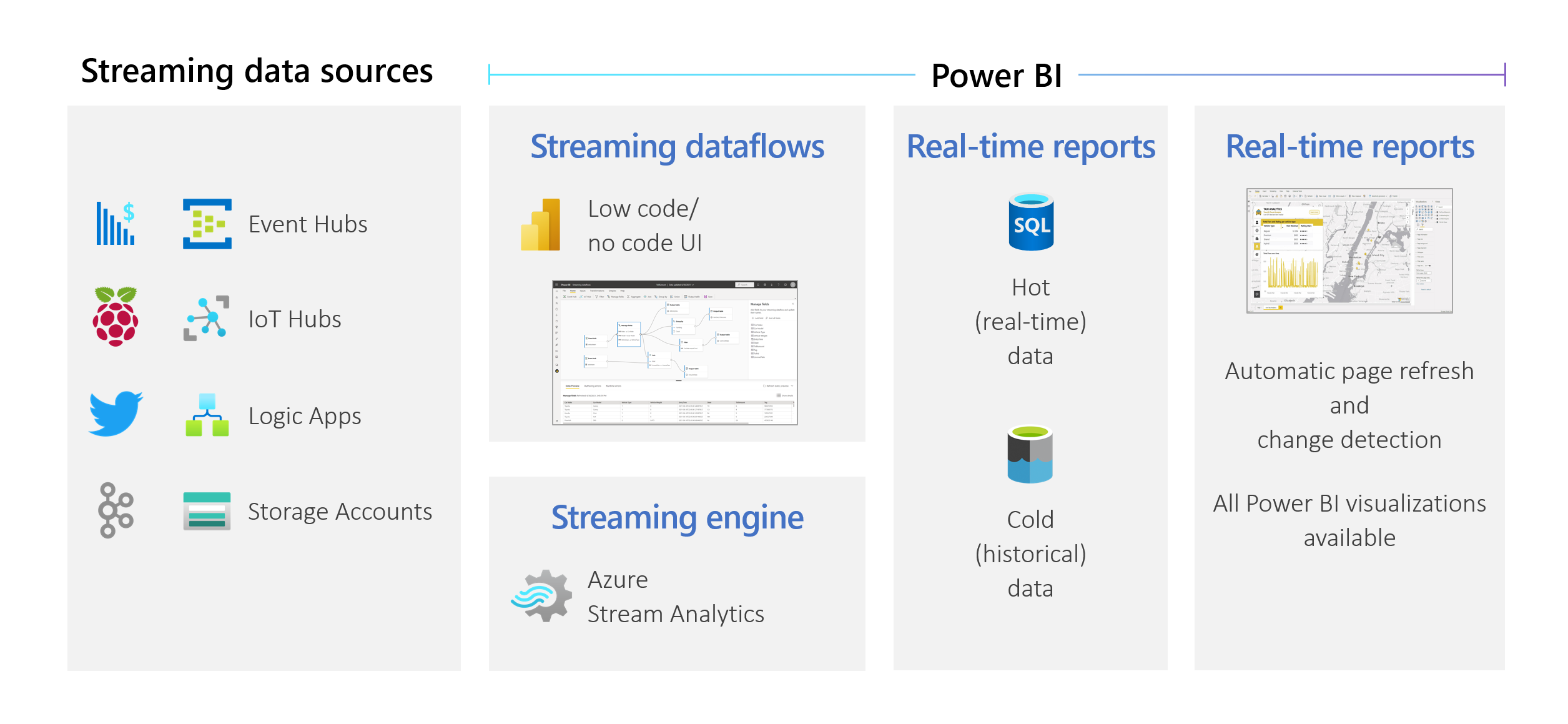
ストリーミング データフロー (プレビュー)
組織は、数日や数週間後ではなく、データが届いたときにそれを処理することを望んでいます。 Power BI のビジョンはシンプルです。つまり、バッチ、リアルタイム、ストリーミングの区別がなくなるということです。 ユーザーは、すべてのデータを、それが利用可能になった時点ですぐに操作できる必要があります。 通常、アナリストは、データ ソースのストリーミング、データの準備、複雑な時間ベースの操作、リアルタイムのデータの視覚化を処理するための技術的な支援を必要としています。 IT 部門は、多くの場合、データの分析をタイムリーに実行するために、カスタム ビルドのシステムと、さまざまなベンダーのテクノロジの組み合わせに依存しています。 この複雑さがなければ、意思決定者に準リアルタイムで情報を提供することはできません。
"ストリーミング データフロー" により、作成者は Power BI サービス内で直接、準リアルタイムのデータのストリーミングに基づいて、接続、取り込み、マッシュアップ、モデル化、レポートの作成を行うことができます。 サービスにより、ドラッグ アンド ドロップのノー コード エクスペリエンスが可能になります。 必要に応じて、"ダイアグラム ビュー" を含むユーザー インターフェイス (UI) を使ってストリーミング データとバッチ データを組み合わせ、簡単にデータ マッシュアップを行うことができます。 生成される最終的な項目はデータフローです。これは、リアルタイムで使用できるため、高度にインタラクティブで、準リアルタイムのレポートが作成されます。 Power BI のデータ視覚化機能はすべて、ストリーミング データでもバッチ データとまったく同様に機能します。
重要
ストリーミング データフローは廃止され、使用できなくなりました。 Azure Stream Analytics によってストリーミング データフローの機能が統合されました。 ストリーミング データフローの廃止について詳しくは、廃止のお知らせを参照してください。
 ユーザーは、結合やフィルターなどのデータ準備操作を実行できます。 さらに、group-by 操作の時間ウィンドウ集計 (タンブリング、ホッピング、セッション ウィンドウなど) も実行できます。
Power BI のストリーミング データフローにより、組織は次のことが可能になります。
ユーザーは、結合やフィルターなどのデータ準備操作を実行できます。 さらに、group-by 操作の時間ウィンドウ集計 (タンブリング、ホッピング、セッション ウィンドウなど) も実行できます。
Power BI のストリーミング データフローにより、組織は次のことが可能になります。
- 意思決定を準リアルタイムで自信を持って行う: 組織は、機敏性が向上し、最新の分析情報に基づいて、意味のある行動を取ることができます。
- ストリーミング データを民主化する: 組織はノーコード ソリューションにより、データにアクセスしやすくなり、解釈が容易になります。また、このアクセスのしやすさによって IT リソースを削減できます。
- 統合されたデータ ストレージとビジネス インテリジェンスによるエンドツーエンドのストリーミング分析ソリューションを使用することで、分析情報を得るまでの時間が短縮されます。
ストリーミング データフローでは、DirectQuery とページの自動更新/変更検出がサポートされています。 このサポートにより、ユーザーは、Power BI で利用可能な任意のビジュアルを使用して、準リアルタイムで (最大 1 秒ごとに) 更新されるレポートを作成できます。
必要条件
最初のストリーミング データフローを作成する前に、次のすべての要件を満たしていることを確認してください。
ストリーミング データフローを作成して実行するには、Premium 容量 または Premium Per User (PPU) ライセンスの一部であるワークスペースが必要です。
重要
PPU ライセンスを使用しており、リアルタイムで更新されるストリーミング データフローを使用して作成されたレポートを他のユーザーも利用できるようにする場合、それらのユーザーにも PPU ライセンスが必要です。 それにより、設定した更新頻度が 30 分おきよりも短い場合に、それらのユーザーがその同じ更新頻度でレポートを利用できます。
テナントに対してデータフローを有効にします。 詳細については、記事「Power BI Premium でのデータフローの有効化」を参照してください。
ストリーミング データフローがお使いの Premium 容量で機能することを確認するには、拡張コンピューティング エンジンを有効にする必要があります。 エンジンは既定でオンになっていますが、Power BI の容量管理者はこれをオフにすることができます。 その場合は、管理者に連絡して有効にしてください。
拡張コンピューティング エンジンは、Premium P か Embedded A3 以上の容量でのみ使用できます。 ストリーミング データフローを使うには、PPU、任意のサイズの Premium P 容量、または Embedded A3 以上の容量が必要です。 Premium SKU の詳細とそれらの仕様については、「Power BI Embedded の分析の容量と SKU」を参照してください。
リアルタイムで更新されるレポートを作成するには、管理者 (PPU の容量または Power BI) がページの自動更新を有効にしていることを確認します。 また、ニーズに一致した最小更新間隔を管理者が許可していることも確認してください。 詳細については、「Power BI でのページの自動更新」を参照してください。
ストリーミング データフローを作成する
ストリーミング データフローは、そのデータフロー相対と同様に、Power BI サービスのワークスペースで作成および管理されるエンティティ (テーブル) のコレクションです。 テーブルは、データベース内のテーブルと同様に、データを格納するために使用されるフィールドのセットです。
