クエリが複数回実行されるのはなぜですか?
Power Query で更新する場合、スムーズなユーザー エクスペリエンスを提供し、クエリを効率的かつ安全に実行するために、バックグラウンドで多くのことが行われます。 ただし、場合によっては、データが更新された際に Power Query によって複数のデータ ソース要求がトリガーされたことに気付くことがあります。 場合によっては、これらの要求が正常であることもありますが、それ以外の場合はそれらの要求を防止できます。
複数の要求が発生した場合
次のセクションでは、Power Query がデータ ソースに複数の要求を送信できる場合の、いくつかのインスタンスについて説明します。
コネクタのデザイン
コネクタは、メタデータ、結果のキャッシュ、改ページなど、さまざまな理由でデータ ソースへの複数の呼び出しを行うことができます。 この動作は正常であり、そのように動作するように設計されています。
1 つのデータ ソースを参照する複数のクエリ
複数のクエリがそのデータ ソースからプルされた場合、同じデータ ソースに対する複数の要求が発生する可能性があります。 これらの要求は、1 つのクエリのみがデータ ソースを参照している場合でも発生する可能性があります。 他の 1 つ以上のクエリがそのクエリを参照している場合は、各クエリとそれに依存するすべてのクエリが個別に評価されます。
デスクトップ環境では、データ モデル内のすべてのテーブルの 1 回の更新が、1 つの共有キャッシュを使用して実行されます。 キャッシュを使用すると、同じデータ ソースに対して複数の要求が発生する可能性を減らすことができます。これは、1 つのクエリが別のクエリに対して既に実行されていて、キャッシュされている場合があるためです。 ただし、ここでも、次の理由で複数の要求を取得することができます。
- データ ソースはキャッシュされません (ローカル CSV ファイルなど)。
- データ ソースへの要求は、ダウンストリーム操作 (フォールディング処理を変更する可能性がある) のために既にキャッシュされた要求とは異なります。
- キャッシュが小さすぎます (比較的可能性が低い)。
- クエリは、ほぼ同時に実行されます。
クラウド環境では、各クエリは独自の個別のキャッシュを使用して更新されます。 そのため、別のクエリに対して同じ要求が既にキャッシュされている場合、クエリのメリットを得られません。
折りたたみ
Power Query のフォールディング レイヤーでは、ダウンストリームで実行される操作に基づいて、データ ソースに対して複数の要求を生成することができます。 このような場合は、Table.Buffer を使用して複数の要求を回避できます。 詳細情報: テーブルのバッファー
Power BI Desktop モデルへの読み込み
Power BI Desktop では、Analysis Services (AS) は 2 つの評価を使用してデータを更新します。1 つは AS がゼロ行を要求することによって行うスキーマを取り込むためのもので、もう 1 つはデータを取り込むためのものです。 ゼロ行スキーマを計算するためにデータを取り込む必要がある場合、重複するデータ ソース要求が発生する可能性があります。
データのプライバシー分析
データのプライバシーでは、各クエリを独自に評価して、クエリをまとめて実行するのが安全かどうかを判断します。 この評価では、データ ソースに対して複数の要求が行われる場合があります。 特定の要求がデータ プライバシー分析からのものであることを示す明らかなサインは、"上位 1000" の状態になることです (ただし、すべてのデータ ソースがこのような状態をサポートしているわけではありません)。 一般に、それが許容できると仮定するデータ プライバシーを無効にすると、更新中の "上位 1000" またはその他のデータ プライバシー関連の要求が削除されます。 詳細情報: データ プライバシー ファイアウォールを無効にする
バックグラウンド データのダウンロード ("バックグラウンド分析" とも呼ばれます)
