適用対象: ✔️ Linux VM ✔️ Windows VM
この記事では、仮想マシン (VM) の監視と観察によるパフォーマンスの一般的なトラブルシューティングについて説明し、発生する可能性のある問題を修復します。 監視だけでなく、Perfinsights を使用することもできます。これにより、ベスト プラクティスのレコメンデーションと IO/CPU/メモリに関する主要なボトルネックを含むレポートが提供されます。 Perfinsights は、Azure の Windows と Linux VM の両方で使用できます。
この記事では、監視を使用してパフォーマンスのボトルネックを診断する手順について説明します。
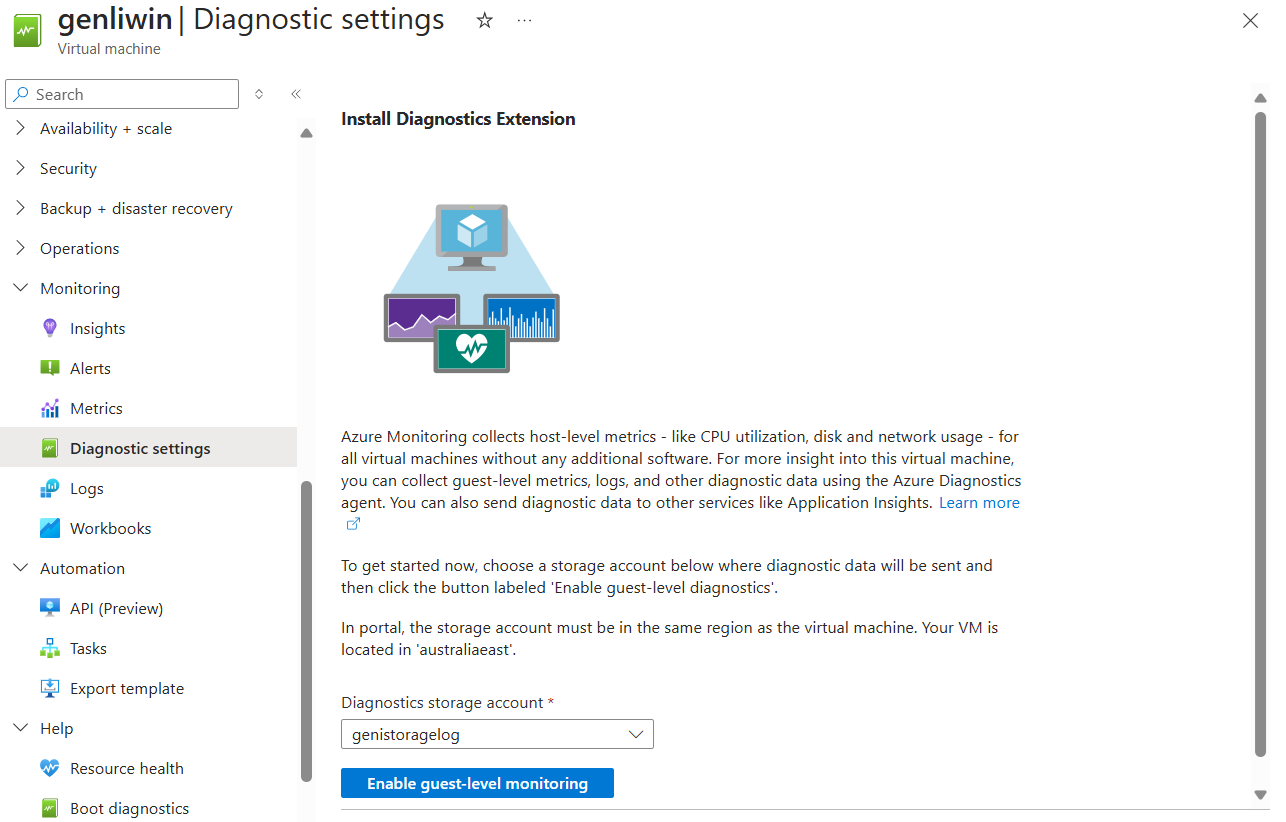
Azure portal を使用して VM 診断を有効にする
VM 診断を有効にするには
VM に移動します。
[ Monitoring セクションで、 Diagnostics 設定を選択します。
ストレージ アカウントを選択し、 ゲスト レベルの監視を有効にするを選択します。

Azure portal を使用してストレージ アカウントのメトリックを表示する (アンマネージド ディスクの場合)
管理されていないディスクを使用する VM の場合ストレージは、IO パフォーマンスを分析する際に非常に重要なレベルです。 ストレージ関連のメトリックについては、追加の手順として診断を有効にする必要があります。
VM を選択して、VM が使用しているストレージ アカウント (またはアカウント) を特定します。
- Azure portal で、VM を選択します。
- Settings で Disk を選択し、ディスクが保存されているストレージ アカウントを見つけます。
- ストレージ アカウントに移動し、 Metrics を選択します。
パフォーマンスのボトルネックを特定する
必要なメトリックの初期セットアップ プロセスを実行すると、VM と関連するストレージ アカウントの診断を有効にした後、分析フェーズに移行できるようになります。
監視にアクセスする
Azure portal で、調査する Azure VM を選択し、 Metrics Monitoring セクションを選択し、メトリックを選択します。
![[使用量と推定コスト] ページを開く方法を示すスクリーンショット。](media/troubleshoot-performance-virtual-machine-linux-windows/select-monitoring.png#lightbox)