ストリーミング データフロー内のテーブルは、そのデータフローを作成したワークスペースから直接追加したり、編集したりすることができます。 通常のデータフローとの主な違いは、更新や頻度について心配する必要がないことです。 ストリーミング データの性質上、ストリームが継続的に受信されます。 更新は停止しない限り一定または無限です。
Note
ワークスペースあたりに作成できるデータフローの種類は 1 つだけです。 Premium ワークスペースに通常のデータフローが既にある場合、ストリーミング データフローを作成することはできません (その逆も同様)。
ストリーミング データフローを作成するには:
ブラウザーで Power BI サービスを開き、Premium 対応ワークスペースを選択します。 (通常のデータフローと同様に、ストリーミング データフローはマイ ワークスペースで使用できません。)
[新規] ドロップダウン メニューを選択し、[ストリーミング データフロー] を選択します。
![ストリーミング データフローが強調表示された [新規] メニュー オプションを示すスクリーンショット。](media/dataflows-streaming/dataflows-streaming-02-b.png)
開いた作業ウィンドウで、ストリーミング データフローに名前を付ける必要があります。 [名前] ボックス (1) に名前を入力し、 [作成] (2) を選択します。
![新しいストリーミング データフロー ペインのスクリーンショット。[名前] と [作成] が強調表示されています。](media/dataflows-streaming/dataflows-streaming-03.png)
ストリーミング データフローの空のダイアグラム ビューが表示されます。
次のスクリーンショットは、完成したデータフローを示しています。 ストリーミング データフロー UI で作成に使用できるすべてのセクションが強調表示されています。

リボン: リボンでは、セクションが "従来" の分析プロセスの順序、つまり入力 (データソースとも呼ばれます)、変換 (ストリーミング ETL 操作)、出力に従っており、さらに進行状況を保存するためのボタンがあります。
ダイアグラム ビュー: このビューは、入力から操作、出力までのデータフローのグラフィック表現です。
作業ウィンドウ: ダイアグラム ビューで選択したコンポーネントに応じて、各入力、変換、または出力を変更するための設定が表示されます。
データのプレビュー、作成エラー、ランタイム エラーのタブ: 表示されているカードごとに、データのプレビューには、その手順の結果が表示されます (入力の場合はライブ、変換と出力の場合はオンデマンド)。
このセクションでは、データフローで発生するおそれのある作成エラーまたは警告の概要も表示されます。 各エラーまたは警告を選択すると、その変換が選択されます。 さらに、削除されたメッセージなどの、データフローが実行された後のランタイム エラーにアクセスできます。
右上隅にある矢印を選択して、ストリーミング データフローのこのセクションをいつでも最小化できます。
ストリーミング データフローは、ストリーミング入力、変換、出力の 3 つの主要コンポーネントに基づいて構築されています。 複数の入力、複数の変換を使用した並列分岐、複数の出力など、必要な数のコンポーネントを含めることができます。
ストリーミング入力の追加
ストリーミング入力を追加するには、リボンのアイコンを選択し、作業ウィンドウで必要な情報を入力して設定します。 2021 年 7 月の時点で、ストリーミング データフローのプレビューでは、入力として Azure Event Hubs と Azure IoT Hub がサポートされています。
Azure Event Hubs および Azure IoT Hub サービスは、イベントの高速でスケーラブルな取り込みと使用を容易にするために、共通のアーキテクチャに基づいて構築されています。 特に IoT Hub は、IoT アプリケーションとそれにアタッチされたデバイス間の双方向通信用の中央メッセージ ハブとして作成されています。
Azure Event Hubs
Azure Event Hubs は、ビッグ データのストリーミング プラットフォームとなるイベント インジェスト サービスです。 1 秒間に何百万ものイベントを受信して処理することができます。 イベント ハブに送信されたデータは、任意のリアルタイム分析プロバイダーを使って変換および保存できます。または、バッチ処理またはストレージ アダプターを使用できます。
ストリーミング データフローの入力としてイベント ハブを構成するには、 [イベント ハブ] アイコンを選択します。 構成用の作業ウィンドウを含むカードがダイアグラム ビューに表示されます。
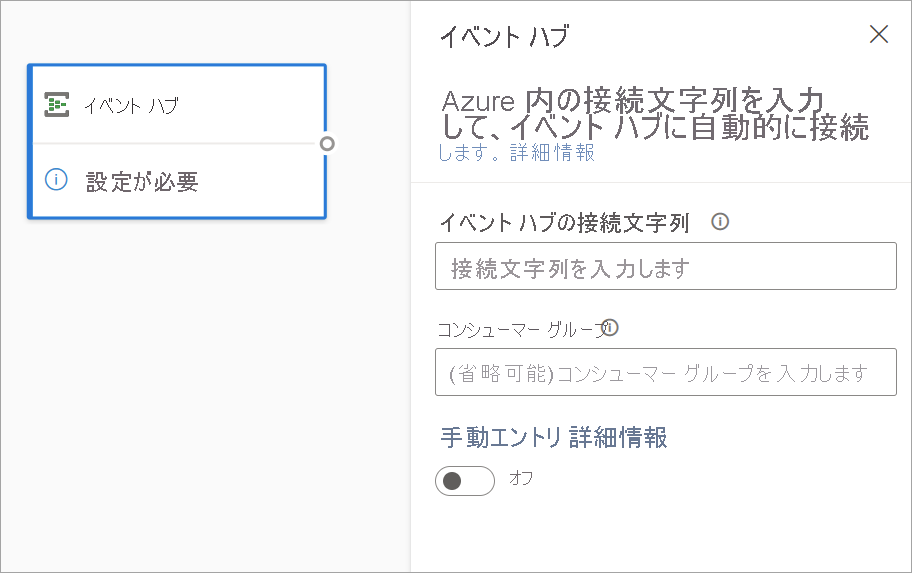
Event Hubs 接続文字列を貼り付けるオプションがあります。 ストリーミング データフローには、オプションのコンシューマー グループ (既定では $Default) を含め、必要な情報がすべて入力されます。 すべてのフィールドを手動で入力する必要がある場合は、手動入力の切り替えをオンにしてそれらを表示できます。 詳細については、「Event Hubs の接続文字列の取得」を参照してください。
Event Hubs の資格情報を設定し、 [接続] を選択した後、フィールド名がわかっている場合は [+ フィールドの追加] を使用して手動でフィールドを追加することができます。 または、受信メッセージのサンプルに基づいてフィールドとデータ型を自動的に検出するには、[フィールドの自動検出] を選択します。 必要に応じて、歯車アイコンを選択して、資格情報を編集できます。
![入力データのオプションを示すスクリーンショット。EntryTime が選択され、[その他のオプション] ツール ヒントが表示されています。](media/dataflows-streaming/dataflows-streaming-06.png)
ストリーミング データフローでフィールドが検出されると、それらが一覧に表示されます。 ダイアグラム ビューの下にある [データのプレビュー] テーブルには、受信メッセージのライブ プレビューもあります。
