データ品質ルールの詳細と作成
データ品質は、organization内のデータの整合性の測定であり、データ品質スコアを使用して評価されます。 Microsoft Purview 統合カタログで定義されているルールに対するデータの評価に基づいて生成されるスコア。
データ品質ルールは、組織がデータの正確性、一貫性、完全性を確保するために確立する重要なガイドラインです。 これらのルールは、データの整合性と信頼性を維持するのに役立ちます。
データ品質ルールの主な側面を次に示します。
精度 - データは実際のエンティティを正確に表す必要があります。 コンテキストが重要です。 たとえば、顧客アドレスを格納する場合は、実際の場所と一致していることを確認します。
完全性 - このルールの目的は、空、null、または不足しているデータを特定することです。 この規則は、すべての値が存在することを検証します (必ずしも正しいとは限りません)。
適合性 - この規則により、データが日付、住所、許可値の表現などのデータ書式設定標準に従うことが保証されます。
整合性 - このルールは、同じレコードの異なる値が特定のルールに準拠しており、矛盾がないことを確認します。 データの整合性により、同じ情報が異なるレコード間で一様に表現されます。 たとえば、製品カタログがある場合は、一貫性のある製品名と説明が重要です。
タイムライン - このルールは、データにできるだけ短時間でアクセスできるようにすることを目的としています。 これにより、データが最新の状態になります。
一意性 - このルールでは、値が重複していないことを確認します。たとえば、顧客ごとに 1 つのレコードしか存在しない場合、同じ顧客に対して複数のレコードが存在しない場合などです。 各顧客、製品、またはトランザクションには、一意の識別子が必要です。
データ品質のライフ サイクル
データ品質ルールの作成は、データ品質ライフサイクルの 6 番目 の手順です。 前の手順は次のとおりです。
- すべてのデータ品質機能を使用するには、統合カタログでユーザーにデータ品質スチュワードのアクセス許可を割り当てます。
- Microsoft Purview データ マップでデータ ソースを登録してスキャンします。
