高速 R-CNN を使用した物体検出
目次
まとめ

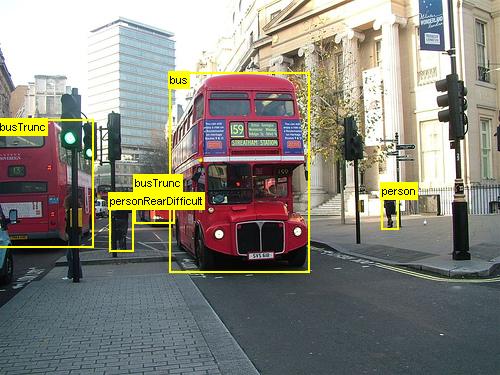
上記は、このチュートリアルで使用する Grocery データ セット (左) と Pascal VOC データ セット (右) の画像とオブジェクト注釈の例です。
高速 R-CNN は、2015 年に Shaoqing Ren、Kaiming He、Ross Girshick、Jian Sun によって提案された物体検出アルゴリズムです。 研究論文は「より高速なR-CNN:リージョン提案ネットワークを使用したReal-Time物体検出に向けて」と題され、アーカイブされています https://arxiv.org/abs/1506.01497. 以前の作業に基づく R-CNN のビルドを高速化し、深い畳み込みネットワークを使用してオブジェクト提案を効率的に分類します。 以前の作業と比較して、より高速な R-CNN は リージョン提案ネットワーク を採用しており、候補リージョンの提案に外部の方法を必要としません。
このチュートリアルは、3 つの主要なセクションに構成されています。 最初のセクションでは、提供されているサンプル データ セットで CNTK で Faster R-CNN を実行する方法について簡潔に説明します。 2 番目のセクションでは、高速 R-CNN のセットアップとパラメーター化を含むすべての手順について詳しく説明します。 最後のセクションでは、アルゴリズムとリージョン提案ネットワークの技術的な詳細、入力データの読み取りと拡張、および高速 R-CNN のさまざまなトレーニング オプションについて説明します。
クイック スタート
このセクションでは、CNTK Python API を使用するようにシステムを設定していることを前提としています。 さらに、Windows では Python 3.5、Linux では 3.5/3.6 を使用していることを前提としています。 詳細な手順については、 手順を参照してください。 高速 R-CNN を実行するには、cntk Python 環境に次の追加パッケージをインストールしてください
pip install opencv-python easydict pyyaml
おもちゃの例を実行する
冷蔵庫からキャプチャした画像のおもちゃのデータセットを使用して、高速 R-CNN を示します (Fast R-CNN の例と同じです)。 データセットと事前トレーニング済みの AlexNet モデルの両方をダウンロードするには、Examples/Image/Detection/FastRCNN フォルダーから次の Python コマンドを実行します。
python install_data_and_model.py
スクリプトを実行すると、おもちゃのデータセットがフォルダーの下に Examples/Image/DataSets/Grocery インストールされます。 AlexNet モデルがフォルダーに PretrainedModels ダウンロードされます。
既定では、構成ファイルがその場所を想定しているため、ダウンロードしたデータはそれぞれのフォルダーに保持することをお勧めします。
R-CNN 実行の高速化をトレーニングして評価するには
python run_faster_rcnn.py
基本モデルとして AlexNet を使用した食料品に関するエンドツーエンドのトレーニングの結果は、次のようになります。
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
フォルダーから開 FasterRCNN_config.py いて設定した画像の予測境界ボックスとラベルを FasterRCNN 視覚化するには
__C.VISUALIZE_RESULTS = True
実行すると、イメージがフォルダーpython run_faster_rcnn.pyにFasterRCNN/Output/Grocery/保存されます。
詳細な手順
セットアップ
この例のコードを実行するには、CNTK Python 環境が必要です (セットアップのヘルプについては 、こちらを 参照してください)。 cntk Python 環境に次の追加パッケージをインストールしてください
pip install opencv-python easydict pyyaml
境界ボックス回帰と非最大抑制用の事前コンパイル済みバイナリ
このフォルダー Examples\Image\Detection\utils\cython_modules には、高速 R-CNN を実行するために必要な事前コンパイル済みバイナリが含まれています。 リポジトリに現在含まれているバージョンは、Windows 用 Python 3.5、Python 3.5、Linux 用 3.6、すべて 64 ビットです。 別のバージョンが必要な場合は、次の手順に従ってコンパイルできます。
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
生成された cython_bbox バイナリと cpu_nms (または gpu_nms) バイナリのコピー元を $FRCN_ROOT/lib/utils コピーします $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules。
データとベースライン モデルの例