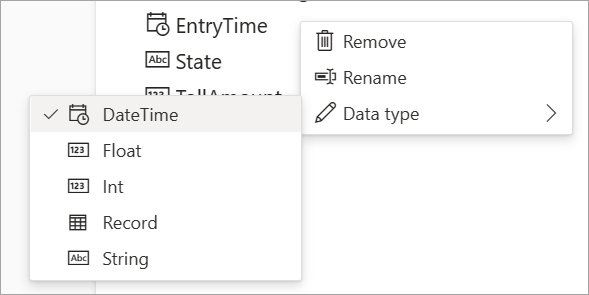
各フィールドの横にある [その他のオプション] ([...]) を選択すれば、いつでもフィールド名を編集したり、データ型を削除または変更したりできます。 さらに、次の図に示すように、受信メッセージから、入れ子になったフィールドを展開、選択、および編集することもできます。
Azure IoT Hub
IoT Hub はクラウドでホストされるマネージド サービスです。 それは、IoT アプリケーションとそれに接続されたデバイスとの間で双方向の通信の中央メッセージ ハブとしての役割を担います。 何百万ものデバイスとそのバックエンド ソリューションとを、高い信頼性で安全に接続することができます。 IoT ハブには、ほぼすべてのデバイスを接続することができます。
IoT Hub の構成は、共通のアーキテクチャのため、Event Hubs 構成に似ています。 ただし、Event Hubs 互換の組み込みエンドポイントの接続文字列がある場所など、いくつかの違いがあります。 詳しくは、「デバイスからクラウドへのメッセージを組み込みのエンドポイントから読み取る」を参照してください。
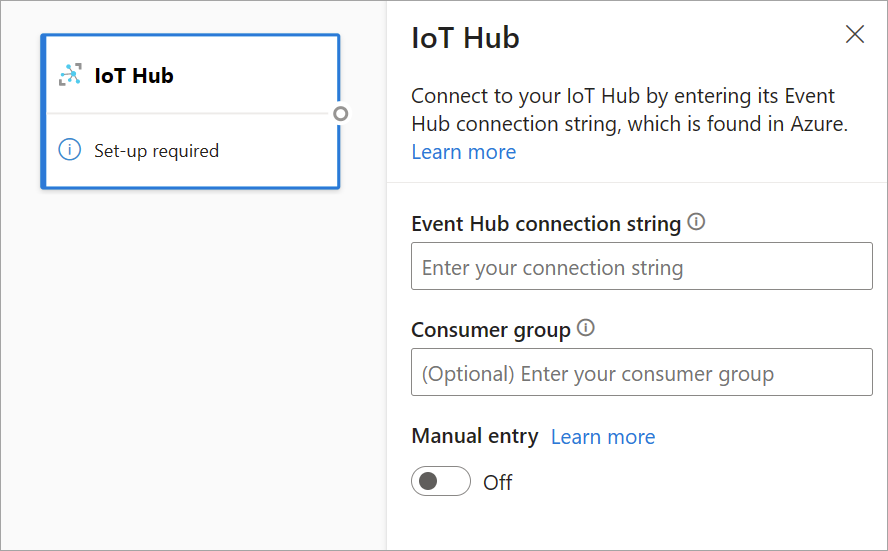
組み込みエンドポイントの接続文字列を貼り付けた後、IoT Hub から受信するフィールドを選択、追加、自動検出、編集するためのすべての機能は、Event Hubs の場合と同じです。 歯車アイコンを選択して、資格情報を編集することもできます。
ヒント
組織の Azure portal で Event Hubs または IoT Hub にアクセスでき、それをストリーミング データフローの入力として使用する場合は、次の場所で接続文字列を見つけることができます。
Event Hubs の場合:
- 分析 セクションで、すべてのサービス>Event Hubs の順に選択します。
- [Event Hubs 名前空間]>[エンティティ/Event Hubs] を選択し、イベントハブ名を選択します。
- [共有アクセス ポリシー] の一覧で、ポリシーを選択します。
- [接続文字列 - 主キー] フィールドの横にある [クリップボードにコピー] を選択します。
IoT Hub の場合:
- [モノのインターネット] セクションで、 [すべてのサービス]>[IoT Hub] の順に選択します。
- 接続先の IoT ハブ を選択し、 [組み込みのエンドポイント] を選択します。
- Event Hubs 互換エンドポイントの横にある [クリップボードにコピー] を選択します。
Event Hubs または IoT Hub からのストリーム データを使用する場合、ストリーミング データフローで次のメタデータ時間フィールドにアクセスできます。
- EventProcessedUtcTime: イベントが処理された日付と時刻。
- EventEnqueuedUtcTime: イベントが受信された日付と時刻。
これらのフィールドはいずれも入力プレビューに表示されません。 手動で追加する必要があります。
BLOB ストレージ
Azure Blob Storage は、Microsoft のクラウド用オブジェクト ストレージ ソリューションです。 Blob Storage は、大量の非構造化データを格納できるよう最適化されています。 非構造化データとは、特定のデータ モデルや定義に従っていないデータであり、テキスト データやバイナリ データなどがあります。
Azure BLOB は、ストリーミングや参照入力として使用できます。 ストリーミング BLOB は 1 秒ごとに更新がチェックされます。 ストリーミング BLOB とは異なり、参照 BLOB は更新の開始時にのみ読み込まれます。 これは変更が想定されない静的データであり、静的データの推奨される制限は 50 MB 以下です。
Power BI では、参照 BLOB がストリーミング ソースと共に使用されることを想定しています (たとえば JOIN を介して)。 このため、参照 BLOB を持つストリーミング データフローには、ストリーミング ソースも必要です。
Azure BLOB の構成は、Azure Event Hubs ノードの構成とは少し異なります。 Azure BLOB の接続文字列を見つけるには、「アカウント アクセス キーの表示」を参照してください。
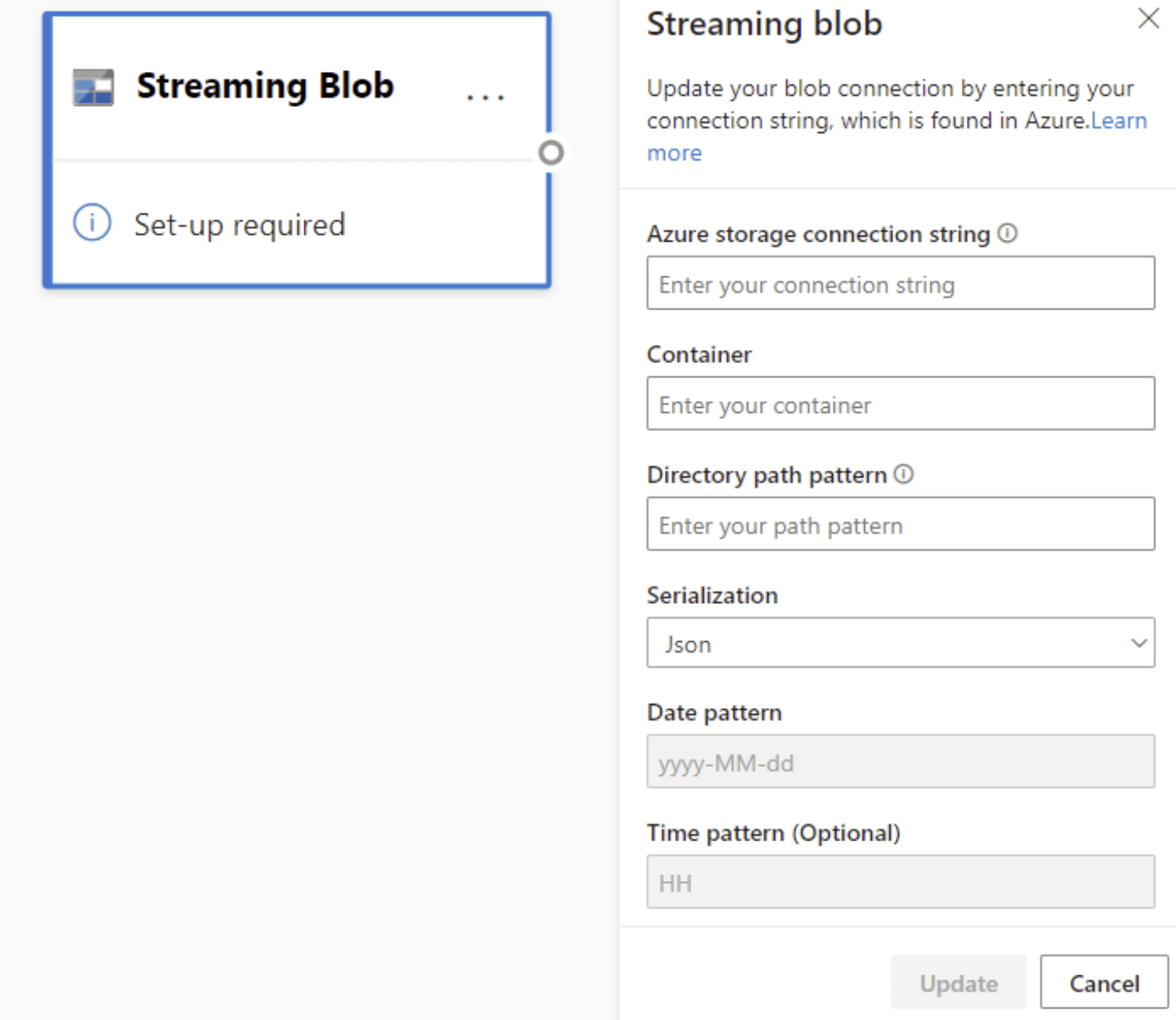
BLOB の接続文字列を入力したら、コンテナーの名前を指定する必要があります。 また、データフローのソースとして設定するファイルにアクセスするために、ディレクトリ内のパス パターンを入力する必要があります。
ストリーミング BLOB の場合、ディレクトリのパス パターンは動的な値であると想定されます。 日付は、BLOB のファイルパスの一部にする必要があります。これは {date} として参照されます。 また、パス パターン内でのアスタリスク (*) の使用はサポートされていません (例: {date}/{time}/*.json)。
たとえば、入れ子になった .json ファイルを格納する ExampleContainer という名前の BLOB があり、1 番目のレベルが作成日、2 番目のレベルが作成時刻である場合 (yyyy-mm-dd/hh)、コンテナーの入力は "ExampleContainer" になります。 ディレクトリ パスのパターンは "{date}/{time}" になります。日付と時刻のパターンは変更可能です。

BLOB をエンドポイントに接続すると、Azure BLOB から入力されるフィールドを選択、追加、自動検出、編集するための機能は、すべて Event Hubs と同じになります。 歯車アイコンを選択して、資格情報を編集することもできます。
