Enterprise Websites クラウド Microsoft Graph コネクタ
Enterprise Websites クラウド Microsoft Graph コネクタを使用すると、organizationは、会社所有の Web サイトまたはインターネット上のパブリック Web サイトの Web ページとコンテンツにインデックスを作成できます。 Web サイトからコネクタとインデックス コンテンツを構成した後、エンド ユーザーは Microsoft Search でそのコンテンツを検索し、Microsoft 365 Copilotできます。
この記事は、Microsoft 365 管理者、または Enterprise Websites クラウド Microsoft Graph コネクタを構成、実行、監視するユーザーを対象とします。
重要
オンプレミスまたはプライベート クラウドでホストされている Web サイトのインデックスを作成するには、Enterprise Websites オンプレミスの Microsoft Graph コネクタ を使用できます。
機能
- クラウドアクセス可能な Web サイトから Web ページにインデックスを作成します。
- 1 つの接続で最大 50 個の Web サイトにインデックスを作成します。
- 除外ルールを使用してクロールから Web ページを除外します。
- Copilot でセマンティック検索を使用して、ユーザーが関連するコンテンツを検索できるようにします。
サポートされているファイルの種類
| File Extension | ファイルの種類 | 説明 |
|---|---|---|
| Portable Document Format | ||
| .odt | OpenDocument テキスト | OpenDocument テキスト ドキュメント |
| .ods | OpenDocument スプレッドシート | OpenDocument スプレッドシート |
| .odp | OpenDocument プレゼンテーション | OpenDocument プレゼンテーション |
| .odg | OpenDocument グラフィックス | OpenDocument グラフィックス |
| .xls | Excel (古い) | Excel スプレッドシート (古い形式) |
| .xlsx | Excel (新規) | Excel スプレッドシート (新しい形式) |
| .ppt | PowerPoint (古い) | PowerPointプレゼンテーション (旧形式) |
| .pptx | PowerPoint (新規) | PowerPointプレゼンテーション (新しい形式) |
| .doc | Word (古い) | Word ドキュメント (旧形式) |
| .docx | Word (新規) | ドキュメントのWord (新しい形式) |
| .csv | CSV | Comma-Separated 値 |
| .txt | プレーン テキスト | プレーン テキスト ファイル |
