Microsoft 365 管理センターで Microsoft Graph コネクタを設定する
この記事では、Microsoft 365 管理センターで Microsoft Graph コネクタを設定する手順について説明します。 セットアップ プロセスは合理化され、最小限の入力で接続の作成が簡略化されます。 ただし、カスタム セットアップを選択して、特定の設定を微調整できます。
注:
セットアップ プロセスはすべての Microsoft Graph コネクタで似ていますが、まったく同じではありません。 この記事を読むことに加えて、お使いのデータ ソースのコネクタに固有の情報を必ずお読みください。
注:
各テナントに最大 30(30) の Microsoft Graph 接続を追加できます。
ヒント
製品アンケート
Copilot または Microsoft Search へのより多くのデータ ソースの接続に関連する要件を理解するために、この アンケート フォームに記入するのに数分かかるようお願いします。 調査結果に基づいて、Microsoft は要求の多いデータ ソース用のコネクタを構築します。
前提条件
開始する前に、次のことを確認してください。
- 管理アクセス: Graph コネクタを構成するには、M365 管理センターで次のいずれかのロール (グローバル管理者、検索管理者、または Copilot 管理者) が必要です。
- データ ソース資格情報: 接続するデータ ソースに必要な資格情報とアクセス許可を収集します。
- サービス アカウント (該当する場合): データ ソースにサービス アカウントが必要な場合は、必要なロールまたはアクセス許可があることを確認します。
手順 1: Microsoft Graph コネクタを追加する
次の手順を実行して、Microsoft Graph コネクタのいずれかを構成します (または、 ここをクリックして コネクタ カタログに直接アクセスします)。
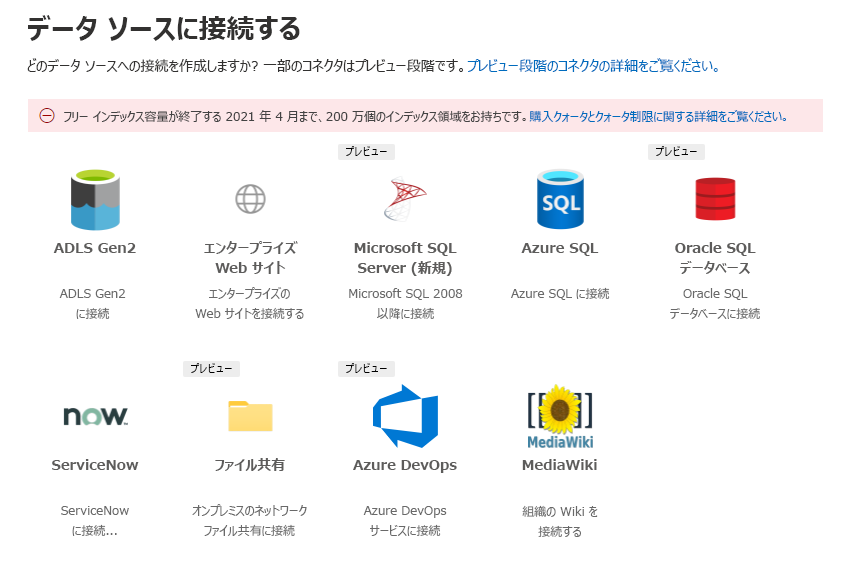
Microsoft 365 管理 センターを開きます。
- Microsoft 365 管理センターにサインインします。
[設定] に移動します。
- 左側のナビゲーション ウィンドウで、[設定] を選択します。
- [検索 & インテリジェンス] をクリックします。
新しいデータ ソースを追加します。
- [データ ソース] タブに移動します。
- [ + 追加] をクリックします。
- 使用可能なコネクタの一覧から、接続するデータ ソース (ServiceNow ナレッジ、Salesforce など) を選択します。
手順 2: 基本的な接続の詳細を入力する
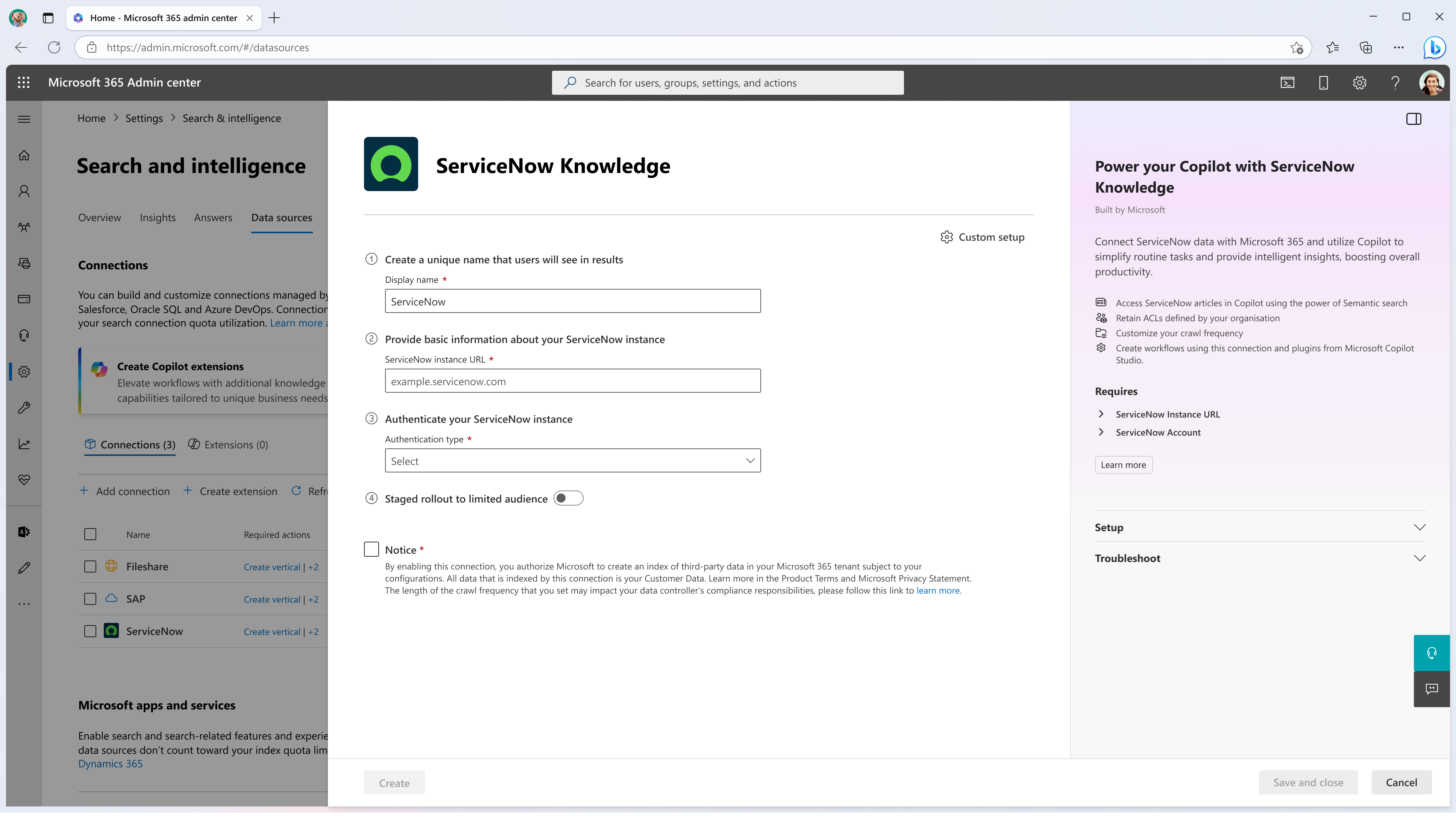
表示名:
- Copilot のソースと検索結果をユーザーが認識できるように、コネクタを識別する名前を入力します。
- 既定の名前が指定されていますが、organizationのニーズに合わせてカスタマイズできます。
データ ソース URL:
- データ ソースの URL を指定します。 たとえば、ServiceNow に接続している場合、URL は
https://your-organization-name.service-now.comのようになります。
- データ ソースの URL を指定します。 たとえば、ServiceNow に接続している場合、URL は
認証の種類:
- データ ソースにアクセスする認証方法を選択します。
限定対象ユーザーへのロールアウト
- 最初に、Copilot やその他の検索サーフェスで検証するために、コネクタをユーザーのサブセットにデプロイできます。 この機能を使用すると、より広範なロールアウトの前に統合をテストできます。
注:
ほとんどのコネクタでは、既定の設定がデータ ソース用に最適化されています。 これらの設定には、アクセス許可、スキーマ、同期頻度が含まれます。 これらの設定のいずれかを編集する場合は、 "カスタム セットアップ" オプションを選択する必要があります。
手順 3: 接続を作成する
- [ 作成 ] をクリックして接続を設定します。 コネクタは、既定の設定を使用してデータ ソースからコンテンツのインデックス作成を開始します。
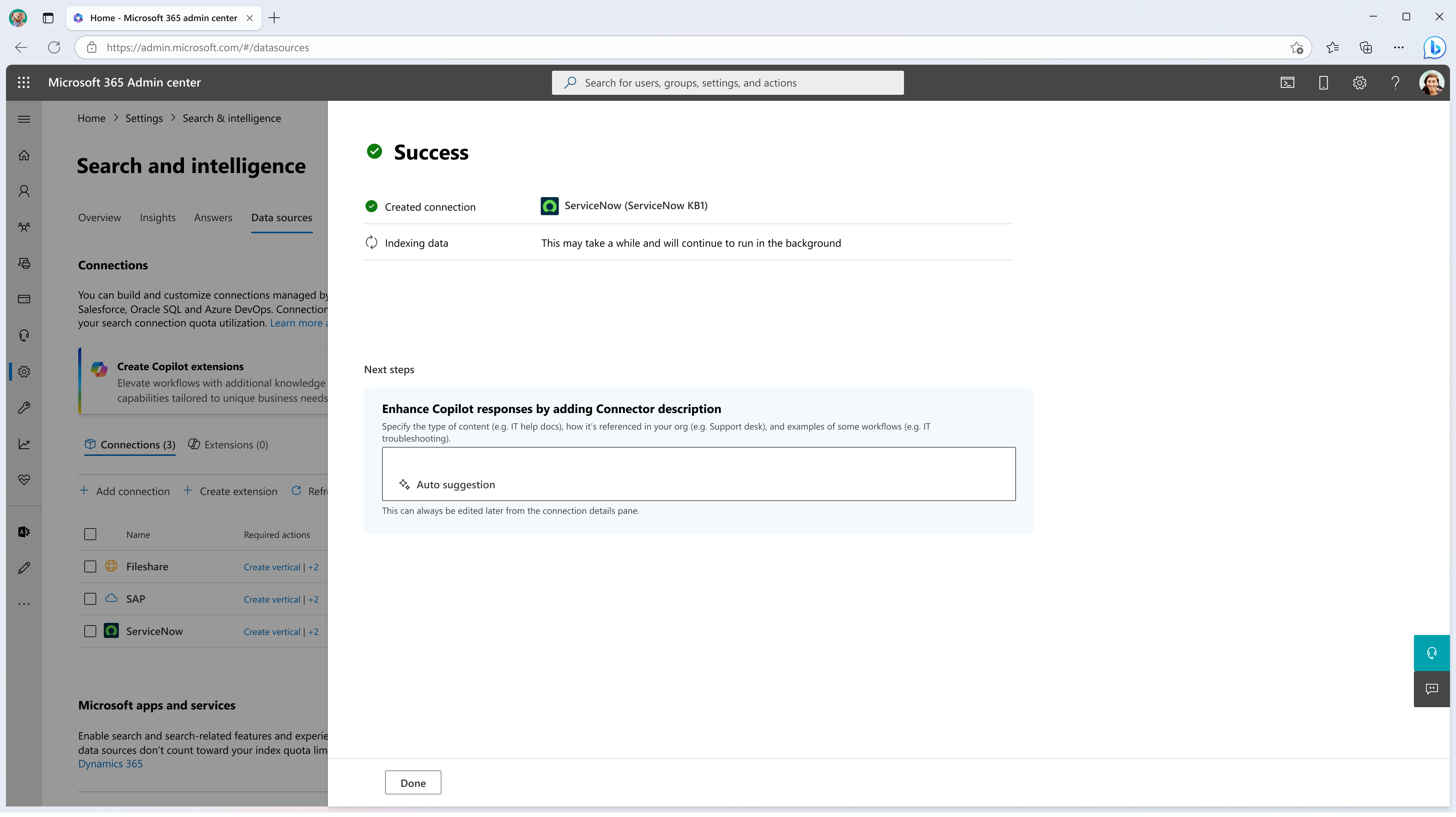
接続が作成されたら、成功画面で接続の説明を追加できます。 Copilot がユーザーの接続結果を向上させるために、説明は次の質問に簡単に答える必要があります。
- この接続にはどのようなコンテンツがありますか?