リアルタイムのデータを使う場合、データは圧縮されることが多く、そのオブジェクトを表すために識別子が使われます。 BLOB のユース ケースとしては、ストリーミング ソースの参照データとしての使用も考えられます。 参照データを使うと、静的なデータをストリーミング データに結合して、分析用のストリームを強化できます。 この機能が役立つ簡単な例としては、さまざまなデパートにセンサーを設置して、特定の時間に何人の人が店舗に入っているかを測定する場合が挙げられます。 通常、センサー ID を静的テーブルに結合して、センサーが配置されているデパートと場所を示す必要があります。 ここで参照データを使うと、インジェスト フェーズ中にこのデータを結合して、ユーザーの活動が最も多い店舗を簡単に確認できます。
Note
ストリーミング データフロー ジョブは、BLOB ファイルが使用可能な場合、Azure Blob ストレージか ADLS Gen2 の入力から 1 秒ごとにデータをプルします。 BLOB ファイルが使用不可能な場合は、最大で 90 秒の時間遅延がある指数関数的バックオフがあります。
データ型
ストリーミング データフロー フィールドに使用できるデータ型は次のとおりです。
- DateTime: ISO 形式の日付と時刻フィールド
- Float: 10 進数
- Int: 整数
- Record: 複数のレコードを含む入れ子になったオブジェクト
- String: テキスト
重要
ストリーミングの入力用に選択されたデータ型は、ストリーミング データフローのダウンストリームに重要な影響を与えます。 後で編集のために停止する必要がないように、データフローでできるだけ早くデータ型を選択してください。
ストリーミング データ変換の追加
ストリーミング データの変換はバッチ データの変換とは本質的に異なります。 ほとんどすべてのストリーミング データには時間コンポーネントがあり、関連するすべてのデータ準備タスクに影響を与えます。
ストリーミング データ変換をデータフローに追加するには、その変換のリボンにある変換アイコンを選択します。 それぞれのカードがダイアグラム ビューに表示されます。 それを選択すると、その変換用の作業ウィンドウが表示され、構成することができます。
2021 年 7 月の時点で、ストリーミング データフローでは、次のストリーミング変換がサポートされています。
Assert
フィルター変換を使用して、入力のフィールドの値に基づいてイベントをフィルター処理します。 データ型 (数値またはテキスト) に応じて、変換では選択した条件に一致する値が保持されます。
![コンテナーの例の構成に使われる [フィルター] の入力ボックスを示すスクリーンショット。](media/dataflows-streaming/dataflows-streaming-09.png)
Note
すべてのカード内には、変換の準備を完了するために他に何が必要であるかについて情報が表示されます。 たとえば、新しいカードを追加すると、"セットアップが必要" というメッセージが表示されます。 ノード コネクタがない場合は、"エラー" または "警告" メッセージが表示されます。
フィールドの管理
フィールドの管理変換では、入力または別の変換から受信するフィールドの追加、削除、または名前の変更を行うことができます。 作業ウィンドウの設定で、 [フィールドの追加] を選択して新しいフィールドを追加するか、またはすべてのフィールドを一度に追加するかを選択できます。
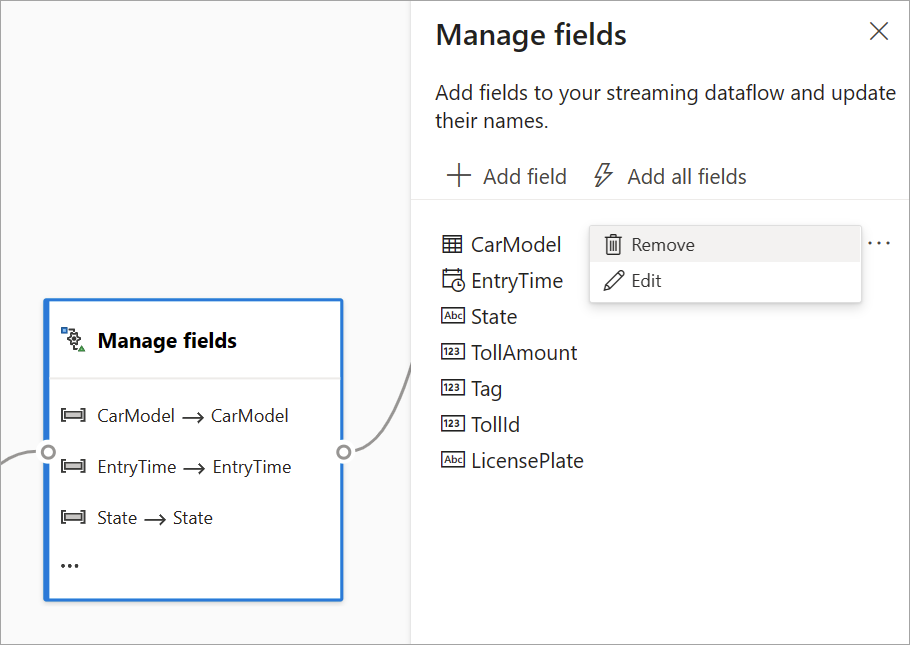
ヒント
カードを構成すると、ダイアグラム ビューで、カード自体の設定を簡単に確認できます。 たとえば、前の画像の [フィールドの管理] 領域では、最初の 3 つのフィールドが管理されており、それらに新しい名前が割り当てられているのがわかります。 各カードには、それに関連する情報が含まれます。
Aggregate
集計変換を使用すると、一定期間に新しいイベントが発生するたびに、集計 ( [合計] 、 [最小] 、 [最大] 、または [平均] ) を計算できます。 この操作により、データ内の他のディメンションに基づいて集計のフィルター処理またはスライスを行うこともできます。 同じ変換に 1 つ以上の集計を含めることができます。
集計を追加するには、変換アイコンを選択します。 次に、入力を接続し、集計を選択して、フィルターまたはスライス ディメンションを追加し、集計を計算する期間を選択します。 この例では、過去 10 秒間の通行料金の合計を、車両の出発地の州別に計算します。
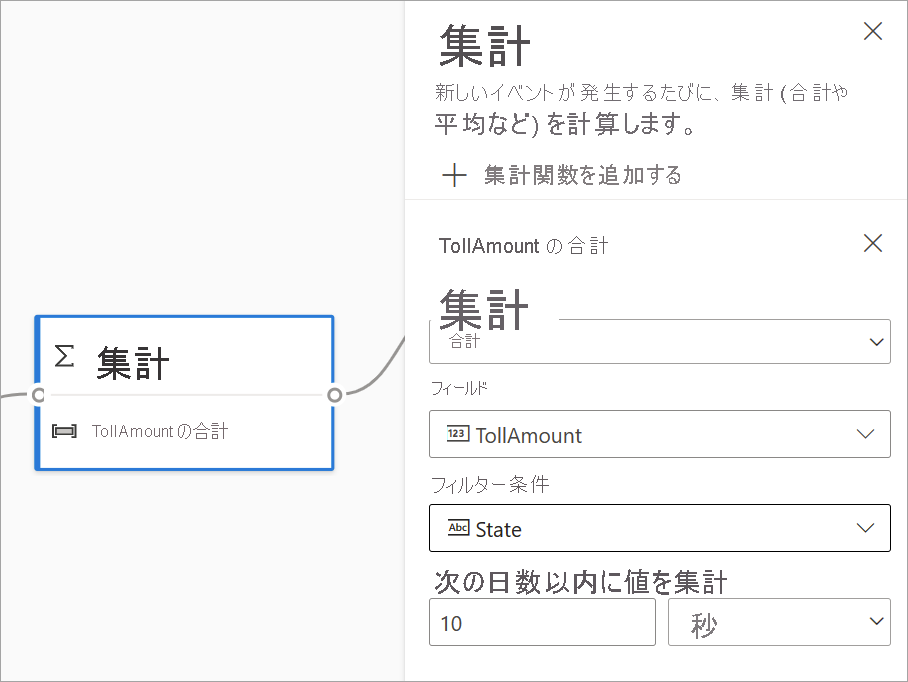
同じ変換に別の集計を追加するには、 [集計関数の追加] を選択します。 フィルターまたはスライスは、変換内のすべての集計に適用されることに注意してください。
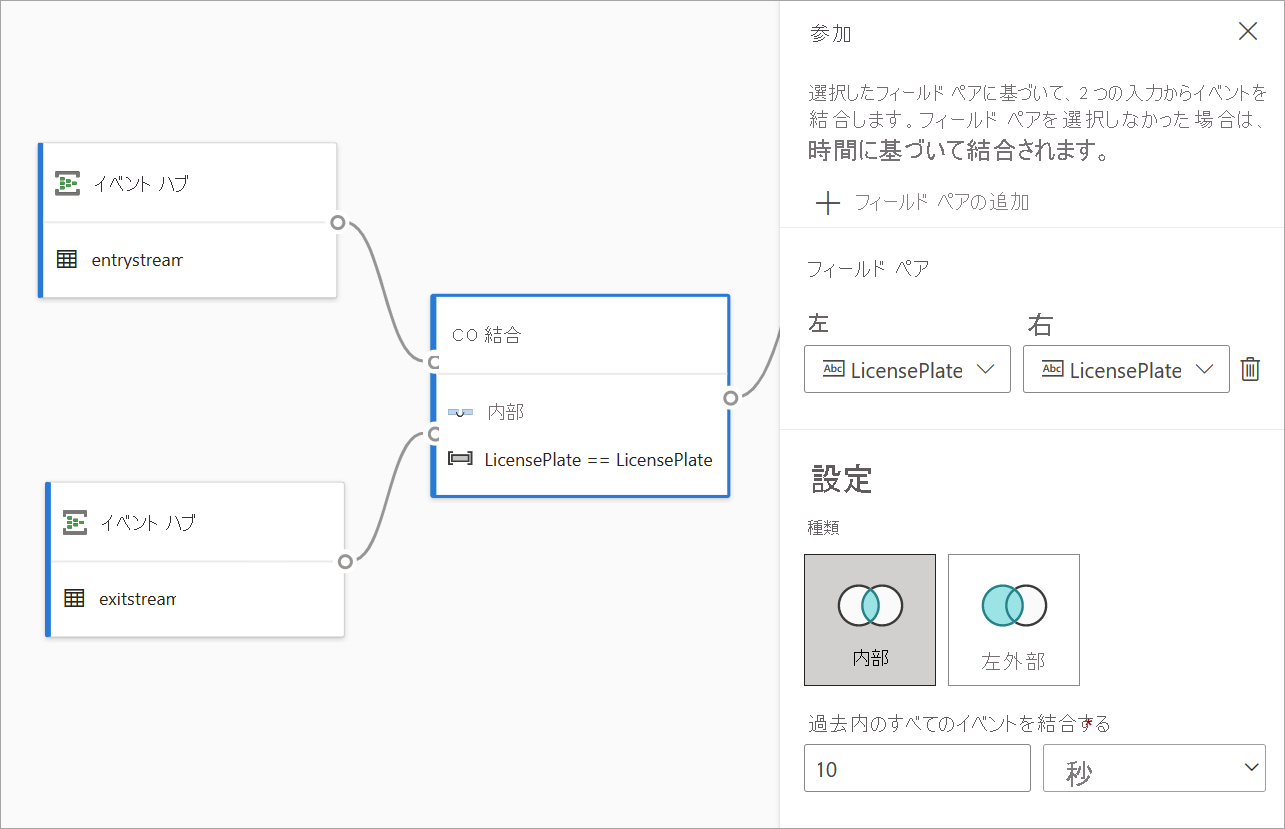
Join
結合変換を使用することにより、選択したフィールドのペアに基づいて、2 つの入力からのイベントを組み合わせます。 フィールドのペアを選択しない場合、結合は、既定で時間に基づきます。 この既定によって、この変換をバッチ変換とは異なるものにしています。
通常の結合と同様に、結合ロジックにはさまざまなオプションがあります。
- 内部結合: ペアが一致する両方のテーブルからのレコードのみが含まれます。 この例では、それはライセンス プレートが両方の入力と一致している場所になります。
- 左外部結合: 左側 (最初) のテーブルからのすべてのレコードと、フィールドのペアと一致する、2 番目のテーブルからのレコードのみが含まれます。 一致するものがない場合、2 番目の入力からのフィールドは空白になります。
結合の種類を選択するには、作業ウィンドウで、優先する種類のアイコンを選択します。
最後に、結合を計算する時間を選択します。 この例では、結合は、過去 10 秒間を対象とします。 期間が長くなるほど、出力の頻度が少なくなり、変換に使用される処理リソースが増えることに注意してください。
既定では、両方のテーブルのすべてのフィールドが含まれます。 出力でプレフィックスの left (最初のノード) と right (2 番目のノード) は、ソースを区別するのに役立ちます。
グループ化