| .xml | XML | 拡張可能なマークアップ言語 |
| .md | Markdown | Markdown ファイル |
| .rtf | リッチ テキスト形式 | リッチ テキスト形式 |
| .tsv | タブ区切り値 | Tab-Separated 値 |
サポートされている MIME の種類
| MIME タイプ | 説明 |
|---|---|
| text/html | Web ページの構造の書式設定に使用される HyperText マークアップ言語 (HTML)。 |
| text/webviewhtml | WebView コントロールでレンダリングされる Web コンテンツに使用される MIME の種類。 |
| text/x-server-parsed-html | サーバー側インクルード (SSI) でよく使用されるサーバー解析 HTML ドキュメント。 |
制限事項
- コネクタは、SAML、JWT トークン、Forms ベースの認証などの認証メカニズムをサポートしていません。
- コネクタは、Web ページ内の動的コンテンツのクロールをサポートしていません。
前提条件
- organizationの Microsoft 365 テナントの検索管理者である必要があります。
- Web サイト URL: Web サイトのコンテンツに接続するには、Web サイトへの URL が必要です。 1 つの接続で複数の Web サイトにインデックスを作成できます (最大 50)。
- サービス アカウント (省略可能): サービス アカウントは、Web サイトで認証が必要な場合にのみ必要です。 パブリック Web サイトは認証を必要とせず、直接クロールできます。 認証を必要とする Web サイトの場合は、コンテンツを認証してクロールするための専用アカウントを用意することをお勧めします。
はじめに

1. 表示名
表示名は、Copilot の各引用文献を識別するために使用され、ユーザーが関連付けられているファイルまたは項目を簡単に認識するのに役立ちます。 表示名は、信頼されたコンテンツも示します。 表示名は、 コンテンツ ソース フィルターとしても使用されます。 このフィールドには既定値が存在しますが、organizationのユーザーが認識する名前にカスタマイズできます。
2. インデックスを作成する Web サイトの URL
クロールする Web サイトのルートを指定します。 Enterprise Websites クラウド Microsoft Graph コネクタでは、この URL を開始点として使用し、この URL のすべてのリンクに従ってクロールを行います。 1 つの接続で最大 50 個の異なるサイト URL のインデックスを作成できます。 [URL] フィールドに、サイト URL をコンマ (,) で区切って入力します。 たとえば、「 https://www.contoso.com,https://www.contosoelectronics.com 」のように入力します。