- データ製品にデータ資産を追加する
- データ品質評価のためにソースを準備するために、データ ソース接続を設定します。
- データ ソース内の資産のデータ プロファイルを構成して実行します。
必要な役割
- データ品質ルールを作成および管理するには、ユーザーが データ品質スチュワード ロールである必要があります。
- 既存の品質規則を表示するには、ユーザーが データ品質閲覧者ロールに含まれている必要があります。
既存のデータ品質ルールを表示する
Microsoft Purview 統合カタログから、[正常性管理] メニューと [データ品質] サブメニューを選択します。
データ品質サブメニューで、 ガバナンス ドメインを選択します。
データ製品を選択します。
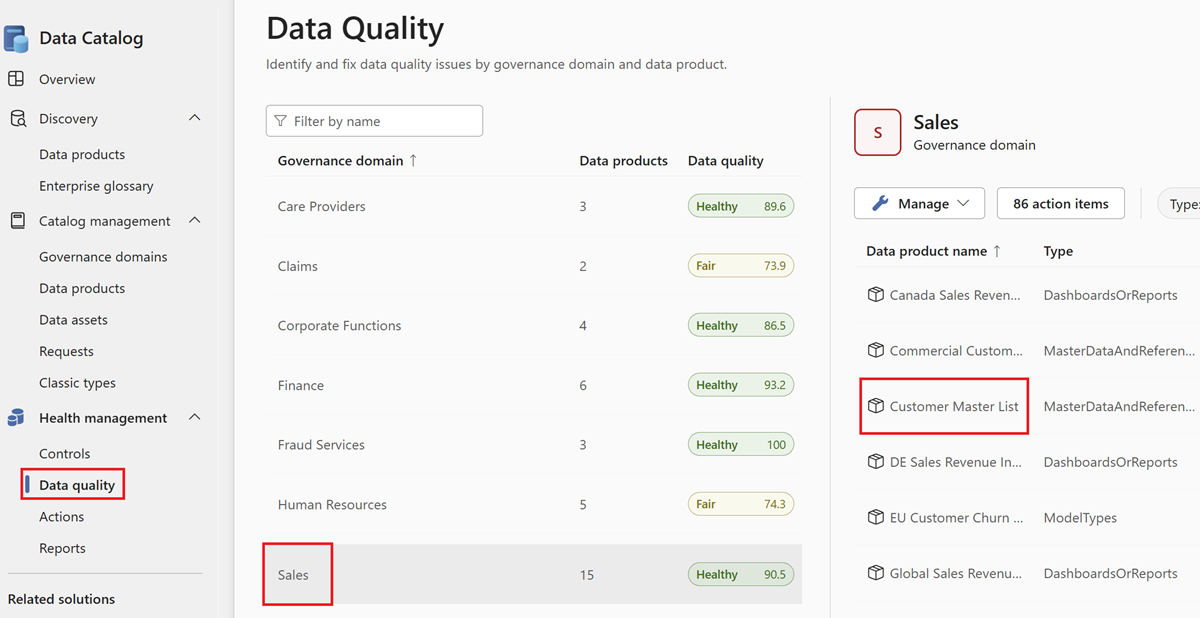
選択した データ 製品の資産一覧からデータ資産を選択します。
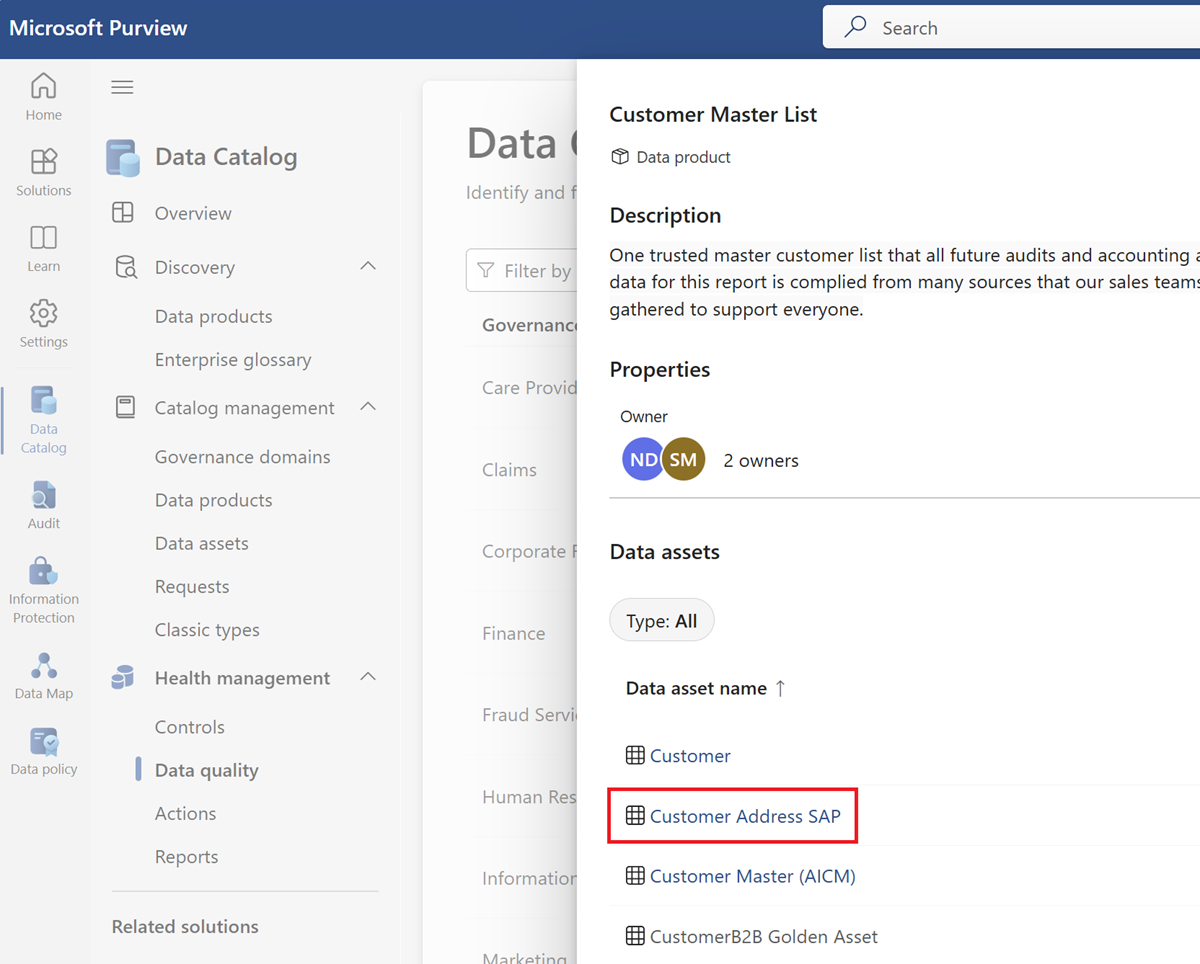
[ ルール ] メニュー タブを選択すると、資産に適用されている既存のルールが表示されます。
![[ルール] タブが選択されているデータ資産のスクリーンショット。](media/concept-data-quality-rules/rule-page-inline.png)
ルールを選択して、選択したデータ資産に適用されたルールのパフォーマンス履歴を参照します。
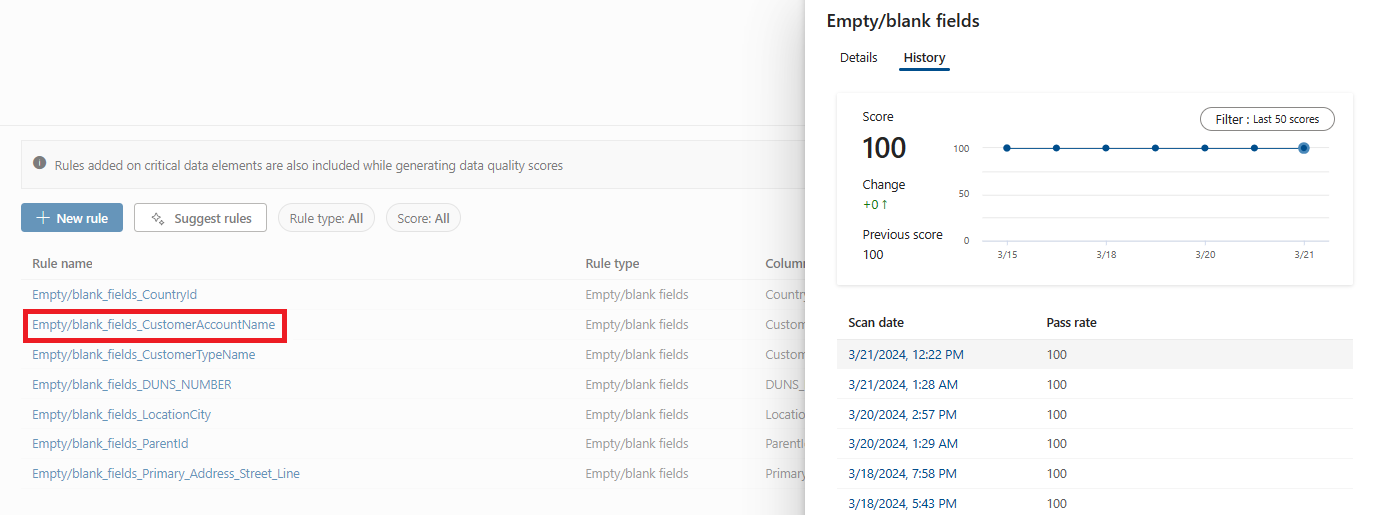


![[ルール] タブが選択されているデータ資産のスクリーンショット。](media/concept-data-quality-rules/rule-page.png#lightbox)

使用可能なデータ品質ルール
次の規則の構成を有効にするMicrosoft Purview データ品質、これらは、低コードからコードなしの方法でデータの品質を測定する規定外のルールです。
| Rule | 定義 |
|---|---|
| Freshness | すべての値が最新であることを確認します。 |
| 一意の値 | 列の値が一意であることを確認します。 |