グループ化変換を使用して、特定の時間ウィンドウ内のすべてのイベントの集計を計算します。 1 つまたは複数のフィールドの値でグループ化することができます。 これは、集計変換に似ていますが、より多くの集計のためのオプションが用意されています。 より複雑な時間ウィンドウ オプションも含まれています。 さらに、集計と同様に、変換あたり複数の集計を追加できます。
この変換で使用できる集計は、 [平均] 、 [カウント] 、 [最大] 、 [最小] 、 [パーセンタイル] (連続と離散)、 [標準偏差] 、 [合計] 、 [差異] です。
この変換を構成するには:
- 優先する集計を選択します。
- 集計するフィールドを選択します。
- 別のディメンションまたはカテゴリ (状態など) に対する集計計算を取得する場合は、オプションのグループ化フィールドを選択します。
- 時間ウィンドウの関数を選択します。
同じ変換に別の集計を追加するには、 [集計関数の追加] を選択します。 [グループ化] フィールドとウィンドウ関数は、変換内のすべての集計に適用されることに注意してください。
![[グループ化] カードのスクリーンショット。構成ペインが開いています。](media/dataflows-streaming/dataflows-streaming-13.png)
時間ウィンドウの終了のタイム スタンプは、参照のために変換出力の一部として提供されます。
この記事の後半のセクションで、この変換に使用できる時間ウィンドウの各種類について説明します。
Union
和集合変換を使用して、2 つ以上の入力を接続して、共有フィールド (同じ名前とデータ型を持つ) を含むイベントを 1 つのテーブルに追加します。 一致しないフィールドは削除され、出力に含まれません。
時間ウィンドウ関数の設定
時間ウィンドウは、ストリーミング データで最も複雑な概念の 1 つです。 この概念は、ストリーミング分析の中核に位置付けられます。
ストリーミング データフローによって、グループ化変換のオプションとして、データを集計するときに時間ウィンドウを設定できます。
Note
ウィンドウ操作のすべての出力結果は、時間ウィンドウの終了時に計算されることにご注意ください。 ウィンドウの出力は、集計関数に基づく単一のイベントになります。 このイベントには、ウィンドウの終了のタイム スタンプがあり、すべてのウィンドウ関数は固定長で定義されています。
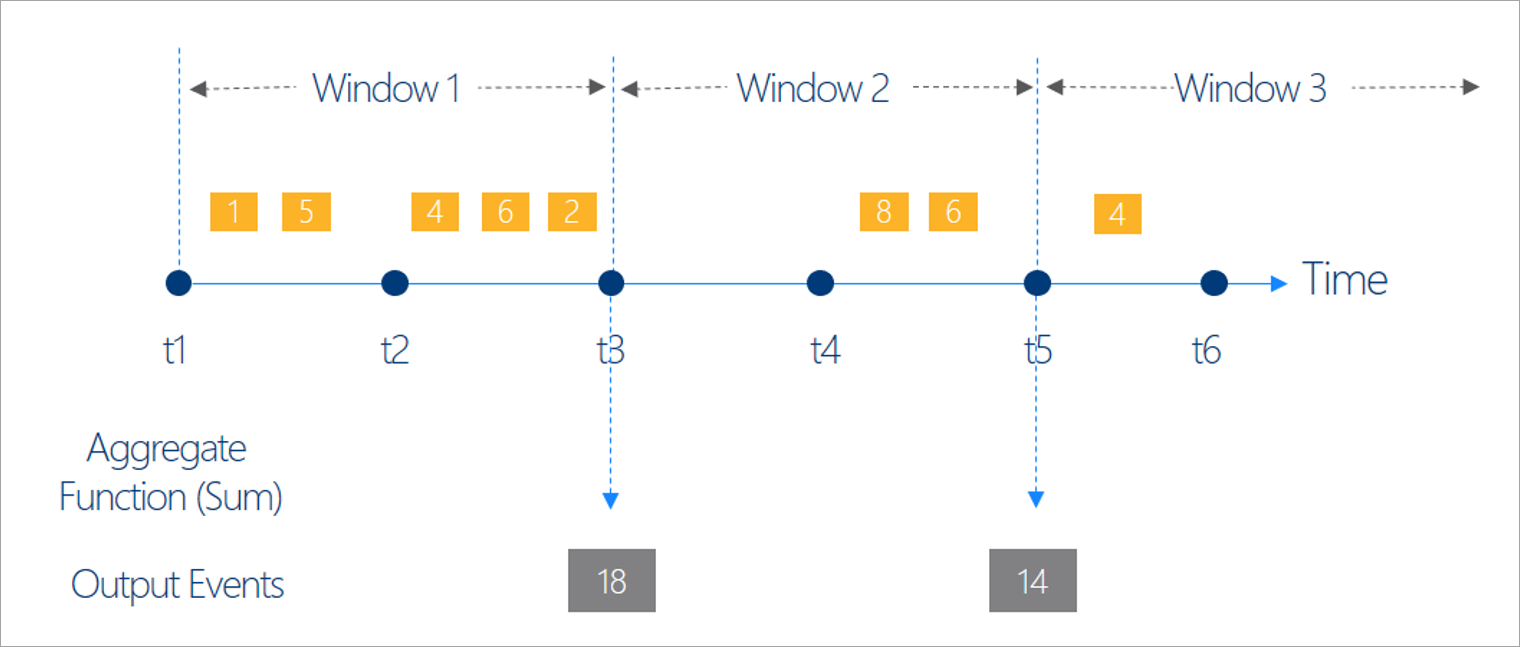
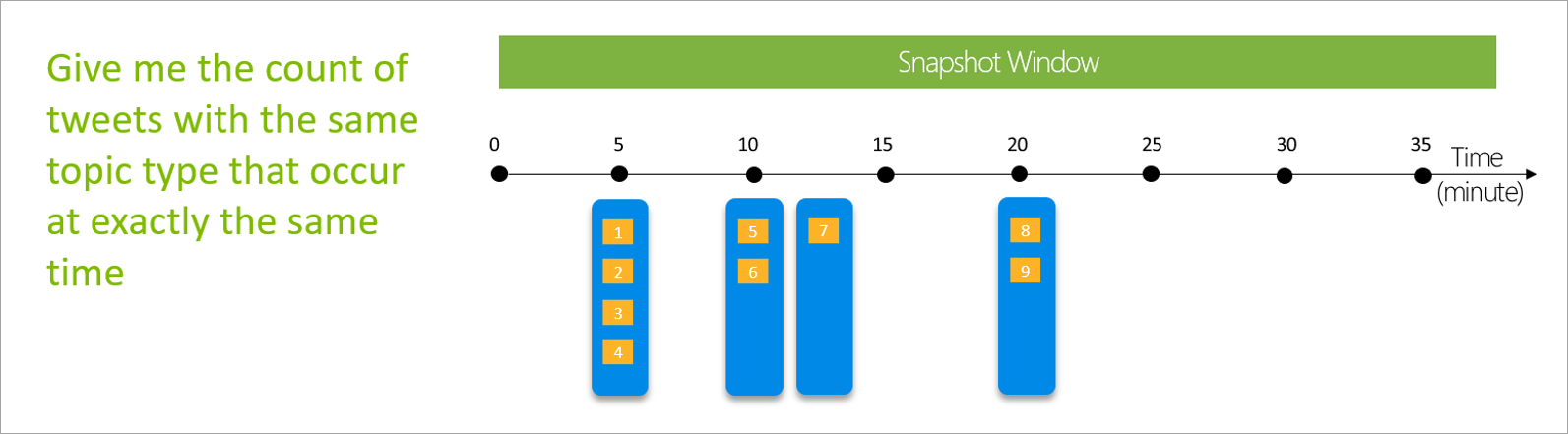
選択できる時間ウィンドウには、タンブリング、ホッピング、スライディング、セッション、およびスナップショットの 5 種類があります。
タンブリング ウィンドウ
タンブリングは、時間ウィンドウの最も一般的な種類です。 タンブリング ウィンドウの主な特性は、繰り返し、同じ時間の長さ、重複しないことです。 イベントは、複数のタンブリング ウィンドウに属することはできません。
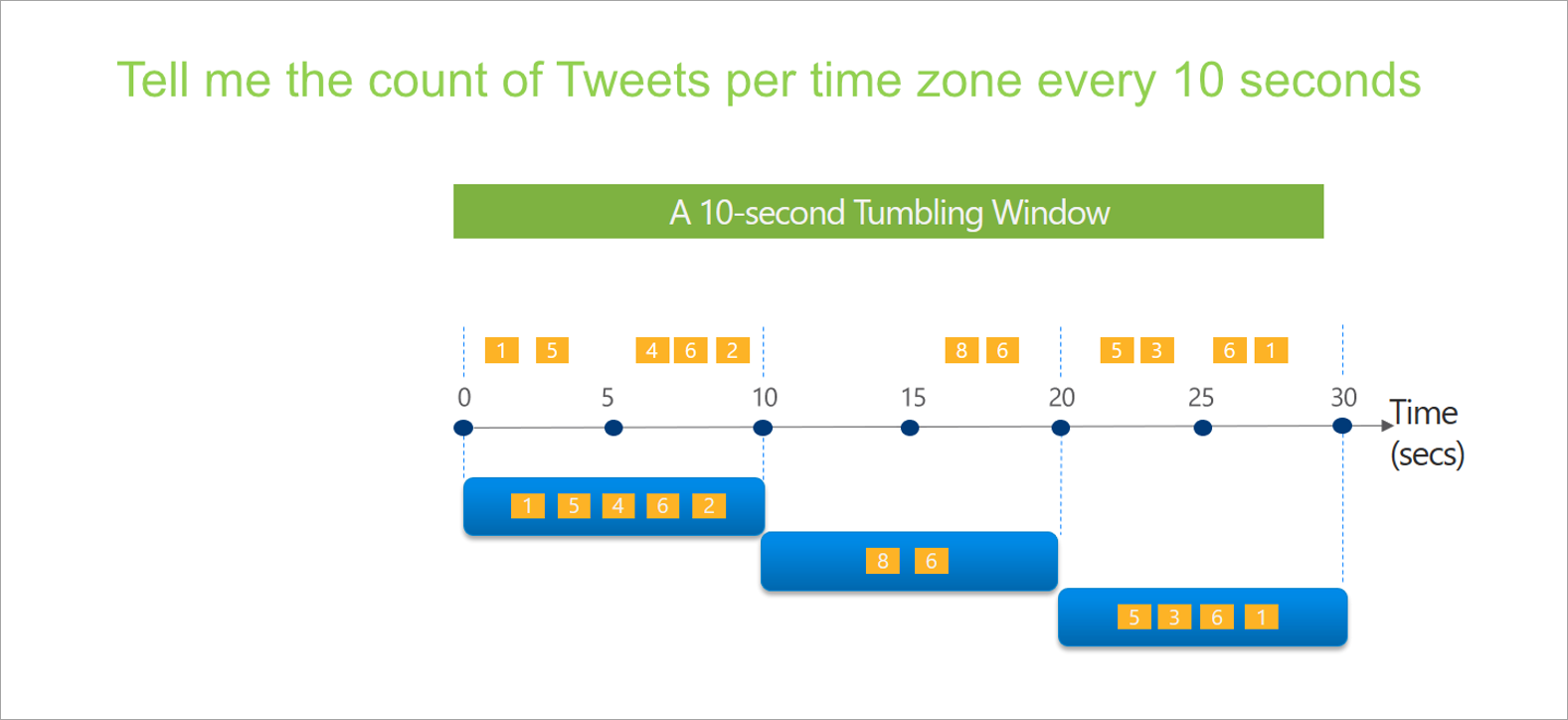
ストリーミング データフローでタンブリング ウィンドウを設定する場合、ウィンドウの期間を指定する必要があります (この例ではすべてのウィンドウで同じです)。 さらに、オプションのオフセットを指定することもできます。 既定で、タンブリング ウィンドウにはウィンドウの終了が含まれ、開始は除外されます。 このパラメーターを使用してこの動作を変更し、ウィンドウの開始時のイベントを含めて、終了時のイベントを除外できます。
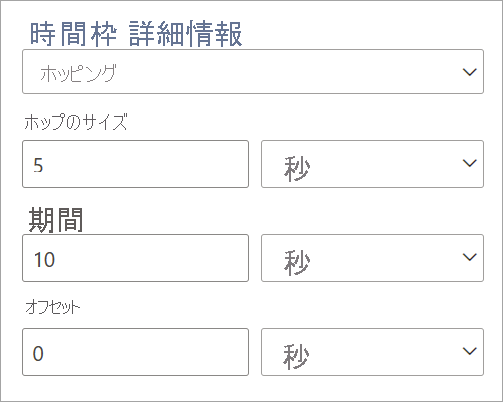
ホッピング ウィンドウ
ホッピング ウィンドウでは、時間を一定の期間だけ前に "ホップ" します。 それらは、ウィンドウ サイズよりも頻繁に重複して出力できるタンブリング ウィンドウと考えることができます。 イベントはホッピング ウィンドウの複数の結果セットに属することができます。 ホッピング ウィンドウをタンブリング ウィンドウと同じにするには、ホップ サイズとして、ウィンドウ サイズと同じ値を指定します。
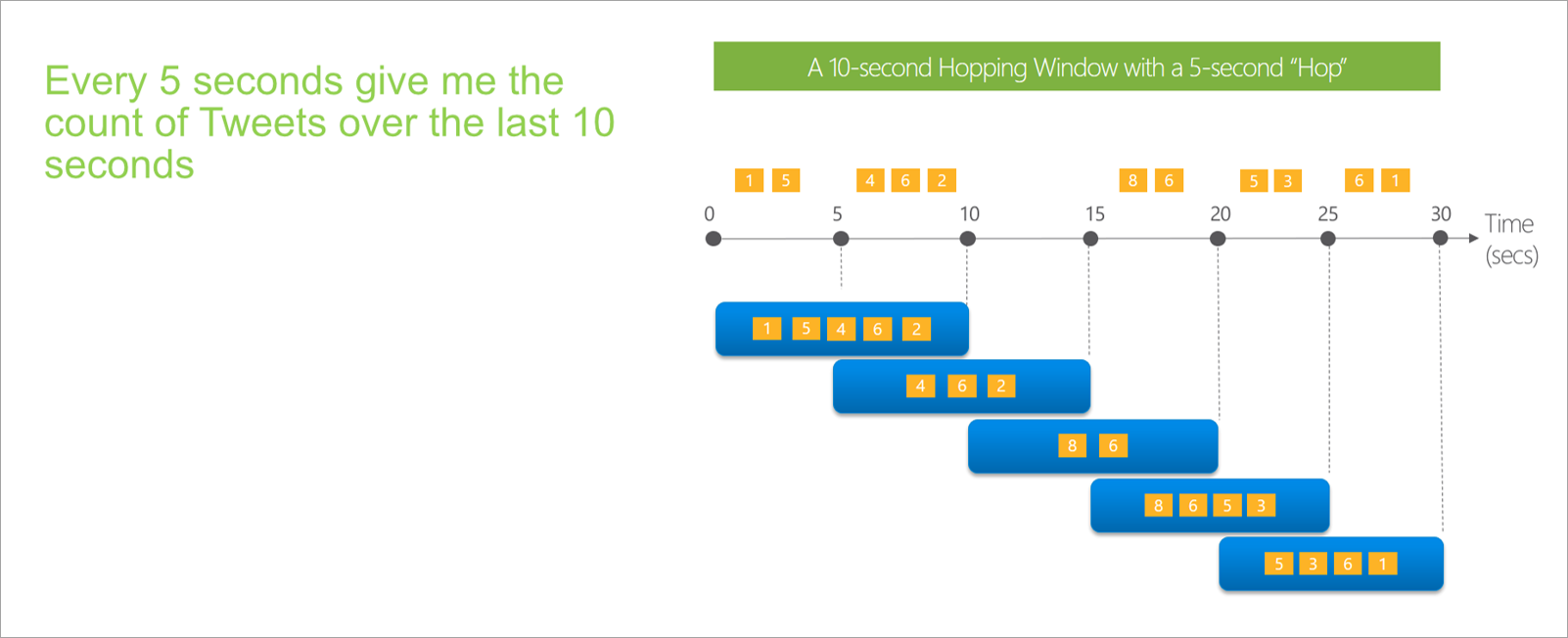
ストリーミング データフローでホッピング ウィンドウを設定する場合、ウィンドウの期間を指定する必要があります (タンブリング ウィンドウと同様に)。 また、ホップ サイズも指定する必要があります。これは、定義された期間で集計を計算する頻度をストリーミング データフローに指示します。
オフセット パラメーターは、ホッピング ウィンドウでもタンブリング ウィンドウと同じ理由で使用できます。 ホッピング ウィンドウの開始と終了のイベントを含めたり除外したりするためのロジックを定義できます。
スライディング ウィンドウ
スライディング ウィンドウでは、タンブリング ウィンドウやホッピング ウィンドウとは異なり、ウィンドウのコンテンツが実際に変更された時点の集計のみが計算されます。 イベントがウィンドウに入るか出るときに、集計が計算されます。 そのため、すべてのウィンドウに少なくとも 1 つのイベントがあります。 ホッピング ウィンドウと同様に、イベントは複数のスライディング ウィンドウに属することができます。
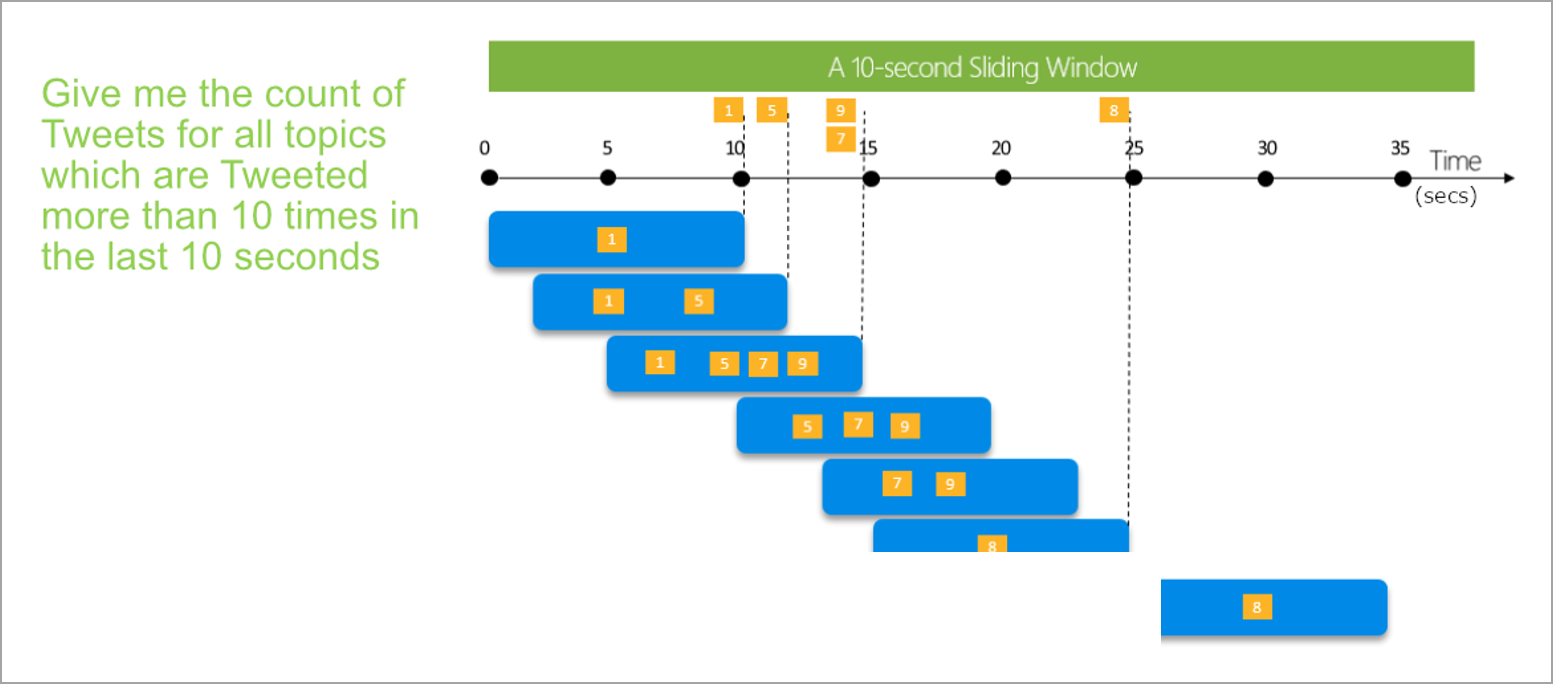
スライディング ウィンドウに必要な唯一のパラメーターは、イベント自体がウィンドウの開始時を定義するため、期間です。 オフセット ロジックは必要ありません。

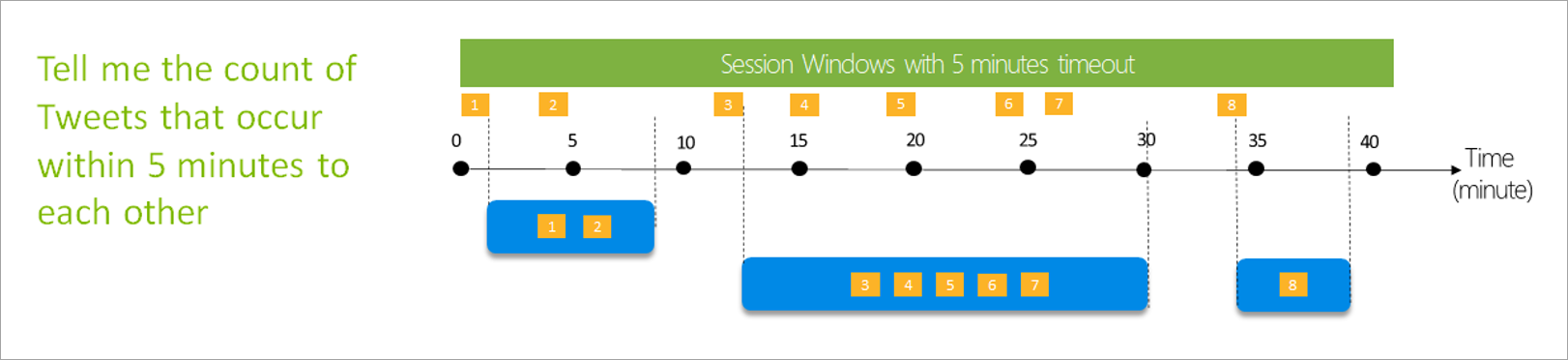
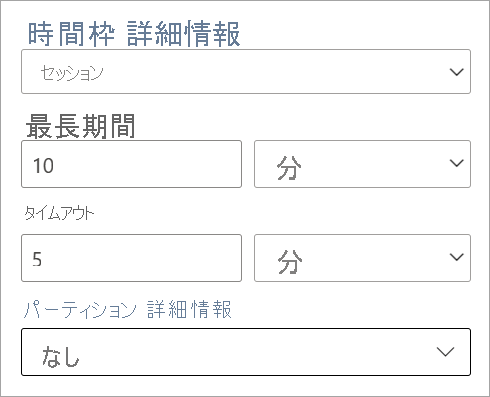
セッション ウィンドウ
セッション ウィンドウは、最も複雑な種類です。 それらは、同様の時刻に到着するイベントをグループ化し、データがない期間をフィルターで除外します。 このウィンドウには、次を指定する必要があります。
- タイムアウト: 新しいデータがない場合に待機する時間。
- 最大期間: データが継続して送信されてくる場合に集計が計算される最長時間。
必要に応じて、パーティションを定義することもできます。