注:
コネクタは常に URL のルートからクロールを開始します。 たとえば、指定した URL が の場合、 https://www.contoso.com/electronicsコネクタは から https://www.contoso.comクロールを開始します。
コネクタは、ルート URL のドメイン内の Web ページのみをクロールし、ドメイン外 URL のクロールをサポートしていません。 リダイレクトは、同じドメイン内でのみサポートされます。 クロールする Web ページにリダイレクトがある場合は、クロールする URL の一覧にリダイレクトされた URL を直接追加できます。
クロールにサイトマップを使用する
選択すると、コネクタはサイトマップに一覧表示されている URL のみをクロールします。 このオプションを使用すると、後の手順で増分クロールを構成することもできます。 選択されていない場合、またはサイトマップが見つからない場合、コネクタはサイトのルート URL で見つかったすべてのリンクのディープ クロールを実行します。
このオプションを選択すると、クローラーは次の手順を実行します。
a. クローラーは、ルートの場所で robots.txt ファイルを検索します。 たとえば、指定した URL が の場合、クローラーは https://www.contoso.comで robots.txt ファイル https://www.contoso.com/robots.txtを検索します。
b. robots.txt ファイルを見つけると、クローラーは robots.txt ファイル内のサイトマップリンクを見つけます。
c. その後、クローラーはサイトマップ ファイルに一覧表示されているすべての Web ページをクロールします。
d. 上記のいずれかの手順でエラーが発生した場合、クローラはエラーをスローすることなく、Web サイトのディープ クロールを実行します。
3. 認証の種類
選択した認証方法は、接続でインデックスを作成するために指定したすべての Web サイトに適用されます。 Web サイトからコンテンツを認証および同期するには、サポートされている 4 つの方法のいずれかを 選択します。
a.
なし
認証要件なしで Web サイトにパブリックにアクセスできる場合は、このオプションを選択します。
b. [ 基本認証]
基本認証を使用して認証するには、アカウントのユーザー名とパスワードを入力します。
c.
SiteMinder
Siteminder 認証には、適切な形式の URL、、 https://custom_siteminder_hostname/smapi/rest/createsmsessionユーザー名、およびパスワードが必要です。
d.
OAuth 2.0 クライアント資格情報のMicrosoft Entra
Microsoft Entra IDを使用する OAuth 2.0 には、リソース ID、クライアント ID、およびクライアント シークレットが必要です。