- ユーザーはそれぞれの組織でこのコンテンツ ソースをどのように参照しますか?
- ユーザーが日常業務でこのコンテンツを参照するワークフローの一部は何ですか?
- コンテンツの特徴は何ですか?
詳細については、Graph コネクタ コンテンツを使用したMicrosoft Copilot検出の強化に関する記事を参照してください。
カスタム セットアップ (省略可能)
構成をより詳細に制御する管理者は、[ カスタム セットアップ] オプションを選択できます。 このオプションを使用すると、 ユーザー、 コンテンツ、 同期の 3 つのタブにアクセスして、詳細な設定を行うことができます。
ユーザー
![アクセス許可とユーザー マッピング規則を構成できる [ユーザー] タブを示すスクリーンショット ユーザー](media/servicenow-knowledge-users-tab.png "に関連する設定を構成する")
アクセス許可:
- インデックス付きデータを表示するかどうかを選択します。
- organizationのすべてのユーザー。
- データ ソース内のコンテンツにアクセスできるユーザーのみ。
- インデックス付きデータを表示するかどうかを選択します。
マップ ID:
- 既定では、データ ソース内のメールがMicrosoft Entra IDの
UserPrincipalNameまたはMailと一致するかどうかを確認することで、ユーザーがマップされます。 - この既定値がorganizationに対して機能しない場合は、カスタム マッピング式を指定します。
- 既定では、データ ソース内のメールがMicrosoft Entra IDの
コンテンツ
![[クエリ文字列] と [プロパティ] コンテンツ](media/servicenow-knowledge-content-tab.png "に関連する設定を構成") できる [コンテンツ] タブを示すスクリーンショット
できる [コンテンツ] タブを示すスクリーンショット
プロパティの管理:
- データ ソースからプロパティを構成します (検索可能、クエリ可能、絞り込み可能にするなど)。
- セマンティック ラベルとエイリアスを割り当てて、検索の関連性を高めます。
プロパティの管理の詳細については、以下を参照 してください。
同期
![クロール頻度を構成できる [同期] タブを示すスクリーンショット クロール頻度](media/servicenow-knowledge-sync-tab.png "の構成")
更新間隔:
データ ソースと Graph コネクタ インデックス間のデータ同期の頻度を構成します。
- フル クロール: スケジュールされた間隔ですべてのデータを同期します。
- 増分クロール: 変更されたデータまたは新しいデータのみをUpdatesします。
organizationに必要に応じて、既定の同期設定を調整します。
同期設定の詳細については、以下を参照 してください。
その他のリソース
"プロパティの管理" のガイドライン
コンテンツ プロパティ
オプションのドロップダウン メニューから [コンテンツ プロパティ ] を選択するか、存在する場合は既定値のままにすることをお勧めします。 このプロパティは、コンテンツのフルテキスト インデックス処理、検索結果ページのスニペットの生成、結果クラスターへの参加、言語の検出、HTML/テキストのサポート、ランク付けと関連性、クエリの編成に使用されます。
コンテンツ プロパティを選択した場合は、結果の種類を作成するときにシステム生成プロパティ ResultSnippet を使用できます。 このプロパティは、クエリ時にコンテンツ プロパティから生成される動的スニペットのプレースホルダーとして機能します。 結果の種類でこのプロパティを使用すると、スニペットが検索結果に生成されます。