セッション ウィンドウは、変換の作業ウィンドウで直接設定します。 パーティションを指定した場合、集計では、同じキーのイベントのみがグループ化されます。
スナップショット ウィンドウ
スナップショット ウィンドウでは、同じタイム スタンプを持つイベントがグループ化されます。 他のウィンドウとは異なり、スナップショットではシステムの時間が使用されるため、パラメーターは必要ありません。
出力を定義する
入力と変換を設定したら、1 つ以上の出力を定義します。 2021 年 7 月の時点で、ストリーミング データフローでは Power BI テーブルが出力の唯一の種類としてサポートされています。
この出力は、Power BI Desktop でレポートを作成するために使用できるデータフロー テーブル (つまりエンティティ) になります。 それを機能させるには、前の手順のノードを、作成している出力と結合させる必要があります。 その後、テーブルに名前を付けます。
データフローに接続したら、レポート用にリアルタイムで更新されるビジュアルを作成するために、このテーブルを使用できます。
データのプレビューとエラー
ストリーミング データフローには、ストリーミング データの分析パイプラインの作成、トラブルシューティング、パフォーマンスの評価を行うのに役立つツールが用意されています。
入力のライブ データ プレビュー
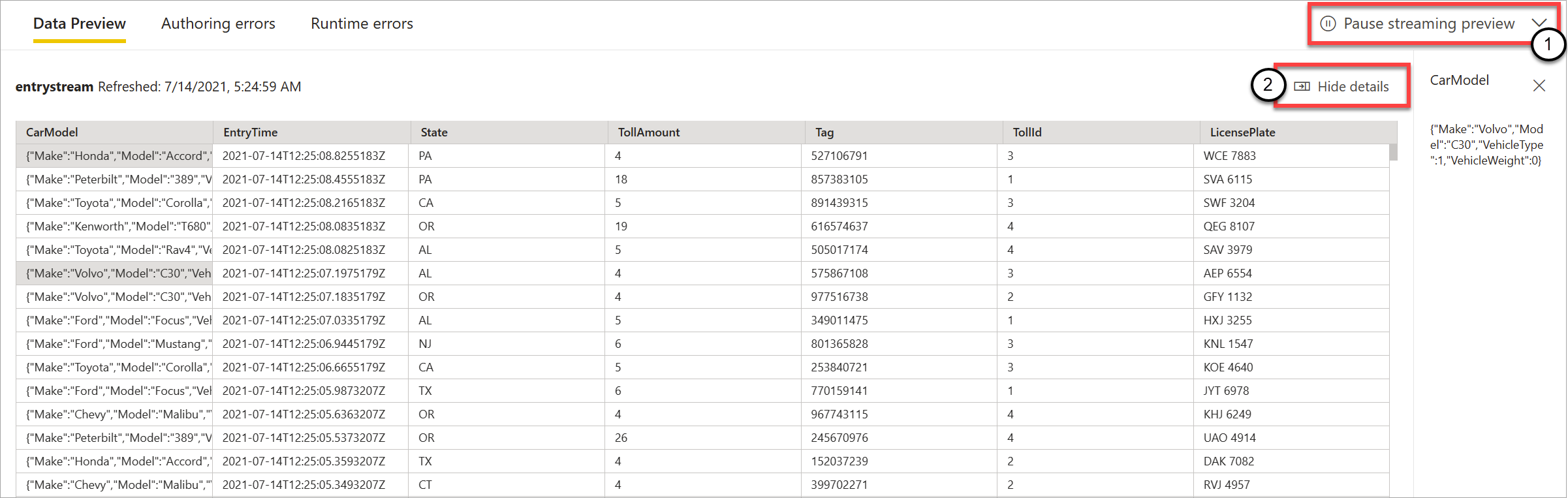
イベント ハブまたは IoT ハブに接続し、ダイアグラム ビュー ([データ プレビュー] タブ) でそのカードを選択すると、次のすべての条件が当てはまる場合に、受信するデータのライブ プレビューが表示されます。
- データがプッシュされている。
- 入力が正しく構成されている。
- フィールドが追加された。
次のスクリーンショットに示すように、特定のものを表示またはドリルダウンする場合は、プレビューを一時停止することができます (1)。 または、完了したら、再度開始できます。
また、特定のレコード (テーブル内の "セル") の詳細を確認するには、それを選択した後、[詳細の表示] または [詳細の非表示] を選択します (2)。 スクリーンショットに、レコードの入れ子になったオブジェクトの詳細ビューが示されています。
変換および出力の静的プレビュー
ダイアグラム ビューでステップを追加して設定したら、静的データ ボタンを選択して、それらの動作をテストできます。

これを行うと、ストリーミング データフローにより、正しく構成されているすべての変換と出力が評価されます。 次に、ストリーミング データフローにより、次の図に示すように、結果が静的データ プレビューに表示されます。
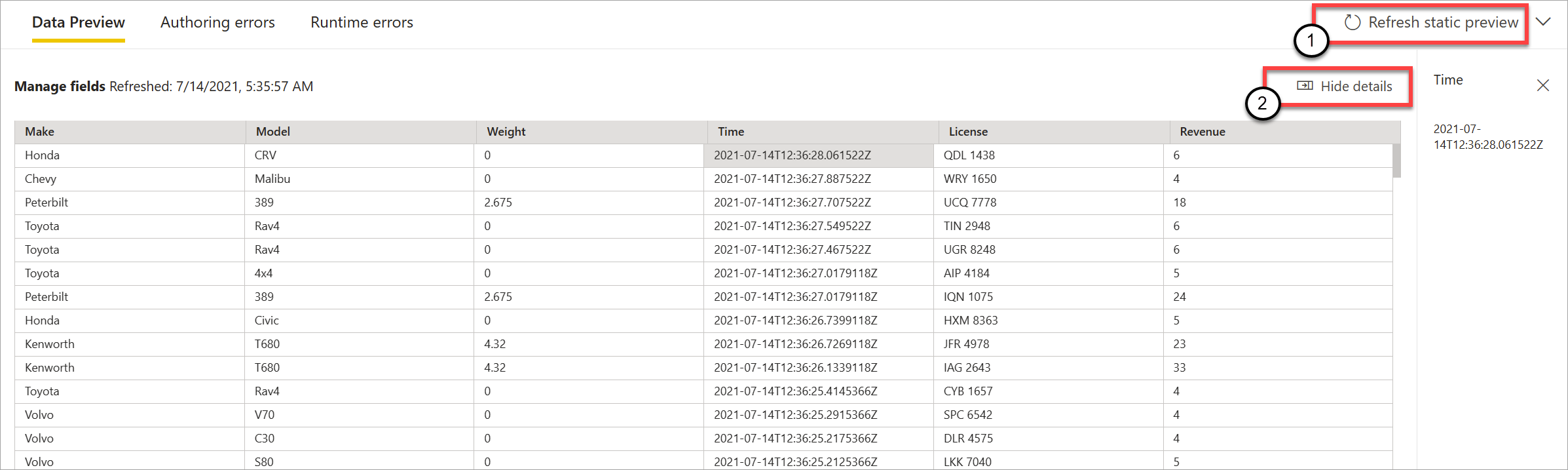
プレビューを更新するには、 [静的プレビューの更新] を選択します (1)。 これを行うと、ストリーミング データフローは入力から新しいデータを取得し、実行する可能性のある更新を使用してすべての変換と出力を再び評価します。 [詳細の表示] または [詳細の非表示] オプションも使用できます (2)。
作成エラー
作成エラーや警告がある場合は、次のスクリーンショットに示すように、[作成エラー] タブ (1) にそれらが一覧表示されます。 この一覧には、エラーや警告の詳細、カードの種類 (入力、変換、または出力)、エラー レベル、エラーまたは警告の説明が含まれます (2)。 いずれかのエラーまたは警告を選択すると、それぞれのカードが選択され、構成の作業ウィンドウが開くので、必要な変更を行うことができます。

実行時エラー
プレビューの最後に使用可能なタブは、次のスクリーンショットに示すように、実行時エラー (1) です。 このタブには、ストリーミング データフローの開始後に、その取り込みおよび分析中のエラーが一覧表示されます。 たとえば、受信したメッセージが破損しており、データフローでそれを取り込んで、定義された変換を実行できなかった場合に、実行時エラーを受け取ることがあります。
データフローは長期間実行される可能性があるため、このタブには、期間でフィルター処理するオプションと、エラーの一覧をダウンロードし、必要に応じて更新するオプションがあります (2)。

ストリーミング データフローの設定を変更する
通常のデータフローと同様に、所有者および作成者のニーズに応じて、ストリーミング データフローの設定を変更することができます。 次の設定は、ストリーミング データフローに固有です。 設定の残りについては、2 種類のデータフロー間の共有インフラストラクチャのため、使用方法は同じであると見なすことができます。
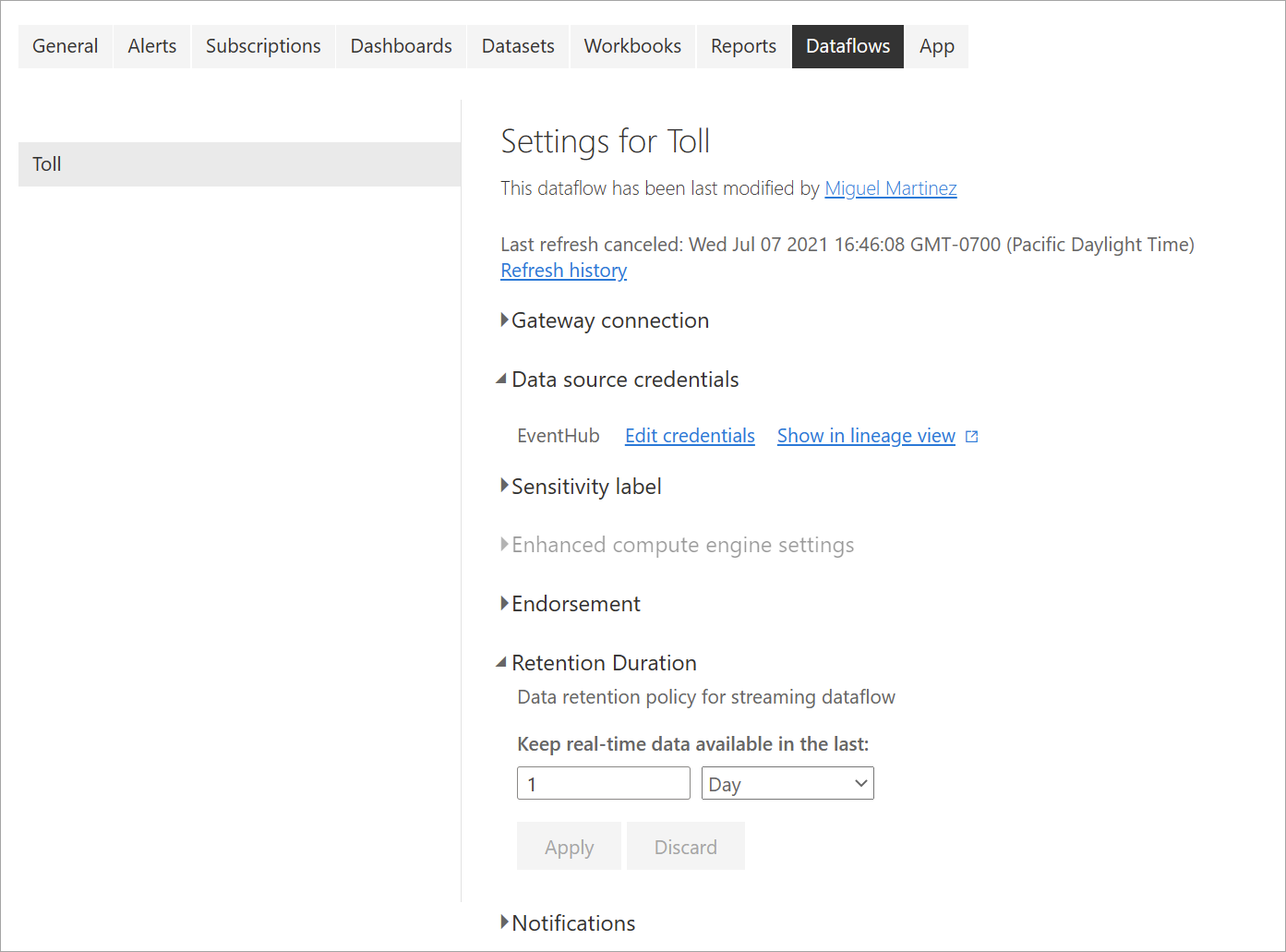
更新履歴: ストリーミング データフローは継続的に実行されるため、更新履歴には、データフローがいつ開始されたか、いつキャンセルされたか、またはいつ失敗したかに関する情報のみが (該当する場合は詳細およびエラー コードと共に) 表示されます。 この情報は、通常のデータフローの場合に表示されるものと似ています。 この情報は、問題のトラブルシューティングまたは Power BI サポートに必要な詳細を提供するためにも使用できます。
データ ソースの資格情報: この設定には、特定のストリーミング データフローに対して構成された入力が表示されます。
拡張コンピューティング エンジンの設定: ストリーミング データフローでは、リアルタイムのビジュアルを提供するために拡張コンピューティング エンジンが必要であるため、この設定は既定でオンにされており、変更できません。
リテンション期間: この設定は、ストリーミング データフローに固有です。 ここでは、レポートでリアルタイム データを視覚化し続ける期間を定義できます。 履歴データは、既定で Azure Blob Storage に保存されます。 この設定は、データのリアルタイム側 (ホット ストレージ) に固有です。 最小値は、1 日または 24 時間です。
重要
