プロセスとデータを準備する
Power Automate のプロセス マイニング機能を効果的に使用するには、次のことを理解する必要があります。
プロセス マイニング機能を使用してデータをアップロードする方法に関するショート ビデオをご覧ください。
データ要件
イベント ログとアクティビティ ログは、イベントやアクティビティが発生した際に文書化する記録システムに格納するテーブルです。 たとえば、顧客関係管理 (CRM) アプリで実行するアクティビティは、CRM アプリケーションのイベント ログとして保存されます。 プロセス マイニングでイベント ログを分析する場合は、次のフィールドが必要です。
サポート案件 ID
ケース ID はプロセスのインスタンスを表す必要があり、多くの場合、プロセスが作用するオブジェクトです。 入院患者のチェックインプロセスの場合は "患者 ID"、注文送信プロセスの場合は "注文 ID"、承認プロセスの場合は "要求 ID" になります。 この ID は、ログ内のすべてのアクティビティに存在する必要があります。
活動名
活動はプロセスのステップであり、活動名は各ステップを説明します。 一般的な承認プロセスでは、アクティビティ名は「リクエストの送信」、「リクエストの承認」、「リクエストの拒否」、「リクエストの修正」などになります。
開始の Timestamp と終了の Timestamp
タイムスタンプは、イベントまたはアクティビティが発生した正確な時刻を示します。 イベント ログのタイムスタンプは 1 つだけです。 これは、システムでイベントや活動が発生した時刻を示します。 活動ログには、開始タイムスタンプと終了タイムスタンプの 2 つのタイムスタンプがあります。 これらは、各イベントや活動の開始と終了を示します。
オプションの属性タイプを取り込むことで分析を拡張することもできます:
Resource
特定のイベントを実行する人的または技術的リソースです。
イベント レベル属性
アクティビティを実行する部門など、イベントごとに異なる値を持つ追加の分析属性。
ケース レベル属性 (最初のイベント)
ケース レベル属性は追加の属性であり、分析の観点からはケースごとにひとつの値 (たとえば、USDでの請求額) を持つと見なされます。 ただし、取り込まれるイベント ログは、イベント ログ内のすべてのイベントの特定の属性に同じ値を持たせるなど、一貫性を保つ必要はありません。 たとえば、増分データ更新が使用されている場合、これを保証できない可能性があります。 Power Automate Process Mining はデータをそのまま取り込み、イベント ログに提供されたすべての値を保存しますが、ケース レベルの属性を操作するため、いわゆる ケース レベル属性解釈 メカニズムを使用します。
つまり、イベント レベルの値を必要とする特定の機能 (イベント レベルのフィルタリングなど) に属性が使用されるときは常に、製品はイベント レベルの値を使用します。 ケース レベルの値が必要な場合 (ケース レベル フィルター、根本原因分析など) は常に、ケース内の時系列で最初のイベントから取得された解釈された値が使用されます。
ケース レベル属性 (最後のイベント)
ケース レベル属性 (最初のイベント) と同じですが、ケース レベルで解釈される場合、値はケース内の時系列で最後のイベントから取得されます。
イベントごとの財務
宅配便サービスのコストなど、実行されるアクティビティごとに変化する固定コスト/収益/数値です。 財務価値は、各イベントごとの財務価値の合計 (平均、最小、最大) として計算されます。
ケースごとの財務 (最初のイベント)
ケースごとの財務属性は追加の数値属性で、分析の観点からは 1 件につきひとつの値を持つとみなされます (たとえば、請求書の金額 (USD))。 ただし、取り込まれるイベント ログは、イベント ログ内のすべてのイベントの特定の属性に同じ値を持たせるなど、一貫性を保つ必要はありません。 たとえば、増分データ更新が使用されている場合、これを保証できない可能性があります。 Power Automate Process Mining はデータをそのまま取り込み、提供されたすべての値をイベント ログに保存します。 ただし、ケース レベルの属性を操作するために、ケース レベル属性解釈 メカニズムが使用されます。
つまり、イベント レベルの値を必要とする特定の機能 (イベント レベルのフィルタリングなど) に属性が使用されるときは常に、製品はイベント レベルの値を使用します。 ケース レベルの値が必要な場合 (ケース レベル フィルター、根本原因分析など) は常に、ケース内の時系列で最初のイベントから取得された解釈された値が使用されます。
ケースごとの財務 (最後のイベント)
ケースごとの財務 (最初のイベント) と同じですが、ケース レベルで解釈される場合、値はケース内の時系列で最後のイベントから取得されます。
アプリケーションからログ データを取得する場所
