Microsoft Purview で Hive メタストア データベースに接続して管理する
この記事では、Hive メタストア データベースを登録する方法と、Microsoft Purview で Hive メタストア データベースを認証して操作する方法について説明します。 Microsoft Purview の詳細については、 入門記事を参照してください。
サポートされている機能
| メタデータ抽出 | フル スキャン | 増分スキャン | スコープスキャン | 分類 | ラベル付け | アクセス ポリシー | 系統 | データ共有 | ライブ ビュー |
|---|---|---|---|---|---|---|---|---|---|
| ○ | はい | いいえ | はい | いいえ | いいえ | いいえ | はい* | いいえ | いいえ |
* データ ソース内の資産の系列に加えて、データセットが Data Factory または Synapse パイプラインのソース/シンクとして使用されている場合は、系列もサポートされます。
サポートされている Hive バージョンは、2.x から 3.x です。 サポートされているプラットフォームは、Apache Hadoop、Cloudera、Hortonworks です。 Azure Databricks をスキャンする場合は、互換性が高く使いやすい Azure Databricks コネクタを使用することをお勧めします。
Hive メタストア ソースをスキャンする場合、Microsoft Purview では次の処理がサポートされます。
以下を含む技術的なメタデータの抽出:
- サーバー
- Databases
- 列、外部キー、一意の制約、ストレージの説明を含むテーブル
- 列とストレージの説明を含むビュー
テーブルとビュー間の資産リレーションシップに対する静的系列のフェッチ。
スキャンを設定するときに、Hive メタストア データベース全体をスキャンするか、指定された名前または名前パターンに一致するスキーマのサブセットにスキャンのスコープを設定するかを選択できます。
既知の制限
オブジェクトがデータ ソースから削除された場合、現在、後続のスキャンでは、Microsoft Purview の対応する資産は自動的に削除されません。
前提条件
アクティブなサブスクリプションを持つ Azure アカウントが必要です。 無料でアカウントを作成します。
アクティブな Microsoft Purview アカウントが必要です。
ソースを登録し、Microsoft Purview ガバナンス ポータルで管理するには、データ ソース管理者とデータ 閲覧者のアクセス許可が必要です。 アクセス許可の詳細については、「 Microsoft Purview でのアクセス制御」を参照してください。
データ ソースにパブリックにアクセスできない場合は、最新のセルフホステッド統合ランタイムを設定します。
-
シナリオに適した統合ランタイムを選択します。
-
セルフホステッド統合ランタイムを使用するには:
- 記事に従って、セルフホステッド統合ランタイムを作成して構成します。
- セルフホステッド統合ランタイムがインストールされているマシンに JDK 11 がインストールされていることを確認します。 JDK を新しくインストールして有効にした後、マシンを再起動します。
- セルフホステッド統合ランタイムが実行されているコンピューターに、Visual C++ 再頒布可能パッケージ (バージョン Visual Studio 2012 Update 4 以降) がインストールされていることを確認します。 この更新プログラムがインストールされていない場合は、 今すぐダウンロードしてください。
- セルフホステッド統合ランタイムが実行されているマシンに Hive メタストア データベースの JDBC ドライバーをダウンロードします。 たとえば、データベースが mssql の場合は、SQL Server用に Microsoft の JDBC ドライバーをダウンロードします。 スキャンの設定に使用するフォルダー パスをメモします。
-
kubernetes でサポートされているセルフホステッド統合ランタイムを使用するには:
- 記事に従って、kubernetes でサポートされている統合ランタイムを作成して構成します。
- セルフホステッド統合ランタイムが実行されているマシンに Hive メタストア データベースの JDBC ドライバーをダウンロードします。 たとえば、データベースが mssql の場合は、SQL Server用に Microsoft の JDBC ドライバーをダウンロードします。 スキャンの設定に使用するフォルダー パスをメモします。
-
セルフホステッド統合ランタイムを使用するには:
注:
JDBC ドライバーには、セルフホステッド統合ランタイムからアクセスできる必要があります。 既定では、セルフホステッド統合ランタイムは ローカル サービス アカウント "NT SERVICE\DIAHostService" を使用します。 ドライバー フォルダーに対する "読み取りと実行" および "フォルダーの内容の一覧表示" アクセス許可があることを確認します。
