Azure portal を使用して、Azure Data Lake Storage Gen1 を使用する HDInsight クラスターを作成する
Azure portal を使用して、既定のストレージまたは追加のストレージとして Azure Data Lake Storage Gen1 を使用する HDInsight クラスターを作成する方法を説明します。 追加のストレージは HDInsight クラスターでは省略可能ですが、業務データは追加のストレージ アカウントに格納することをお勧めします。
前提条件
開始する前に、次の要件を満たしていることを確認します。
- Azure サブスクリプション。 Azure 無料試用版の取得に関するページをご覧ください。
- Azure Data Lake Storage Gen1 アカウント。 「Azure portal で Azure Data Lake Storage Gen1 の使用を開始する」の手順に従ってください。 アカウントのルート フォルダーも作成する必要があります。 この記事では、 /clusters という名前のルート フォルダーを使用します。
- Microsoft Entra サービス プリンシパル。 このハウツー ガイドでは、Microsoft Entra IDでサービス プリンシパルを作成する方法について説明します。 ただし、サービス プリンシパルを作成するには、Microsoft Entra管理者である必要があります。 管理者である場合は、この前提条件をスキップして続行することができます。
注意
サービス プリンシパルは、Microsoft Entra管理者の場合にのみ作成できます。 Data Lake Storage Gen1を使用して HDInsight クラスターを作成するには、Microsoft Entra管理者がサービス プリンシパルを作成する必要があります。 また、「証明書を使用したサービス プリンシパルの作成」で説明しているように、サービス プリンシパルは証明書を使って作成する必要があります。
HDInsight クラスターの作成
このセクションでは、既定のまたは追加のストレージとして Data Lake Storage Gen1 を使用する HDInsight クラスターを作成します。 この記事では、Data Lake Storage Gen1 の構成の一部のみを取り上げます。 一般的なクラスターの作成に関する情報および手順については、HDInsight での Hadoop クラスターの作成に関するページを参照してください。
Data Lake Storage Gen1 を既定のストレージとして使用してクラスターを作成する
既定のストレージ アカウントとして Data Lake Storage Gen1 を使用する HDInsight クラスターを作成するには:
Azure portal にサインインする
HDInsight クラスターの作成に関する一般的な情報については、「クラスターの作成」を参照してください。
[ストレージ] ブレードの [プライマリ ストレージの種類] で、 [Azure Data Lake Storage Gen1] を選択して、次の情報を入力します。
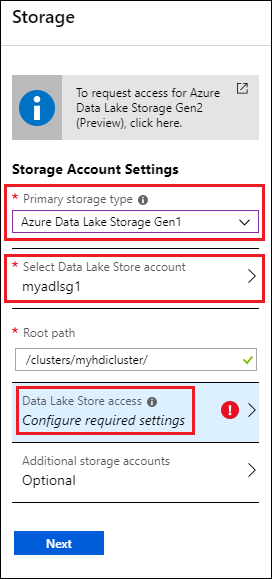