| 文字列形式の一致 | 列の値が特定の形式またはその他の条件と一致することを確認します。 |
| データ型の一致 | 列の値がデータ型の要件と一致することを確認します。 |
| 重複する行 | 2 つ以上の列で同じ値を持つ重複する行をチェックします。 |
| 空/空白フィールド | 値が必要な列で空白フィールドと空のフィールドを検索します。 |
| テーブル参照 | あるテーブルの値が別のテーブルの特定の列に存在することを確認します。 |
| Custom | ビジュアル式ビルダーを使用してカスタム ルールを作成します。 |
Freshness
鮮度ルールの目的は、資産が予想時間内に更新されたかどうかを判断することです。 現在、Microsoft Purview では 、最終変更日を確認することで、鮮度のチェックがサポートされています。
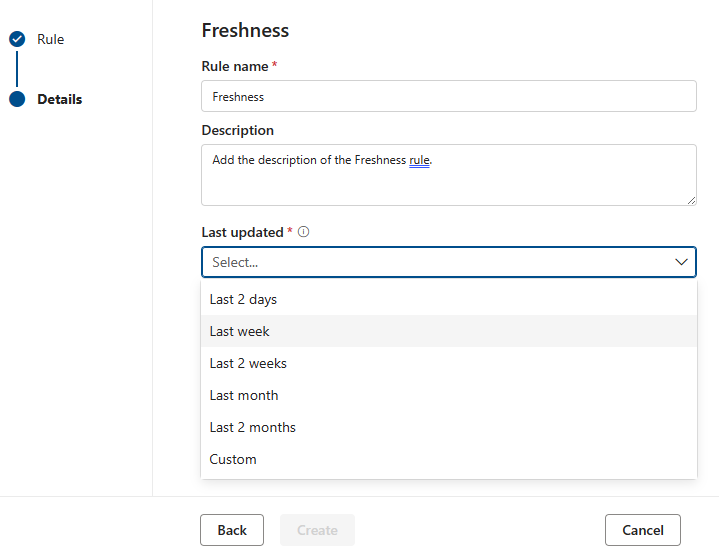
注:
鮮度ルールのスコアは、100 (合格) または 0 (失敗) のいずれかです。 Snowflake、Azure Databricks UC、Google BigQuery、Synapes、Azure SQLでは、鮮度ルールはサポートされていません。
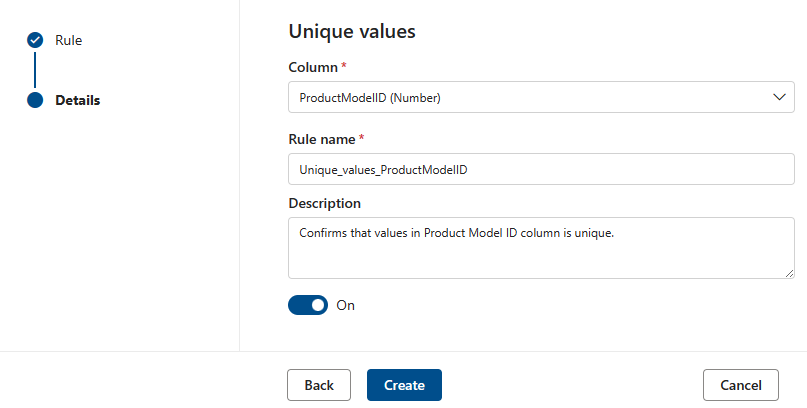
一意の値
[Unique values]\(一意の値\) ルールは、指定した列のすべての値が一意である必要があることを示します。 一意の 'pass' である値と、失敗として扱われないものはすべてです。 列に空/空白フィールドルールが定義されていない場合、このルールの目的で null/空の値は無視されます。
文字列形式の一致
[書式] 一致ルールでは、列内のすべての値が有効かどうかを確認します。 列に空/空白フィールドルールが定義されていない場合、このルールの目的で null/空の値は無視されます。
このルールでは、次の 3 つの異なる方法を使用して、列内の各値を検証できます。
列挙 – これはコンマ区切りの値の一覧です。 評価される値を一覧表示されている値の 1 つと比較できない場合は、チェックが失敗します。 コンマと円記号は、円記号 (