観察のタイムライン
リソースのボトルネックがあるかどうかを特定するには、データを確認します。 コンピューターが正常に実行されているのにパフォーマンスが最近低下したことが報告された場合は、報告された問題の発生前、発生中、発生後のパフォーマンス メトリック データが含まれるデータの時間範囲を確認します。
CPU のボトルネックを確認する
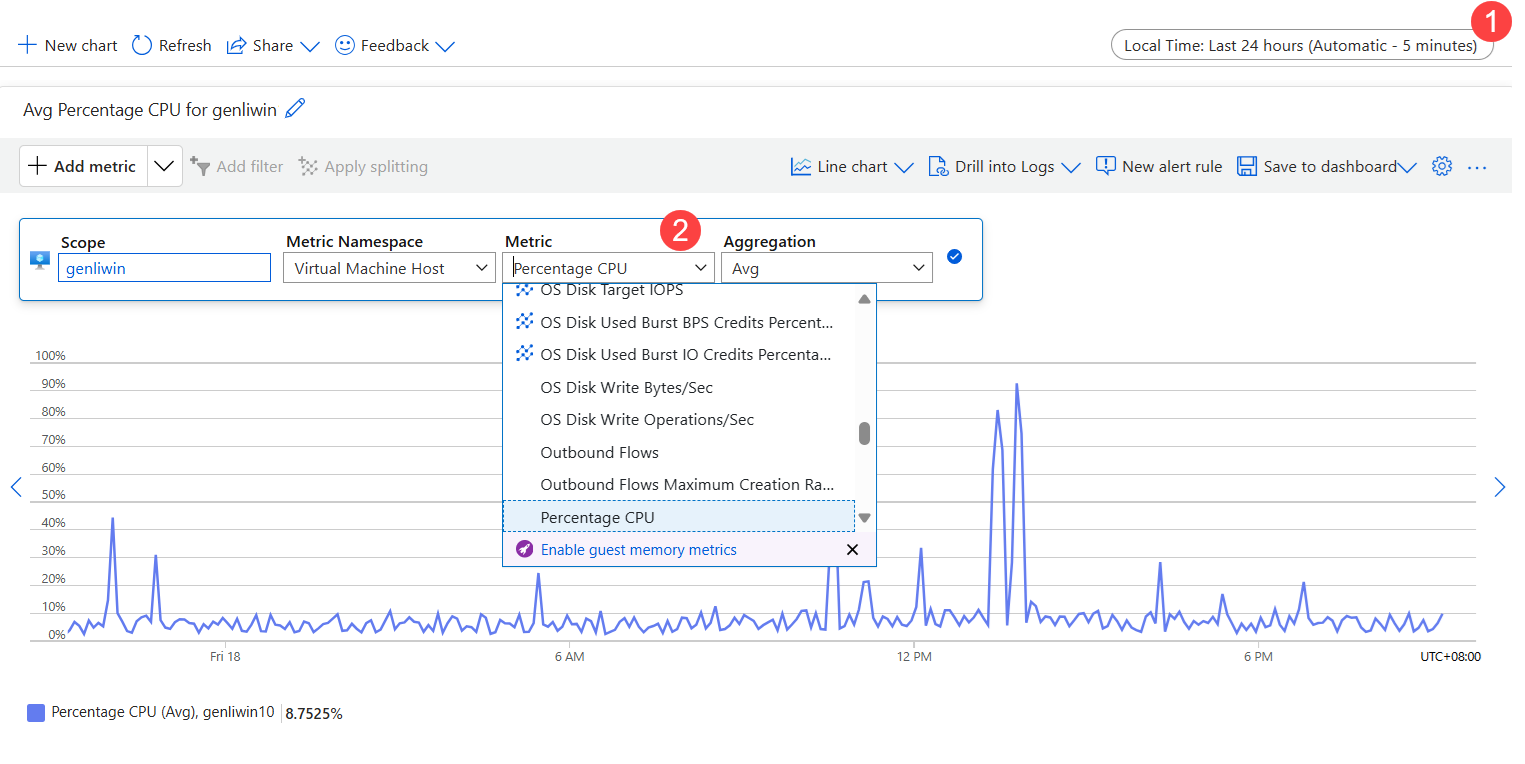
- 時間の範囲を設定します。
- Metric で、[CPU 使用率選択。
CPU パフォーマンスの傾向を監視する
パフォーマンスの問題を調査するときは、傾向を把握して、その影響を受けるかどうかを判断します。 次のセクションでは、ポータルの監視グラフを使用して傾向を表示します。 同じ期間に異なるリソース動作を相互参照する場合にも役立つことがあります。 グラフをカスタマイズするには、Azure Monitor データ プラットフォームをクリックします。
急上昇 – 急上昇は、スケジュールされたタスク/既知のイベントに関連する可能性があります。 タスクを特定できる場合は、必要なパフォーマンス レベルでタスクが実行されているかどうかを判断します。 パフォーマンスが許容できる場合は、リソースを増やす必要はない可能性があります。
急上昇後に一定 – 多くの場合、新しいワークロードを示します。 ワークロードが認識されない場合は、VM の監視を有効にして、動作の原因となっているプロセス (1 つまたは複数) を確認します。 プロセスが認識されたら、使用量の増加が、非効率的なコードによるものか、通常の使用なのかを判断します。 通常の使用の場合は、必要なパフォーマンス レベルでプロセスが動作するかどうかを判定します。
一定 – VM が常にこのレベルで実行されているかどうか、または診断が有効になってからそのレベルでのみ実行されているかどうかを判断します。 その場合は、問題の原因となっているプロセス (1 つまたは複数) を特定し、そのリソースをさらに追加することを検討します。
増加し続ける – 消費量が増加し続けるのは、多くの場合、非効率的なコードまたはプロセスがユーザーのワークロードを増やしています。
高い CPU 使用率の修復
アプリケーションまたはプロセスが最適に実行されておらず、CPU 使用率が 95% を超える場合は、次のいずれかのタスクを実行できます。
- 直ちに軽減する - VM のサイズをコア数が多いサイズに増やします
