WinMLRunner
WinMLRunner は、Windows ML API で評価された場合にモデルが正常に実行されるかどうかをテストするためのツールです。 GPU や CPU での評価時間とメモリ使用量をキャプチャすることもできます。 .onnx または .pb 形式のモデルは、入力変数と出力変数がテンソルまたは画像である場合に評価できます。 WinMLRunner を使用するには、次の 2 つの方法があります。
- コマンドライン用の Python ツール をダウンロードします。
- WinML ダッシュボード内で使用します。 詳細については、WinML ダッシュボードのドキュメントを参照してください。
モデルを実行する
まず、ダウンロードした Python ツールを開きます。 WinMLRunner.exe があるフォルダーに移動し、次のように実行可能ファイルを実行します。 インストール場所は、実際のものと一致する場所に必ず置き換えてください。
.\WinMLRunner.exe -model SqueezeNet.onnx
次のようなコマンドを使用して、モデルのフォルダーを実行することもできます。
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
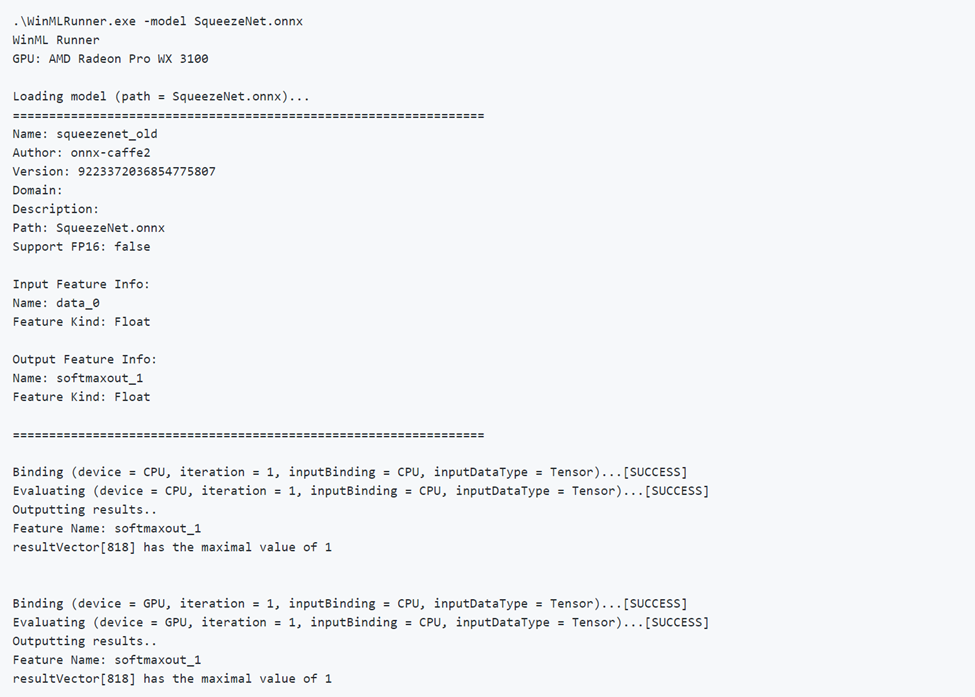
正しいモデルの実行
モデルを正常に実行する例を次に示します。 最初にモデルを読み込み、モデル メタデータが出力されていることに注意してください。 その後、モデルは CPU と GPU で個別に実行され、バインドの成功、評価の成功、モデルの出力が出力されます。
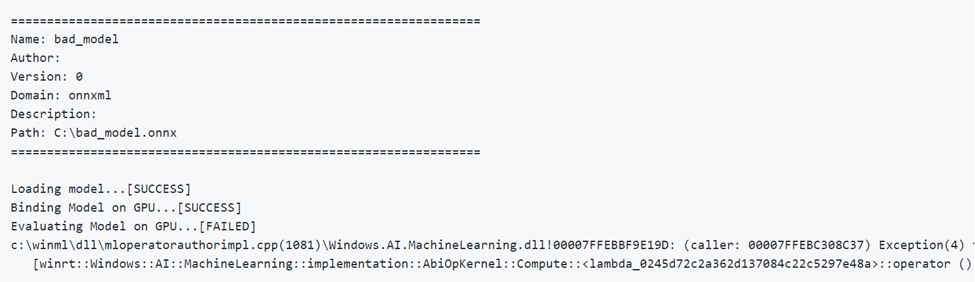
不正なモデルの実行
パラメーターが正しくないモデルを実行する例を次に示します。 GPU で評価する場合は、FAILED 出力に注意してください。
デバイスの選択と最適化
既定では、モデルは CPU と GPU で個別に実行されますが、-CPU または -GPU フラグによりデバイスを指定できます。 CPU のみを使用してモデルを 3 回実行する例を次に示します。
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
パフォーマンス データのログ出力