リソース ID、クライアント ID、およびクライアント シークレットの値は、Web サイトのMicrosoft Entra ID ベースの認証のセットアップ方法によって異なります。 指定した 2 つのオプションの 1 つが、Web サイトに適している場合があります。
Microsoft Entra アプリケーションを ID プロバイダーとクライアント アプリの両方として使用して Web サイトにアクセスする場合、クライアント ID とリソース ID はこの単一アプリケーションのアプリケーション ID であり、クライアント シークレットはこのアプリケーションで生成したシークレットです。
注:
クライアント アプリケーションを ID プロバイダーとして構成する詳細な手順については、「クイック スタート: Microsoft ID プラットフォームにアプリケーションを登録する」および「Microsoft Entraログインを使用するようにApp ServiceまたはAzure Functions アプリを構成する」を参照してください。
クライアント アプリが構成されたら、アプリの [証明書 & シークレット ] セクションに移動して、新しいクライアント シークレットを作成します。 ページに表示されているクライアント シークレットの値は、再び表示されないためコピーします。
次のスクリーンショットでは、クライアント ID とクライアント シークレットを取得し、独自にアプリを作成している場合にアプリを設定する手順を確認できます。
[ブランド化] セクションの設定を表示します。
![ブランド化ページの [設定] セクションを示す画像。](media/enterprise-web-connector/connectors-enterpriseweb-branding.png)
認証セクションの設定の表示:
![認証ページの [設定] セクションを示す画像。](media/enterprise-web-connector/connectors-enterpriseweb-authentication.png)
注:
Web サイトのリダイレクト URI に上記のルートを指定する必要はありません。 認証に Azure によって送信されたユーザー トークンを Web サイトで使用する場合にのみ、ルートを作成する必要があります。
[Essentials] セクションのクライアント ID の表示:
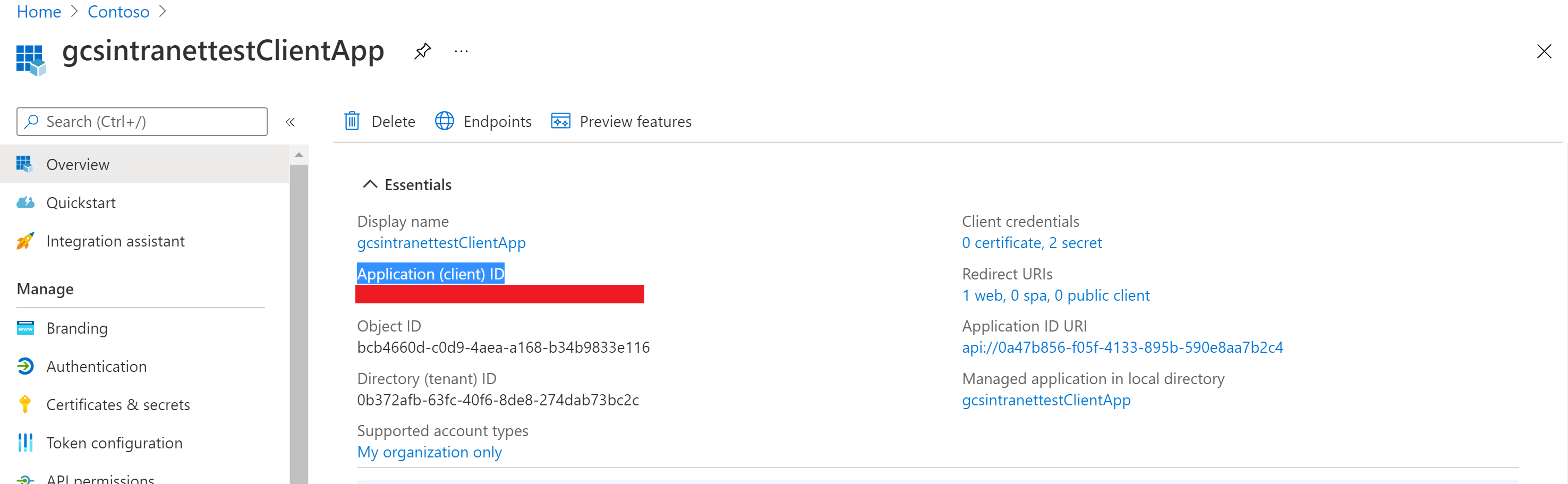
[証明書 & シークレット] セクションでクライアント シークレットを 表示します。

Web サイトの ID プロバイダーとしてアプリケーション (最初のアプリ) をリソースとして使用し、別のアプリケーション (2 番目のアプリ) を使用して Web サイトにアクセスする場合、クライアント ID は 2 番目のアプリのアプリケーション ID であり、クライアント シークレットは 2 番目のアプリで構成されたシークレットです。 ただし、リソース ID は最初のアプリの ID です。
注:
クライアント アプリケーションを ID プロバイダーとして構成する手順については、「クイック スタート: Microsoft ID プラットフォームにアプリケーションを登録する」および「Microsoft Entraログインを使用するようにApp ServiceまたはAzure Functions アプリを構成する」を参照してください。
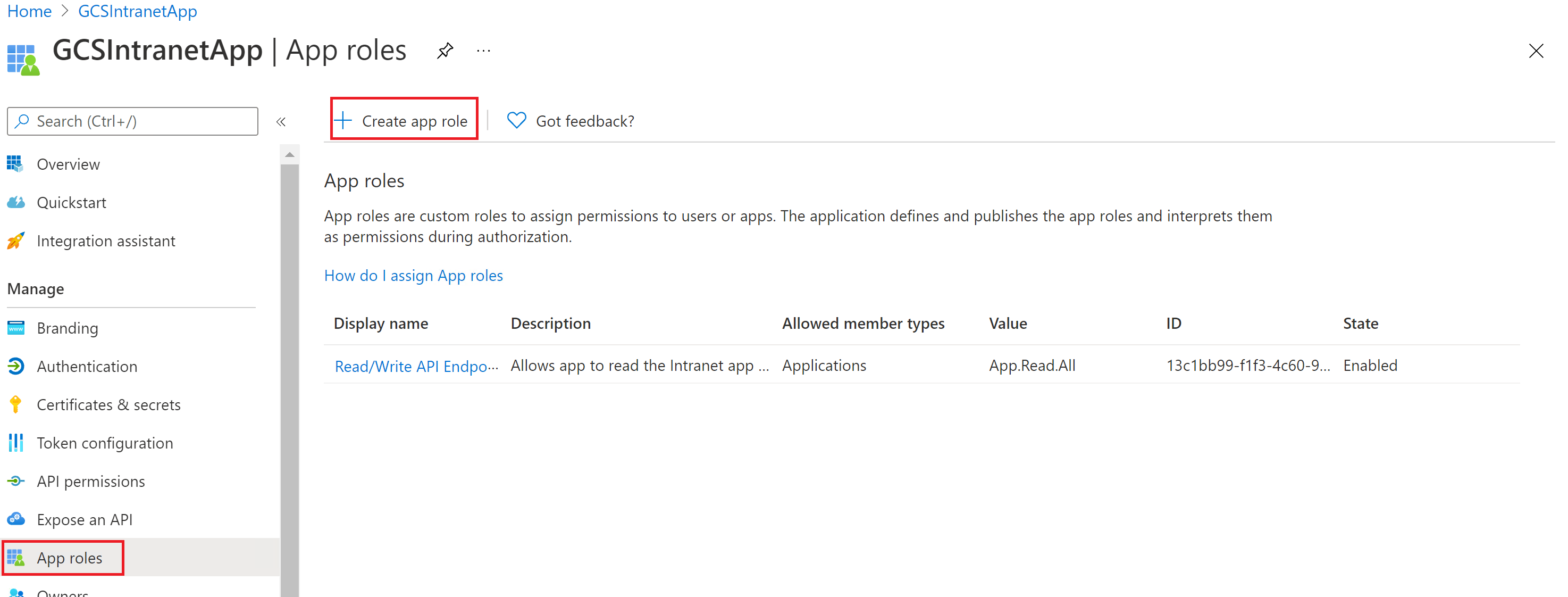
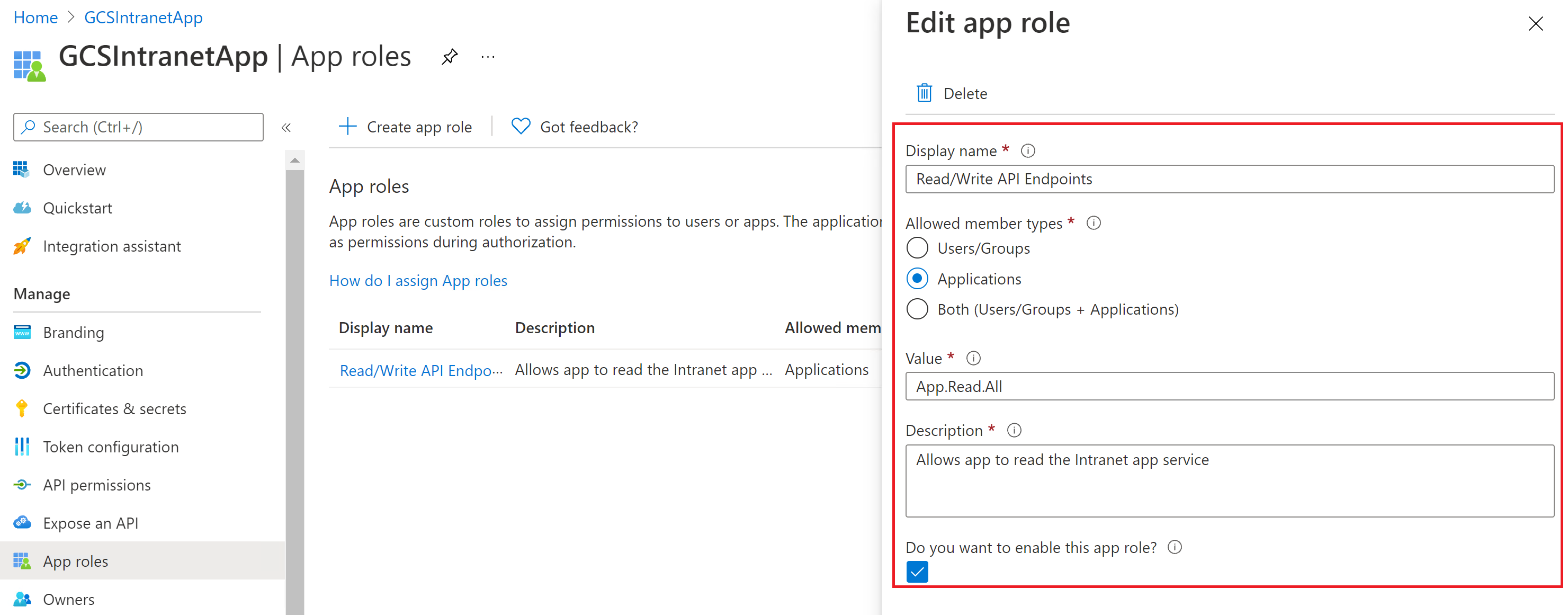
このアプリケーションでクライアント シークレットを構成する必要はありませんが、[アプリ ロール] セクション にアプリ ロールを追加する必要があります。これは後でクライアント アプリケーションに割り当てられます。 アプリ ロールを追加する方法については、画像を参照してください。
新しいアプリ ロールの作成:
新しいアプリ ロールの編集:
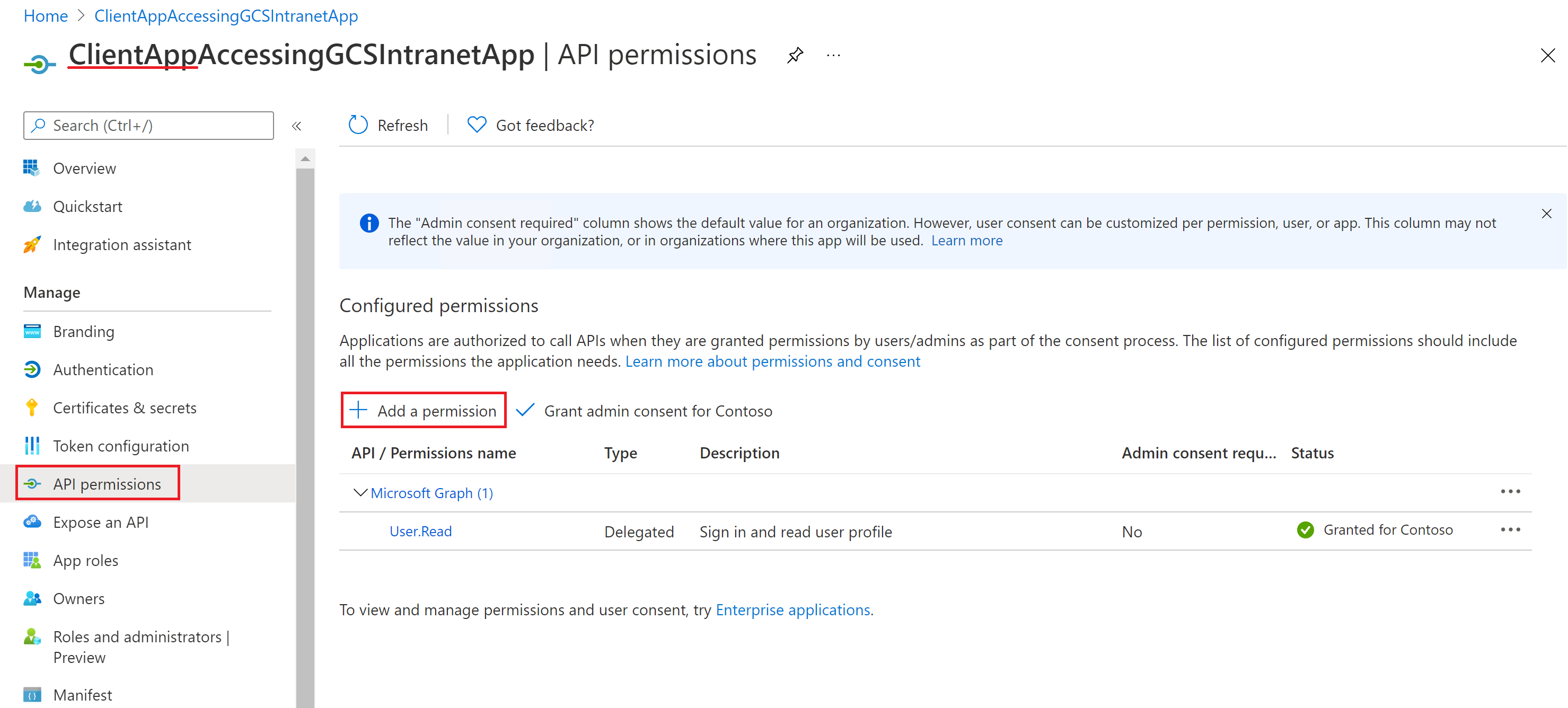
リソース アプリを構成したら、クライアント アプリを作成し、クライアント アプリの API アクセス許可で上記で構成したアプリ ロールを追加して、リソース アプリにアクセスするためのアクセス許可を付与します。
注:
クライアント アプリにアクセス許可を付与する方法については、「 クイック スタート: Web API にアクセスするようにクライアント アプリケーションを構成する」を参照してください。
次のスクリーンショットは、クライアント アプリにアクセス許可を付与するセクションを示しています。
アクセス許可の追加:
アクセス許可の選択:
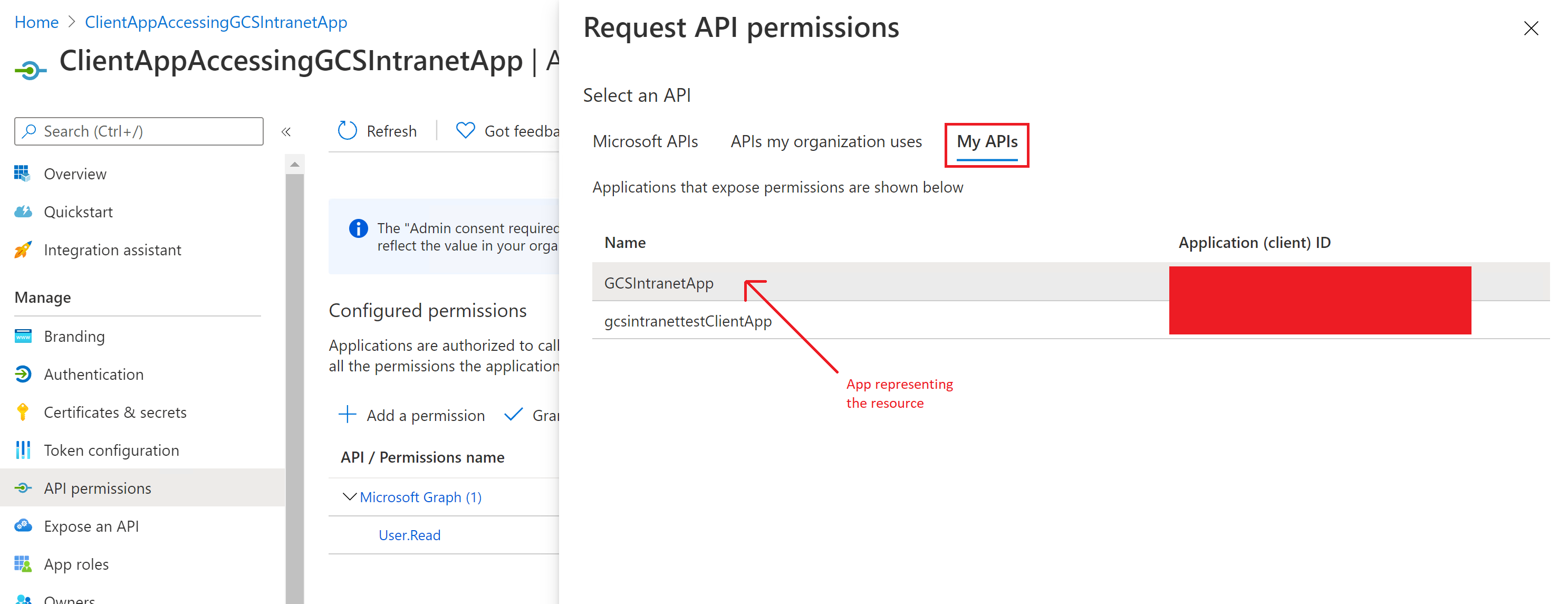
アクセス許可の追加:
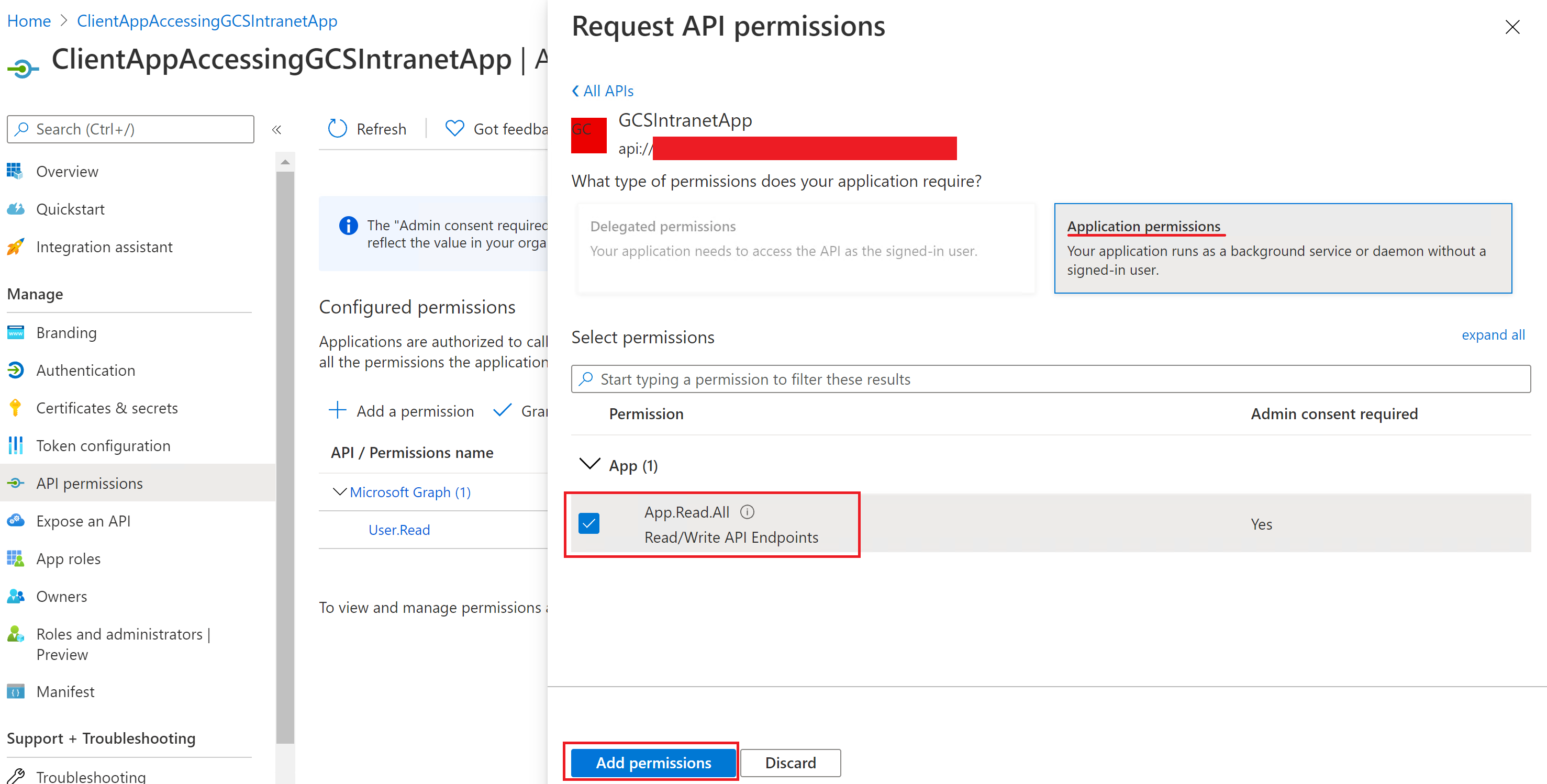
アクセス許可が割り当てられたら、[証明書 & シークレット] セクションに移動して、このアプリケーションの新しいクライアント シークレットを作成する必要があります。 ページに表示されるクライアント シークレットの値は、再び表示されないためコピーします。 このアプリのアプリケーション ID をクライアント ID として使用し、このアプリのシークレットをクライアント シークレットとして使用し、最初のアプリのアプリケーション ID をリソース ID として使用します。
![ブランド化ページの [設定] セクションを示す画像。](media/enterprise-web-connector/connectors-enterpriseweb-branding.png#lightbox)
![認証ページの [設定] セクションを示す画像。](media/enterprise-web-connector/connectors-enterpriseweb-authentication.png#lightbox)







4. 限定対象ユーザーにロールアウトする