ソース プロパティのエイリアス
[エイリアス] 列の下のプロパティにエイリアスを追加できます。 エイリアスは、プロパティのフレンドリ名です。 これらはクエリやフィルターの作成で使用されます。 また、複数の接続からのソース プロパティを正規化して、同じ名前になるようにするためにも使用されます。 こうすることで、複数の接続を持つバーティカル用に 1 つのフィルターを作成できます。 詳細については、「検索バーティカルの管理」をご覧ください。
ソース プロパティのセマンティック ラベル
ソース プロパティにセマンティック ラベルを割り当てることができます。 ラベルは Microsoft によって提供される既知のタグで、セマンティックな意味を提供します。 これにより、Microsoft はコネクタ データを Copilot、拡張検索、人物カード、インテリジェント検出などの Microsoft 365 エクスペリエンスに統合できます。
次の表に、現在サポートされているラベルとその説明を示します。
| Label | 説明 |
|---|---|
| title | 検索や他のエクスペリエンスに表示する、アイテムのタイトル |
| url | ソース システム内のアイテムのターゲット URL |
| 作成者 | アイテムを作成したユーザーの名前 |
| 最終更新者 | アイテムを最後に編集したユーザーの名前 |
| Authors | アイテムの作成に参加したり共同作業を行ったりしたユーザーの名前 |
| 作成日時 | アイテムが作成された時刻 |
| 最終更新日時 | アイテムが最後に編集された時刻 |
| ファイル名 | ファイル アイテムの名前 |
| ファイル拡張子 | .pdf や .word など、ファイル アイテムの種類 |
このページのプロパティはお使いのデータ ソースに基づいて事前に選択されていますが、特定のラベルにより適した別のプロパティがある場合は、この選択を変更できます。
ラベル タイトル が最も重要です。 結果のクラスター エクスペリエンスに参加するために、接続のためにこのラベルにプロパティを割り当てることを強くお勧めします。
ラベルのマッピングが正しくないと、検索エクスペリエンスが低下します。 一部のラベルにプロパティが割り当てられていなくても問題ありません。
検索スキーマの属性
検索スキーマ属性を設定して、各ソース プロパティの検索機能を制御できます。 検索スキーマは、検索結果ページに表示される結果と、エンド ユーザーが表示およびアクセスできる情報を決定するのに役立ちます。
検索スキーマの属性には、クエリ、検索、取得、絞り込みに対するオプションがあります。 次の表に Microsoft Graph コネクタがサポートする各属性の一覧を示し、その機能について説明します。
| 検索スキーマの属性 | 職務 | 例 |
|---|---|---|
| SEARCH | プロパティのテキスト コンテンツを検索できるようにします。 プロパティ コンテンツは、フルテキスト インデックスに含められます。 | プロパティがタイトルの場合、エンタープライズをクエリすると、テキストまたはタイトルにエンタープライズという語句を含む回答が返されます。 |
| クエリ | クエリでは、特定のプロパティの一致を検索します。 その後、プロパティ名をプログラムで、または逐語的にクエリに指定できます。 | Title プロパティをクエリできる場合は、Title: エンタープライズというクエリがサポートされます。 |