事前トレーニング済みの AlexNet モデルを Faster-R-CNN トレーニングの基礎として使用します (VGG またはその他の基本モデルの場合は、 別の基本モデルの使用を参照してください。 サンプル データセットと事前トレーニング済みの AlexNet モデルの両方をダウンロードするには、 FastRCNN フォルダーから次の Python コマンドを実行します。
python install_data_and_model.py
- 別の基本モデルを使用する方法について説明します
- Pascal VOC データで高速 R-CNN を実行する方法について説明します
- 独自のデータで高速 R-CNN を実行する方法について説明します
構成とパラメーター
パラメーターは、次の 3 つの部分にグループ化されます。
- 検出パラメーター (参照
FasterRCNN/FasterRCNN_config.py) - データ セット パラメーター (例
utils/configs/Grocery_config.pyを参照) - 基本モデル パラメーター (例
utils/configs/AlexNet_config.pyを参照)
3 つの部分が読み込まれ、メソッドrun_faster_rcnn.pyにget_configuration()マージされます。 このセクションでは、検出パラメーターについて説明します。 データ セット パラメーターについては 、ここで説明します。基本モデル パラメーター については、ここで説明します。 以下では、上から下の内容 FasterRCNN_config.py を見ていきます。 この構成では、 EasyDict 入れ子になったディクショナリに簡単にアクセスできるパッケージが使用されます。
# If set to 'True' training will be skipped if a trained model exists already
__C.CNTK.MAKE_MODE = False
# E2E or 4-stage training
__C.CNTK.TRAIN_E2E = True
# set to 'True' to use deterministic algorithms
__C.CNTK.FORCE_DETERMINISTIC = False
# set to 'True' to run only a single epoch
__C.CNTK.FAST_MODE = False
# Debug parameters
__C.CNTK.DEBUG_OUTPUT = False
__C.CNTK.GRAPH_TYPE = "png" # "png" or "pdf"
# Set to True if you want to store an eval model with native UDFs (e.g. for inference using C++ or C#)
__C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = False
パラメーターの最初のブロックには、トレーニング プロセスに関するより高いレベルの命令が含まれています。 __C.CNTK.TRAIN_E2E では、エンド ツー エンドまたは 4 段階のトレーニング スキームを選択できます。 ここでは、2 つのトレーニング スキームの詳細について説明 します。 __C.CNTK.FAST_MODE = True 1 つのエポックのみを実行します。セットアップが機能していて、すべてのパラメーターが正しいかどうかをテストすると便利です。 __C.CNTK.DEBUG_OUTPUT = True では、コンソール出力に追加のデバッグ メッセージが生成されます。 また、トレーニング モデルと eval モデルの両方について CNTK 計算グラフをプロットします ( CNTK グラフをプロットするための要件に注意してください)。 結果のグラフはフォルダーに FasterRCNN/Output 格納されます。 __C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = True では、ネイティブ コードのみを使用する 2 つ目の評価モデルが格納されます (Python レイヤーは使用しません)。 このモデルは、たとえば C++ または C# から読み込んで評価できます。
# Learning parameters
__C.CNTK.L2_REG_WEIGHT = 0.0005
__C.CNTK.MOMENTUM_PER_MB = 0.9
# The learning rate multiplier for all bias weights
__C.CNTK.BIAS_LR_MULT = 2.0
# E2E learning parameters
__C.CNTK.E2E_MAX_EPOCHS = 20
__C.CNTK.E2E_LR_PER_SAMPLE = [0.001] * 10 + [0.0001] * 10 + [0.00001]
2 番目のブロックには、学習パラメーターが含まれています。 これらは主に通常の CNTK 学習パラメーターです。 唯一の例外は __C.CNTK.BIAS_LR_MULT、ネットワーク内のすべてのバイアスに使用される学習率乗数です。 これは基本的に、現在の学習率の 2 倍のバイアスをトレーニングします。これは、元の高速 R-CNN コードでも行われます。 サンプルあたりのエポック数と学習率は、2 つの異なる学習スキーム (上で省略した 4 段階のパラメーター) に対して個別に指定されます。