このリテンション期間によって格納されるホット データの量は、このデータに基づいてレポートを作成する際のリアルタイム ビジュアルのパフォーマンスに直接影響します。 このリテンション期間が長いほど、レポートのリアルタイム ビジュアルが低パフォーマンスによる影響を受ける可能性が高くなります。 履歴分析を実行する必要がある場合は、ストリーミング データフロー用に提供されているコールド ストレージを使う必要があります。
ストリーミング データフローの実行と編集
ストリーミング データフローを保存して構成すると、実行する準備がすべて整います。 その後、定義したストリーミング分析ロジックで Power BI へのデータの取り込みを開始できます。
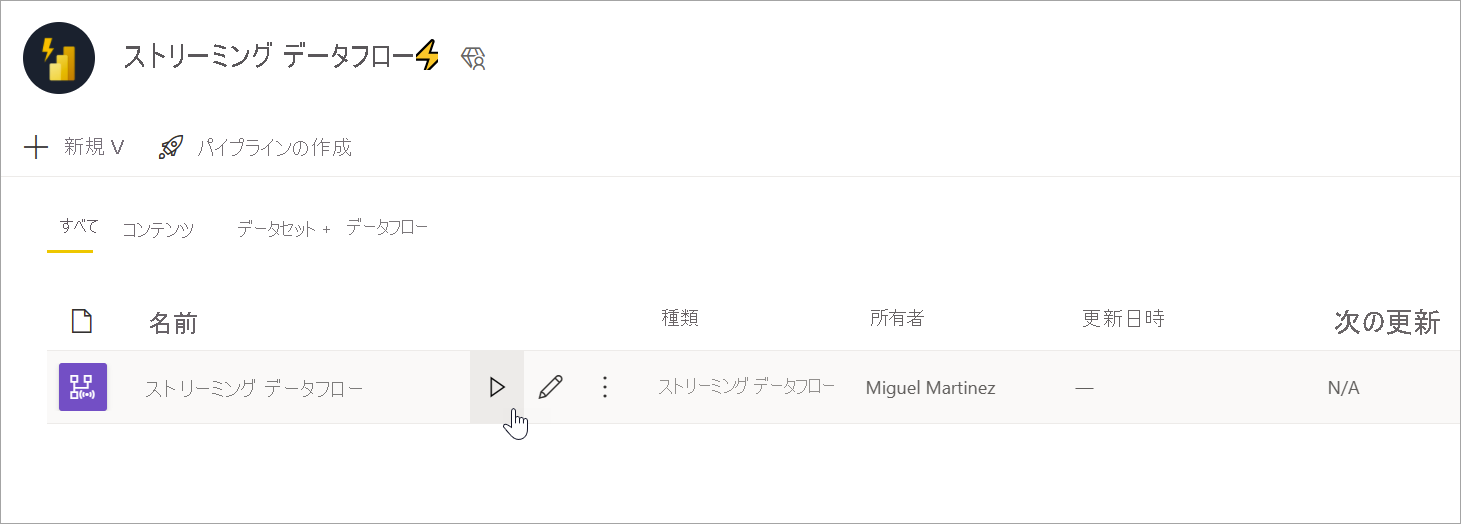
ストリーミング データフローを実行する
ストリーミング データフローを開始するには、まずデータフローを保存し、それを作成したワークスペースに移動します。 ストリーミング データフローをポイントし、表示される再生ボタンを選択します。 ポップアップ メッセージに、ストリーミング データフローが開始されていることが示されます。
Note
データの取り込みが開始され、Power BI Desktop でレポートとダッシュボードを作成するために、データの受信が確認されるまで、最大 5 分かかる場合があります。
ストリーミング データフローを編集する
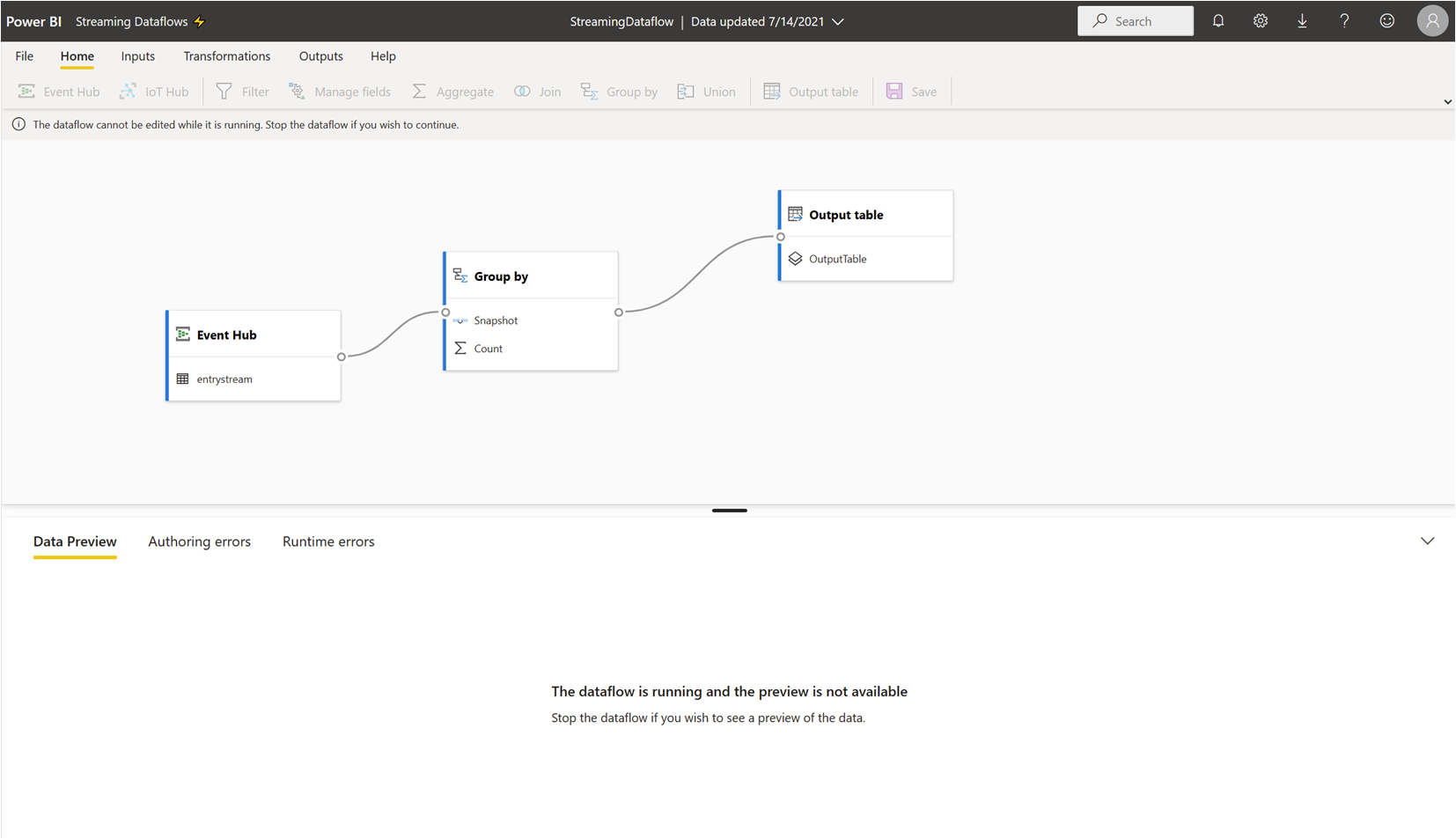
ストリーミング データフローが実行中に、編集することはできません。 ただし、ユーザーは、実行中の状態のストリーミング データフローに入り、データフローが構築されている分析ロジックを確認できます。
実行中のストリーミング データフローに入ると、すべての編集オプションが無効になっており、"実行中はデータフローを編集できません。 続行する場合は、データフローを停止してください。" というメッセージが表示されます。データのプレビューも無効になっています。
ストリーミング データフローを編集するには、それを停止する必要があります。 "データフローが停止すると、データが欠落します。"
ストリーミング データフローの実行中に使用できるエクスペリエンスは、[ランタイム エラー] タブのみです。ここでは、削除されたメッセージや同様の状況についてデータフローの動作を監視できます。
データフローの編集時にデータ ストレージを考慮する
データフローを編集する場合は、他の考慮事項を考慮する必要があります。 通常のデータフローに対するスキーマの変更と同様に、出力テーブルに変更を加えると、既にプッシュされ、Power BI に保存されているデータが失われます。 インターフェイスによって、保存する前に行う変更のための選択肢と共に、ストリーミング データフローでのこれらの変更の結果について明確な情報が提供されます。
このエクスペリエンスを、例でわかりやすく示します。 次のスクリーンショットは、1 つのテーブルに列を追加し、2 番目のテーブルの名前を変更し、3 番目のテーブルは以前と同じままにした後に表示されるメッセージを示しています。

この例で、スキーマと名前の変更があった両方のテーブルに既に保存されているデータは、変更を保存すると削除されます。 同じままにしたテーブルについては、古いデータを削除して最初から開始するか、または後で分析するために、新しく受信するデータと共に保存するかを選択できます。
ストリーミング データフローを編集する場合、特に後でさらに分析するために履歴データを利用できるようにする必要がある場合は、これらの微妙な違いにご注意ください。
ストリーミング データフローを使用する
ストリーミング データフローを実行すると、ストリーミング データに基づいてコンテンツの作成を開始する準備ができます。 リアルタイムで更新されるレポートを作成するために行う必要があることと比べて、構造的な変更はありません。 ストリーミング データ用にこの新しい種類のデータ準備を利用できるようにするため、考慮すべき微妙な違いと更新がいくつかあります。
データ ストレージの設定
前に述べたように、ストリーミング データフローでは、データが次の 2 つの場所に保存されます。 これらのソースの使用は、実行しようとしている分析の種類によって異なります。
- ホット ストレージ (リアルタイム分析): データがストリーミング データフローから Power BI に送られると、データはホット ロケーションに保存され、リアルタイムの視覚化を使ってアクセスできます。 このストレージに保存されるデータの量は、ストリーミング データフロー設定の [リテンション期間] に定義した値によって異なります。 既定値 (および最小値) は 24 時間です。
- コールド ストレージ (履歴分析) : [リテンション期間] で定義した期間に含まれない期間は、必要に応じて使用できるように、Power BI のコールド ストレージ (BLOB) に保存されます。
Note
これら 2 つのデータ ストレージの場所には重複があります。 両方の場所を組み合わせて使用する必要がある場合 (たとえば、前日比パーセントの変化)、レコードの重複を排除することが必要になる可能性があります。 これは、作成するタイム インテリジェンスの計算とアイテム保持ポリシーによって異なります。
Power BI Desktop からストリーミング データフローに接続する
Power BI Desktop では、[データフロー] と呼ばれるコネクタを使用できます。 ストリーミング データフローのこのコネクタの一部として、前述のデータ ストレージと一致する 2 つのテーブルが表示されます。
ストリーミング データフローのデータに接続するには:
[データの取得] に移動し、[Power Platform] を選択し、[データフロー] コネクタを選択します。
![[データの取得] ウィンドウのスクリーンショット。ナビゲーション ウィンドウで [Power Platform] が選択され、メインのペインで [データフロー] が強調表示されています。](media/dataflows-streaming/dataflows-streaming-40.png)
Power BI の資格情報を使用してサインインします。