| 取得 | 取得可能なプロパティのみを結果の種類で使用し、検索結果に表示できます。 | |
| 絞り込み | 絞り込みオプションは、Microsoft 検索結果ページと同様に使用できます。 | organizationのユーザーは、接続のセットアップ中に refine プロパティがマークされている場合、検索結果ページの URL でフィルター処理できます。 |
ファイル共有コネクタを除くすべてのコネクタでは、カスタム型を手動で設定する必要があります。 各フィールドの検索機能をアクティブにするには、検索スキーマをプロパティの一覧にマップする必要があります。 接続構成アシスタントは、選択したソース プロパティのセットに基づいて検索スキーマを自動的に選択します。 このスキーマを変更するには、検索スキーマ ページで各プロパティと属性のチェック ボックスを選択します。

検索スキーマの設定に関する制限事項と推奨事項
コンテンツ プロパティは検索のみ可能です。 ドロップダウンで選択した後、このプロパティを 取得 または クエリオプションで使用することはできません。
コンテンツ プロパティを使用して検索結果をレンダリングすると、パフォーマンスに大きな問題が発生します。 たとえば、ServiceNow のナレッジ ベース記事の Text コンテンツ フィールドの場合がそうです。
取得可能としてマークされたプロパティのみが検索結果にレンダリングされ、モダンな結果の種類 (MRT) の作成に使用できます。
検索可能とマークできるのは文字列プロパティのみです。
注:
接続の作成後にスキーマを更新するには、 検索スキーマの管理 に関する記事を参照してください。
同期設定のガイドライン
更新間隔によって、データ ソースと Microsoft Search の間でデータが同期される頻度が決まります。 データ ソースの種類ごとに、データの変更頻度と変更の種類に基づいて、最適な更新スケジュールのセットが異なります。
更新間隔には、 完全更新 と 増分更新の 2 種類がありますが、一部のデータ ソースでは増分更新を使用できません。
完全更新を使用すると、検索エンジンは、以前のクロールに関係なく、コンテンツ ソースで変更されたアイテムを処理してインデックスを作成します。 完全更新は、次の状況に最適です。
- データの削除を検出する。
- 増分更新でエラーが検出され、失敗した。
- ACL (Access Control Lists) が変更されました。
- クロール ルールが変更された。
- 接続のスキーマが更新されました。
増分更新を使用すると、検索エンジンは、前回正常にクロールされた後に作成または変更されたアイテムのみを処理してインデックスを作成できます。 その結果、コンテンツ ソース内のすべてのデータのインデックスが再作成されるわけではありません。 増分更新は、コンテンツ、メタデータ、およびその他の更新を検出するのに最適です。
注:
増分クロールでは、現在、 アクセス許可に対する更新の処理はサポートされていません。
増分更新は、変更されていない項目は処理されないため、完全更新よりも高速です。 ただし、増分更新を実行することを選択した場合でも、コンテンツ ソースと検索インデックスの間で正しいデータ同期を維持するために、完全更新を定期的に実行する必要があります。
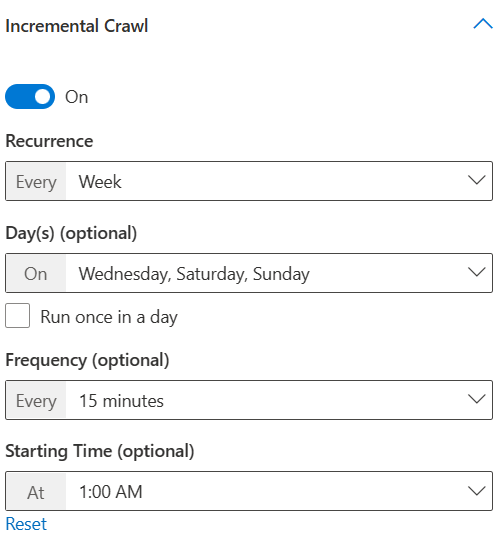
クロール スケジュール