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Sigma parameter for smooth L1 loss in the RPN and the detector (DET)
__C.SIGMA_RPN_L1 = 3.0
__C.SIGMA_DET_L1 = 1.0
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# all bounding boxes with a score lower than this threshold will be considered background
__C.RESULTS_NMS_CONF_THRESHOLD = 0.0
# Enable plotting of results generally / also plot background boxes / also plot unregressed boxes
__C.VISUALIZE_RESULTS = False
__C.DRAW_NEGATIVE_ROIS = False
__C.DRAW_UNREGRESSED_ROIS = False
# only for plotting results: boxes with a score lower than this threshold will be considered background
__C.RESULTS_BGR_PLOT_THRESHOLD = 0.1
__C.INPUT_ROIS_PER_IMAGE は、画像ごとのグラウンド トゥルース注釈の最大数を指定します。 現在、CNTK では最大数を設定する必要があります。 注釈が少ない場合は、内部的に埋め込まれます。 __C.IMAGE_WIDTH は __C.IMAGE_HEIGHT 、入力イメージのサイズ変更と埋め込みに使用されるディメンションです。 __C.RESULTS_NMS_THRESHOLD は、評価で重複する予測境界ボックスを破棄するために使用される NMS しきい値です。 しきい値を小さくすると、削除が少なくなり、最終的な出力で予測される境界ボックスが増えます。
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
# RPN parameters
# IOU >= thresh: positive example
__C.TRAIN.RPN_POSITIVE_OVERLAP = 0.7
# IOU < thresh: negative example
__C.TRAIN.RPN_NEGATIVE_OVERLAP = 0.3
# If an anchor statisfied by positive and negative conditions set to negative
__C.TRAIN.RPN_CLOBBER_POSITIVES = False
# Max number of foreground examples
__C.TRAIN.RPN_FG_FRACTION = 0.5
# Total number of examples
__C.TRAIN.RPN_BATCHSIZE = 256
# NMS threshold used on RPN proposals
__C.TRAIN.RPN_NMS_THRESH = 0.7
# Number of top scoring boxes to keep before apply NMS to RPN proposals
__C.TRAIN.RPN_PRE_NMS_TOP_N = 12000
# Number of top scoring boxes to keep after applying NMS to RPN proposals
__C.TRAIN.RPN_POST_NMS_TOP_N = 2000
# Proposal height and width both need to be greater than RPN_MIN_SIZE (at orig image scale)
__C.TRAIN.RPN_MIN_SIZE = 16
__C.TRAIN.USE_FLIPPED = True は、すべての画像を他のすべてのエポックに反転することでトレーニング データを強化します。つまり、最初のエポックにはすべての通常の画像があり、2 番目のエポックにはすべての画像が反転されます。 __C.TRAIN_CONV_LAYERS は、入力から畳み込みフィーチャ マップまでの畳み込みレイヤーをトレーニングするか固定するかを決定します。 conv レイヤーの重みを固定することは、基本モデルからの重みが取得され、トレーニング中に変更されないことを意味します。 (トレーニングする conv レイヤーの数を指定することもできます。 「別の基本モデルの使用」セクションを参照してください)。 rpnパラメータについては、定義の横にあるコメントを参照するか、詳細については元の研究論文を参照してください。 また、次のディテクタ パラメーターの場合も同様です。