- 問題を把握する – アプリケーション/プロセスを特定し、それに応じてトラブルシューティングを行います。
VM を増やしても CPU の実行が 95% ある場合は、この設定でパフォーマンスが向上するか、アプリケーションのスループットが許容できるレベルになるかを判断します。 それ以外の場合は、個々のアプリケーション\プロセスのトラブルシューティングを行います。
Windows または Linux に Perfinsights を使用して、どのプロセスが CPU 使用率に影響を与えているかを分析できます。
メモリのボトルネックを確認する
メトリックを表示するには:
- セクションを追加します。
- タイルを追加します。
- ギャラリーを開きます。
- メモリ使用量を選択してドラッグします。 タイルがドッキングされたら、右クリックして [6x4] を選択します。
メモリ パフォーマンスの傾向を監視する
メモリ使用量は、VM で使用されているメモリの量を示します。 傾向と、それが問題が発生した時刻にマップされているかどうかを把握します。 常に 100 MB を超える使用可能なメモリが必要です。
急上昇後に一定/一定の安定した消費量 - 高いメモリ使用率がパフォーマンスの低下の原因ではない場合があります。リレーショナル データベース エンジンなどの一部のアプリケーションで大量のメモリを割り当てても、この使用率に大きな影響がないことがあります。 ただし、メモリを大量に使用するアプリケーションが複数ある場合は、メモリの競合によりパフォーマンスが低下し、ディスクへのトリミングおよびページング/スワップが発生する可能性があります。 このパフォーマンスの低下が、アプリケーションのパフォーマンスに影響を与える顕著な原因になる場合が多くあります。
使用量が着実に増加する – "ウォームアップ" 可能なアプリケーションでは、この消費量は、起動するデータベース エンジンの間で一般的です。 ただし、アプリケーションでメモリ リークが発生している兆候である可能性もあります。 アプリケーションを特定し、動作が想定されたものであるかどうかを判断します。
ページまたはスワップ ファイルの使用状況 – Windows ページング ファイル (D:) または Linux スワップ ファイル ( /dev/sdb にある) を使用しているかどうかを確認します。 これらのファイル以外には、これらのボリュームに何もない場合は、それらのディスクで読み取り/書き込みが多いかどうかを確認してください。 この問題は、メモリ不足の状態を示しています。
高いメモリ使用率の修復
高メモリ使用率を解決するには、次のいずれかのタスクを実行します。
