データフローを使用した AI
この記事では、データフローで人工知能 (AI) を使用する方法について説明します。 この記事では、次の内容について説明します。
- Cognitive Services
- 自動化された機械学習
- Azure Machine Learning 統合
重要
データフロー v1 用の Power BI 自動機械学習 (AutoML) モデルの作成は廃止され、使用できなくなりました。 お客様は Microsoft Fabric の AutoML 機能にソリューションを移行することをお勧めします。 詳細については、廃止のお知らせを参照してください。
Power BI の Cognitive Services
Power BI で Cognitive Services を使用すると、Azure Cognitive Services からさまざまなアルゴリズムを適用して、セルフサービスで自分のデータを準備し、データフロー用のデータを強化できます。
現在サポートされているサービスは、感情分析、キー フレーズ抽出、言語検出、およびイメージのタグ付けです。 変換は Power BI サービス上で実行され、Azure Cognitive Services サブスクリプションは必要ありません。 この機能には、Power BI Premium が必要です。
AI 機能の有効化
Cognitive Services は、Premium 容量ノード EM2、A2、P1、または F64、およびさらに多くのリソースを持つその他のノードでサポートされます。 Cognitive Services も Premium Per User (PPU) ライセンスで利用できます。 Cognitive Services を実行する際は、容量上の別個の AI ワークロードが使用されます。 Power BI で Cognitive Services を使用する前に、[管理ポータル] の [容量の設定] で AI ワークロードを有効にする必要があります。 [ワークロード] セクションで [AI ワークロード] を有効にすることができます。
![[容量の設定] を示す [管理ポータル] のスクリーンショット。](media/service-cognitive-services/cognitive-services-01.png)
Power BI で Cognitive Services の使用を開始する
Cognitive Services の変換は、データフロー用のセルフ サービスのデータ準備の一部です。 Cognitive Services を使用してデータを強化するには、最初にデータフローを編集します。
Power Query エディターの上部にあるリボンで [AI 分析情報] を選択します。
ポップアップ ウィンドウで、使用する関数と、変換するデータを選択します。 この例では、レビュー テキストを含む列のセンチメントにスコアを付けています。
![[CognitiveServices.ScoreSentiment] が選択されていることを示す [関数の呼び出し] ダイアログのスクリーンショット。](media/service-cognitive-services/cognitive-services-04.png)
LanguageISOCode は、テキストの言語を指定する入力 (省略可能) です。 この列には、ISO コードが想定されています。 LanguageISOCode の入力として、列、または静的列を使用できます。 この例では、列全体で言語が英語 (en) として指定されています。 この列を空白のままにすると、Power BI によって自動的に言語が検出された後、関数が適用されます。 次に、[呼び出す] を選択します。
![[CognitiveServices.ScoreSentiment] が選択され、[LanguageIsoCode] が [en] に設定されていることを示す [関数の呼び出し] ダイアログのスクリーンショット。](media/service-cognitive-services/cognitive-services-05.png)
関数を呼び出すと、結果が新しい列としてテーブルに追加されます。 変換もクエリ内の適用された手順として追加されます。
関数から複数の出力列が返される場合、その関数を呼び出すと複数の出力列の行を持つ新しい列が追加されます。
[展開] オプションを使用すると、一方または両方の値を列としてデータに追加できます。
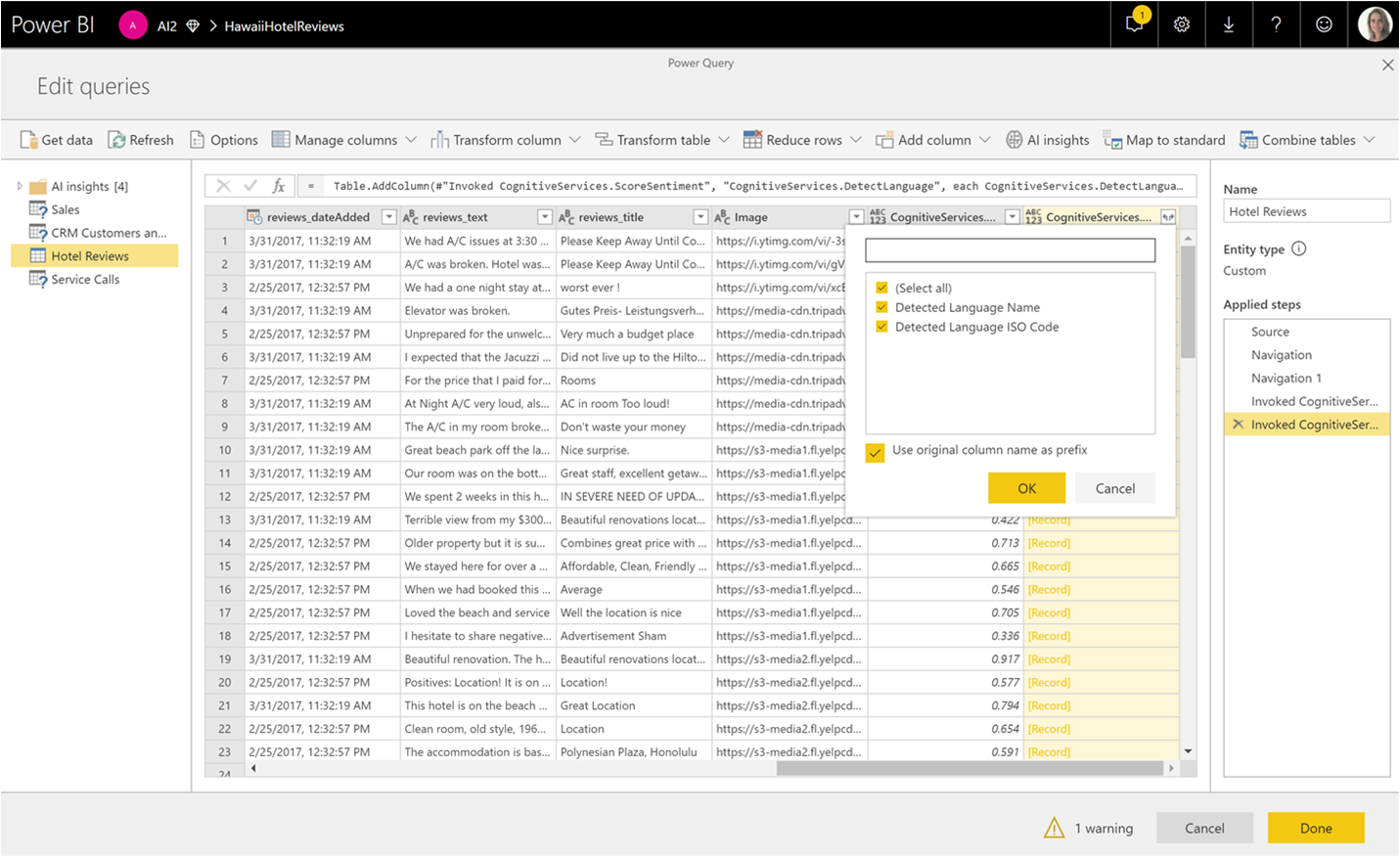
使用できる関数
このセクションでは、Power BI 内の Cognitive Services で使用可能な関数について説明します。
言語の検出
言語検出関数によって、テキスト入力が評価され、列ごとに言語名と ISO 識別子が返されます。 この関数は、データ列で任意のテキストが収集され、言語が不明な場合に役立ちます。 この関数では、入力データがテキスト形式であることが前提となっています。
Text Analytics では、最大 120 の言語が認識されます。 詳細については、「Azure Cognitive Service for Language での言語検出とは」を参照してください。
キー フレーズを抽出する
キー フレーズ抽出関数によって、非構造化テキストが評価され、テキスト列ごとにキー フレーズの一覧が返されます。 この関数は、入力としてテキスト列を必要とし、 LanguageISOCode の入力 (省略可能) も受け入れます。 詳細については、使用の開始に関するセクションを参照してください。
キー フレーズ抽出は、感情分析とは反対に、処理対象のテキストのチャンクが大きい方が効果的です。 感情分析は、テキスト ブロックが小さい方が効果的です。 両方の操作から最良の結果を得るには、入力を適宜再構築することを検討してください。
センチメントのスコア付け
センチメントのスコア付け関数では、テキスト入力が評価され、0 (否定的) から 1 (肯定的) までのセンチメント スコアがドキュメントごとに返されます。 この関数は、ソーシャル メディア、顧客のレビュー、およびディスカッション フォーラムで肯定的および否定的なセンチメントを検出するのに役立ちます。