# Detector parameters
# Minibatch size (number of regions of interest [ROIs]) -- was: __C.TRAIN.BATCH_SIZE = 128
__C.NUM_ROI_PROPOSALS = 128
# Fraction of minibatch that is labeled foreground (i.e. class > 0)
__C.TRAIN.FG_FRACTION = 0.25
# Overlap threshold for an ROI to be considered foreground (if >= FG_THRESH)
__C.TRAIN.FG_THRESH = 0.5
# Overlap threshold for an ROI to be considered background (class = 0 if
# overlap in [LO, HI))
__C.TRAIN.BG_THRESH_HI = 0.5
__C.TRAIN.BG_THRESH_LO = 0.0
# Normalize the targets using "precomputed" (or made up) means and stdevs
__C.BBOX_NORMALIZE_TARGETS = True
__C.BBOX_NORMALIZE_MEANS = (0.0, 0.0, 0.0, 0.0)
__C.BBOX_NORMALIZE_STDS = (0.1, 0.1, 0.2, 0.2)
Pascal VOC で R-CNN をより高速に実行する
Pascal データをダウンロードし、CNTK 形式で Pascal の注釈ファイルを作成するには、次のスクリプトを実行します。
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
のdataset_cfg方法run_faster_rcnn.pyをget_configuration()変更します。
from utils.configs.Pascal_config import cfg as dataset_cfg
これで、Pascal VOC 2007 データを使用して python run_faster_rcnn.pyトレーニングするように設定されています。 トレーニングに時間がかかる場合があることに注意してください。
独自のデータで高速な R-CNN を実行する
独自のデータを準備し、グラウンド トゥルース境界ボックスで注釈を付ける方法については、 高速 R-CNN を使用した物体検出で説明されています。 説明したフォルダー構造にイメージを格納し、それらに注釈を付けた後、実行してください
python Examples/Image/Detection/utils/annotations/annotations_helper.py
そのスクリプト内のフォルダーをデータ フォルダーに変更した後。 最後に、このコード スニペットのように、既存のutils\configs例に従ってフォルダーに作成MyDataSet_config.pyします。
...
# data set config
__C.DATA.DATASET = "YourDataSet"
__C.DATA.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.DATA.CLASS_MAP_FILE = "class_map.txt"
__C.DATA.TRAIN_MAP_FILE = "train_img_file.txt"
__C.DATA.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.DATA.TEST_MAP_FILE = "test_img_file.txt"
__C.DATA.TEST_ROI_FILE = "test_roi_file.txt"
__C.DATA.NUM_TRAIN_IMAGES = 500
__C.DATA.NUM_TEST_IMAGES = 200
__C.DATA.PROPOSAL_LAYER_SCALES = [8, 16, 32]
...
__C.CNTK.PROPOSAL_LAYER_SCALESは (参照utils/rpn/generate_anchors.py) でgenerate_anchors()使用されます。 縦横比0.5, 1.0を持つ 3 つのアンカーの16基本サイズから開始し2.0、結果として (8 x 24, 16 x 16, 24 x 8) が作成されます。 これらは、各提案レイヤースケールと乗算され、9 つのアンカー (64 x 192....、 768 x 256) になります。 これらは、入力画像の絶対ピクセル座標 w.r.t です。 すべてのアンカーは、畳み込みフィーチャ マップの各空間位置に適用され、関心のある候補領域が生成されます。 データ セット内のオブジェクト サイズと、使用している入力イメージ サイズに応じて、これらの提案レイヤーのスケールを調整します。 たとえば、使用 __C.DATA.PROPOSAL_LAYER_SCALES = [4, 8, 12] している Grocery データ セットと入力画像サイズ 850 x 850 (参照 utils/configs/Grocery_config.py) などです。
データに対する高速 R-CNN のトレーニングと評価を行う場合は、dataset_cfg次のrun_faster_rcnn.py方法でget_configuration()変更します。
from utils.configs.MyDataSet_config import cfg as dataset_cfg
