Power BI Premium データフロー ワークロードを構成する
Power BI Premium サブスクリプションにデータフロー ワークロードを作成することができます。 Power BI では "ワークロード" の概念を使用して、Premium コンテンツを記述します。 ワークロードには、データセット、ページ分割されたレポート、データフロー、AI が含まれます。 "データフロー" ワークロードを使用すると、データフローのセルフサービスのデータ準備を使用して、データの取り込み、変換、統合、および強化を行うことができます。 Power BI Premium データフローは、 [管理ポータル] で管理されています。
以下のセクションでは、組織でデータフローを有効にする方法、Premium 容量の設定を調整する方法、および一般的な使用法のガイダンスについて説明します。
Power BI Premium でのデータフローの有効化
Power BI Premium サブスクリプションでデータフローを使用するための最初の要件は、組織のデータフローを作成して使用できるようにすることです。 次の画像に示すように、 [管理ポータル] で、 [テナント設定] を選択し、 [データフローの設定] の下にあるスライダーを [有効] に切り替えます。
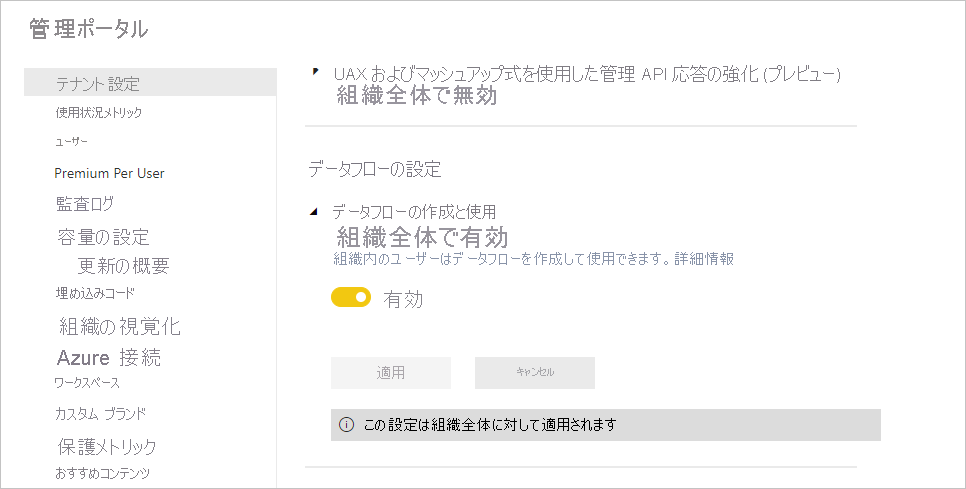
データフロー ワークロードを有効にすると、既定の設定で構成されます。 必要に応じて、これらの設定を調整することもできます。 次に、これらの設定がどこにあるかを説明し、それぞれについて説明し、データフローのパフォーマンスを最適化するために値を変更するタイミングを理解するのに役立ちます。
Premium でのデータフローの設定の調整
データフローが有効になったら、 [管理ポータル] を使用して、データフローの作成方法と Power BI Premium サブスクリプションでのリソースの使用方法を変更または調整できます。 Power BI Premium の場合、メモリの設定を変更する必要はありません。 Power BI Premium のメモリは、基になるシステムを自動的に管理します。 次の手順は、データフローの設定を調整する方法を示しています。
Admin ポータルでテナント設定を選択して、作成されたすべての容量を一覧表示します。 設定を管理する容量を選択します。
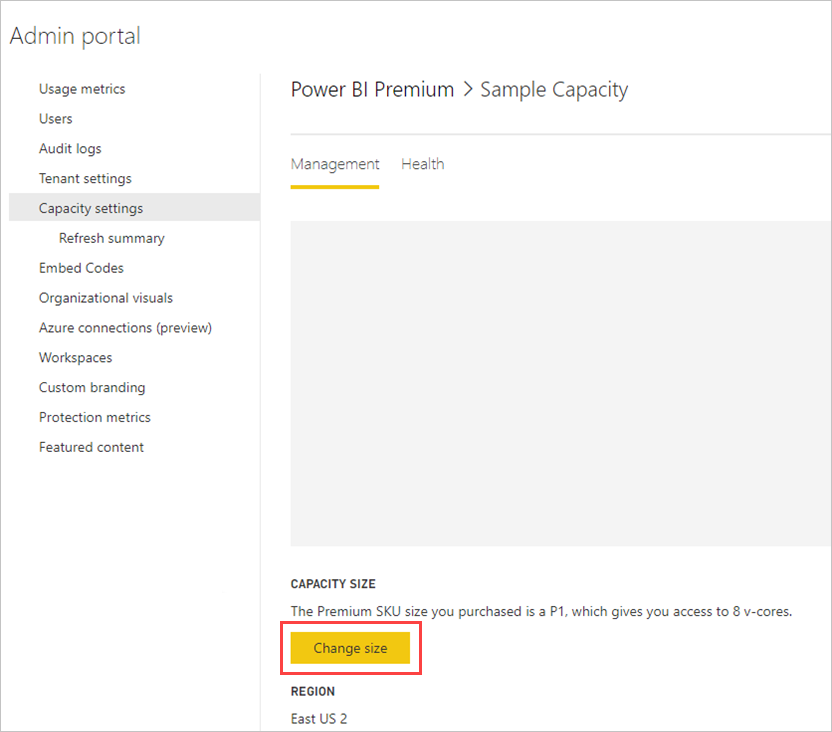
Power BI Premium 容量には、データフローで使用可能なリソースが反映されます。 次の画像に示すように、 [サイズの変更] ボタンを選択することで容量のサイズを変更できます。
Premium 容量 SKU - ハードウェアをスケールアップする
Power BI Premium ワークロードでは、仮想コアを使用して、さまざまなワークロードの種類にわたって高速なクエリを提供します。 「容量と SKU」には、使用可能な各ワークロード オファリングにおける現在の仕様を示すグラフが含まれています。 A3 以上の容量ではコンピューティング エンジンを利用できます。したがって、拡張コンピューティング エンジンを使用する必要がある場合は、そこから始めます。
拡張コンピューティング エンジン - パフォーマンスを向上させる機会
拡張コンピューティング エンジンは、クエリを高速にできるエンジンです。 Power BI ではコンピューティング エンジンを使用して、クエリおよび更新操作を処理します。 拡張コンピューティング エンジンは標準エンジンに比べて改善されており、SQL キャッシュにデータを読み込むことで機能し、SQL を使用してテーブル変換、更新操作を高速化し、DirectQuery 接続を有効にします。 計算対象エンティティについて、 [オン] または [最適化] に構成した状態で、ビジネス ロジックでそれが許可されている場合、パフォーマンスを向上させるために Power BI で SQL が使用されます。 エンジンを [オン] にすると、DirectQuery 接続も提供されます。 データフローの使用状況で、強化されたコンピューティング エンジンが適切に使用されていることを確認します。 ユーザーは拡張コンピューティング エンジンを、データフローごとにオン、最適化、またはオフに構成することができます。