ワークスペースを選択します。 ストリーミング データフローを含むものを探して、そのデータフローを選択します。 (この例では、ストリーミング データフローは Toll と呼ばれます。)
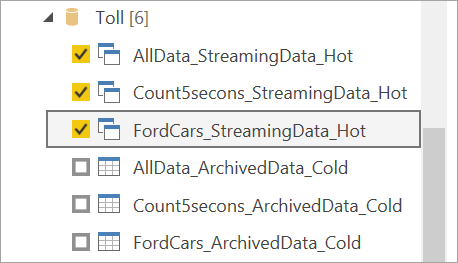
すべての出力テーブルが 2 回表示されることに注意してください。1 つはストリーミング データ用 (ホット) で、もう 1 つはアーカイブ データ用 (コールド) です。 それらは、テーブル名の後に追加されたラベルと、アイコンによって区別できます。
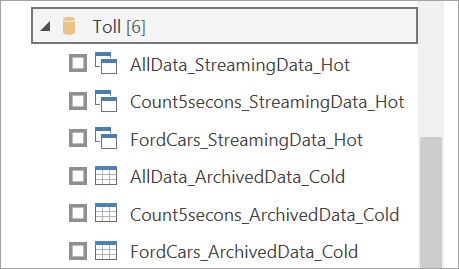
ストリーミング データに接続します。 アーカイブ データの場合も同じですが、インポート モードでのみ使用できます。 Streaming と Hot というラベルが含まれるテーブルを選択し、 [読み込み] を選択します。
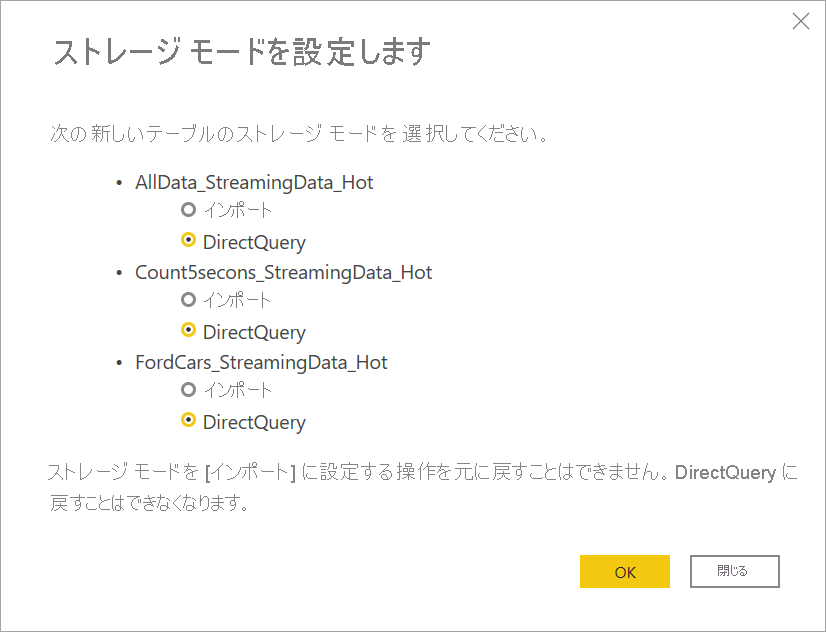
ストレージ モードを選択するように求められたら、リアルタイムのビジュアルを作成することが目標である場合は、 [DirectQuery] を選択します。
これで、Power BI Desktop で使用できる機能を使用して、ビジュアルやメジャーなどを作成できるようになります。
Note
通常の Power BI データフロー コネクタも引き続き使用でき、ストリーミング データフローで機能しますが、次の 2 つの注意事項があります。
- これは、ホット ストレージに接続するためにのみ使用できます。
- コネクタ内のデータ プレビューは、ストリーミング データフローでは機能しません。
リアルタイム ビジュアルに対してページの自動更新を有効にする
レポートの準備が整い、共有するすべてのコンテンツを追加したら、残った手順はビジュアルがリアルタイムで更新されることを確認することだけです。 "ページの自動更新" と呼ばれる機能を使用できます。 この機能により、DirectQuery ソースからのビジュアルを 1 秒ごとに更新できます。
機能の詳細については、記事「Power BI でのページの自動更新」を参照してください。 この記事には、その使用方法、設定方法、問題が発生した場合の管理者への連絡方法などに関する情報が含まれています。 設定方法の基本を次に示します。
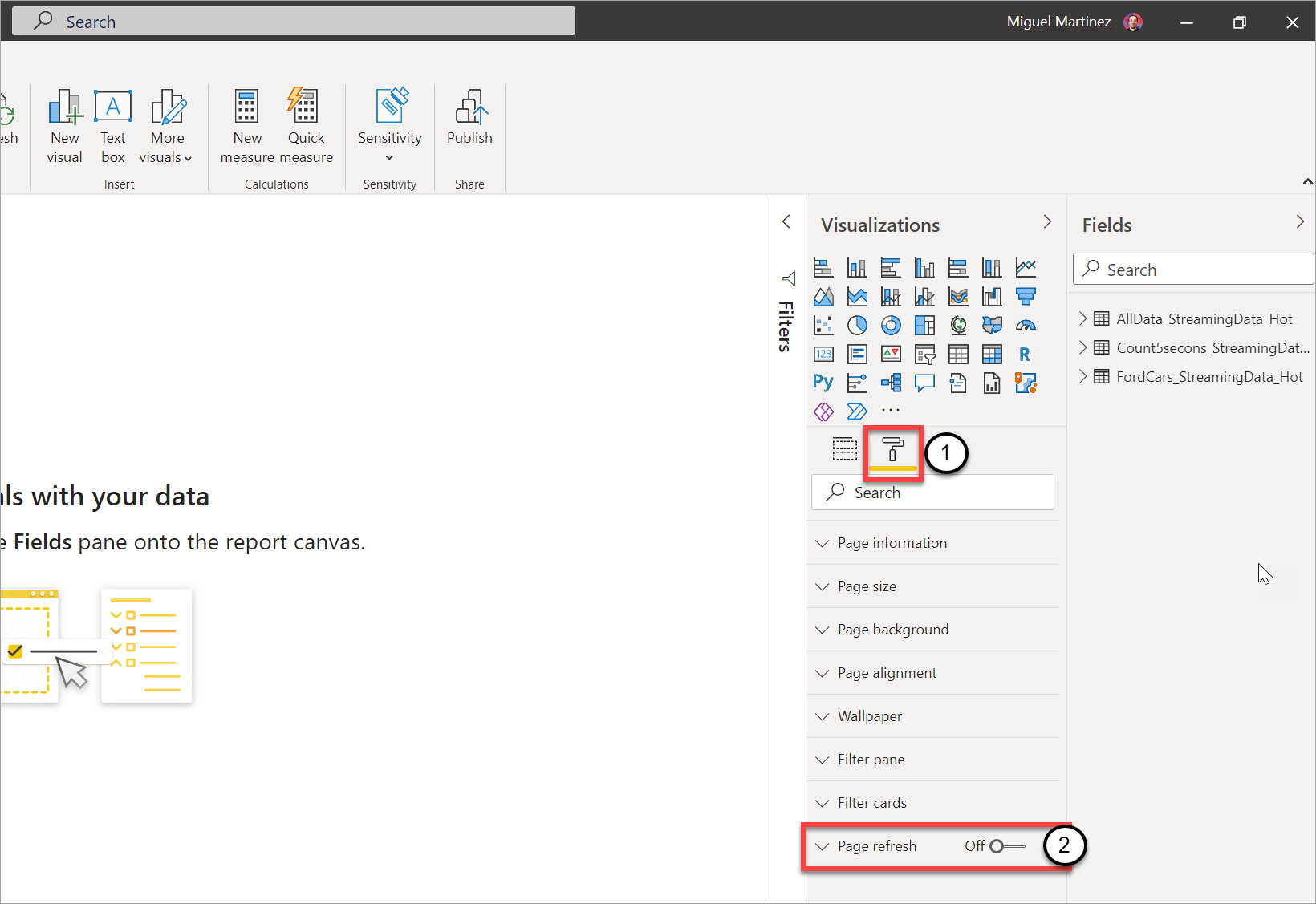
ビジュアルをリアルタイムで更新させるレポート ページに移動します。
ページ上のすべてのビジュアルをクリアします。 可能であれば、ページの背景を選択します。
書式設定ペイン (1) に移動し、[ページの更新] (2) をオンにします。
必要な頻度 (管理者が許可している場合は最大 1 秒ごと) を設定します。

リアルタイム レポートを共有するには、まず Power BI サービスに発行します。 次に、セマンティック モデルと共有のデータフロー資格情報を設定できます。
ヒント
レポートが必要な速さまたはリアルタイムで更新されていない場合は、ページの自動更新に関するドキュメントを確認してください。 FAQ とトラブルシューティングの手順に従って、この問題が発生している理由を解明します。
考慮事項と制限事項
一般的な制限事項
- ストリーミング データフローを作成して実行するには、Power BI Premium サブスクリプション (容量または PPU) が必要です。
- ワークスペースごとに使用できるデータフローの種類は 1 つのみです。
- 通常のデータフローとストリーミング データフローをリンクすることはできません。
- A3 より小さい容量では、ストリーミング データフローを使用できません。
- テナントでデータフローまたは拡張計算エンジンが有効になっていない場合、ストリーミング データフローを作成または実行できません。
- ストレージ アカウントに接続されたワークスペースはサポートされていません。
- 各ストリーミング データフローでは、最大で毎秒 1 MB のスループットを提供できます。
可用性
ストリーミング データフローのプレビューは、次のリージョンでは使用できません。
- Central India
- ドイツ北部
- ノルウェー東部
- ノルウェー西部
- アラブ首長国連邦中部
- 南アフリカ北部
- 南アフリカ西部
- スイス北部
- スイス西部
- ブラジル南東部
ライセンス
1 つのテナントあたりに許可されるストリーミング データフローの数は、使用するライセンスによって異なります。
通常の容量の場合、容量で許可されるストリーミング データフローの最大数は、次の式を使用して計算します。
容量あたりのストリーミング データフローの最大数 = 容量内の仮想コア数 x 5
たとえば、P1 に 8 つの仮想コアがある: 8 * 5 = 40 ストリーミング データフロー。
Premium Per User の場合、ユーザーあたり 1 つのストリーミング データフローが許可されます。 別のユーザーが PPU ワークスペースでストリーミング データフローを使用しようとする場合、PPU ライセンスも必要になります。
データフローの作成
ストリーミング データフローを作成する場合、次の考慮事項に注意する必要があります。
- ストリーミング データフローの所有者は変更のみを行うことができます。また、変更できるのは、データフローが実行されていない場合のみです。
- ストリーミング データフローは、マイ ワークスペースでは使用できません。
Power BI Desktop から接続する
コールド ストレージには、2021 年 7 月の Power BI Desktop 更新プログラムから利用可能な [データフロー] コネクタを使用してのみアクセスできます。 以前の Power BI データフロー コネクタでは、ストリーミング データ (ホット) ストレージへの接続のみが許可されます。 コネクタのデータ プレビューは機能しません。
関連するコンテンツ
この記事では、ストリーミング データフローを使用したセルフサービスのストリーミング データの準備の概要について説明しました。 次の記事では、この機能をテストする方法と Power BI の他のストリーミングデータ機能の使用方法について説明します。