を実行 python run_faster_rcnn.pyします。
技術詳細
ほとんどの DNN ベースのオブジェクト検出機能により、高速 R-CNN は転送学習を使用します。 これは、画像分類用にトレーニングされたモデルである基本モデルから始まります。 基本モデルは 2 つの部分に切り取られ、最初の 1 つは最後のプーリング レイヤーまでのすべての畳み込みレイヤーであり、2 番目の部分は最後のプール レイヤーから最終的な予測レイヤーまでのネットワークの残りの部分 (および最終予測レイヤーを除く) です。 最初の部分の出力は、 畳み込みフィーチャ マップと呼ばれることもあります。 これは roi プーリング レイヤーへの入力として使用されます。これは、元の画像のリージョン提案に対応する入力マップの一部に対してプール操作を実行します。 リージョン提案は、roi プーリング レイヤーへの 2 番目の入力です。 高速 R-CNN では、これらの提案は リージョン提案 ネットワークと呼ばれる小さなサブネットワークによって生成されます (RPN、次のセクションを参照)。
roi プーリング レイヤーの出力は、入力 (畳み込みフィーチャ マップ + リージョン提案) を同じ出力サイズにプールするため、常に同じ固定サイズになります。 入力サイズ、つまり畳み込み featute マップのサイズ、したがって入力画像のサイズは任意であることに注意してください。 アルゴリズムのトレーニングでは、RPN に 2 つ、検出器に 2 つの 4 つの損失関数を使用します (次のセクションも参照)。 次の方法が含まれており FasterRCNN_train.py 、高速 R-CNN モデルの高レベルの構築を示しています。 完全なコードを FasterRCNN_train.py 参照してください utils/rpn/rpn_helpers.py 。
def create_faster_rcnn_model(features, scaled_gt_boxes, dims_input, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# RPN and prediction targets
rpn_rois, rpn_losses = create_rpn(conv_out, scaled_gt_boxes, dims_input, cfg)
rois, label_targets, bbox_targets, bbox_inside_weights = \
create_proposal_target_layer(rpn_rois, scaled_gt_boxes, cfg)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg)
detection_losses = create_detection_losses(...)
loss = rpn_losses + detection_losses
pred_error = classification_error(cls_score, label_targets, axis=1)
return loss, pred_error
トレーニング後、ネットワークは評価に必要でないすべてのパーツ (たとえば、損失関数) を削除して評価モデルに変換されます。 最終的な評価モデルには 3 つの出力があります (詳細については、FasterRCNN_train.py以下を参照してくださいcreate_faster_rcnn_eval_model())。
rpn_rois- 候補 rois の絶対ピクセル座標cls_pred- 各 ROI のクラス確率bbox_regr- 各 ROI の クラスごとの 回帰係数
Python から評価モデルを使用するには、次FasterRCNN_eval.pyのコードをFasterRCNN_Evaluator使用できます。 モデルを 1 回読み込んでから、1 つの画像を評価できます。 エバリュエーターのメソッドは process_image() 、イメージへのパスを引数として受け取り、そのイメージのモデルを評価し、結果の ROI に境界ボックス回帰を適用します。 これは、回帰された ROI と対応するクラス確率を返します。
evaluator = FasterRCNN_Evaluator(model, cfg)
regressed_rois, cls_probs = evaluator.process_image(img_path)
リージョン提案ネットワーク
高速 R-CNN では、いわゆる リージョン提案 netwrok (RPN) が使用され、入力イメージに基づいて関心のある候補領域 (ROIs) が生成されます。 これは、外部ソースからリージョンの提案を提供する必要がある高速 R-CNN とは対照的です。 RPN は、基本的に 3 つの畳み込みレイヤーと 提案レイヤーと呼ばれる新しいレイヤーによって構築されます。 新しいレイヤーは、Python または C++ のユーザー定義関数 (UDF) として実現されます (詳細については、以下を参照してください)。 CNTK で RPN を作成する Python コードは utils/rpn/rpn_helpers.py、提案レイヤーなどの新しいレイヤーがすべてフォルダー内にあります utils/rpn 。