- 直ちに軽減する場合や、ページまたはスワップ ファイルの使用量が多い場合は、VM のサイズを、メモリの多いものに増やしてから監視します。
- 問題を把握する – アプリケーション/プロセスを見つけ、大量のメモリを消費するアプリケーションを特定するためのトラブルシューティングを行います。
- アプリケーションがわかっている場合は、メモリ割り当てが制限されているかどうかを確認します。
より大きな VM にアップグレードした後も、100% まで一定して増加し続けていることがわかった場合は、アプリケーション/プロセスを特定し、トラブルシューティングを行います。
Windows または Linux に Perfinsights を使用して、どのプロセスがメモリ使用率に影響を与えているかを分析できます。
ディスクのボトルネックを確認する (アンマネージド ディスクの場合)
VM のストレージ サブシステムを確認するには、VM 診断のカウンターとストレージ アカウント診断も使用して、Azure VM レベルで診断を確認します。
VM 固有のトラブルシューティングでは、 Windows または Linux に Perfinsights を使用できます。これは、IO を推進しているプロセスを分析するのに役立ちます。
ゾーン冗長および Premium Storage アカウントのカウンターはないことに注意してください。 これらのカウンターに関連する問題の場合は、サポート ケースを生成します。
監視でストレージ アカウント診断を表示する
以下の項目を操作するには、ポータルで VM のストレージ アカウントにアクセスします。
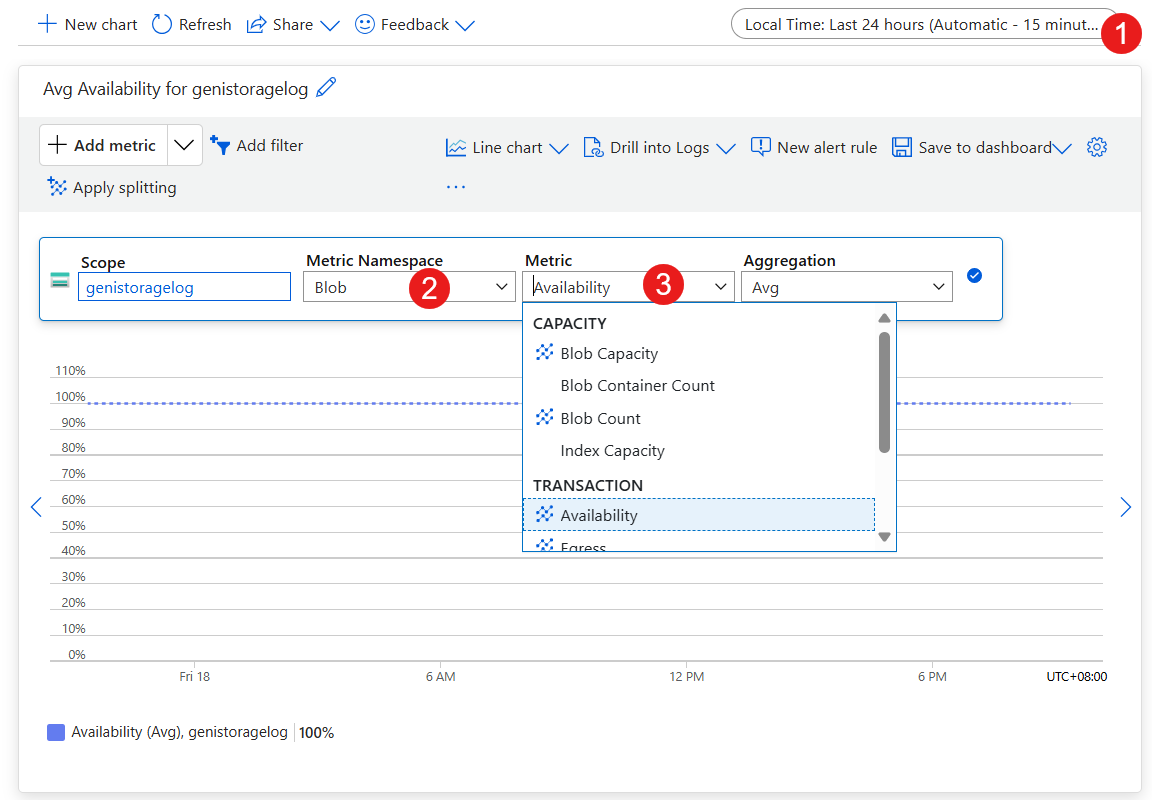
- 時間の範囲を設定します。
- Metric Namespace を Blob に設定します。
- Metric を Availability に設定します。
ディスク パフォーマンスの傾向を監視する (Standard Storage のみ)
ストレージに関する問題を特定するには、ストレージ アカウント診断と VM 診断のパフォーマンス メトリックを確認します。
以下のチェックごとに、問題の時間範囲内で問題が発生した場合の主な傾向を確認します。
Azure ストレージの可用性を確認する – ストレージ アカウントのメトリックを追加する: 可用性
可用性が低下している場合は、プラットフォームに問題がある可能性があるため、Azure の状態を確認します。 問題が何も表示されない場合は、新しいサポート リクエストを生成します。