\) を使用してエスケープできます。 そのため、a \, b, cには 2 つの値が含まれています。1 つ目はa , b、2 つ目はcです。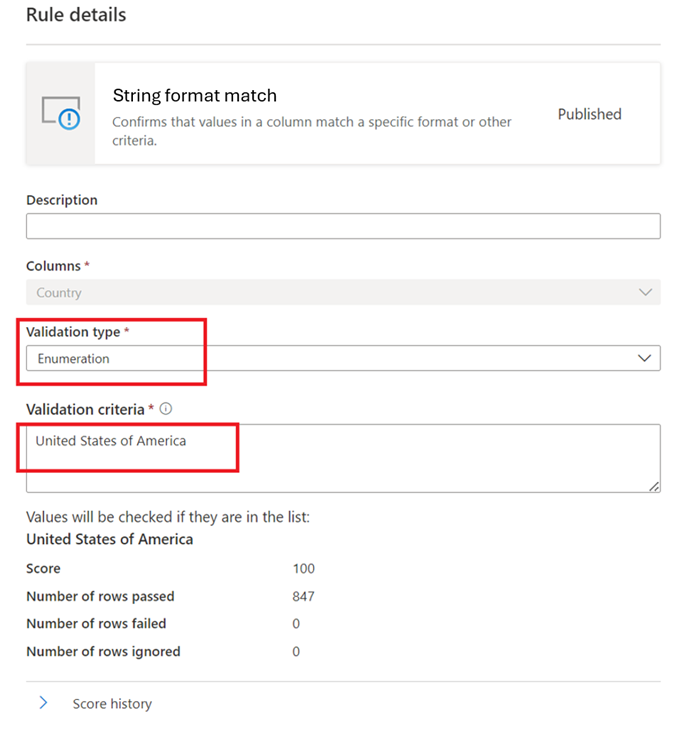
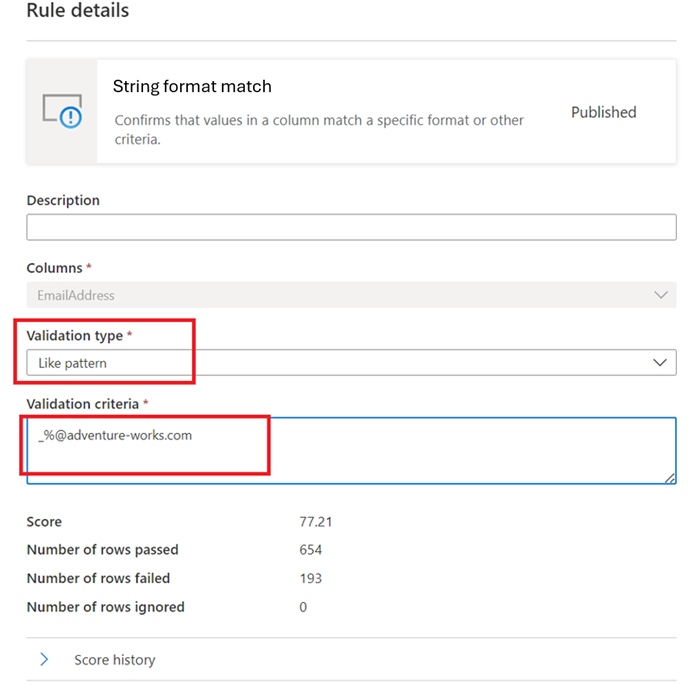
Like Pattern -
like(<string> : string, <pattern match> : string) => boolean
パターンは、リテラルに一致する文字列です。 例外は、次の特殊な記号です。 _ は、入力内の任意の 1 文字 (posix正規表現の 場合と同様) に一致します。% は、入力の 0 個以上の文字 (posix正規表現では .* と同様) と一致します。 エスケープ文字は '' です。 エスケープ文字が特別な記号または別のエスケープ文字の前にある場合、次の文字はリテラルで一致します。 他の文字をエスケープすることは無効です。like('icecream', 'ice%') -> true
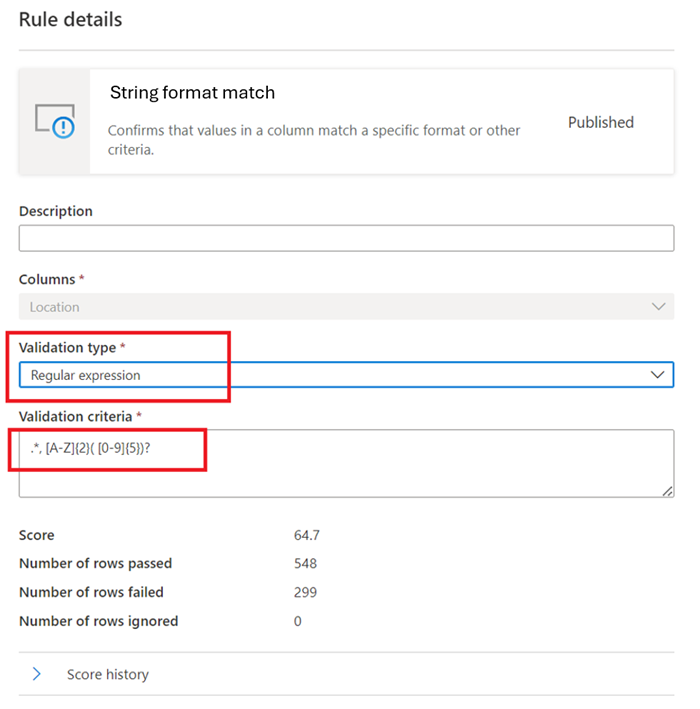
正規表現 –
regexMatch(<string> : string, <regex to match> : string) => boolean
文字列が指定された正規表現パターンと一致するかどうかを確認します。 エスケープせずに文字列を照合するには、<regex>(バッククォート) を使用します。regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
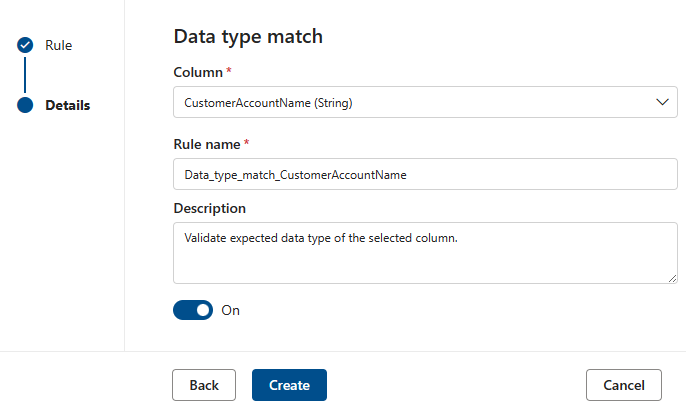
データ型の一致
データ型の一致規則では、関連付けられている列に含める必要があるデータ型を指定します。 ルール エンジンはさまざまなデータ ソースで実行する必要があるため、BIGINT や VARCHAR などのネイティブ型を使用することはできません。 代わりに、ネイティブ型を変換する独自の型システムがあります。 このルールは、ネイティブ型を変換する必要がある組み込み型のうちどれを品質スキャン エンジンに指示します。 データ型システムは、Azure Data Factoryで使用される Azure Data Flow 型システムから取得されます。