- [Data Lake Store アカウントを選択する] : 既存の Data Lake Storage Gen1 アカウントを選択します。 既存の Data Lake Storage Gen1 アカウントが必要です。 「前提条件」を参照してください。
- [ルート パス] : クラスターに固有のファイルが格納されるパスを入力します。 このスクリーン ショットでは、 /clusters/myhdiadlcluster/ です。この場合、 /clusters フォルダーが存在する必要があり、Portal では myhdicluster フォルダーが作成されます。 myhdicluster がクラスター名です。
- [Data Lake Store アクセス] : Data Lake Storage Gen1 アカウントと HDInsight クラスターの間のアクセスを構成します。 手順については、「Data Lake Storage Gen1 のアクセスの構成」を参照してください。
- [追加のストレージ アカウント] : クラスターの追加のストレージ アカウントとして Azure ストレージ アカウントを追加します。 Data Lake Storage Gen1 アカウントの追加は、プライマリ ストレージ タイプとして Data Lake Storage Gen1 アカウントを構成する際に、他の Data Lake Storage Gen1 アカウントのデータに対するクラスターのアクセス許可を与えることで完了します。 「Data Lake Storage Gen1 のアクセスの構成」を参照してください。
[Data Lake Store アクセス] で、 [選択] をクリックし、HDInsight での Hadoop クラスターの作成に関するページの説明に従ってクラスターの作成に進みます。
Data Lake Storage Gen1 を追加のストレージとして使用してクラスターを作成する
次の手順で、既定のストレージとして Azure Blob ストレージ アカウントを使い、追加のストレージとして Data Lake Storage Gen1 を使用するストレージ アカウントを使って HDInsight クラスターを作成します。
Data Lake Storage Gen1 を追加のストレージ アカウントとして使用する HDInsight クラスターを作成するには:
Azure portal にサインインする
HDInsight クラスターの作成に関する一般的な情報については、「クラスターの作成」を参照してください。
[ストレージ] ブレードの [プライマリ ストレージの種類] で、 [Azure Storage] を選択して、次の情報を入力します。
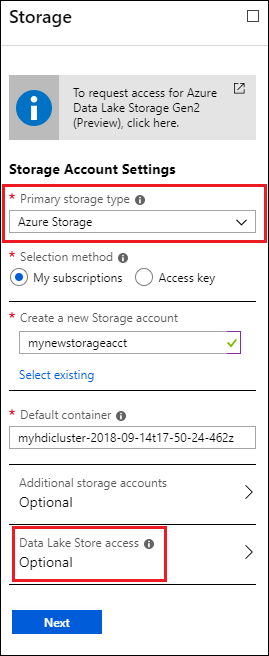
選択方法 - Azure サブスクリプションの一部であるストレージ アカウントを指定するには、[個人用サブスクリプション] を選択し、ストレージ アカウントを選択します。 Azure サブスクリプションの外部にあるストレージ アカウントを指定するには、アクセス キー を選択し、外部のストレージ アカウントの情報を入力します。
[既定のコンテナー] - 既定値を使用するか、独自の名前を指定します。
[追加のストレージ アカウント] - 追加のストレージとして Azure ストレージ アカウントを追加します。
