Azure Data Explorer (Kusto)
まとめ
| 項目 | 説明 |
|---|---|
| リリース状態 | 一般提供 |
| 製品 | Excel Power BI (セマンティック モデル) Power BI (データフロー) ファブリック (データフロー Gen2) Power Apps (データフロー) Dynamics 365 Customer Insights |
| サポートされている認証の種類 | 組織アカウント |
| 関数リファレンス ドキュメント | — |
Note
デプロイ スケジュールにより、またホスト固有の機能があることにより、ある製品に存在する機能が他の製品にはない場合があります。
前提条件
Azure サブスクリプション。 Azure 無料試用版の取得に関するページをご覧ください。
Microsoft Entra ID のメンバーである組織の電子メール アカウント。 この記事では、このアカウントを使用して、Azure Data Explorer ヘルプ クラスターのサンプルに接続します。
サポートされる機能
- インポート
- DirectQuery (Power BI セマンティック モデル)
- 詳細オプション
- クエリ結果のレコード数を制限する
- クエリ結果のデータ サイズ (バイト単位) を制限する
- 結果セットの切り詰めを無効にする
- 追加の SET ステートメント
Power Query Desktop から Azure Data Explorer に接続する
Power Query Desktop から Azure Data Explorer に接続するには、次の手順を実行します。
データの取得エクスペリエンスで [Azure Data Explorer (Kusto)] を選択します。 Power Query Desktop でのデータの取得エクスペリエンスは、アプリによって異なります。 アプリの Power Query Desktop データの取得エクスペリエンスの詳細については、「データを取得する場所」を参照してください。
[Azure Data Explorer (Kusto)] で、Azure Data Explorer クラスターの名前を指定します。 この例では、
https://help.kusto.windows.netを使用してサンプルのヘルプ クラスターにアクセスします。 その他のクラスターでは、URL が https://<クラスター名>.<リージョン>.kusto.windows.net. 形式になります。接続先のクラスターでホストされているデータベース、データベース内のテーブルの1つ、または
StormEvents | take 1000のようなクエリを選択することもできます。詳細オプションを使用する場合は、オプションを選択し、そのオプションで使用するデータを入力します。 詳細情報: 詳細オプションを使用して接続
Note
すべての詳細オプションとデータ接続の選択を表示するには、下にスクロールすることが必要な場合があります。
[インポート] または [DirectQuery] のデータ接続モードを選択します (Power BI Desktop のみ)。 詳細情報: Import モードまたは DirectQuery モードを使用する場合
OK を選択して続行します。
![[Azure Data Explorer (Kusto)] ダイアログ ボックスのスクリーンショット。クラスターの URL が入力されています。](media/azure-data-explorer/ade-cluster.png)
クラスターへの接続がまだない場合は、[サインイン] を選択します。 組織アカウントでサインインし、[接続] を選択します。
![Azure Data Explorer の [サインイン] ダイアログ ボックスのスクリーンショット。組織アカウントをサインインする準備ができています。](media/azure-data-explorer/sign-in-desktop.png)
[ナビゲーター] で、目的のデータベース情報を選択し、[読み込み] を選択してデータを読み込むか、[データの変換] を選択して Power Query エディターでデータの変換を続行します。 この例では、Samples データベースの StormEvents が選択されています。