データ プライバシーを確保するために実行される評価と同様に、Power Query エディターでは、各クエリ手順の最初の 1000 行のプレビューが既定でダウンロードされます。 これらの行をダウンロードすると、手順が選択されるとすぐにデータ プレビューを表示できるようになりますが、重複したデータ ソース要求が発生する可能性もあります。 詳細情報: バックグラウンド分析を無効にする
その他の Power Query エディターのバックグラウンド タスク
さまざまな Power Query エディターのバックグラウンド タスクによって、追加のデータ ソース リクエストがトリガーされることもあります (たとえば、クエリ フォールディング分析、列プロファイリング、結果を Excel に読み込んだ後に Power Query がトリガーする 1000 行プレビューの自動更新など)。
複数のクエリの分離
クエリプロセスの特定の部分をオフにして、重複する要求の送信元を分離することで、複数のクエリのインスタンスを分離することができます。 たとえば、次のように開始するとします。
- Power Query エディターで
- ファイアウォールが無効になっている
- バックグラウンド分析が無効になっている
- 列プロファイルおよびその他のバックグラウンド タスクが無効になっている
- [省略可能]
Table.Bufferの実行
この例では、Power Query エディターのプレビューを更新すると、1 つの M 評価のみが生成されます。 この時点で重複する要求が発生した場合、それらはクエリの作成方法に固有のものです。 それ以外の場合、上記の設定を 1 つずつ有効にすると、重複する要求がどの時点で発生しているかを確認できます。
以降のセクションで、これらの手順について詳しく説明します。
Power Query エディターのセットアップ
クエリを再接続または再作成する必要はありません。Power Query エディターでテストするクエリを開くだけです。 既存のクエリを使用しない場合は、エディターでクエリを複製することができます。
データ プライバシー ファイアウォールを無効にする
次の手順では、データ プライバシー ファイアウォールを無効にします。 この手順では、ソース間のデータ漏洩についての懸念がないことを前提としているため、データ プライバシー ファイアウォールの無効化は、Excel の [高速結合オプションの設定] で説明されている [常にプライバシー レベル設定を無視します] を使用して行うことができます。または、Power BI Desktop の [Power BI Desktop のプライバシーレベル] で説明されている [プライバシー レベルを無視すると、パフォーマンスが向上する場合があります] 設定を使用します。
通常のテストを再開する前に、この手順を元に戻してください。
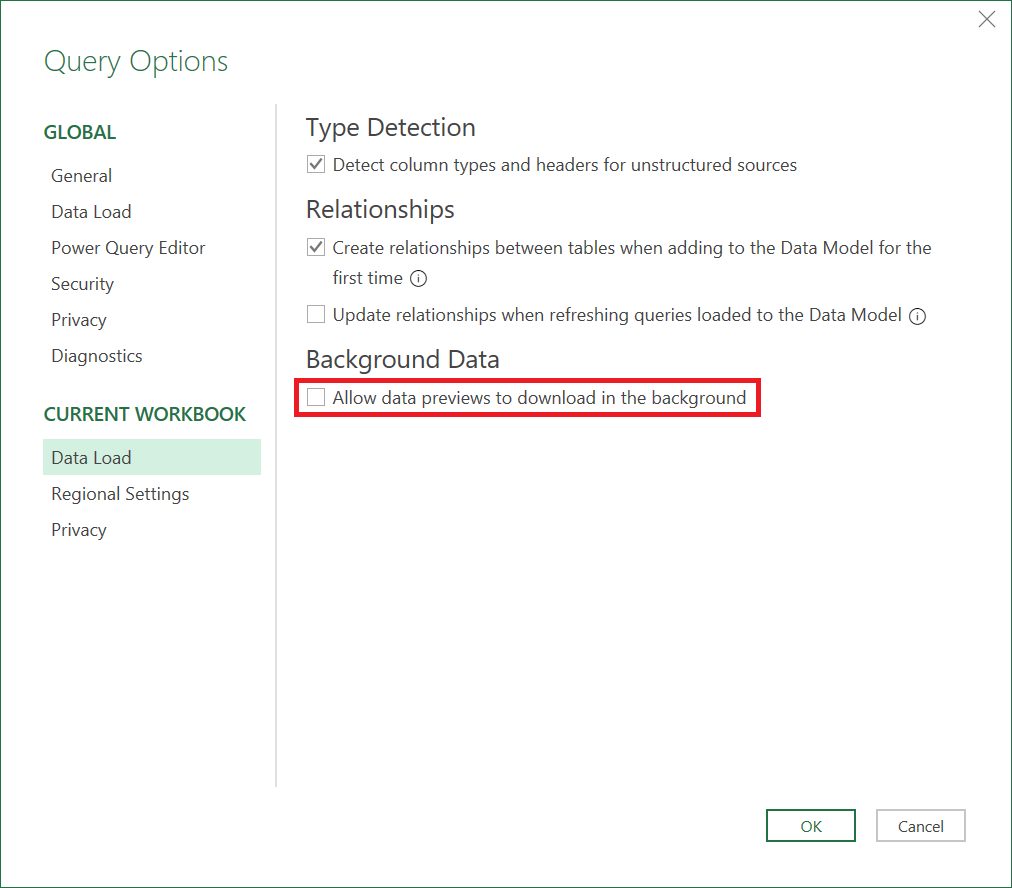
バックグラウンド分析を無効にする
次の手順では、バックグラウンド分析を無効にします。 バックグラウンド分析は、[Power BI の Power Query バックグラウンド更新の無効化] で説明されている [バックグランドでのデータ プレビューのダウンロードを許可する] 設定によって制御されます。 Excel でこのオプションを無効にすることもできます。
テーブルのバッファー
必要に応じて、Table.Buffer を使用してすべてのデータを強制的に読み取ることもできます。これにより、読み込み中の処理が模倣されます。 Power Query エディターで Table.Buffer を使用するには、次のようにします。
Power Query エディターの数式バーで、[fx] ボタンを選択して新しい手順を追加します。
数式バーで、前のステップの名前を Table.Buffer で囲みます (<前のステップ名はここに表示されます>)。 たとえば、前の手順の名前が
Sourceの場合、数式バーには= Sourceと表示されます。 数式バーの手順を編集して= Table.Buffer(Source)と呼びます。
詳細情報: Table.Buffer
テストの実行
テストを実行するには、Power Query エディターで更新を行います。