Azure ストレージのタイムアウトを確認する - ストレージ アカウントメトリックを追加する
- ClientTimeOutError
- ServerTimeOutError
- AverageE2ELatency
- AverageServerLatency
- TotalRequests
*TimeOutError メトリックの値は、IO 操作に時間がかかりすぎてタイムアウトしたことを示します。次の手順を実行すると、潜在的な原因を特定するのに役立ちます。
TimeOutErrors で同時に AverageServerLatency が増加する場合は、プラットフォームの問題である可能性があります。 この場合は、新しいサポート リクエストを生成します。
AverageE2ELatency は、クライアントの待機時間を表します。 アプリケーションによって IOPS がどのように実行されるかを確認します。 増加、または TotalRequests メトリックが常に高いかを確認します。 このメトリックは IOPS を表します。 ストレージ アカウントまたは単一の VHD の上限に達し始めている場合は、待機時間が調整に関連している可能性があります。
Azure ストレージの調整を確認する - ストレージ アカウントのメトリックを追加する: ThrottlingError
調整の値は、ストレージ アカウント レベルで調整されていることを示します。つまり、アカウントの IOPS 制限に達していることを意味します。 IOP のしきい値に達しているかどうかを確認するには、メトリック TotalRequests を確認します。
各 VHD には 500 IOPS または 60 MBit の制限がありますが、ストレージ アカウントあたりの 20000 IOPS の累積制限に縛られます。
このメトリックでは、どの BLOB が調整の原因であり、どれがその影響を受けているかは判断できません。 ただし、ストレージ アカウントの IOPS またはイングレス/エグレスの制限のいずれかに達しています。
IOPS の上限に達しているかどうかを確認するには、ストレージ アカウントの診断にアクセスし、TotalRequests を調べて、TotalRequests が 20000 に達しているかどうかを確認します。 パターンの変更、制限が初めて表示されているかどうか、またはこの制限が特定の時間に発生するかどうかを特定します。