[更新設定] ページに表示される高度なスケジュール 設定オプションに基づいて、フル クロールと増分クロールを構成できます。 一部のコネクタでは増分クロールがサポートされていないため、増分クロールを構成するオプションは、これらのコネクタでは使用できません。 それ以外の場合、増分クロールはオプションのクロールであり、既定で有効になっています。 コネクタの種類に基づいて、クロール スケジュールが既定で選択されます。 この既定の設定は、接続の作成時に変更することも、接続の "編集" フローから接続を発行した後に編集することもできます。 次のフィールドから選択できます。
- 繰り返し: 毎日、週、2 週目、または 4 週目にクロールを実行できます。
- 日: このオプションは、特定の曜日にのみクロールを実行する場合に有効になります。
- [1 日 1 回実行チェック ボックスを使用すると、1 日にクロールの開始時刻を選択できます。 選択されていない場合、クロールは既定で 1 日で繰り返されます。 ドロップダウンから繰り返し間隔を選択できます。
- 頻度: 特定の時間間隔の 1 日後にクロールを繰り返す場合は、このオプションを選択します。 最小の繰り返し頻度は 15 分で、最大は 12 時間です。
- 開始時刻: クロールを開始する時刻を選択します。
- リセット: このオプションは、コネクタの既定のスケジュールにスケジュールをリセットします。
クロール スケジュールの構成中に注意すべき点を次に示します。
- いずれかのフィールドを空のままにするか、選択されていない場合、Graph コネクタはクロールを開始するための最適なタイミングを選択します。 たとえば、クロールの繰り返しを "日" として選択し、開始時刻を選択しない場合、Graph コネクタは最後のクロールに基づいて時間を選択して新しいクロールを開始します。 クロールの開始時刻を指定しない場合は、コネクタがクロールを開始するタイミングを決定することをお勧めします。
- 開始時刻が記載されていても、クロールの開始が 1 時間遅れる可能性があります。 この遅延は、ネットワークの負荷などの理由が原因である可能性があります。
- 前のクロールが次のクロールの時刻までオーバーランした場合、進行中のクロールは停止されず、次のクロールがキューに入れられます。 進行中のクロールが完了した後、キューに登録されたクロールは、前のクロールとは異なる種類 (フル/増分) の場合にのみ実行されます。 たとえば、増分クロールが次のフル クロールをオーバーランした場合、増分クロールを中断せず、フル クロールをキューに入れます。 増分クロールが完了すると、キューに登録されたクロールの種類が異なるため (完全)、すぐにフル クロールを開始します。
シナリオの一部を次に示します。
- 15 分ごとに増分クロールを毎日実行する
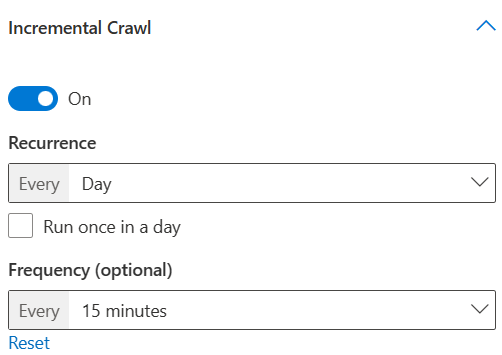
ここで [1 日に 1 回実行] チェック ボックスをオンにすると、[開始時刻] を選択して、指定した時刻から 1 日に 1 回だけ増分クロールを実行できます。 ただし、選択を解除すると、クロールの繰り返しの頻度を 1 日で選択できます。 データを継続的に更新する場合は、増分クロールを 1 日で頻繁に実行するように選択できます。 ただし、データ ソース内のアイテムの数が多く、クロールが長くなる傾向がある場合、またはコンテンツに頻繁な更新が必要ない場合は、増分クロールを 1 日に 1 回実行するように選択できます。
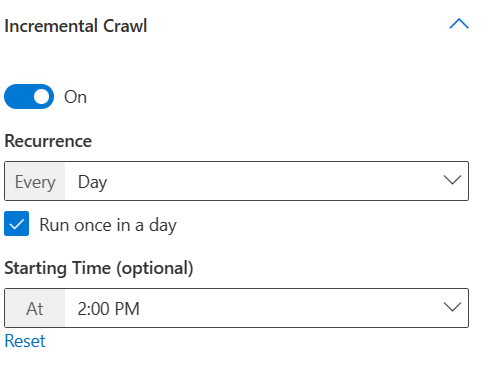
- 毎週水曜日、土曜日、日曜日に増分クロールを実行し、15 分ごとに午前 1 時から繰り返します。
- 毎日午前 1 時にフル クロールを実行する

- 金曜日の午後 8:00 に毎週フル クロールを実行する
