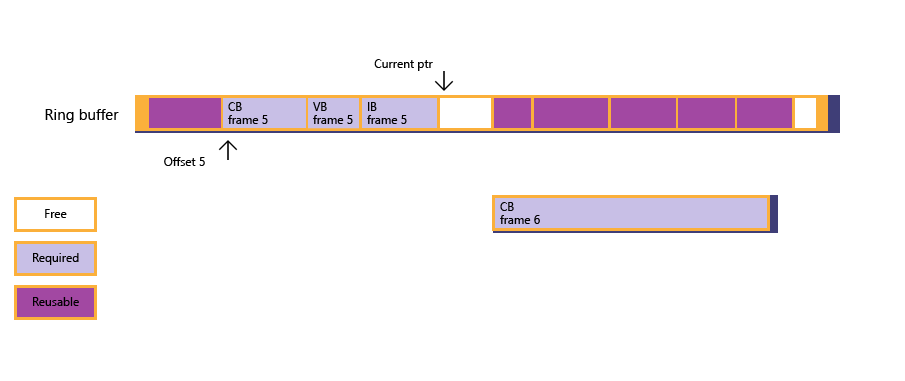
図 4: この時点で、定数バッファー用として空きメモリは十分な大きさになり、サブ割り当てが成功します。アプリは、フレーム 3 と 4 の両方のリソース データで以前使用されたメモリに、大きな定数バッファーのデータをコピーします。 現在の入力ポインターが最後に更新されます。
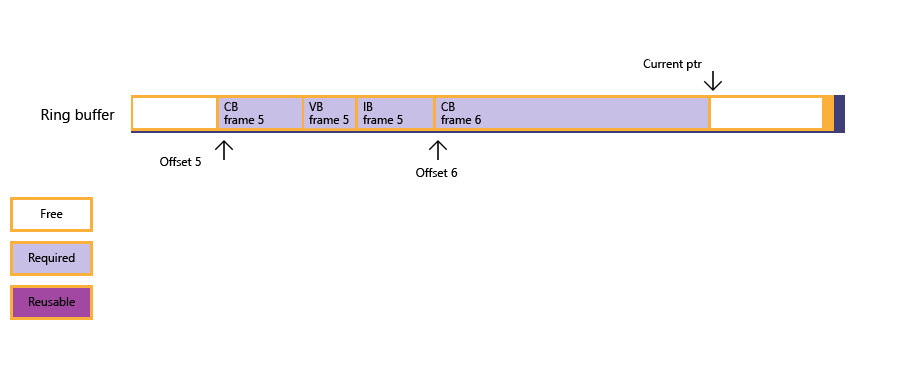
アプリでリング バッファーを実装する場合、リソース データのサイズが過度に大きい場合でも対処できるように、リング バッファーを十分大きくする必要があります。
リング バッファーのサンプル
次のサンプル コードで、フェンス ポーリングおよび待機を処理するサブ割り当てルーチンに注意しながら、リング バッファーをどのように管理できるかを示します。 わかりやすくするために、このサンプルでは NOT_SUFFICIENT_MEMORY を使用して、(FrameOffsetQueue 内のm_pDataCurとオフセットに基づく) ロジックがヒープまたはフェンスに密接に関連していないため、"ヒープに見つかった空きメモリが不足しています" の詳細を非表示にします。 このサンプルは単純化されており、そのため、メモリの使用率の代わりにフレーム レートが犠牲になっています。
リング バッファー サポートは、一般的なシナリオになることが予想されますが、ヒープ設計では、コマンド リストのパラメーター化や再使用など、その他の使用法は不可にはならないことにご注意ください。
struct FrameResourceOffset
{
UINT frameIndex;
UINT8* pResourceOffset;
};
std::queue<FrameResourceOffset> frameOffsetQueue;
void DrawFrame()
{
float vertices[] = ...;
UINT verticesOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
vertices, sizeof(float), sizeof(vertices) / sizeof(float),
4, // Max alignment requirement for vertex data is 4 bytes.
verticesOffset
));
float constants[] = ...;
UINT constantsOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
constants, sizeof(float), sizeof(constants) / sizeof(float),
D3D12_CONSTANT_BUFFER_DATA_PLACEMENT_ALIGNMENT,
constantsOffset
));
// Create vertex buffer views for the new binding model.
// Create constant buffer views for the new binding model.
// ...
commandQueue->Execute(commandList);
commandQueue->AdvanceFence();
}
HRESULT SuballocateFromHeap(SIZE_T uSize, UINT uAlign)
{
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Free up resources for frames processed by GPU; see Figure 2.
UINT lastCompletedFrame = commandQueue->GetLastCompletedFence();
FreeUpMemoryUntilFrame( lastCompletedFrame );
while ( NOT_SUFFICIENT_MEMORY(uSize, uAlign)
&& !frameOffsetQueue.empty() )
{
// Block until a new frame is processed by GPU, then free up more memory; see Figure 3.
UINT nextGPUFrame = frameOffsetQueue.front().frameIndex;
commandQueue->SetEventOnFenceCompletion(nextGPUFrame, hEvent);
WaitForSingleObject(hEvent, INFINITE);
FreeUpMemoryUntilFrame( nextGPUFrame );
}
}
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Apps need to create a new Heap that is large enough for this resource.
return E_HEAPNOTLARGEENOUGH;
}
else
{
// Update current data pointer for the new resource.
m_pDataCur = reinterpret_cast<UINT8*>(
Align(reinterpret_cast<SIZE_T>(m_pHDataCur), uAlign)
);
// Update frame offset queue if this is the first resource for a new frame; see Figure 4.
UINT currentFrame = commandQueue->GetCurrentFence();
if ( frameOffsetQueue.empty()
|| frameOffsetQueue.back().frameIndex < currentFrame )
{
FrameResourceOffset offset = {currentFrame, m_pDataCur};
frameOffsetQueue.push(offset);
}
return S_OK;
}
}
void FreeUpMemoryUntilFrame(UINT lastCompletedFrame)
{
while ( !frameOffsetQueue.empty()
&& frameOffsetQueue.first().frameIndex <= lastCompletedFrame )
{
frameOffsetQueue.pop();
}
}
関連トピック