プロセス マイニング機能がプロセス マイニングを実行する際には、イベント ログ データが必要です。 アプリケーションのデータベースに存在する多くのテーブルは、データの現在の状態を含みますが、発生したイベントの履歴レコードは含んでいない可能性があります。これにはイベント ログ形式が必要です。 幸い、多くの大規模なアプリケーションでは、この履歴レコードまたはログは特定のテーブルに保存されることがよくあります。 たとえば、多くの Dynamics アプリケーションは、このレコードを活動テーブルに保持します。 SAP や Salesforce などの他のアプリケーションに同様の概念がありますが、名前が違っている可能性があります。
履歴レコードを記録するこれらのテーブルでは、データ構造が複雑になる可能性があります。 特定の ID または名前を取得するには、ログ テーブルをアプリケーション データベース内の他のテーブルと結合する必要があるかもしれません。 また、関心のあるすべてのイベントがログに記録されるわけではありません。 どのイベントを保持、または除外するかを決定する必要がある場合があります。ヘルプが必要な場合は、このアプリケーションを管理する IT チームに連絡して詳細を理解する必要があります。
データ ソースへの接続
データ ソースからの最新データでプロセス レポートを最新の状態に保つことができることが、データベースに直接接続するメリットです。
Power Query は多種多様なコネクタをサポートし、プロセス マイニング機能が対応するデータソースに接続し、データをインポートする方法を提供します。 一般的なコネクタには、テキスト/CSV、Microsoft Dataverse、および SQL Server データベースが含まれています。 SAP や Salesforce などのアプリケーションを使用している場合は、これらのデータソースに、対応するコネクタを使用して直接接続できる可能性があります。 サポートされているコネクタとその使用方法については、Power Query のコネクタ を参照してください。
テキスト/CSV コネクタを使用してプロセス マイニング機能を試す
データ ソースがどこにあるかに関係なく、プロセス マイニング機能を試す簡単な方法の 1 つに、テキスト/CSV コネクタの使用があります。 データベース管理者と協力して、イベント ログの小さなサンプルを CSV ファイルとしてエクスポートする必要がある場合があります。 CSV ファイルを取得したら、データ ソース選択画面で次の手順を使用してプロセス マイニング機能にインポートできます。
Note
テキスト/CSV コネクタを使用するには、ビジネス用の OneDrive が必要です。 OneDrive for Business を所有しない場合は、次の手順 3 と同様、テキスト/CSV ではなく、空白のテーブル を使用することを検討してください。 空白のテーブルの場合、インポートできるレコードは少なくなります。
プロセス マイニングのホームページで、ここから開始 を選択してプロセスを作成します。
プロセス名を入力し、作成 を選択します。
データ ソースを選択 画面で、すべてのカテゴリ>テキスト/CSV を選択します。
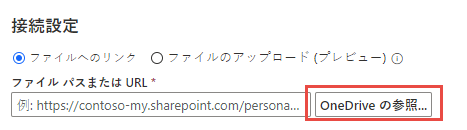
OneDrive の参照を選択します。 認証が必要な場合があります。
右上のアップロードアイコン、次にファイルを選択して、イベント ログをアップロードします。
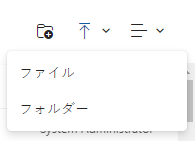
イベント ログをアップロードし、リストからファイルを選択してから、開くを選択してそのファイルを使用します。
データフローコネクタを使用する
Dataflowコネクタはサポートされていません Microsoft Power Platform。 既存のデータフローは、 Power Automate プロセス マイニング の データ ソース として使用できません。
Dataverse コネクタの使用
Dataverse コネクタは、Microsoft Power Platform でサポートされていません。 OData コネクタを使用して接続する必要があります。これには、さらにいくつかの手順が必要になります。
Dataverse 環境へのアクセス許可があることを確認します。
接続先の Dataverse 環境の環境 URL が必要です。 通常は次のようになります。

URL を見つける方法については、Dataverse 環境 URL を見つけるを参照してください。
Power Query - データ ソースの選択画面で、OData を選択します。
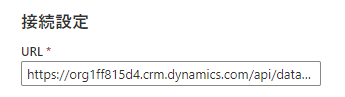
URLの最後の URL テキストボックスに、api/data/v9.2 と入力し、次のようになるようにします。
接続の資格情報の下にある認証の種類フィールドで、組織アカウントを選択します。
サインイン選択して、資格情報を入力します。
次へを選択します。
OData フォルダーを展開します。 その環境の Dataverse テーブルがすべて表示されています。 例として、アクティビティ テーブルは、activitypointers と呼ばれます。
インポートするテーブルの横にあるチェックボックスを選択してから、次へを選択します。