![[ナビゲーター] が開いているスクリーンショット。Samples データベースの StormEvents からのデータが含まれています。](media/azure-data-explorer/navigator-desktop.png)
![[ナビゲーター] が開いているスクリーンショット。Samples データベースの StormEvents からのデータが含まれています。](media/azure-data-explorer/navigator-desktop.png#lightbox)
Power Query Online から Azure Data Explorer に接続する
Power Query Online から Azure Data Explorer に接続するには、次の手順を実行します。
データの取得エクスペリエンスで [Azure Data Explorer (Kusto)] オプションを選択します。 Power Query Online のデータの取得エクスペリエンスに到達する方法は、アプリによって異なります。 Power Query Online のデータの取得エクスペリエンスに到達する方法の詳細については、「データを取得する場所」を参照してください。
![Azure Data Explorer が強調された [データの取得] ウィンドウのスクリーンショット。](media/azure-data-explorer/get-data-online.png)
[データ ソースに接続] で、Azure Data Explorer クラスターの名前を指定します。 この例では、
https://help.kusto.windows.netを使用してサンプルのヘルプ クラスターにアクセスします。 その他のクラスターでは、URL が https://<クラスター名>.<リージョン>.kusto.windows.net. 形式になります。接続先のクラスターでホストされているデータベース、データベース内のテーブルの1つ、または
StormEvents | take 1000のようなクエリを選択することもできます。![クラスターの URL が入力された Azure Data Explorer (Kusto) の [データ ソースの選択] ページのスクリーンショット。](media/azure-data-explorer/sign-in-online.png)
詳細オプションを使用する場合は、オプションを選択し、そのオプションで使用するデータを入力します。 詳細情報: 詳細オプションを使用して接続
必要に応じて、[データ ゲートウェイ] でオンプレミス データ ゲートウェイを選択します。
クラスターへの接続がまだない場合は、[サインイン] を選択します。 組織のアカウントを使用してサインインします。
正常にサインインした後、[次へ] を選択します。
[データの選択] ページで、目的のデータベース情報を選択し、[データの変換] または [次へ] を選択して Power Query エディターでデータの変換を続行します。 この例では、Samples データベースの StormEvents が選択されています。
![サンプル データベースの StormEvents のデータを含む [データの選択] ページのスクリーンショット。](media/azure-data-explorer/navigator-online.png)
![サンプル データベースの StormEvents のデータを含む [データの選択] ページのスクリーンショット。](media/azure-data-explorer/navigator-online.png#lightbox)
詳細オプションを使用して接続する
Power Query Desktop と Power Query Online のどちらにも、必要に応じてクエリに追加できる一連の詳細オプションが用意されています。
次の表に、Power Query Desktop と Power Query Online で設定できるすべての詳細オプションを示します。
| 詳細オプション | 説明 |
|---|---|
| クエリ結果のレコード数を制限する | 結果として返されるレコードの最大数。 |
| クエリ結果のデータ サイズをバイト単位で制限する | 結果として返される最大データ サイズ (バイト単位)。 |