パフォーマンス データをキャプチャするには、-perf フラグを使用します。 CPU と GPU のデータ フォルダー内のすべてのモデルを 3 回個別に実行し、パフォーマンス データをキャプチャする例を次に示します。
WinMLRunner.exe -folder c:\data iterations 3 -perf
パフォーマンス測定値
次のパフォーマンス測定値は、読み込み、バインド、評価操作ごとに、コマンドラインと .csv ファイルに出力されます。
- 実時間 (ms): 操作の開始と終了の間のリアルタイムでの経過時間。
- GPU 時間 (ms): 操作が CPU から GPU に渡され、GPU で実行される時間 (注: Load() は GPU では実行されません)。
- CPU 時間 (ms): 操作が CPU で実行される時間。
- 専用および共有メモリ使用量 (MB): CPU または GPU での評価時のカーネルとユーザー レベルの平均メモリ使用量 (MB 単位)。
- ワーキング セット メモリ (MB): CPU 上のプロセスが評価時に必要な DRAM メモリの量。 専用メモリ (MB) - 専用 GPU の VRAM で使用されたメモリ容量。
- 共有メモリ (MB): GPU の DRAM で使用されたメモリ容量。
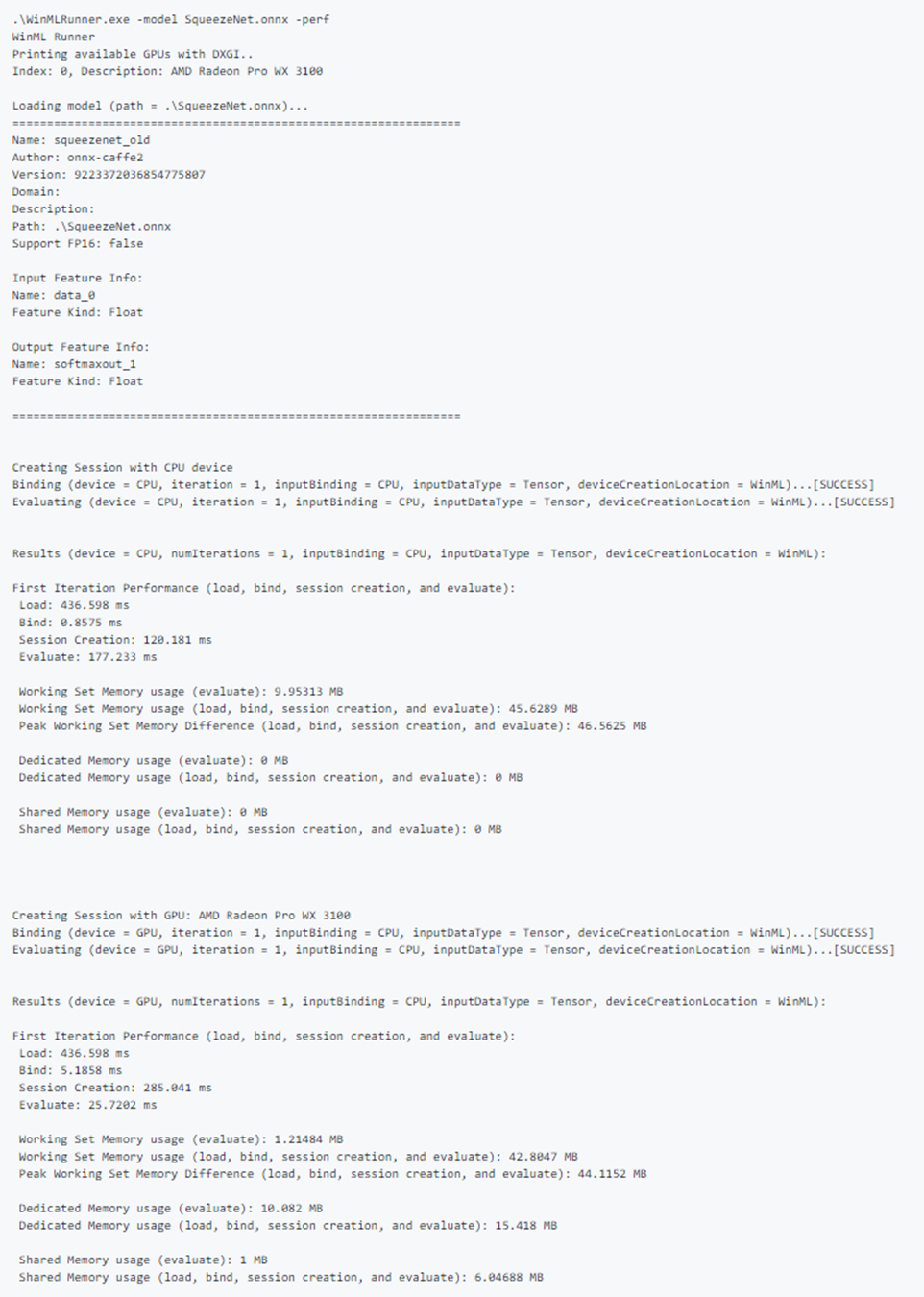
パフォーマンス出力のサンプル:
テストのサンプル入力
CPU と GPU で個別にモデルを実行し、入力を CPU と GPU に個別にバインドします (合計 4 回の実行)。
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
入力を GPU にバインドし、RGB 画像として読み込んだ状態で、モデルを CPU 上で実行します。
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
トレース ログのキャプチャ
ツールを使用してトレース ログをキャプチャする場合は、logman コマンドとデバッグ フラグを組み合わせて使用できます。
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
winmllog.etl ファイルは、WinMLRunner.exe と同じディレクトリに表示されます。