Text Analytics では、機械学習分類アルゴリズムを使用して、0 ~ 1 のセンチメント スコアが生成されます。 スコアが 1 に近いほど肯定的なセンチメントを示し、 0 に近いほど否定的なセンチメントを示します。 モデルは、センチメントが関連付けられている幅広いテキスト本文を使用して、事前にトレーニングされています。 現時点では、独自のトレーニング データを指定することはできません。 テキストの分析時、モデルでは、テキスト処理、品詞分析、語の配置、語の関連付けなど、さまざまな手法が組み合わされて使用されます。 アルゴリズムの詳細については、「Machine Learning と Text Analytics」を参照してください。
感情分析は、テキスト内の特定のテーブルのセンチメントを抽出するのではなく、入力列全体に対して実行されます。 実際には、ドキュメントに大きなテキストのブロックではなく、1 つか 2 つの文が含まれているときにスコリング精度が向上する傾向があります。 客観性評価フェーズでは、入力列全体が客観的であるか、センチメントが含まれているのかがモデルによって判断されます。 入力列が概ね客観的な場合は、センチメント検出フェーズに進まず、スコアが 0.50 となり、処理が終了します。 入力列がパイプライン内を進行した場合は、次のフェーズで、入力列で検出されたセンチメントの程度に応じて 0.50 より上または下のスコアが生成されます。
現時点では、感情分析では、英語、ドイツ語、スペイン語、およびフランス語がサポートされています。 他の言語はプレビュー段階です。 詳細については、「Azure Cognitive Service for Language での言語検出とは」を参照してください。
タグ イメージ
タグ イメージ関数では、生物、風景、アクションなどの 2,000 を超える認識可能なオブジェクトに基づいてタグが返されます。 タグが不明瞭または一般に理解されないものである場合は、既知の状況のコンテキストでタグの意味を理解しやすくする "ヒント" が表示されます。 タグは分類として編成されず、継承の階層は存在しません。 一連のコンテンツ タグでは、完全な文章で書式設定された人間が判読できる言語として表示されるイメージの "説明" の基礎が形成されます。
イメージをアップロードするか、またはイメージの URL を指定すると、Computer Vision のアルゴリズムにより、そのイメージ内で識別されたオブジェクト、生物、およびアクションに基づいてタグが出力されます。 タグ付けの対象は、前景の人物などの被写体に限らず、背景 (屋内または屋外)、家具、道具、植物、動物、アクセサリ、ガジェットなども含まれます。
この関数では、イメージの URL または base-64 列が入力として必要です。 現時点でイメージのタグ付けでサポートされるのは、英語、スペイン語、日本語、ポルトガル語、および簡体中国語です。 詳細については、「ComputerVision インターフェイス」を参照してください。
Power BI での自動機械学習
ビジネス アナリストはデータフローに自動機械学習 (AutoML) を使用すると、Power BI で Machine Learning (ML) モデルのトレーニング、検証、呼び出しを直接行うことができます。 新しい ML モデルを作成するためのシンプルなエクスペリエンスが含まれており、アナリストはデータフローを使用して、モデルをトレーニングするための入力データを指定できます。 このサービスでは、最も関連性の高い特徴の抽出、適切なアルゴリズムの選択、ML モデルの調整と検証が自動的に行われます。 モデルのトレーニングが完了すると、Power BI によって、検証結果を含むパフォーマンス レポートが自動的に生成されます。 これで、データフロー内の新しいデータまたは更新されたデータに対してモデルを呼び出すことができるようになります。
![AutoML の [作業を開始する] 画面のスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-01.png)
自動機械学習は、Power BI Premium および Embedded 容量でホストされているデータフローにのみ使用できます。
AutoML を使用する
業界や科学研究分野では、機械学習と AI の人気がかつてないほど高まっています。 企業は、これらの新しいテクノロジを業務に統合する方法も模索しています。
データフローを使用すると、ビッグ データ用にセルフサービスでデータを準備できます。 AutoML はデータフローに統合されており、Power BI 内で直接、機械学習モデルを構築するためのデータ準備作業を使用できます。
データ アナリストは Power BI で AutoML を使用すると、シンプルなエクスペリエンスで Power BI のスキルのみを使用して、機械学習モデルを構築できます。 Power BI では、ML モデルの作成の背後にあるほとんどのデータ サイエンスが自動化されています。 これには、良好な品質のモデルを確実に作成できるガードレールがあり、ML モデルの作成に使用されたプロセスの可視性が提供されます。
AutoML では、データフローのためにバイナリの予測、分類、回帰モデルの作成がサポートされています。 これらの機能は教師あり機械学習技術の種類です。つまり、過去の観測による既知の結果から学習して、他の観測結果を予測します。 AutoML モデルをトレーニングするための入力セマンティック モデルは、既知の結果を使用してラベル付けされた行のセットです。
Power BI の AutoML では、Azure Machine Learning の自動 ML を統合して ML モデルが作成されます。 ただし、Power BI で AutoML を使用するために Azure サブスクリプションは必要ありません。 ML モデルのトレーニングとホスティングのプロセスは、Power BI サービスによって完全に管理されます。