| 結果セットの切り詰めを無効にする | notruncationリクエスト オプションを使用して、結果の切り捨てを有効または無効にします。 |
| 追加の Set ステートメント | クエリの実行中のクエリ オプションを設定します。 クエリ オプションは、クエリの実行方法とクエリが結果を返す方法を制御します。 複数の SET ステートメントはセミコロンで区切ることができます。 |
Power Query UI で使用できない追加の詳細オプションの詳細については、「M クエリでの Azure Data Explorer コネクタ オプションの構成」を参照してください。
Import モードまたは DirectQuery モードを使用する場合
Import モードでは、データは Power BI に移行されます。 DirectQuery モードでは、クラスターからデータのクエリが直接実行されます。
次の場合は Import モードを使用します。
- データ セットが小さい。
- ほぼリアルタイムのデータが必要ない。
- データは既に集計済みか、Kusto で集計を実行している。
次の場合は DirectQuery モードを使用します。
- データ セットが非常に大きい。
- ほぼリアルタイムのデータが必要。
DirectQuery の使用の詳細については、「Power BI の DirectQuery」を参照してください。
Azure Data Explorer コネクタを使用してデータのクエリを実行するためのヒント
次のセクションでは、Power Query に Kusto クエリ言語を使用するためのヒントと手法について説明します。
Power BI での複雑なクエリ
複雑なクエリは、Kusto でのほうが Power Query よりも簡単に表現できます。 これらは Kusto 関数として実装し、Power BI で呼び出す必要があります。 この方法は、Kusto クエリの let ステートメントと共に DirectQuery を使用する場合に必要です。 Power BI によって 2 つのクエリが結合され、join 演算子と共に let ステートメントを使用できないため、構文エラーが発生する可能性があります。 したがって、結合の各部分を Kusto 関数として保存し、Power BI でこれら 2 つの関数を結合できるようにします。
相対 date-time 演算子をシミュレートする方法
Power Query には、ago() などの相対日付/時刻演算子が含まれていません。
ago() をシミュレートするには、Power Query M 関数の DateTime.FixedLocalNow と #duration を組み合わせて使用します。
このクエリではなく、ago() 演算子を使用します。
StormEvents | where StartTime > (now()-5d)
StormEvents | where StartTime > ago(5d)
次の同等のクエリを使用します。
let
Source = AzureDataExplorer.Contents("help", "Samples", "StormEvents", []),
#"Filtered Rows" = Table.SelectRows(Source, each [StartTime] > (DateTime.FixedLocalNow()-#duration(5,0,0,0)))
in
#"Filtered Rows"
M クエリでの Azure Data Explorer コネクタ オプションの構成
Azure Data Explorer コネクタのオプションは、Mクエリ言語の Power Query 詳細エディターから構成できます。 これらのオプションを使用して、Azure Data Explorer クラスターに送信される、生成されたクエリを制御できます。
let
Source = AzureDataExplorer.Contents("help", "Samples", "StormEvents", [<options>])
in
Source
M クエリで、次のすべてのオプションを使用できます。
| オプション | サンプル | 説明 |
|---|---|---|
| MaxRows | [MaxRows=300000] |
set truncationmaxrecords ステートメントをクエリに追加します。 クエリが呼び出し元に返すことのできるレコードの既定の最大数をオーバーライドします (切り詰め)。 |