ロールアウトを広範な対象ユーザーに展開する前に、Copilot やその他の Search サーフェスで検証する場合は、制限付きユーザー ベースにこの接続をデプロイします。 制限付きロールアウトの詳細については、「 段階的なロールアウト」を参照してください。
この時点で、クラウド Web サイトの接続を作成する準備ができました。 [ 作成 ] をクリックすると、Web サイトから接続とインデックス Web ページを発行できます。
アクセス許可、データ包含ルール、スキーマ、クロール頻度などのその他の設定については、Web サイトで最適な機能に基づいて既定値が設定されています。 既定値は次のとおりです。
| ユーザー | 説明 |
|---|---|
| アクセス許可 | organizationのすべてのユーザーにこのコンテンツが表示されます |
| コンテンツ | 説明 |
|---|---|
| 除外する URL | なし |
| プロパティの管理 | 既定のプロパティとそのスキーマをチェックするには、コンテンツに関するページを参照してください |
| 同期 | 説明 |
|---|---|
| 増分クロール | 頻度: 15 分ごと (サイトマップ クロールでのみサポート) |
| フル クロール | 頻度: 毎日 |
これらの値のいずれかを編集する場合は、"カスタム セットアップ" オプションを選択する必要があります。
カスタム セットアップ
カスタム セットアップは、上記の表に示した設定の既定値を編集する管理者向けです。 [カスタム セットアップ] オプションをクリックすると、[ユーザー]、[コンテンツ]、[同期] の 3 つのタブが表示されます。
ユーザー
![[ユーザー] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-users-tab.png#lightbox)
アクセス許可
Enterprise Websites クラウド コネクタでは、 すべてのユーザー にのみ表示される検索アクセス許可がサポートされています。 インデックス付きデータは、organization内のすべてのユーザーの検索結果に表示されます。
コンテンツ
![除外ルールとプロパティを設定できる [コンテンツ] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-content-tab.png#lightbox)
除外する URL を追加する (オプションのクロール制限)
ページがクロールされないようにするには、robots.txt ファイルでページを禁止するか、除外リストに追加する方法の 2 つの方法があります。
robots.txt のサポート
コネクタは、ルート サイトの robots.txt ファイルがあるかどうかを確認します。 存在する場合は、そのファイル内の指示に従って尊重します。 コネクタがサイト上の特定のページまたはディレクトリをクロールしないようにする場合は、robots.txt ファイルの "許可しない" 宣言にページまたはディレクトリを含めます。
除外する URL を追加する