ML モデルをトレーニングした後、AutoML によって、ML モデルの可能性のパフォーマンスを説明する Power BI レポートが自動的に生成されます。 AutoML では、モデルから返される予測に影響を与える入力の中で主要なインフルエンサーを強調することにより、説明可能性を強調します。 このレポートには、モデルの主要なメトリックも含まれています。
生成されたレポートのその他のページには、モデルの統計の概要とトレーニングの詳細が表示されます。 統計の概要は、モデル パフォーマンスの標準的なデータ サイエンス メジャーを表示したいと考えているユーザーにとって重要です。 トレーニングの詳細には、モデルを作成するために実行されたすべてのイテレーションと、関連するモデリングのパラメーターがまとめられています。 また、ML モデルを作成するために各入力がどのように使用されたかも示されます。
次に ML モデルをデータに適用してスコアリングを行うことができます。 データフローが更新されると、データは ML モデルからの予測によって更新されます。 Power BI には、ML モデルで生成される特定の予測ごとの個別の説明も含まれています。
機械学習モデルを作成する
このセクションでは、AutoML モデルを作成する方法について説明します。
ML モデルを作成するためのデータ準備
Power BI で機械学習モデルを作成するには、まず、履歴結果情報を含むデータのデータフローを作成する必要があります。これは ML モデルのトレーニングに使用されます。 また、ビジネス メトリックの計算列も追加する必要があります。これは、予測しようとしている結果の強力な予測因子となる可能性があります。 データフローの構成の詳細については、「データフローの構成と使用」を参照してください。
AutoML には、機械学習モデルをトレーニングするための特定のデータ要件があります。 これらの要件については、以下のセクションで、各モデルの種類に基づいて説明します。
ML モデル入力を構成する
AutoML モデルを作成するには、データフロー テーブルの [アクション] 列にある ML アイコンを選択し、 [機械学習モデルの追加] を選択します。
![データフロー エンティティで強調表示されている [機械学習モデルの追加] アクションのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-02.png)
ML モデルを作成するプロセスを案内するウィザードで構成されるシンプルなエクスペリエンスが開始されます。 このウィザードには、次のシンプルな手順が含まれています。
1. 履歴データを含むテーブルと、予測が必要な結果列を選択する
次の図に示すように、結果列によって ML モデルをトレーニングするためのラベル属性が特定されます。
![[予測するフィールドを選択します] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-03.png)
2.モデルの種類を選択する
結果列を指定すると、AutoML によってラベル データが分析され、トレーニング可能な最も可能性の高い ML モデルの種類が推奨されます。 次の図に示すように、[モデルの選択] をクリックして、別のモデルの種類を選択できます。
![[モデルの選択] ページを示すスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-04.png)
注意
一部のモデルの種類は、選択したデータに対してサポートされていない可能性があり、その場合は無効になります。 前の例では、テキスト列が結果列として選択されているため、[回帰] が無効になっています。
3.モデルで予測シグナルとして使用する入力を選択する
AutoML により、選択したテーブルのサンプルが分析され、ML モデルのトレーニングに使用できる入力が提案されます。 選択されていない列の横に説明が表示されます。 特定の列に個別の値が多すぎるか 1 つの値しかない場合、または出力列との相関関係が低い、または高い場合、推奨されません。
結果列 (またはラベル列) に依存する入力は、パフォーマンスに影響があるため、ML モデルのトレーニングには使用しないでください。 このような列には、"出力列との不自然に高い相関関係" があるとしてフラグが設定されます。 これらの列をトレーニング データに導入すると、ラベルの漏えいが発生します。この場合、モデルは検証データまたはテスト データに対して適切に動作しますが、運用環境でスコアリングに使用すると、そのパフォーマンスを実現することはできません。 トレーニング モデルのパフォーマンスがあまりにも優れている場合、AutoML モデルではラベルの漏えいが懸念される可能性があります。
この機能の推奨事項は、データのサンプルに基づいているため、使用した入力を確認する必要があります。 モデルに学習させる列だけを含めるように選択を変更することができます。 また、テーブル名の横にあるチェックボックスをオンにして、すべての列を選択することもできます。
![[学習するデータを選択します] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-05.png)
4.モデルに名前を付けて構成を保存する
最後の手順では、モデルに名前を付けて [保存] を選択し、ML モデルのトレーニングを開始するモデルを選択できます。 トレーニング時間を短縮して簡単な結果を表示するか、トレーニングにかける時間を増やして最適なモデルを得るかを選択できます。
![[名前を付けてトレーニングします] ページを示すスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-06.png)
ML モデルのトレーニング
AutoML モデルのトレーニングは、データフローの更新の一部です。 AutoML では、最初にトレーニング用のデータが準備されます。 AutoML によって、指定した履歴データがトレーニング セマンティック モデルとテスト セマンティック モデルに分割されます。 テスト セマンティック モデルは、トレーニング後にモデルのパフォーマンスを検証するために使用される予約セットです。 これらのセットは、データフローのトレーニングおよびテスト テーブルとして実現されます。 AutoML では、モデルの検証にクロス検証が使用されます。