| MaxSize | [MaxSize=4194304] |
set truncationmaxsize ステートメントをクエリに追加します。 クエリが呼び出し元に返すことのできる既定の最大データ サイズをオーバーライドします (切り詰め)。 |
| NoTruncate | [NoTruncate=true] |
set notruncation ステートメントをクエリに追加します。 呼び出し元に返されるクエリ結果の切り詰めの抑制を有効にします。 |
| AdditionalSetStatements | [AdditionalSetStatements="set query_datascope=hotcache"] |
指定した set ステートメントをクエリに追加します。 これらのステートメントは、クエリの実行中にクエリ オプションを設定するために使用されます。 クエリ オプションは、クエリの実行方法とクエリが結果を返す方法を制御します。 |
| CaseInsensitive | [CaseInsensitive=true] |
大文字と小文字を区別しないクエリをコネクタが生成するようにします。クエリでは、値を比較するときに、== 演算子ではなく、=~ 演算子が使用されます。 |
| ForceUseContains | [ForceUseContains=true] |
テキスト フィールドを操作するときに、既定の has ではなく contains を使用するクエリがコネクタによって生成されるようにします。 has は、はるかにパフォーマンスに優れていますが、部分文字列は処理されません。 2 つの演算子の違いの詳細については、「文字列演算子」を参照してください。 |
| Timeout | [Timeout=#duration(0,10,0,0)] |
クエリに対するクライアントとサーバー両方のタイムアウトを、指定された期間に構成します。 |
| ClientRequestIdPrefix | [ClientRequestIdPrefix="MyReport"] |
コネクタによって送信されるすべてのクエリに対して ClientRequestId プレフィックスを構成します。 これにより、特定のレポートやデータ ソースからのクエリをクラスター内で識別できるようになります。 |
Note
次のように複数のオプションを組み合わせることで、必要な動作に到達できます: [NoTruncate=true, CaseInsensitive=true]
Kusto クエリの制限に達する
Kusto クエリからは、既定で最大 500,000 行または 64 MB が返されます。詳細についてはクエリの制限に関する記事を参照してください。 これらの既定値をオーバーライドするには、Azure Data Explorer (Kusto) 接続ウィンドウで [詳細オプション] を使用します。
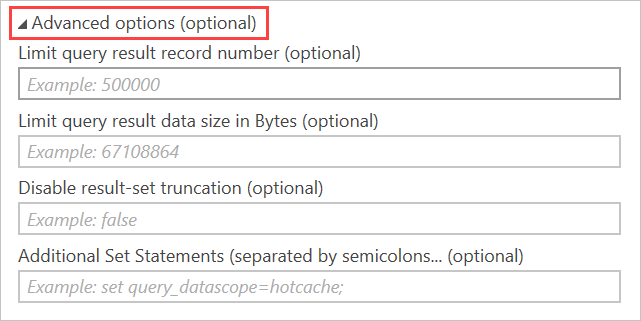
これらのオプションでは、クエリと共に SET ステートメントが発行され、既定のクエリ制限が変更されます。
- [クエリ結果のレコード数を制限する] で
set truncationmaxrecordsが生成されます。 - [クエリ結果のデータ サイズを制限する (バイト単位)] で
set truncationmaxsizeが生成されます。 - [結果セットの切り詰めを無効にする] で
set notruncationが生成されます。
大文字小文字の区別
既定では、コネクタによって生成されるクエリでは、文字列値を比較するときに、大文字と小文字を区別する == 演算子が使用されます。 データで大文字と小文字が区別されない場合、これは望ましい動作ではありません。 生成されるクエリを変更するには、CaseInsensitive コネクタ オプションを使用します。
let
Source = AzureDataExplorer.Contents("help", "Samples", "StormEvents", [CaseInsensitive=true]),
#"Filtered Rows" = Table.SelectRows(Source, each [State] == "aLaBama")
in
#"Filtered Rows"
クエリ パラメーターの使用