[Data Lake Store アクセス] - Data Lake Storage Gen1 アカウントと HDInsight クラスターの間のアクセスを構成します。 手順については、「Data Lake Storage Gen1 のアクセスの構成」を参照してください。
Data Lake Storage Gen1 のアクセスの構成
このセクションでは、Microsoft Entra サービス プリンシパルを使用して HDInsight クラスターからのData Lake Storage Gen1アクセスを構成します。
サービス プリンシパルの指定
Azure Portal から、既存のサービス プリンシパルを使用するか、新しいものを作成することができます。
Azure portal からサービス プリンシパルを作成するには:
- 「Microsoft Entra IDを使用してサービス プリンシパルと証明書を作成する」を参照してください。
Azure portal から既存のサービス プリンシパルを使用するには:
サービス プリンシパルには、ストレージ アカウントの所有者権限を与える必要があります。 サービス プリンシパルをストレージ アカウントの所有者にする権限を設定する方法に関するページを参照してください。
[Data Lake Store アクセス] を選択します。
[Data Lake Storage Gen1 アクセス] ブレードで、[既存のものを使用] を選択します。
[サービス プリンシパル] を選択し、サービス プリンシパルを選択します。
選択したサービス プリンシパルに関連付けられている証明書 (.pfx ファイル) をアップロードし、証明書のパスワードを入力します。
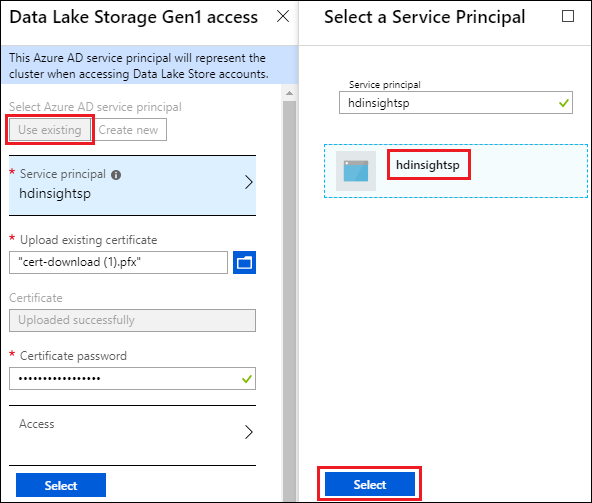
[アクセス] を選択して、フォルダーへのアクセスを構成します。 「ファイルのアクセス許可を構成する」を参照してください。
サービス プリンシパルをストレージ アカウントの所有者にする権限を設定する
- ストレージ アカウントの [アクセス制御 (IAM)] ブレードで [ロールの割り当てを追加する] をクリックします。
- [ロールの割り当てを追加する] ブレードで、ロールとして "所有者" を選択し、SPN を選択し、[保存] をクリックします。
ファイルのアクセス許可を構成する
構成は、アカウントを既定のストレージとして使用するか、追加のストレージ アカウントとして使用するかによって異なります。
既定のストレージとして使用する
- Data Lake Storage Gen1 アカウントのルート レベルでのアクセス許可
- HDInsight クラスター記憶域のルート レベルでのアクセス許可。 たとえば、このチュートリアルで使用した /clusters フォルダー。
追加のストレージとして使用する
- ファイル アクセスが必要なフォルダーのアクセス許可。
Data Lake Storage Gen1 を使用するストレージ アカウントのルート レベルでアクセス許可を割り当てるには:
[Data Lake Storage Gen1 アクセス] ブレードで、[アクセス] を選択します。 [ファイル アクセス許可の選択] ブレードが開きます。 サブスクリプション内のすべてのストレージ アカウントが一覧表示されます。