注意
拡張コンピューティング エンジンは一部のリージョンではまだご利用いただけません。
一般的なシナリオに関するガイダンス
このセクションでは、Power BI Premium でデータフロー ワークロードを使用する場合の一般的なシナリオに関するガイダンスを提供します。
長い更新時間
長い更新時間は通常、並列処理の問題です。 次のオプションをこの順番で確認する必要があります。
長い更新時間の重要な概念は、データ準備の性質です。 データ ソースを利用し、実際に準備を行い、事前クエリ ロジックを実行することで、長い更新時間を最適化できる場合は常にそのようにする必要があります。 特に、ソースとして SQL などのリレーショナル データベースを使用する場合は、最初のクエリをソースで実行できるかどうかを確認し、そのソース クエリをデータ ソースの初期抽出データフローに使用します。 ソース システムでネイティブ クエリを使用できない場合は、データフロー engine がデータ ソースにフォールドできる操作を実行します。
同じ容量での更新時間の分散を評価します。 更新操作は、大量のコンピューティングを必要とするプロセスです。 レストランの例えを使用すると、更新時間の分散は、レストランの客数を制限することに似ています。 レストランがゲストをスケジュールして容量を計画するのと同様に、使用量がピークに満たない時間帯の更新操作も検討する必要があります。 これが容量の負担の緩和に役立つ場合があります。
このセクションの手順で必要な並列処理の次数が得られない場合は、容量を上位の SKU にアップグレードすることを検討してください。 その後、このシーケンスの前の手順をもう一度行います。
コンピューティング エンジンを使用したパフォーマンスの向上
次の手順を行い、ワークロードによって確実にコンピューティング エンジンがトリガーされ、常にパフォーマンスが向上するようにします。
同じワークスペース内の計算およびリンクされたエンティティの場合:
"取り込み" の場合は、データセット全体のサイズを小さくする場合にのみフィルターを使用して、可能な限り迅速にストレージにデータを取り込むことに集中します。 変換ロジックをこの手順から切り離し、エンジンが材料の初期収集に集中できるようにすることをお勧めします。 次に、リンクまたは計算されたエンティティを使用して、変換とビジネス ロジックを同じワークスペース内の別個のデータフローに分割します。これにより、エンジンがアクティブ化し、計算を高速化することができます。 コンピューティング エンジンを利用するには、ロジックを別個に準備する必要があります。
フォールドする操作 (結合、結合、変換、およびその他の操作など) を確実に実行してください。
公開されているガイドラインと制限事項内でのデータフローの構築。
DirectQuery を使用することもできます。
コンピューティング エンジンはオンになっているがパフォーマンスが低下している
コンピューティング エンジンがオンになっていても、パフォーマンスの低下が見られるシナリオについて調べる場合は、次の手順を行います。
ワークスペース全体に存在する計算およびリンクされたエンティティを制限します。
コンピューティング エンジンをオンにして最初の更新を実行すると、データはレイクとキャッシュに書き込まれます。 この二重書き込みでは、更新が遅くなります。
複数のデータフローにリンクされているデータフローがある場合は、すべての更新が同時に行われないように、必ずソース データフローの更新をスケジューリングしてください。
関連するコンテンツ
データフローと Power BI の詳細については、以下の記事を参照してください。