クエリ パラメーターを使用して、クエリを動的に変更できます。
クエリ ステップでクエリ パラメーターを使用する
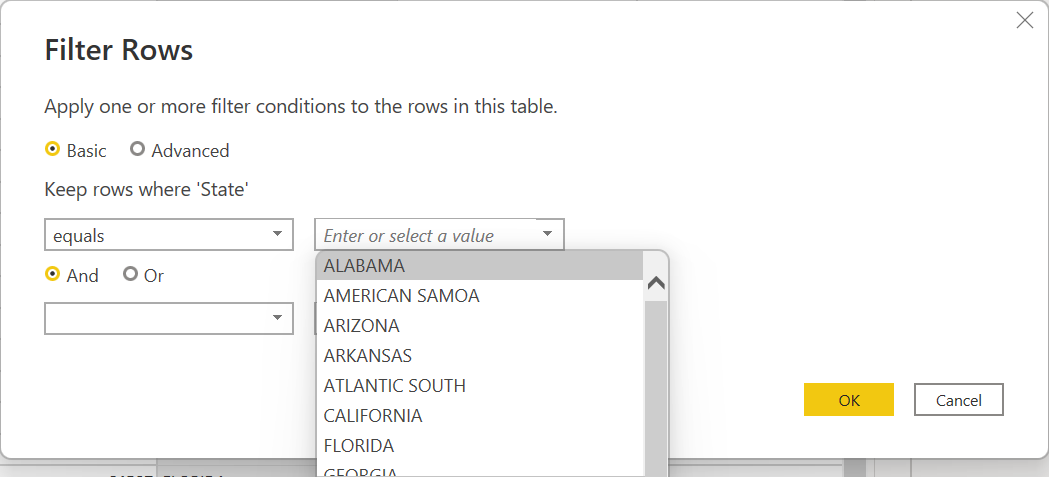
クエリ パラメーターは、それをサポートする任意のクエリ ステップで使用できます。 たとえば、パラメーターの値に基づいて結果をフィルター処理します。 この例では、Power Query エディターの State 列の右側にあるドロップダウン メニューを選択し、[テキスト フィルター]>[次の値に等しい] を選択し、[Keep rows where 'State'] ('State' を含む行を保持します) の下の [ALABAMA] を選択します。
Azure Data Explorer 関数にパラメーターを指定する
Kusto 関数は、複雑な Kusto クエリ言語 (KQL) クエリを維持するための優れた方法です。 Power Query に KQL を埋め込む代わりに関数を使用することをお勧めします。 関数を使用する主な利点は、作成とテストが簡単な環境でロジックが 1 回維持される点です。
関数はパラメーターを受け取ることもできます。そのため、Power BI ユーザーに多くの柔軟性がもたらされます。 Power BI には、データをスライスする多くの方法があります。 ただし、すべてのフィルターとスライサーは元の KQL の後に追加され、多くの場合、クエリの初期段階でフィルター処理を使用する必要があります。 関数と動的パラメーターを使用することは、最終的なクエリをカスタマイズする非常に効果的な方法です。
関数の作成
無料のクラスターを含め、アクセスできる任意の Azure Data Explorer クラスターで次の関数を作成できます。 この関数は、ヘルプ クラスターからテーブル SalesTable を返し、レポート ユーザーが指定した数値より大きいか小さい販売トランザクションに対してフィルター処理されます。
.create-or-alter function LargeOrSmallSales(Cutoff:long,Op:string=">")
{
cluster("help").database("ContosoSales").SalesTable
| where (Op==">" and SalesAmount >= Cutoff) or (Op=="<" and SalesAmount <= Cutoff)
}
関数を作成したら、次を使用してテストできます。
LargeOrSmallSales(2000,">")
| summarize Sales=tolong(sum(SalesAmount)) by Country
次を使用してテストすることもできます。
LargeOrSmallSales(20,"<")
| summarize Sales=tolong(sum(SalesAmount)) by Country
Power BI での関数の使用
関数を作成したクラスターに接続します。
Power Query ナビゲーターで、オブジェクトの一覧から関数を選択します。 コネクタはパラメーターを分析し、ナビゲーターの右側にあるデータの上に表示します。
![ナビゲーターのデータの上に [カットオフ] パラメーターと [Op] パラメーターが表示されているスクリーンショット。](media/azure-data-explorer/connector-analysis.png)
パラメーターに値を追加し、[適用] を選択します。
プレビューが表示されたら、[データの変換] を選択します。
Power Query エディターで、カットオフ値用と演算子用の 2 つのパラメーターを作成します。
LargeOrSmallSalesクエリに戻り、値を数式バーのクエリ パラメーターに置き換えます。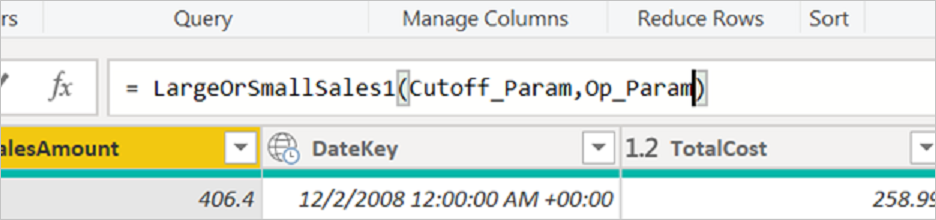
エディターから 2 つの静的テーブル (データの入力) を作成し、2 つのパラメーターのオプションを指定します。 カットオフでは、10、50、100、200、500、1000、2000 などの値を持つテーブルを作成できます。
Opでは、<と>の 2 つのテキスト値を持つテーブルを作成できます。テーブル内の 2 つの列は、[Bind to parameter] (バインドするパラメーター) の選択内容を使用してクエリ パラメーターにバインドする必要があります。
