独自の Azure Data Lake Storage Gen2 を導入する
Power Automate Process Mining には、Azure Data Lake Storage Gen2 から直接イベント ログ データを保存および読み取るオプションがあります。 この機能では、ストレージ アカウントに直接接続することで、抽出、変換、読み込み (ETL) の管理を簡素化します。
この機能は現在、以下の取り込みをサポートしています:
-
CSV
- ひとつの CSV ファイル。
- 同じ構造を持つ複数の CSV ファイルを含むフォルダー。 すべてのファイルが取り込まれます。
-
Parquet
- ひとつの parquet ファイル。
- 同じ構造を持つ複数の Parquet ファイルを含むフォルダー。 すべてのファイルが取り込まれます。
-
Delta-parquet
- delta-parquet 構造を含むフォルダ。
前提条件
Data Lake Storage アカウントは、Gen2 である必要があります。 Azure ポータルで確認できます。 Azure Data Lake Gen1 ストレージ アカウントはサポートしていません。
Data Lake Storage アカウントは、階層型名前空間にを有効しておく必要があります。
オーナー ロールを同じ環境内の次のユーザーに対して環境の初期コンテナーの設定を実行するユーザーに割り当てる必要があります。 これらのユーザーは同じコンテナーに接続しており、次の割り当てが必要です。
- ストレージ ブロブ データ リーダー または ストレージ ブロブ コントリビューター ロールが割り当てられている
- 少なくとも、Azure Resource Manager 閲覧者 のロールが割り当てられている。
リソース共有 (CORS) ストレージ アカウントに対する共有ルールは、Power Automate Process Mining で共有するように確立する必要があります。
許可されるオリジンは
https://make.powerautomate.comとhttps://make.powerapps.comに設定する必要があります。許可されたメソッドには、
get、options、put、postが含まれている必要があります。許可されたヘッダーは可能な限り柔軟である必要があります。
*として定義することをお勧めします。公開されたヘッダーは可能な限り柔軟である必要があります。
*として定義することをお勧めします。最大有効期間は可能な限り柔軟に設定する必要があります。
86400の使用を推奨します。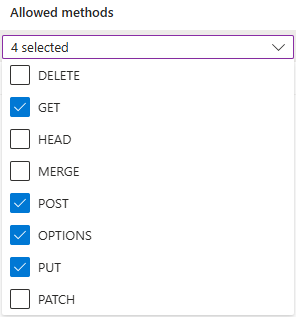
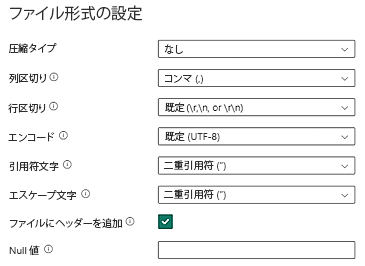
データレイク ストレージの CSV データは、以下の CSV ファイル形式要件を満たす必要があります:
- 圧縮の種類: なし
- 列区切り記号: カンマ (,)
- 行区切り文字: 既定およびエンコード。 例: 既定 (\r、\n、または \r\n)
すべてのデータは最終イベント ログ形式であり、データ要件にリストされている要件を満たしている必要があります。 データをプロセス マイニング スキーマにマッピングする準備ができている必要があります。 インジェスト後に使用できるデータ変換はありません。
ヘッダー行のサイズ (幅) は現在 1 MB に制限されています。
重要
CSV ファイルで表されるタイム スタンプが ISO 8601 標準形式 (YYYY-MM-DD HH:MM:SS.sss や YYYY-MM-DDTHH:MM:SS.sss など) に従っていることを確認してください。
Azure Data Lake Storage への接続
左側のナビゲーション ウィンドウで、プロセス マイニング>ここから開始を選択します。
プロセス名フィールドにプロセスの名前を入力します。
データ ソース 見出しで、データのインポート>Azure Data Lake>続行を選択します。
![[プロセスの作成] ステップのスクリーンショット。](media/process-mining-byo-azure-data-lake/createprocess.svg)
接続設定 画面で、ドロップダウン メニューから自分の サブスクリプション ID、リソース グループ、 ストレージ アカウント、そして コンテナー を選択します。
イベントログデータが含まれるファイルまたはフォルダーを選択します。
単一のファイルを選択することも、複数のファイルが含まれるフォルダーを選択することもできます。 すべてのファイルは同じヘッダーと形式でなければなりません。
次へを選択します。
データのマッピング画面で、データを必要なスキーマにマッピングします。
![[データのマッピング] 画面のスクリーンショット。](media/process-mining-byo-azure-data-lake/map.png)
保存して分析を選択して接続を完了します。
増分データ更新の設定を定義する
完全更新または増分更新を使用して、スケジュールに従って Azure Data Lake から取得したプロセスを更新できます。 保持ポリシーはありませんが、次のいずれかの方法を使用してデータを段階的に取り込むことができます。
前のセクションで 単一ファイル を選択した場合、選択したファイルに他のデータを追加します。
前の画面で フォルダー を選択した場合、選択したフォルダーに増分ファイルを追加します。
重要
選択したフォルダーまたはサブフォルダーに増分ファイルを追加する場合、YYYMMDD.csv や YYYYMMDDHHMMSS.csv のようにファイル名を日付にして増分順序を示してください。
プロセスを最新の情報に更新するには、次の手順を実行します。
プロセスの詳細ページに移動します。
更新設定を選択します。
スケジュールの更新画面で、次の手順を完了します。
- データを最新に維持するトグル スイッチをオンにします。
- データの更新間隔 ドロップダウン リストで、更新の頻度を選択します。
- 開始時刻フィールドで、更新の日時を選択します。
- 増分更新 トグル スイッチをオンにします。