必要に応じて 、除外リスト を作成して、コンテンツが機密性が高い場合やクロールする価値がない場合にクロールから一部の URL を除外できます。 除外リストを作成するには、ルート URL を参照します。 構成プロセス中に、除外された URL を一覧に追加できます。
プロパティの管理
ここでは、Web サイトから使用可能なプロパティを追加または削除したり、プロパティにスキーマを割り当てたり (プロパティが検索可能、クエリ可能、取得可能、または絞り込み可能かどうかを定義する)、セマンティック ラベルを変更してプロパティにエイリアスを追加したりできます。 既定で選択されているプロパティを次に示します。
| Source プロパティ | Label | 説明 | Schema |
|---|---|---|---|
| ブロック | ブロック | データ ソース内のアイテムに参加したユーザーのPeople | クエリ、取得 |
| コンテンツ | コンテンツ | Web ページ内のすべてのテキスト コンテンツ | 検索 |
| CreatedDateTime | 作成日時 | データ ソースでアイテムが作成されたデータと時刻 | クエリ、取得 |
| 説明 | 取得、検索 | ||
| FileType | ファイル拡張子 | クロールされたコンテンツのファイル拡張子 | クエリ、絞り込み、取得 |
| IconURL | IconUrl | Web ページのアイコン URL | 取り戻す |
| LastModifiedBy | 最終更新者 | データ ソース内のアイテムを最後に変更したユーザー | クエリ、取得 |
| LastModifiedDateTime | 最終更新日時 | データ ソースでアイテムが最後に変更された日時。 | クエリ、取得 |
| タイトル | タイトル | Copilot やその他の検索エクスペリエンスに表示するアイテムのタイトル | 取得、検索 |
| URL | url | データソース内のアイテムのターゲット URL | 取り戻す |
Enterprise Web サイト クラウド コネクタでは、次の 2 種類のソース プロパティがサポートされています。
メタ タグ
コネクタは、ルート URL に含まれる可能性があるメタ タグをフェッチして表示します。 クロールに含めるタグを選択できます。 選択したタグは、指定されたすべての URL に対してインデックスが作成されます (使用可能な場合)。
![メタ タグ パネルを含む [コンテンツ] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-metatags.png)
選択したメタ タグを使用して、カスタム プロパティを作成できます。 また、スキーマ ページでは、それらをさらに管理できます (クエリ可能、検索可能、取得可能、絞り込み可能)。
カスタム プロパティの設定
インデックス付きデータをエンリッチするには、選択したメタ タグまたはコネクタの既定のプロパティのカスタム プロパティを作成します。