次に、各入力列が分析され、欠損値がある場合は代替値に置き換えるインピュテーションが適用されます。 AutoML では、いくつかの異なるインピュテーション戦略が使用されます。 数値特徴として扱われる入力属性の場合、列の値の平均がインピュテーションに使用されます。 カテゴリ特徴として扱われる入力属性の場合、AutoML で列値のモードがインピュテーションに使用されます。 AutoML フレームワークでは、サブサンプリングされたトレーニング セマンティック モデルの補完に使用される値の平均値と最頻値が計算されます。
次に、必要に応じて、サンプリングと正規化がデータに適用されます。 分類モデルの場合、AutoML では層化サンプリングを使用して入力データを実行され、クラスのバランスを取ることで、行カウントが確実にすべて等しくなるようにします。
AutoML によって、選択された各入力列に対し、そのデータ型と統計プロパティに基づいていくつかの変換が適用されます。 AutoML では、これらの変換を使用して、ML モデルのトレーニングに使用する特徴が抽出されます。
AutoML モデルのトレーニング プロセスは、最適なパフォーマンスのモデルを見つけるために、さまざまなモデリング アルゴリズムとハイパーパラメーター設定を使用する最大 50 個のイテレーションで構成されます。 AutoML から、パフォーマンスの改善が見られないと通知された場合、反復回数を減らしてトレーニングを早めに終了できます。 AutoML では、提示されたテスト セマンティック モデルを使用して検証することにより、これらの各モデルのパフォーマンスが評価されます。 このトレーニング手順では、これらのイテレーションのトレーニングと検証のために、AutoML によって複数のパイプラインが作成されます。 モデルのパフォーマンスを評価するプロセスには、数分から数時間 (最長で、ウィザードで構成されているトレーニング時間) までかかる場合があります。 所要時間は、セマンティック モデルのサイズと使用可能な容量リソースによって異なります。
場合によっては、生成された最終モデルでアンサンブル学習が使用されることがあります。この場合、複数のモデルを使用して予測パフォーマンスを向上させることができます。
AutoML モデルの説明可能性
モデルのトレーニングが完了すると、AutoML によって入力機能とモデル出力の間のリレーションシップが分析されます。 これにより、各入力の特徴について、予約データのテスト セマンティック モデルのモデル出力に対する変更の大きさが評価されます。 このリレーションシップは、"特徴の重要度" と呼ばれます。 この分析は、トレーニングが完了した後に更新の一部として行われます。 そのため、更新には、ウィザードで構成されているトレーニング時間よりも長い時間がかかることがあります。
![モデル レポートの [モデル パフォーマンス] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-07.png)
AutoML モデル レポート
AutoML では、グローバルな特徴の重要度と共に、検証中のモデルのパフォーマンスをまとめた Power BI レポートが生成されます。 このレポートには、データフローの更新が正常に完了した後、[Machine Learning モデル] タブからアクセスできます。 このレポートには、予約データのテスト データに ML モデルを適用し、その予測を既知の結果値と比較した結果がまとめられます。
モデルのレポートを確認すると、そのパフォーマンスを把握できます。 また、モデルの主要なインフルエンサーが、既知の結果に関するビジネスの分析情報に沿っているかどうかを検証することもできます。
レポート内でモデルのパフォーマンスを説明するために使用されるグラフとメジャーは、モデルの種類によって異なります。 これらのパフォーマンス グラフとメジャーについては、以下のセクションで説明します。
レポート内の他のページでは、データ サイエンスの観点からモデルに関する統計的なメジャーについて説明されている場合があります。 たとえば、バイナリの予測レポートには、モデルのゲイン グラフと ROC 曲線が含まれています。
このレポートには、モデルのトレーニング方法についての説明が記載された [トレーニングの詳細] ページと、各イテレーションの実行に対するモデルのパフォーマンスを説明するグラフも含まれています。
![モデル レポートの [トレーニングの詳細] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-08.png)
このページのもう 1 つのセクションには、入力列の検出された種類と、欠損値を埋めるために使用されるインピュテーション方法が示されます。 また、最終的なモデルで使用されたパラメーターも含まれます。
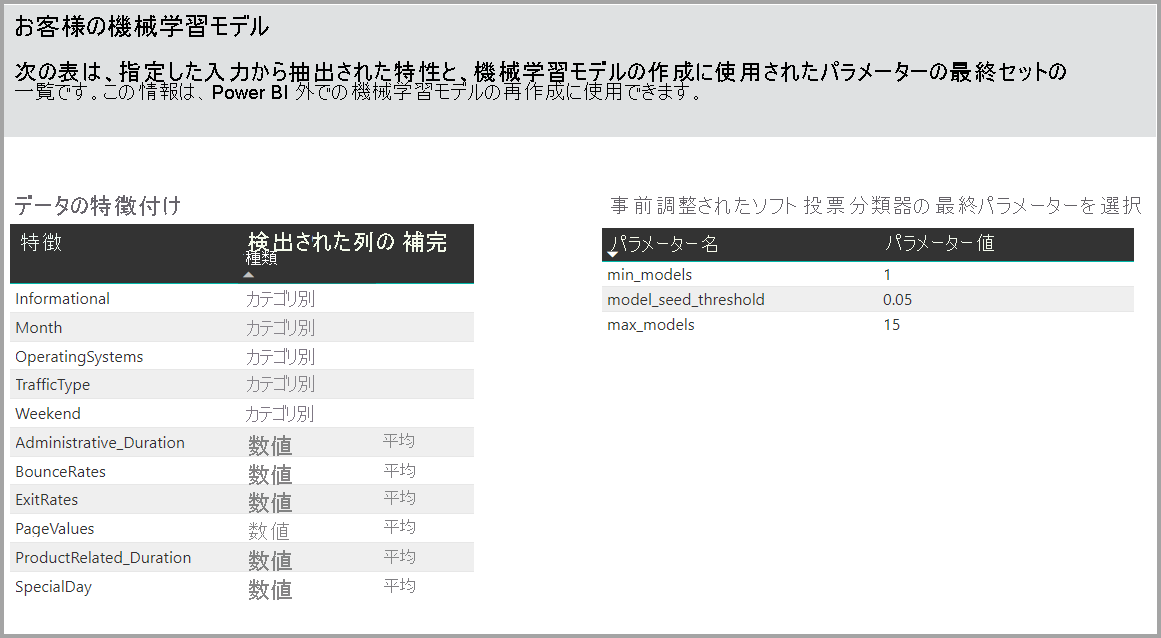
生成されるモデルにアンサンブル学習が使用される場合、[トレーニングの詳細] ページには、アンサンブルにおける各構成モデルの重みを示すグラフとそのパラメーターも含まれます。

AutoML モデルを適用する
作成された ML モデルのパフォーマンスに問題がなければ、データフローが更新されるときに、新しいデータまたは更新されたデータに適用することができます。 モデル レポートで右上隅の [適用] ボタンを選択するか、[Machine Learning モデル] タブの [アクション] の下にある [ML モデルの適用] ボタンを選択します。
ML モデルを適用するには、適用先のテーブルの名前と、モデル出力用にこのテーブルに追加される列のプレフィックスを指定する必要があります。 列名の既定のプレフィックスはモデル名です。 Apply 関数には、モデルの種類に固有の追加のパラメーターを含めることができます。