トレース ログの読み取り
traceprt.exe を使用して、コマンドラインから次のコマンドを実行します。
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
次に、logdump.csv ファイルを開きます。
または、(Visual Studio から) Windows Performance Analyzer を使用することもできます。 Windows Performance Analyzer を起動して winmllog.etl を開きます。
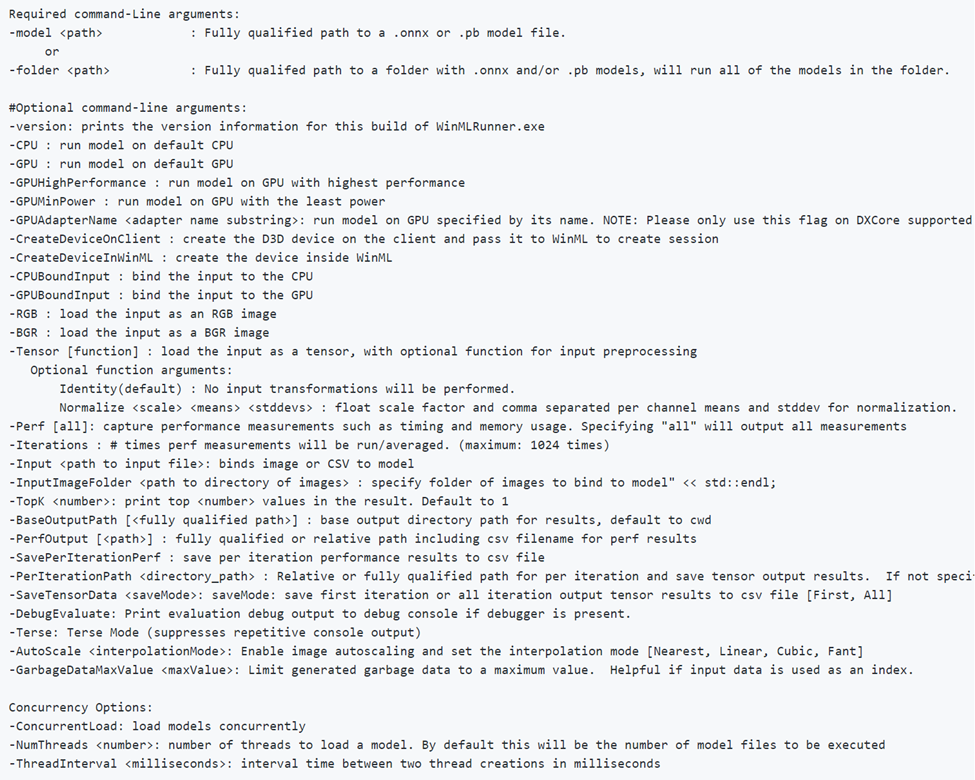
-CPU、-GPU、-GPUHighPerformance、-GPUMinPower、-BGR、-RGB、-tensor、-CPUBoundInput、-GPUBoundInput は相互に排他的ではないことに注意してください (つまり、異なる構成でモデルを実行するために必要な数を組み合わせることができます)。
動的 DLL の読み込み
WinMLRunner を別のバージョンの WinML で実行する場合 (古いバージョンとのパフォーマンスの比較や新しいバージョンのテストなど)、windows.ai.machinelearning.dll ファイルと directml.dll ファイルを WinMLRunner.exe と同じフォルダーに配置します。 WinMLRunner で、最初にこれらの DLL が検索され、見つからなかった場合は C:/Windows/System32 にフォールバックされます。
既知の問題
- シーケンスやマップの入力はまだサポートされていません (モデルはスキップされるだけなので、フォルダー内の他のモデルはブロックされません)。
- 実際のデータで -folder 引数を使用して複数のモデルを確実に実行することはできません。 入力は 1 つしか指定できないので、入力のサイズはほとんどのモデルと一致しません。 現在、-folder 引数の使用はガベージ データでのみ機能します。
- グレーまたは YUV でのガベージ入力の生成は現在サポートされていません。 理想的には、WinMLRunner のガベージ データ パイプラインは、winml に渡すことができるすべての入力タイプをサポートする必要があります。