![カスタム プロパティ パネルを含む [コンテンツ] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-custom-property.png)
カスタム プロパティを追加するには:
- プロパティ名を入力します。 この名前は、このコネクタの検索結果に表示されます。
- 値の場合は、[Static] または [String/Regex Mapping]\(文字列/正規表現マッピング\) を選択します。 静的な値は、このコネクタのすべての検索結果に含まれます。 文字列/正規表現の値は、追加するルールによって異なります。
- 静的な値を選択した場合は、表示する値を入力します。
- String/rRegex 値を選択した場合:
- [ 式の追加 ] セクションの [プロパティ ] の一覧で、一覧から既定のプロパティまたはメタ タグを選択します。 [ サンプル値] に、表示される可能性のある値の種類を表す文字列を入力します。 このサンプルは、ルールをプレビューするときに使用されます。 [ 式] に正規表現を入力して、検索結果に表示するプロパティ値の部分を定義します。 最大 3 つの式を追加できます。
- [ 数式の作成 ] セクションで、式から抽出された値を結合する数式を入力します。
![メタ タグ パネルを含む [コンテンツ] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-metatags.png#lightbox)
![カスタム プロパティ パネルを含む [コンテンツ] タブを示すスクリーンショット](media/enterprise-web-connector/enterprise-website-cloud-custom-property.png#lightbox)
正規表現の詳細については、「 .NET 正規表現 」を参照するか、Web で正規表現式リファレンス ガイドを検索してください。
同期
![クロール頻度を構成できる [同期] タブを示すスクリーンショット。](media/enterprise-web-connector/enterprise-website-cloud-sync-tab.png#lightbox)
更新間隔によって、データ ソースと Graph コネクタ インデックスの間でデータが同期される頻度が決まります。 更新間隔には、フル クロールと増分クロールの 2 種類があります。 詳細については、「 更新設定」を参照してください。
必要に応じて、ここから更新間隔の既定値を変更できます。
注:
増分クロールは、サイトマップ クロール オプションが選択されている場合にのみサポートされます。
トラブルシューティング
接続を公開したら、管理センターの [データ ソース] タブの状態を確認できます。 更新と削除を行う方法については、「接続を監視する」をご覧ください。 よく見られる問題のトラブルシューティング手順 については、こちらを参照してください。
問題がある場合、またはフィードバックを提供する場合は、Microsoft Graph にお問い合わせください |サポート。