ML モデルを適用すると、2 つの新しいデータフロー テーブルが作成されます。これには、出力テーブルでスコアが付けられる各行の予測と個別の説明が含まれています。 たとえば、OnlineShoppers テーブルに PurchaseIntent モデルを適用すると、出力で OnlineShoppers enriched PurchaseIntent テーブルと OnlineShoppers enriched PurchaseIntent explanations テーブルが生成されます。 エンリッチされたテーブルの各行に対して、Explanations が入力の特徴に基づいて、エンリッチされた説明テーブル内の複数の行に分割されます。 ExplanationIndex は、エンリッチされた説明テーブルの行を、エンリッチされたテーブルの行にマップするのに役立ちます。
PQO 関数ブラウザーの [AI 分析情報] を使用し、同じワークスペース内にある任意のデータフロー内のテーブルに任意の Power BI AutoML モデルを適用することもできます。 この方法では、モデルを所有するデータフローの所有者でなくても、同じワークスペース内で他者によって作成されたモデルを使用できます。 Power Query によって、ワークスペース内のすべての Power BI ML モデルが検出され、動的な Power Query 関数として公開されます。 これらの関数を呼び出すには、Power Query エディター内のリボンからこれらの関数にアクセスするか、M 関数を直接呼び出します。 現在、この機能は、Power BI データフローと Power BI サービスの Power Query Online でのみサポートされています。 このプロセスは、AutoML ウィザードを使用してデータフロー内で ML モデルを適用する場合とは異なります。 この方法を使用すると、説明テーブルは作成されません。 データフローの所有者でない限り、モデル トレーニング レポートにアクセスしたり、モデルを再トレーニングしたりすることはできません。 また、入力列の追加または削除によってソース モデルが編集された場合、またはモデルあるいはソース データフローが削除された場合、この依存データフローは中断します。
![[Power BI Machine Learning モデル] が強調表示されている [AI 分析情報] ダイアログ ボックスのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-20.png)
モデルを適用すると、AutoML では、データフローが更新されるとすぐに予測が常に最新の状態に保たれます。
Power BI レポートで ML モデルからの分析情報と予測を使用するには、データフロー コネクタを使用して Power BI Desktop から出力テーブルに接続します。
バイナリの予測モデル
バイナリの予測モデル (より正式な呼び方では二項分類) は、セマンティック モデルを 2 つのグループに分類するために使用されます。 これらは、二元の結果を持つ可能性のあるイベントを予測するために使用されます。 たとえば、営業案件が転換されるかどうか、アカウントが解約されるかどうか、請求書が期日どおりに支払われるかどうか、トランザクションが不正かどうかなどです。
バイナリの予測モデルの出力は確率スコアで、ターゲットの結果が達成される可能性が特定されます。
バイナリ予測モデルのトレーニング
前提条件:
- 結果のクラスごとに最低 20 行の履歴データが必要
バイナリ予測モデルの作成プロセスは、前述のセクション「ML モデル入力を構成する」で説明した、他の AutoML モデルと同じ手順に従います。 唯一の違いは、[モデルの選択] ステップで最も関心のあるターゲットの結果値を選択できることです。 モデル検証の結果を要約した自動生成レポートで使用される結果に、わかりやすいラベルを付けることもできます。
![バイナリ予測の [モデルの選択] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-12.png)
バイナリの予測モデル レポート
バイナリの予測モデルにより、行がターゲットの結果を達成する確率が出力として生成されます。 このレポートには、確率のしきい値のスライサーが含まれます。これは、確率のしきい値より大きいスコアと小さいスコアの解釈方法に影響します。
このレポートでは、モデルのパフォーマンスが [True Positives](真陽性)、[False Positives](偽陽性)、[True Negatives](真陰性)、[False Negatives](偽陰性) で示されます。 [True Positives](真陽性の数) と [True Negatives](真陰性の数) は、結果データの 2 つのクラスに対して正しく予測された結果です。 偽陽性は、ターゲットの結果があると予測されたが、実際にはなかった行です。 逆に、偽陰性は、ターゲットの結果があるのに、ないと予測された行です。
精度やリコールなどのメジャーは、予測される結果に対する確率のしきい値の影響を示します。 確率しきい値のスライサーを使用すると、精度とリコールのバランスが取れた妥協点を達成するしきい値を選択できます。

このレポートには、最高の利益を得るためにターゲットとする母集団のサブセットを特定するのに役立つ、費用対効果分析ツールも含まれています。 目標設定のための推定単位費用と、目標の結果を達成すると得られる単位便益を考慮して、費用対効果分析では利益の最大化が試行されます。 このツールを使用すると、グラフ内の最大ポイントに基づいて確率のしきい値を選択して、利益を最大化することができます。 また、グラフを使用して、確率のしきい値の選択に伴う利益またはコストを計算することもできます。
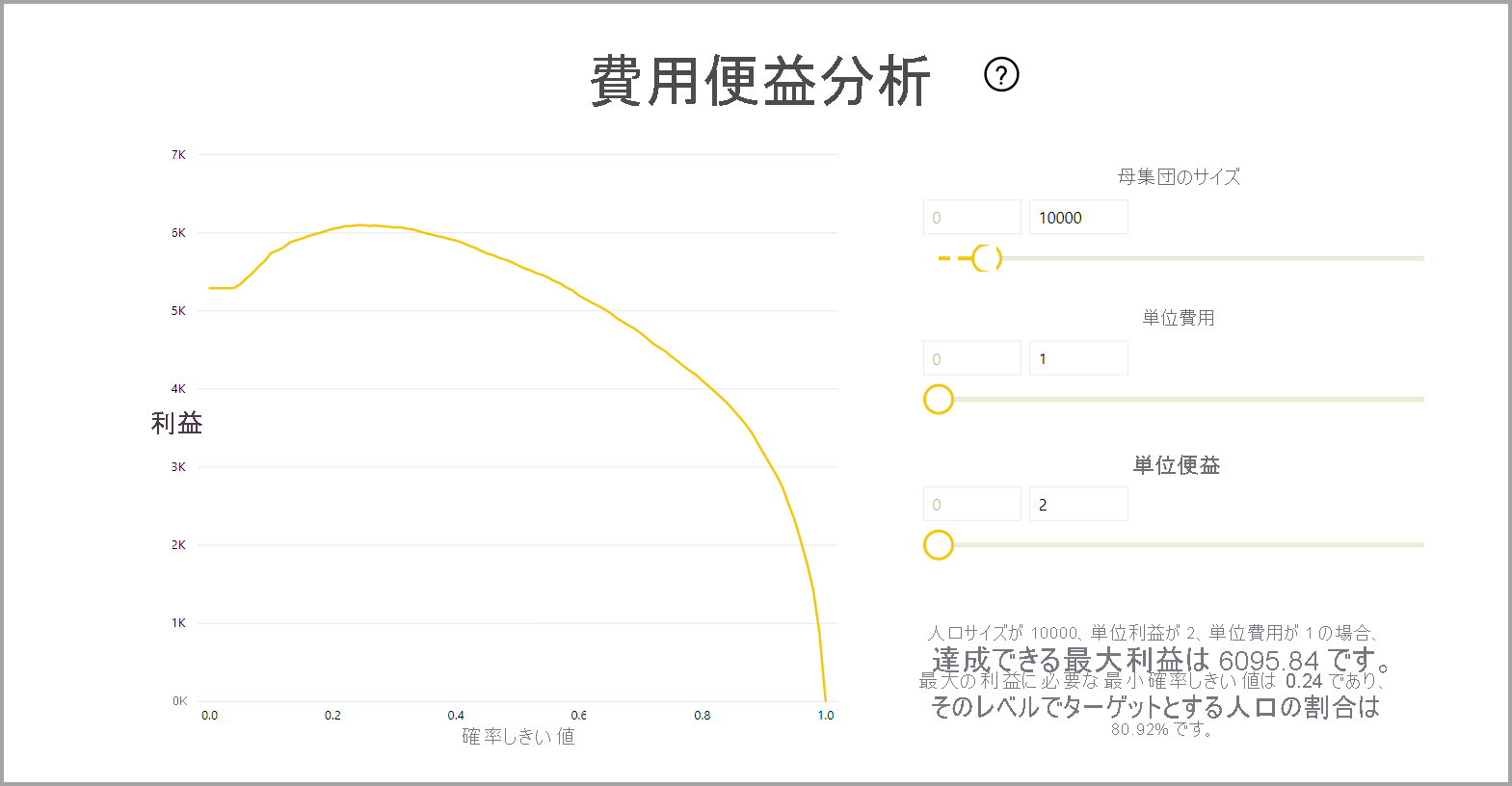
モデル レポートの [Accuracy Report](精度レポート) ページには、モデルの [Cumulative Gains](累積ゲイン) グラフと ROC 曲線が含まれます。 このデータは、モデル パフォーマンスの統計測定値を提供します。 レポートには、表示されているグラフの説明が含まれます。