Data Lake Storage Gen1 を使用するアカウント名の上にマウス ポインターを置いて (クリックしないでください) チェック ボックスを表示し、そのチェック ボックスを選択します。
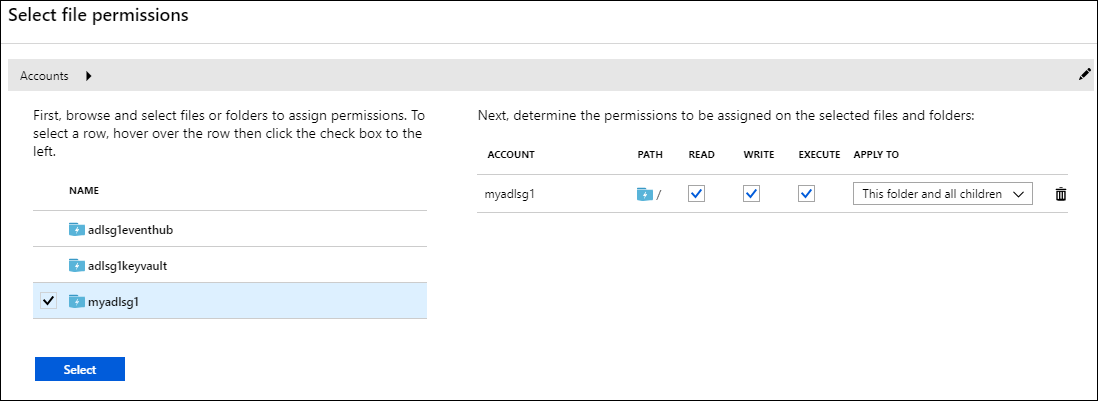
既定では、 [読み取り] 、 [書き込み] 、 [実行] がすべて選択されています。
ページの下部にある [選択] をクリックします。
[実行] を選択して、アクセス許可を割り当てます。
[Done] を選択します。
HDInsight クラスターのルート レベルでアクセス許可を割り当てるには:
- [Data Lake Storage Gen1 アクセス] ブレードで、[アクセス] を選択します。 [ファイル アクセス許可の選択] ブレードが開きます。 サブスクリプション内のすべての Data Lake Storage Gen1 を使用するストレージ アカウントが一覧表示されます。
- [ファイル アクセス許可の選択] ブレードで、Data Lake Storage Gen1 を使用するストレージ アカウントの名前を選択して、その内容を表示します。
- フォルダーの左側のチェック ボックスを選択して HDInsight クラスター記憶域のルートを選択します。 前のスクリーンショットでは、クラスター記憶域のルートは、Data Lake Storage Gen1 を既定のストレージとして選択したときに指定した /clusters フォルダーです。
- フォルダーのアクセス許可を設定します。 既定では、[読み取り]、[書き込み]、[実行] がすべて選択されています。
- ページの下部にある [選択] をクリックします。
- [実行] を選択します。
- [Done] を選択します。
Data Lake Storage Gen1 を追加のストレージとして使用している場合は、HDInsight クラスターからアクセスするフォルダーに対してのみアクセス許可を割り当てる必要があります。 たとえば、次のスクリーンショットでは、Data Lake Storage Gen1 を使用するストレージ アカウントの mynewfolder フォルダーへのアクセスのみを提供します。
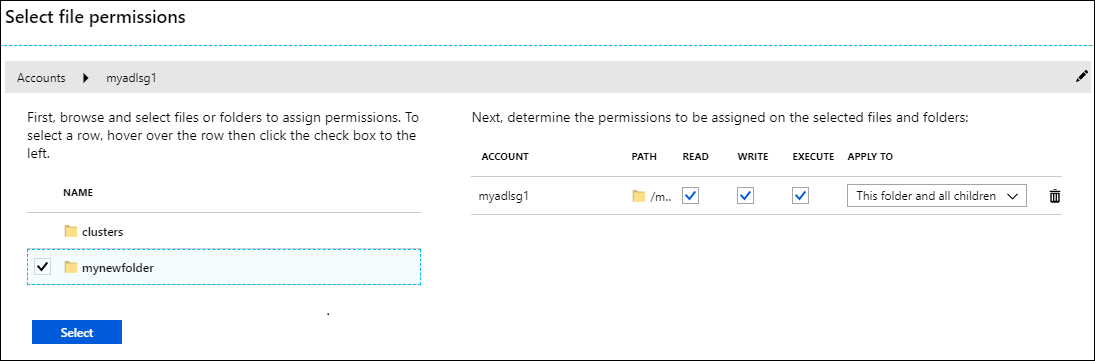
クラスター設定の確認
クラスターのセットアップが完了したら、クラスター ブレードで、次の手順のいずれかまたは両方を実行して結果を確認します。
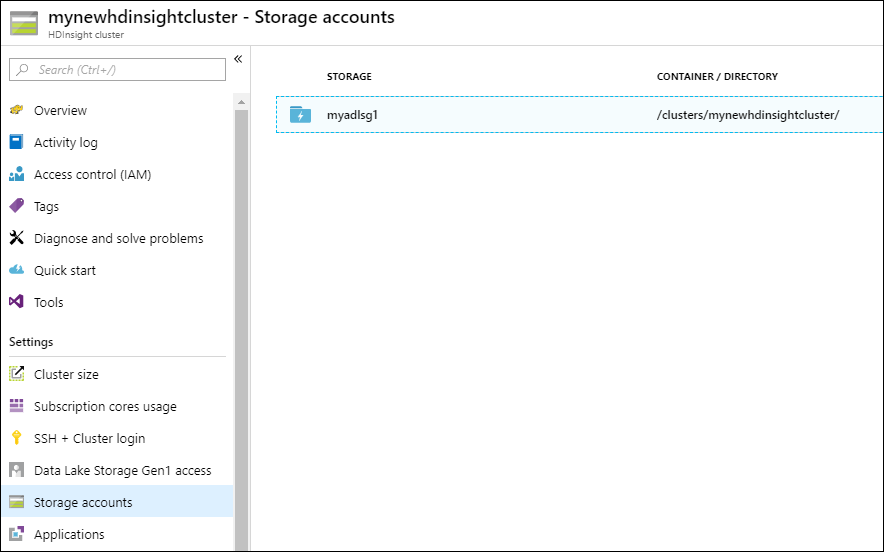
クラスターに関連付けられているストレージが、指定した Data Lake Storage Gen1 を使用するストレージ アカウントであることを確認するには、左側のペインで [ストレージ アカウント] を選択します。
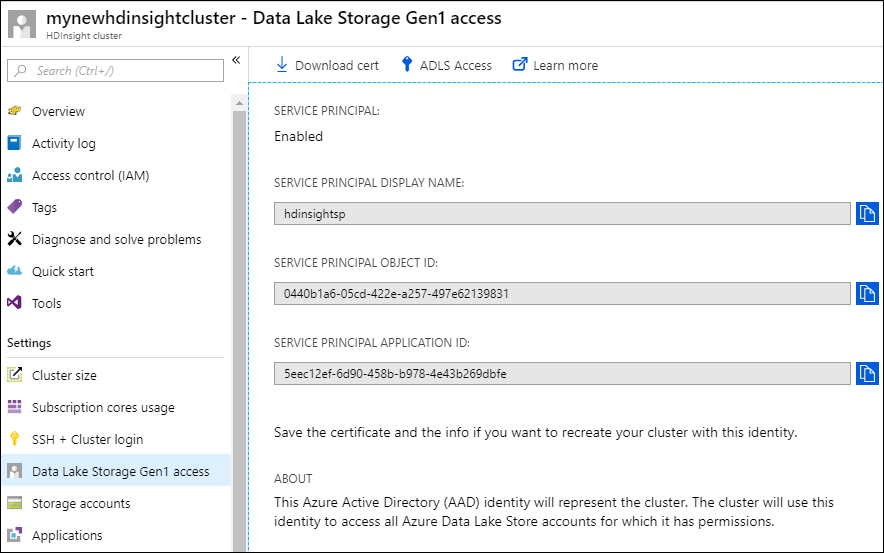
サービス プリンシパルが HDInsight クラスターに正しく関連付けられていることを確認するには、左側のペインで [Data Lake Storage Gen1 アクセス] を選択します。
例
Data Lake Storage Gen1 をストレージとして使用するクラスターを設定したら、HDInsight クラスターを使用して Data Lake Storage Gen1 に格納されているデータを分析する方法について、以下に示すいくつかの例をご覧ください。