品質スキャン中に、すべてのネイティブ型がデータ型の一致型に対してテストされ、ネイティブ型をデータ型の一致型に変換できない場合、その行はエラーとして扱われます。
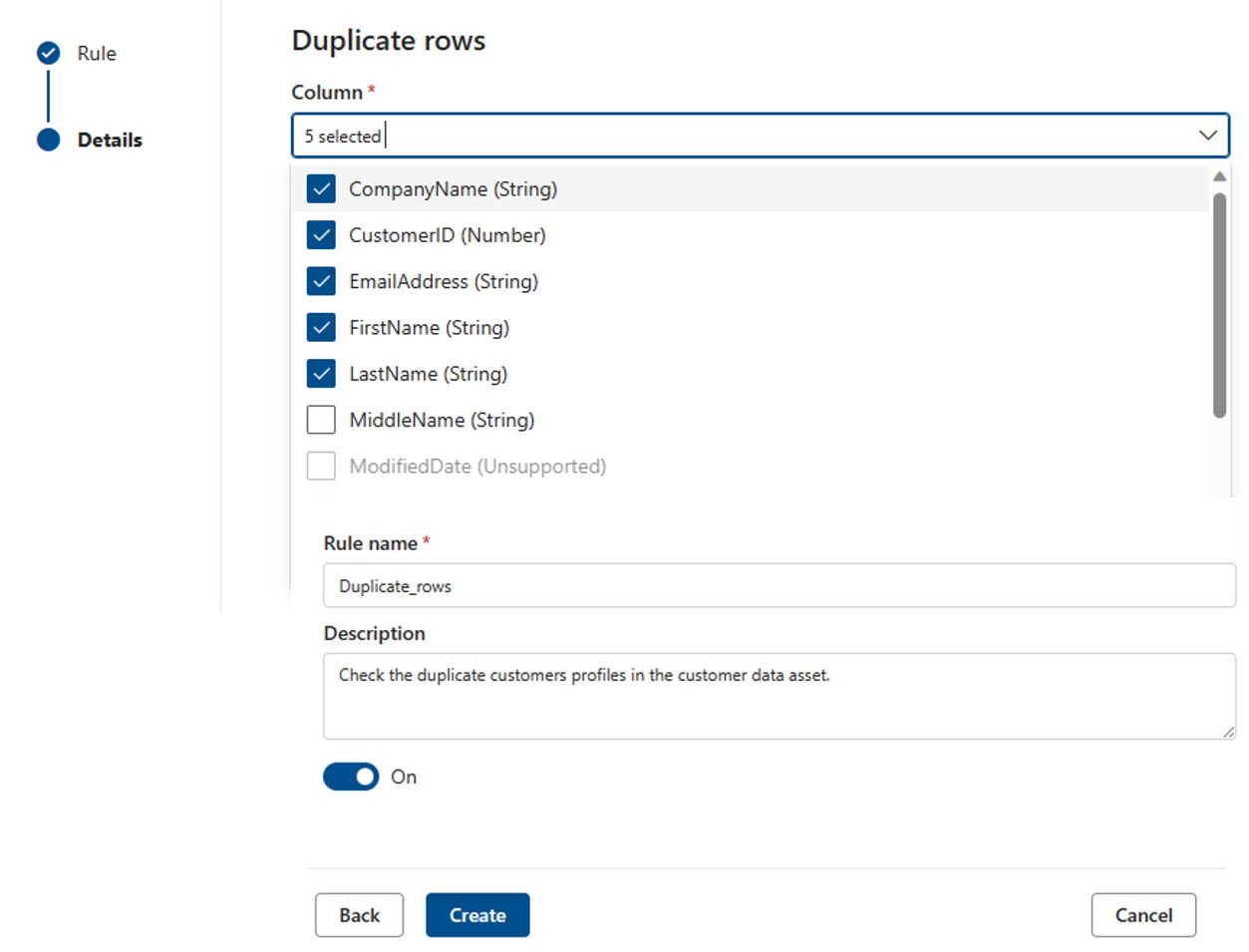
重複する行
[重複する行] ルールでは、列内の値の組み合わせがテーブル内のすべての行に対して一意であるかどうかを確認します。
次の例では、_CompanyName、CustomerID、EmailAddress、FirstName、 LastName を連結すると、テーブル内のすべての行に対して一意の値が生成されます。
各資産には、この規則のインスタンスを 0 個または 1 個使用できます。
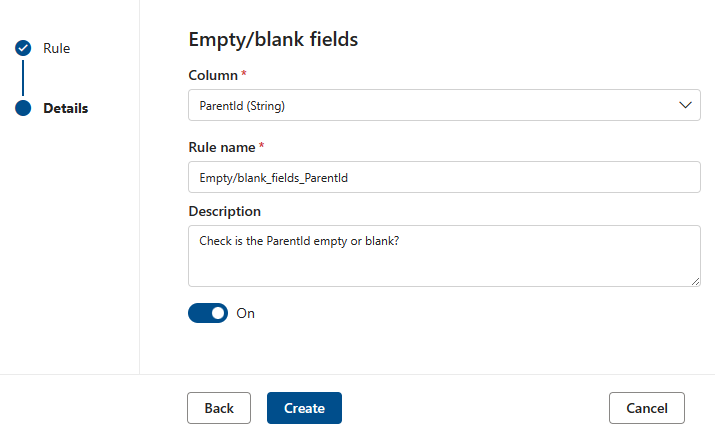
空/空白フィールド
空/空白フィールドルールは、識別された列に null 値を含めず、文字列の特定のケースでは、空または空白の値のみを含めないことをアサートします。 品質スキャン中に、この列内の null ではない値は、正しい値として扱われます。 このルールは、 一意の値 や 書式の一致 ルールなどの他のルールに影響します。 このルールが列に対して定義されていない場合、その列で実行された場合、これらのルールは null 値を自動的に無視します。 このルールが列に対して定義されている場合、それらのルールはその列の null/空の値を調べ、スコアのためにそれらを考慮します。
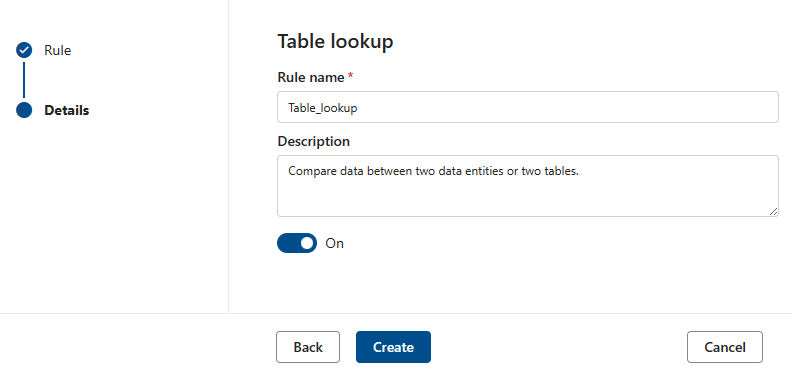
テーブル参照
テーブル参照ルールは、ルールが定義されている列の各値を調べ、参照テーブルと比較します。 たとえば、プライマリ テーブルには "location" という名前の列があり、"city, state zip" という形式の都市、州、郵便番号が含まれています。 citystate と呼ばれる参照テーブルには、米国でサポートされている都市、州、郵便番号のすべての法的な組み合わせが含まれています。 目標は、現在の列のすべての場所をその参照リストと比較して、法的な組み合わせのみが使用されていることを確認することです。