![モデル レポートの [精度レポート] ページのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-15.png)
バイナリ予測モデルを適用する
バイナリの予測モデルを適用するには、ML モデルから予測を適用する先のデータを含むテーブルを指定する必要があります。 その他のパラメーターには、出力列名のプレフィックス、予測される結果を分類するための確率しきい値があります。
![[購入意図予測の適用] ダイアログ ボックスのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-16.png)
バイナリの予測モデルを適用すると、エンリッチされた出力テーブルに Outcome、PredictionScore、PredictionExplanation、ExplanationIndex の 4 つの出力列が追加されます。 テーブル内の列名に、モデルの適用時に指定されたプレフィックスが設定されます。
PredictionScore は確率を示すパーセントで、ターゲットの結果が達成される可能性を割り出します。
Outcome 列には、予測結果ラベルが含まれています。 確率がしきい値を超えているレコードは、ターゲットの結果を達成できる可能性が高いと予測され、True としてラベル付けされます。 しきい値より小さいレコードは、結果を達成する可能性が低いと予測され、False としてラベル付けされます。
PredictionExplanation 列には、PredictionScore に対して入力の特徴が与えた具体的な影響を示す説明が含まれています。
分類モデル
分類モデルは、セマンティック モデルを複数のグループまたはクラスに分類するために使用されます。 これらは、複数の考えられる結果のいずれになるかイベントを予測するために使用されます。 たとえば、顧客の生涯価値が高、中、低のいずれであるかなどです。 また、債務不履行のリスクが高、中、低のいずれであるかを予測することもできます。
分類モデルの出力は確率スコアであり、これによって、特定のクラスの条件を行が達成する可能性が特定されます。
分類モデルのトレーニング
分類モデルのトレーニング データを含む入力テーブルには、過去の既知の結果を特定する文字列または整数の列が結果列として含まれている必要があります。
前提条件:
- 結果のクラスごとに最低 20 行の履歴データが必要
分類モデルの作成プロセスは、前述のセクション「ML モデル入力を構成する」で説明した、他の AutoML モデルと同じ手順に従います。
分類モデル レポート
Power BI では、提示されたテスト データセットに ML モデルを適用して、分類モデル レポートが作成されます。 その後、行の予測クラスと実際の既知のクラスが比較されます。
モデル レポートには、既知の各クラスについて正しく分類された行と不正に分類された行の内訳を含むグラフが表示されます。
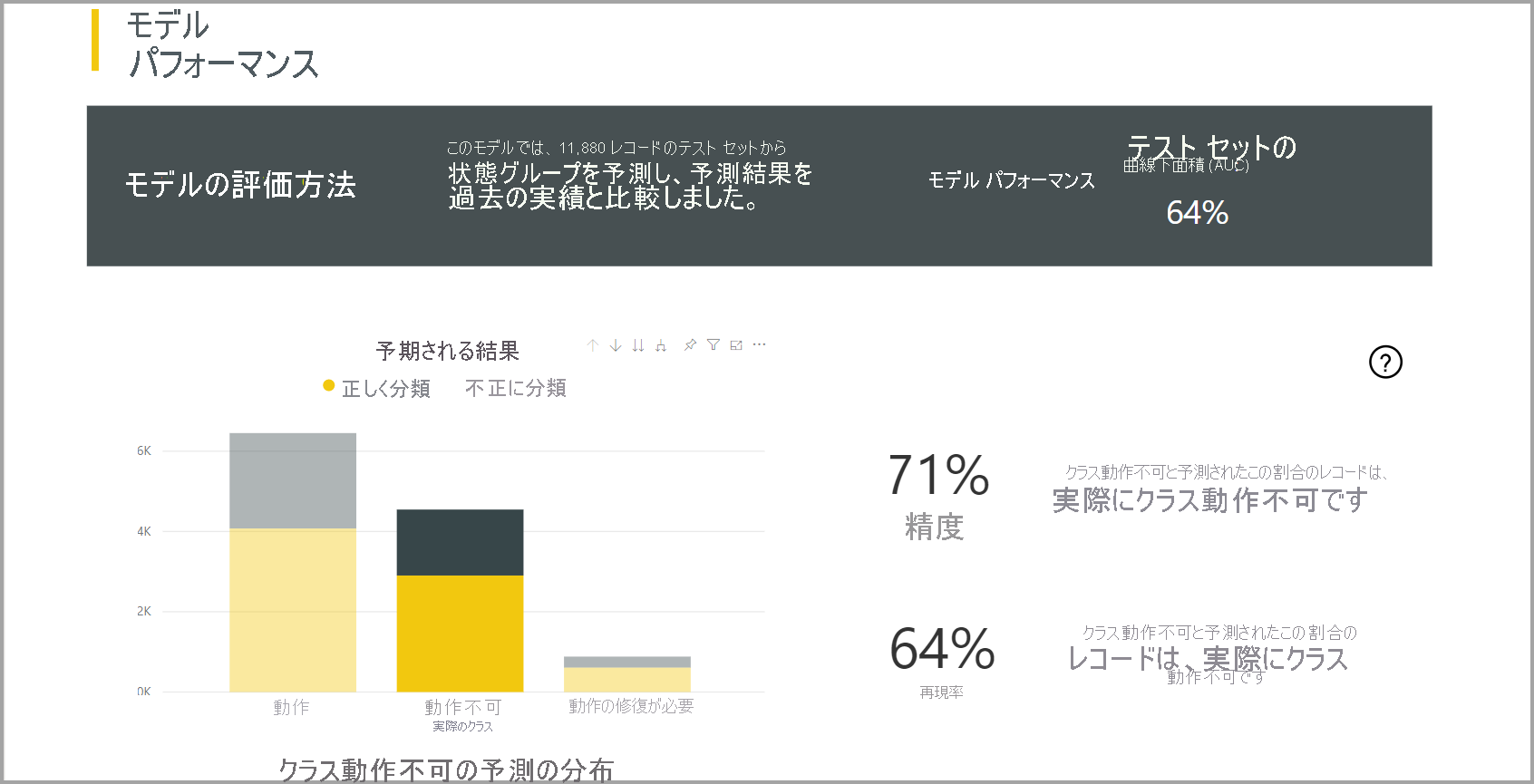
さらにクラス固有のドリルダウン アクションを使用すると、既知のクラスの予測がどのように分散されているかを分析できます。 この分析には、その既知のクラスの行が誤って分類される可能性のある他のクラスが示されます。
レポート内のモデルの説明には、各クラスの上位の予測子も含まれています。
分類モデル レポートには、セクション「AutoML モデル レポート」で前述したように、他の種類のモデルのページと同様の [トレーニングの詳細] ページも表示されます。
分類モデルを適用する
分類 ML モデルを適用するには、入力データを含むテーブルと出力列名のプレフィックスを指定する必要があります。
分類モデルを適用すると、強化された出力テーブルに、ClassificationScore、ClassificationResult、ClassificationExplanation、ClassProbabilities、ExplanationIndex の 5 つの出力列が追加されます。 テーブル内の列名に、モデルの適用時に指定されたプレフィックスが設定されます。
ClassProbabilities 列には、使用可能な各クラスの行の確率スコアの一覧が含まれています。
ClassificationScore は確率を示すパーセントであり、これによって、特定のクラスの条件を行が達成する可能性が特定されます。
ClassificationResult 列には、行に対して予測される可能性が最も高いクラスが含まれています。
ClassificationExplanation 列には、ClassificationScore に対して入力の特徴が与えた具体的な影響を示す説明が含まれています。
回帰モデル
回帰モデルは数値を予測するために使用され、次のような判断を行うシナリオで使用できます。
- 販売取引から実現される可能性が高い収益。
- アカウントの生涯価値。
- 支払われる可能性が高い売掛金請求書の金額
- 請求書の支払日など。
回帰モデルの出力は予測値です。
回帰モデルのトレーニング
回帰モデルのトレーニング データを含む入力テーブルには、既知の結果値を特定する数値列が結果列として含まれている必要があります。
前提条件:
- 回帰モデルには、少なくとも 100 行の履歴データが必要です。
回帰モデルの作成プロセスは、前述のセクション「ML モデル入力を構成する」で説明した、他の AutoML モデルと同じ手順に従います。
回帰モデル レポート
他の AutoML モデル レポートと同様に、回帰レポートは、予約データのテスト データにモデルを適用した結果に基づいています。
モデル レポートには、予測値と実際の値を比較するグラフが含まれています。 このグラフでは、斜線からの距離は、予測の誤差を示しています。
残余誤差グラフは、予約データのテスト セマンティック モデル内のさまざまな値に関する平均誤差の割合の分布を示します。 横軸は、グループの実際の値の平均を表します。 バブルのサイズは、その範囲内の値の頻度またはカウントを示します。 縦軸は、平均残余誤差です。
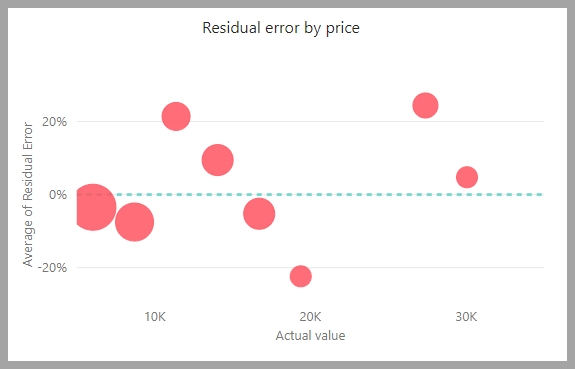