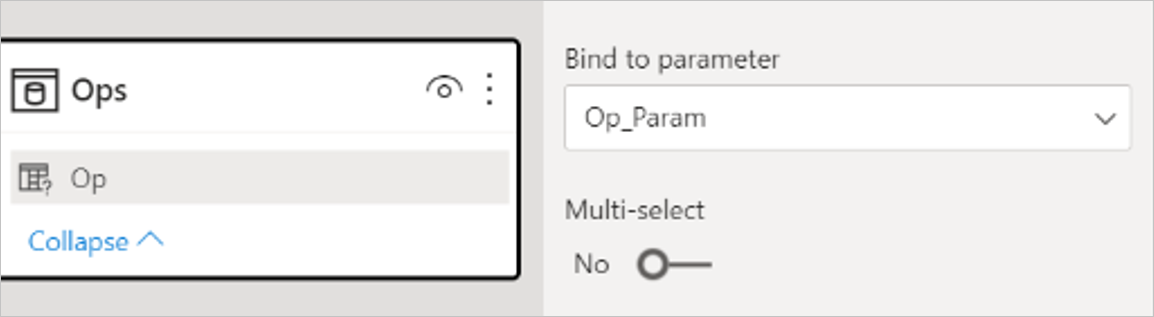
最後のレポートには、2 つの静的テーブルのスライサーと、売上概要のビジュアルが含まれます。
![[カットオフ] 値と [Op] の値の選択が表の横に表示されている Power BI のスクリーンショット。](media/azure-data-explorer/slicers-visuals.png)
ベース テーブルは最初にフィルター処理され、次に集計されます。
接続の詳細でのクエリ パラメーターの使用
クエリ パラメーターを使用して、クエリの情報をフィルター処理し、クエリのパフォーマンスを最適化します。
[詳細エディター] で、次の手順を実行します。
クエリの次のセクションを探します。
Source = AzureDataExplorer.Contents("<クラスター>", "<データベース>", "<クエリ>", [])
次に例を示します。
Source = AzureDataExplorer.Contents("Help", "Samples", "StormEvents | where State == 'ALABAMA' | take 100", [])Kusto クエリ言語 (KQL) クエリにクエリ パラメーターを挿入します。
接続ダイアログに KQL クエリを直接貼り付けると、クエリは Power Query のソース ステップの一部になります。 詳細エディターを使用するか、数式バーでソース ステートメントを編集するときに、クエリの一部としてパラメーターを埋め込むことができます。 クエリの例を次に示します:
StormEvents | where State == ' " & State & " ' | take 100。Stateはパラメーターであり、実行時にクエリは次のようになります。StormEvents | where State == 'ALABAMA' | take 100クエリに引用符が含まれている場合は、それらを適切にエンコードします。 たとえば、次の KQL のクエリがあります。
"StormEvents | where State == "ALABAMA" | take 100"これは、次のように 2 つの引用符を使用して詳細エディターに表示されます。
"StormEvents | where State == ""ALABAMA"" | take 100"Stateなどのパラメーターを使用している場合は、次のクエリに置き換える必要があります。このクエリには、3 つの引用符が含まれています。"StormEvents | where State == """ & State & """ | take 100"
Azure Data Explorer の機能に対して Value.NativeQuery を使用する
Power Query でサポートされていない Azure Data Explorer の機能を使用するには、Power Query M の Value.NativeQuery メソッドを使用します。このメソッドにより、生成されたクエリに Kusto クエリ言語フラグメントが挿入されます。また、実行されたクエリをより詳細に制御するためにも使用できます。
次の例では、Azure Data Explorer で percentiles 関数を使用する方法を示します。
let
StormEvents = AzureDataExplorer.Contents(DefaultCluster, DefaultDatabase){[Name = DefaultTable]}[Data],
Percentiles = Value.NativeQuery(StormEvents, "| summarize percentiles(DamageProperty, 50, 90, 95) by State")
in
Percentiles
Kusto に制御コマンドを発行するために Power BI データ更新スケジューラを使用しない
Power BI には、データ ソースに対して定期的にクエリを発行できるデータ更新スケジューラが用意されています。 Power BI では、すべてのクエリが読み取り専用であると想定されているため、このメカニズムを使用して Kusto に対して制御コマンドをスケジュールすることはできません。