-
シナリオに適した統合ランタイムを選択します。
登録
このセクションでは、 Microsoft Purview ガバナンス ポータルを使用して、Microsoft Purview に Hive メタストア データベースを登録する方法について説明します。
Hive メタストア データベースでサポートされている認証は、基本認証のみです。
次の方法で Microsoft Purview ガバナンス ポータルを開きます。
- https://web.purview.azure.comに直接移動し、Microsoft Purview アカウントを選択します。
- Azure portalを開き、Microsoft Purview アカウントを検索して選択します。 [Microsoft Purview ガバナンス ポータル] ボタンを選択します。
左側のウィンドウで [ データ マップ ] を選択します。
[登録] を選択します。
[ ソースの登録] で、[ Hive メタストア>Continue] を選択します。
[ ソースの登録 (Hive メタストア)] 画面で、次の操作を行います。
[ 名前] に、Microsoft Purview がデータ ソースとして一覧表示する名前を入力します。
[ Hive クラスター URL] に、Ambari URL から取得する値を入力します。 たとえば、「hive.azurehdinsight.net」と入力 します。
[Hive メタストア サーバー URL] に、サーバーの URL を入力します。 たとえば、「sqlserver://hive.database.windows.net」と入力 します。
一覧からコレクションを選択します。
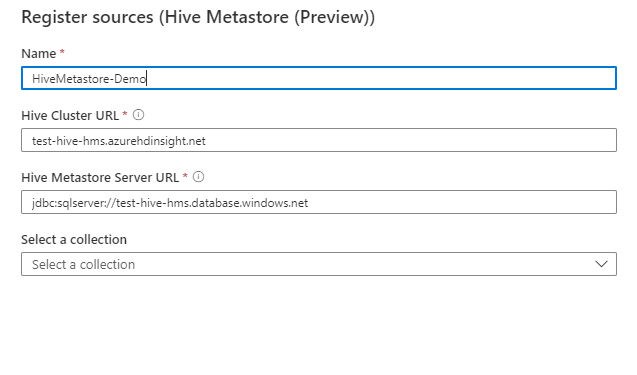
[完了] を選択します。
スキャン
次の手順を使用して Hive メタストア データベースをスキャンし、資産を自動的に識別します。 一般的なスキャンの詳細については、「 Microsoft Purview でのスキャンとインジェスト」を参照してください。
管理センターで、統合ランタイムを選択します。 セルフホステッド統合ランタイムが設定されていることを確認します。 セットアップされていない場合は、前提条件の手順を使用 します。
[ソース] に移動します。
登録済みの Hive メタストア データベースを選択します。
[ + 新しいスキャン] を選択します。
次のユーザー詳細を入力します。
[名前]: スキャンの名前を入力します。
統合ランタイム経由で接続する: 構成済みのセルフホステッド統合ランタイムを選択します。
資格情報: データ ソースに接続する資格情報を選択します。 次のことを確認してください。
- 資格情報の作成時に [基本認証] を選択します。
- 適切なボックスに Metastore ユーザー名を指定します。
- メタストア パスワードを秘密キーに格納します。
詳細については、「 Microsoft Purview でのソース認証の資格情報」を参照してください。
メタストア JDBC ドライバーの場所: セルフホスト統合ランタイムが実行されているコンピューター内の JDBC ドライバーの場所へのパスを指定します。 たとえば、「
D:\Drivers\HiveMetastore」のように入力します。- ローカル コンピューター上のセルフホステッド統合ランタイムの場合:
D:\Drivers\HiveMetastore。 これは、有効な JAR フォルダーの場所へのパスです。 値は有効な絶対ファイル パスである必要があり、スペースは含まれません。 セルフホステッド統合ランタイムがドライバーにアクセスできることを確認します。 詳細については、「前提条件」セクションを参照してください。 - Kubernetes でサポートされるセルフホステッド統合ランタイムの場合:
./drivers/HiveMetastore。 これは、有効な JAR フォルダーの場所へのパスです。 値は、有効な相対ファイル パスである必要があります。 事前にドライバーをアップロードするための 外部ドライバーを含むスキャンを設定 するには、ドキュメントを参照してください。
- ローカル コンピューター上のセルフホステッド統合ランタイムの場合:
メタストア JDBC ドライバー クラス: 接続ドライバーのクラス名を指定します。 たとえば、「 \com.microsoft.sqlserver.jdbc.SQLServerDriver」と入力します。
メタストア JDBC URL: 接続 URL の値を指定し、メタストア データベース サーバーの URL への接続を定義します。 例:
jdbc:sqlserver://hive.database.windows.net;database=hive;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=300。注:
hive-site.xmlから URL をコピーすると、文字列から
amp;が削除されるか、スキャンが失敗します。SSL 証明書を セルフホステッド統合ランタイム コンピューターにダウンロードし、URL 内のコンピューター上の SSL 証明書の場所へのパスを更新します。
スキャン構成でローカル ファイル パスを入力する場合は、Windows パス区切り文字を円記号 (
\) からスラッシュ (/) に変更します。 たとえば、ローカル ファイル パス D:\Drivers\SSLCert\BaltimoreCyberTrustRoot.crt.pem に SSL 証明書を配置する場合は、serverSslCertパラメーターの値を D:/Drivers/SSLCert/BaltimoreCyberTrustRoot.crt.pem に変更します。メタストア JDBC URL の値は、次の例のようになります。
jdbc:mariadb://samplehost.mysql.database.azure.com:3306/XXXXXXXXXXXXXXXX?useSSL=true&enabledSslProtocolSuites=TLSv1,TLSv1.1,TLSv1.2&serverSslCert=D:/Drivers/SSLCert/BaltimoreCyberTrustRoot.crt.pemメタストア データベース名: Hive メタストア データベースの名前を指定します。
スキーマ: インポートする Hive スキーマの一覧を指定します。 例: schema1;schema2。
そのリストが空の場合、すべてのユーザー スキーマがインポートされます。 既定では、すべてのシステム スキーマ (SysAdmin など) とオブジェクトは無視されます。
SQL
LIKE式構文を使用する許容されるスキーマ名パターンには、パーセント記号 (%) が含まれます。 たとえば、A%; %B; %C%; Dは次のことを意味します。- A または から始める
- B または で終わる
- C または を含む
- 等しい D
NOTおよび特殊文字の使用は許可されません。使用可能な最大メモリ: スキャン プロセスで使用するために、お客様のコンピューターで使用可能な最大メモリ (ギガバイト単位)。 この値は、スキャンする Hive メタストア データベースのサイズによって異なります。
注:
経験則として、1000 テーブルごとに 1 GB のメモリを指定してください。
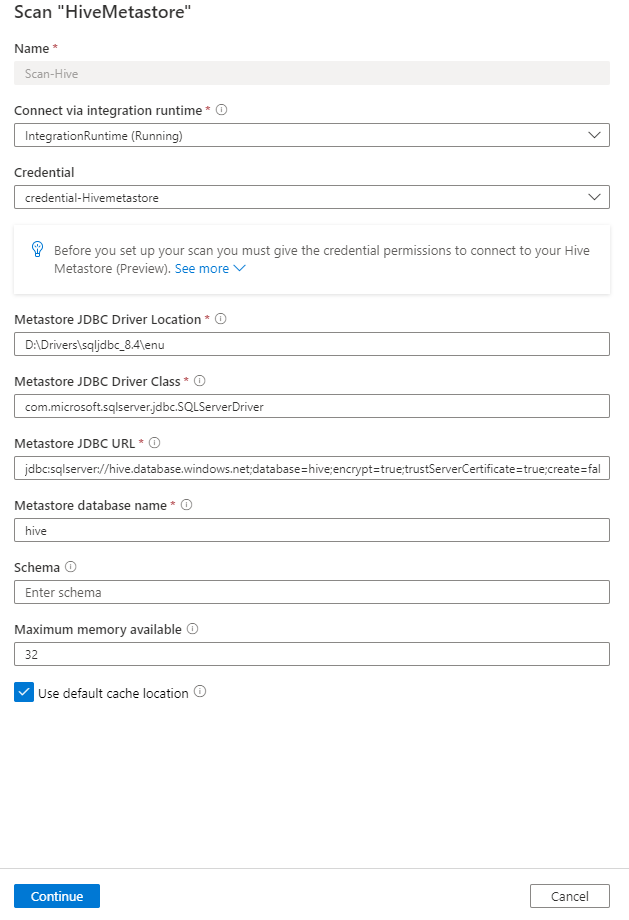
[続行] を選択します。
[ スキャン トリガー] で、スケジュールを設定するか、スキャンを 1 回実行するかを選択します。
スキャンを確認し、[ 保存して実行] を選択します。
スキャンとスキャンの実行を表示する
既存のスキャンを表示するには:
- Microsoft Purview ポータルに移動します。 左側のウィンドウで、[ データ マップ] を選択します。
- データ ソースを選択します。 [最近のスキャン] で、そのデータ ソースの既存の スキャンの一覧を表示したり、[ スキャン ] タブですべてのスキャンを表示したりできます。
- 表示する結果を含むスキャンを選択します。 このウィンドウには、以前のすべてのスキャン実行と、各スキャン実行の状態とメトリックが表示されます。
- 実行 ID を選択して、スキャン実行の詳細をチェックします。
スキャンを管理する
スキャンを編集、取り消し、または削除するには:
Microsoft Purview ポータルに移動します。 左側のウィンドウで、[ データ マップ] を選択します。
データ ソースを選択します。 [最近のスキャン] で、そのデータ ソースの既存の スキャンの一覧を表示したり、[ スキャン ] タブですべてのスキャンを表示したりできます。
管理するスキャンを選択します。 次のことを実行できます。
- [スキャンの編集] を選択して スキャンを編集します。
- [スキャンの実行の取り消し] を選択して、進行中 のスキャンを取り消します。
- [スキャンの削除] を選択して スキャンを削除します。
注:
- スキャンを削除しても、以前のスキャンから作成されたカタログ資産は削除されません。
系統
Hive メタストア ソースをスキャンした後、統合カタログ参照するか、統合カタログを検索して資産の詳細を表示できます。
[資産 - > 系列] タブに移動すると、該当する場合に資産関係を確認できます。 サポートされている Hive Metastore 系列のシナリオについては、サポートされている機能に関するセクションを参照してください。 系列全般の詳細については、「データ系列と系列ユーザー ガイド」を参照してください。
次の手順
ソースを登録したので、次のガイドを使用して、Microsoft Purview とデータの詳細を確認します。