Standard ストレージの新しいディスク オファリングでは、IOPS とスループットの制限が異なる場合がありますが、Standard ストレージ アカウントの累積制限は 20000 IOPS です (Premium ストレージの制限は、アカウント レベルまたはディスク レベルで異なります)。 さまざまな Standard ストレージのディスク オファリングとディスクごとの制限については、以下を参照してください。
関連情報
ストレージ アカウントの帯域幅は、ストレージ アカウントのメトリックで測定されます: TotalIngress および TotalEgress。 帯域幅のしきい値は、冗長性とリージョンの種類によって異なります。
ストレージ アカウントの冗長性の種類とリージョンのイングレスおよびエグレスの制限に対して TotalIngress と TotalEgress を確認します。
VM に接続されている VHD のスループットの上限を確認します。 VM メトリック ディスクの読み取りと書き込みを追加します。
Standard ストレージの新しいディスク オファリングには、さまざまな IOPS とスループットの制限があります (IOPS は VHD ごとには公開されません)。 データを見て、ディスクの読み取りと書き込みを使用して VM レベルでの VHD の合計スループット (MB) の上限に達しているかどうかを確認し、VM ストレージ構成を最適化して、1 つの VHD 制限を超えてスケーリングします。 さまざまな Standard ストレージのディスク オファリングとディスクごとの制限については、以下を参照してください。
ディスクの高使用率と待機時間の修復
クライアントの待機時間を短縮し、VM IO を最適化して、VHD の制限を超えてスケーリングします
調整を減らす
ストレージ アカウントの上限に達した場合は、ストレージ アカウント間で VHD のバランスを再調整します。 Azure Storage のスケーラビリティおよびパフォーマンスのターゲットに関する記事をご覧ください。
スループットの向上と待機時間の短縮
待機時間の影響を受けやすいアプリケーションがあり、高いスループットが必要な場合は、DS および GS シリーズの VM を使用して、VHD を Azure Premium Storage に移行します。
次の記事では、特定のシナリオについて説明します。
お問い合わせはこちらから
質問がある場合やヘルプが必要な場合は、サポート要求を作成するか、Azure コミュニティ サポートにお問い合わせください。 Azure フィードバック コミュニティに製品フィードバックを送信することもできます。