回帰モデル レポートには、前述のセクション「AutoML モデル レポート」で説明したように、他の種類のモデルのレポートと同様の [トレーニングの詳細] ページも表示されます。
回帰を適用する
回帰 ML モデルを適用するには、入力データと出力列名のプレフィックスを持つテーブルを指定する必要があります。
![[価格予測の適用] ダイアログのスクリーンショット。](media/service-machine-learning-automated/automated-machine-learning-power-bi-19.png)
回帰モデルを適用すると、エンリッチされた出力テーブルに RegressionResult、RegressionExplanation、ExplanationIndex の 3 つの出力列が追加されます。 テーブル内の列名に、モデルの適用時に指定されたプレフィックスが設定されます。
RegressionResult 列には、入力列に基づいた行の予測値が含まれています。 RegressionExplanation 列には、RegressionResult に対して入力の特徴が与えた具体的な影響を示す説明が含まれています。
Azure Machine Learning の Power BI への統合
多くの組織が、ビジネスについてより正確な分析情報や予測を得るために機械学習モデルを使用しています。 レポート、ダッシュボード、その他の分析で機械学習を使用すると、これらの分析情報を取得できます。 これらのモデルからの分析情報を視覚化したり、呼び出したりすることができれば、これらの分析情報を最も必要としているビジネス ユーザーにその情報を広めることができます。 Power BI では、ポイントアンドクリック ジェスチャを使用するだけで、Azure Machine Learning 上でホストされているモデルから分析情報を簡単に取り込めるようになりました。
この機能を使用するために、データ サイエンティストは Azure portal を使用して、Azure Machine Learning モデルへのアクセス権を BI アナリストに付与できます。 次に、セッションが開始されるたびに、Power Query では、ユーザーがアクセス可能なすべての Azure Machine Learning モデルを検出し、動的な Power Query 関数として公開します。 ユーザーがこれらの関数を呼び出すには、Power Query エディター内のリボンからこれらの関数にアクセスするか、M 関数を直接呼び出します。 また、一連の行のパフォーマンスを向上させるために、Power BI では、Azure Machine Learning モデルを呼び出すときに、アクセス要求を自動的にバッチ処理します。
現在、この機能は、Power BI データフローと Power BI サービスの Power Query Online でのみサポートされています。
データフローの詳細については、「データフローとセルフサービスのデータの準備の概要」を参照してください。
Azure Machine Learning の詳細については、以下を参照してください。
- 概要:Azure Machine Learning とは
- Azure Machine Learning のクイック スタートおよびチュートリアル:「Azure Machine Learning のドキュメント」
Power BI ユーザーに Azure Machine Learning モデルへのアクセス権を付与する
Power BI から Azure Machine Learning モデルにアクセスするには、Azure サブスクリプションおよび Machine Learning ワークスペースへの読み取りアクセス権が必要です。
この記事では、Azure Machine Learning service でホストされているモデルへのアクセス権を Power BI ユーザーに付与して、Power Query 関数としてのこのモデルにアクセスできるようにする手順について説明します。 詳細については、Azure portal を使用して Azure ロールを割り当てる方法に関するページを参照してください。
Azure portal にサインインします。
[Subscriptions](サブスクリプション) ページに移動します。 Azure portal のナビ ペインのメニューにある [すべてのサービス] リストに [サブスクリプション] ページがあります。

サブスクリプションを選択します。

[アクセス制御 (IAM)] を選択し、[追加] ボタンを選択します。
![Azure サブスクリプションの [アクセス制御 (IAM)] タブのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-03.png)
ロールとして [閲覧者] を選択します。 次に、Azure Machine Learning モデルへのアクセス権を付与する Power BI ユーザーを選択します。
![[アクセス許可の追加] ペインで [閲覧者] に変更されているロールのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-04.png)
[保存] を選択します。
上記の 3 から 6 までの手順を繰り返して、モデルをホストしている特定の機械学習ワークスペースのユーザーに [閲覧者] のアクセス権を付与します。


![Azure サブスクリプションの [アクセス制御 (IAM)] タブのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-03.png#lightbox)
![[アクセス許可の追加] ペインで [閲覧者] に変更されているロールのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-04.png#lightbox)
機械学習モデルのスキーマの検出