これを行うには、最初に "citystatezip の名前を検索資産ダイアログに入力します。 次に、目的の資産を選択し、比較する列を選択します。
注:
参照テーブルまたはデータ資産は、同じガバナンス ドメインに属している必要があります。 異なるガバナンス ドメイン間でのデータ資産の比較は許可されません。
カスタム ルール
カスタム ルールを使用すると、その行内の 1 つ以上の値に基づいて行を検証しようとするルールを指定できます。 カスタム ルールには、次の 2 つの部分があります。
- 最初の部分は、省略可能なフィルター式であり、"フィルター式を使用する" で [チェック] ボックスを選択してアクティブ化されます。 これはブール値を返す式です。 フィルター式が行に適用され、true が返された場合、その行はルールと見なされます。 フィルター式がその行に対して false を返す場合は、この規則の目的で行が無視されることを意味します。 フィルター式の既定の動作は、すべての行を渡すことです。そのため、フィルター式が指定されておらず、必要でない場合は、すべての行が考慮されます。
- 2 番目の部分は 行式です。 これは、フィルター式によって承認される各行に適用されるブール式です。 この式が true を返した場合、行は false の場合に渡され、失敗としてマークされます。
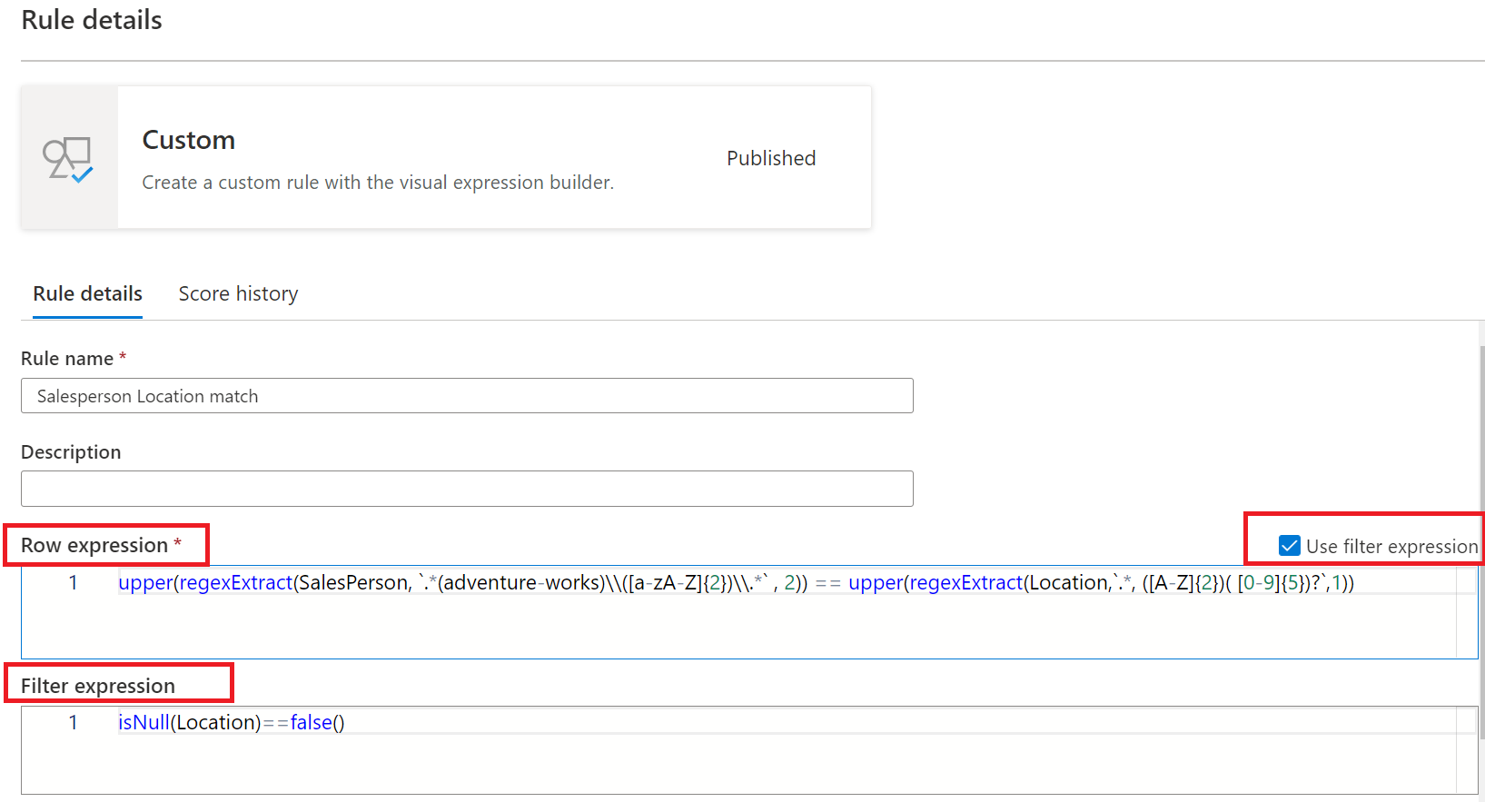
カスタム ルールの例
| シナリオ | 行式 |
|---|---|
| state_idがカリフォルニアと等しく、aba_Routing_Numberが特定の正規表現パターンと一致し、生年月日が特定の範囲に収まるかどうかを検証します | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| VendorID が 124 に等しいかどうかを確認する | {VendorID}=='124' |
| fare_amountが 100 以上かどうかを確認する | {fare_amount} >= "100" |