RPN への入力は、ROI プール レイヤーへの入力と同じ、畳み込みフィーチャ マップです。 この入力は RPN の最初の畳み込み層に送られ、結果は他の 2 つの畳み込み層に伝達されます。 後者の 1 つは、候補領域ごとにクラス スコア、つまり各空間位置のアンカーごとにクラス スコアを予測します (9 アンカー x 2 スコア x 幅 x 高さ)。 2 つのスコアは 、(softmax ノードを使用して) 候補ごとの オブジェクト性スコア に変換されます。これは、前景オブジェクトを含むかどうかの候補領域の確率として解釈されます。 もう 1 つの畳み込みレイヤーは、ROI の実際の位置に対する回帰係数を予測し、各候補について再度予測します (9 アンカー x 4 係数 x 幅 x 高さ)。
回帰係数とオブジェクト性スコア (前景と背景の確率) が提案レイヤーに送られます。 このレイヤーはまず、生成されたアンカーに回帰係数を適用し、結果を画像の境界にクリップし、小さすぎる候補領域を除外します。 次に、前景確率で候補を並べ替え、非最大抑制 (NMS) を適用して候補の数を減らし、最終的にその出力に必要な数の ROI をサンプリングします。
トレーニング中に、より高速な R-CNN には、 アンカー ターゲット レイヤーと提案ターゲット レイヤー という 2 つの新しい レイヤーが必要です。 アンカー ターゲット レイヤーは、RPN の損失関数で使用されるオブジェクトネス スコアと RPN 回帰係数のターゲット値を生成します。 同様に、提案ターゲット レイヤーは、ROIs のターゲット クラス ラベルと、検出機能の損失関数で使用される最終的な検出機能のクラスごとのターゲット回帰係数を生成します。
評価中は、提案レイヤーのみが必要です (損失関数のターゲットは必要ないため)。 CNTK の提案レイヤーは Python と C++ で使用でき、ターゲット レイヤーは現在 Python でのみ使用できます。 したがって、現在、Python API から高速 R-CNN のトレーニングを行う必要があります。 ネイティブ提案レイヤー実装セット __C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = Trueを使用するトレーニング後に評価モデルを格納するには、
リーダーとミニバッチ ソース
データ拡張のためにイメージをスケーリングしたり、画像を反転したりする場合は、グラウンド トゥルース注釈にも同じ変換を適用する必要があります。 (反転は、4 段階のトレーニングでキャッシュされた提案にも適用する必要があります。次のセクションを参照してください)。これらの結合された画像と注釈の変換は、現在、組み込みの CNTK リーダーではサポートされていないため、カスタム Python リーダーと UserMinibatchSource 高速 R-CNN を使用します。 これらはそれぞれにutils/od_reader.pyutils/od_mb_source.py含まれています。
E2E と 4 段階のトレーニング
高速 R-CNN の研究論文では、ネットワークをトレーニングする 2 つの方法について説明します。 エンドツーエンドのトレーニングでは、4 つの損失関数 (rpn 回帰損失、rpn 物体性損失、検出器回帰損失、検出器クラス損失) をすべて使用して、1 つのトレーニングでネットワーク全体をトレーニングします。 既定ではエンド ツー エンド トレーニングを使用します。この 2 つから選択するには、それに応じてFasterRCNN_config.py設定__C.CNTK.TRAIN_E2Eします。
4 段階のトレーニング スキームでは、リージョン提案ネットワークのみをトレーニングし (検出器を固定したまま)、検出器のみをトレーニング (RPN ウェイトを固定) します。 このトレーニングスキームはで実装されていますtrain_faster_rcnn_alternating()FasterRCNN_train.py. これは少し複雑で、モデルの複製部分を頻繁に使用して、凍結とトレーニングの重みを選択的に有効にします。 また、4段階のトレーニングでは、RPNからの提案はステージ1と3の後にバッファリングされ、後続のステージで使用されます。
別の基本モデルを使用する
別の基本モデルを使用するには、次の方法で別のrun_faster_rcnn.pyモデル構成を選択するget_configuration()必要があります。 すぐに 2 つのモデルがサポートされます。
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
VGG16 モデルをダウンロードするには、次のダウンロード スクリプト <cntkroot>/PretrainedModelsを使用してください。
python download_model.py VGG16_ImageNet_Caffe
別の異なる基本モデルを使用する場合は、たとえば、構成ファイル utils/configs/VGG16_config.py をコピーし、ベース モデルに従って変更する必要があります。
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
基本モデルのノード名を調査するには、次のメソッドcntk.logging.graphをplot()使用します。 CNTK での roi プールはまだ roi 平均プーリングをサポートしていないため、ResNet モデルは現在サポートされていないことに注意してください。