データ サイエンティストは、機械学習用の機械学習モデルを開発する際、さらにはデプロイする際にも、主に Python を使用しています。 データ サイエンティストは、Python を使用して、スキーマ ファイルを明示的に生成する必要があります。
機械学習モデルでは、デプロイされた Web サービスにこのスキーマ ファイルを含める必要があります。 Web サービスのスキーマを自動的に生成するには、デプロイされたモデルのエントリ スクリプトで入力/出力のサンプルを指定する必要があります。 詳細については、「オンライン エンドポイントを使用して機械学習モデルをデプロイおよびスコア付けする」を参照してください。 このリンクには、スキーマ生成のステートメントを含む、エントリ スクリプトの例が含まれます。
具体的には、エントリ スクリプトの @input_schema と @output_schema の各関数は、input_sample と output_sample の各変数の入力および出力サンプル形式を参照しています。 これらの関数は、デプロイ時にこれらのサンプルを使って Web サービスの OpenAPI (Swagger) 仕様を生成します。
エントリ スクリプトの更新によるこれらのスキーマ生成手順は、Azure Machine Learning SDK を使って自動機械学習エクスペリエンスにより作成されたモデルにも適用する必要があります。
注意
Azure Machine Learning ビジュアル インターフェイスを使って作成されたモデルでは、現在のところスキーマ生成はサポートされていませんが、今後のリリースではサポートされる予定です。
Power BI で Azure Machine Learning モデルを呼び出す
アクセス権が付与された任意の Azure Machine Learning モデルは、Power Query エディターから直接呼び出すことができます。 Azure Machine Learning モデルにアクセスするには、次の図に示すように、Azure Machine Learning モデルからの分析情報で強化するテーブルの [テーブルの編集] ボタンを選択します。
![データフロー エンティティの強調表示された [テーブルの編集] アイコンのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-05.png#lightbox)
[テーブルの編集] ボタンを選択すると、データフロー内でテーブルの Power Query エディターが開きます。
![[AI 分析情報] ボタンが強調表示されている Power Query のスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-06.png#lightbox)
リボン内で [AI 分析情報] ボタンを選択した後、ナビ ペインのメニューから "Azure Machine Learning Models" フォルダーを選択します。 アクセス権があるすべての Azure Machine Learning モデルが Power Query 関数としてここに一覧表示されます。 また、Azure Machine Learning モデルの入力パラメーターは、対応する Power Query 関数のパラメーターとして自動的にマップされます。
Azure Machine Learning モデルを呼び出すには、選択したテーブルのいずれかの列を、ドロップダウンからの入力として指定します。 入力ダイアログの左側にある列アイコンを切り替えることにより、入力として使用する定数値を指定することもできます。
![[関数の呼び出し] ダイアログ ボックスの列選択オプションのスクリーンショット。](media/service-machine-learning-integration/machine-learning-integration-07.png#lightbox)
[呼び出す] を選択すると、Azure Machine Learning モデルの出力のプレビューが、テーブルの新しい列として表示されます。 モデルの呼び出しが、クエリに適用されたステップとして表示されます。

モデルから複数の出力パラメーターが返された場合、それらのパラメーターは、出力列内で行としてグループ化されます。 列を展開すると、個々の出力パラメーターを別々の列内に生成できます。

データフローを保存すると、データフローの更新時に、テーブル内の新しい行または更新された行に対してモデルが自動的に呼び出されます。
考慮事項と制限事項
- データフロー Gen2 は現在、自動化された機械学習と統合されていません。
- AI 分析情報 (Cognitive Services および Azure Machine Learning モデル) は、プロキシ認証が設定されているコンピューター上ではサポートされていません。
- Azure Machine Learning モデルは、ゲスト ユーザーにはサポートされていません。
- AutoML および Cognitive Services でのゲートウェイの使用には、いくつかの既知の問題があります。 ゲートウェイを使用する必要がある場合は、まずゲートウェイ経由で必要なデータをインポートするデータフローを作成することをお勧めします。 その後、最初のデータフローを参照する別のデータフローを作成して、これらのモデルと AI 関数を作成または適用します。
- AI のデータフローの操作が失敗した場合は、データフローでの AI の使用時に高速結合を有効にする必要がある場合があります。 テーブルのインポートが完了したら、AI 機能の追加を開始する "前" に、[ホーム] リボンから [オプション] を選択し、表示されるウィンドウで [複数のソースからデータを結合できるようにします] の横にあるチェックボックスをオンにして機能を有効にしてから、[OK] を選択して選択内容を保存します。 その後、データフローに AI 機能を追加できるようになります。
関連するコンテンツ
この記事では、Power BI サービスのデータフローの自動機械学習の概要について説明しました。 次の記事も役立つ可能性があります。
データフローと Power BI の詳細については、以下の記事を参照してください。