| fare_amountが 100 より大きく、tolls_amountが 100 に等しくないかどうかを検証します | {fare_amount} >= "100" || {tolls_amount} != "400" |
| レーティングが 5 未満かどうかを確認する | Rating < 5 |
| 年の桁数が 4 であるかどうかを確認する | length(toString(year)) == 4 |
| 2 つの列 bbToLoanRatio と bankBalance を比較し、値が等しい場合はチェックします | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| firstName、lastName、LoanID、uuid のトリミングおよび連結された文字数が 20 を超えるかどうかを確認する | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| aba_Routing_Numberが特定 の 正規表現パターンと一致し、最初のトランザクション日付が 2022-11-12 より大きく、 Disallow-Listed が false で、平均 bankBalance が 50000 を超え、 state_id が 'Massachuse'、'テネシー'、'North Dakota' または 'Albama' と等しいことを確認します | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| aba_Routing_Numberが特定 の 正規表現パターンと一致し、 dateOfBirth が 1968-12-13 から 2020-12-13 の間にあるかどうかを検証します | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| aba_Routing_Numberの一意の値の数が 1,000,000 に等しく、EMAIL_ADDRの一意の値の数が 1,000,000 に等しいかどうかを確認します | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
フィルター式と行式の両方は、ここで定義されている言語でここで紹介するAzure Data Factory式言語を使用して定義されます。 ただし、ジェネリック ADF 式言語に対して定義されているすべての関数が使用できるわけではありません。 使用可能な関数の完全な一覧は、式ダイアログで使用できる関数の一覧にあります。 ここで定義されている次の関数はサポートされていません。isDelete、isError、isIgnore、isInsert、isMatch、isUpdate、isUpsert、partitionId、cached lookup、Window 関数。
注:
<regex> (バッククォート) は、特殊文字をエスケープせずに文字列を一致させるために、カスタム ルールに含まれる正規表現で使用できます。 正規表現言語は Java に基づいており、 ここで指定したとおりに動作します。
このページ では、エスケープする必要がある文字を識別します。
AI 支援自動生成ルール
データ品質測定のための AI 支援の自動ルール生成には、人工知能 (AI) 手法を使用して、データの品質を評価および改善するためのルールを自動的に作成する必要があります。 自動生成されたルールはコンテンツ固有です。 一般的なルールのほとんどは自動的に生成されるため、ユーザーはカスタム ルールを作成するためにそれほど手間をかける必要はありません。
自動生成されたルールを参照して適用するには:
- [ ルール ] ページで [ルールの提案] を選択します。
- 推奨されるルールの一覧を参照します。
![[ルールの提案] ボタンが強調表示されている資産の [ルール] タブのスクリーンショット。](media/concept-data-quality-rules/suggest-rule-main.png#lightbox)
- 推奨されるルールの一覧からルールを選択して、データ資産に適用します。

次の手順
- データ製品でデータ品質スキャンを構成して実行 し、データ製品でサポートされているすべての資産の品質を評価します。
- スキャン結果を確認 して、データ製品の現在のデータ品質を評価します。