(プライマリ ストレージとしての) Data Lake Storage Gen1 に格納されているデータに対して Hive クエリを実行する
Hive クエリを実行する場合は、Ambari ポータルで提供されている Hive ビュー インターフェイスを使用します。 Ambari Hive ビューの使用方法については、「HDInsight での Hive View と Hadoop の使用」をご覧ください。
Data Lake Storage Gen1 内のデータを操作するときは、いくつかの文字列を変更する必要があります。
たとえば、プライマリ ストレージとして Data Lake Storage Gen1 を使用するクラスターを作成した場合は、データのパスは adl://<
CREATE EXTERNAL TABLE websitelog (str string) LOCATION 'adl://hdiadlsg1storage.azuredatalakestore.net/clusters/myhdiadlcluster/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/'
上記のクエリで、
-
adl://hdiadlsg1storage.azuredatalakestore.net/は Data Lake Storage Gen1 を使用するアカウントのルートです。 -
/clusters/myhdiadlclusterはクラスターの作成時に指定したクラスター データのルートです。 -
/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/はクエリで使用したサンプル ファイルの場所です。
(追加ストレージとしての) Data Lake Storage Gen1 に格納されているデータに対して Hive クエリを実行する
作成したクラスターで既定のストレージとして Blob Storage を使用している場合、追加ストレージとして使用されている Data Lake Storage Gen1 を使用するストレージ アカウントにサンプル データは含まれません。 このような場合、Blob Storage から Data Lake Storage Gen1 を使用するストレージ アカウントにデータを転送してから、上の例に示したようにクエリを実行します。
Blob Storage から Data Lake Storage Gen1 を使用するストレージ アカウントにデータをコピーする方法については、次の記事をご覧ください。
- Distcp を使用して Azure Blob Storage と Data Lake Storage Gen1 の間でデータをコピーする
- AdlCopy を使用して Azure Blob Storage のデータを Data Lake Storage Gen1 にコピーする
Spark クラスターで Data Lake Storage Gen1 を使用する
Spark クラスターを使用すると、Data Lake Storage Gen1 に格納されているデータに対して Spark ジョブを実行できます。 詳細については、HDInsight Spark クラスターを使用した Data Lake Storage Gen1 のデータの分析に関するページをご覧ください。