Microsoft Syntexで構造化または自由形式のドキュメント処理モデルをトレーニングする
「Syntex でモデルを作成する」の手順に従って、コンテンツ センターで構造化またはフリーフォームのドキュメント処理モデルを作成します。 または、「 ローカル SharePoint サイトにモデルを作成する 」の手順に従って、ローカル サイトにモデルを作成します。 次に、この記事を使用してモデルをトレーニングします。

構造化または自由形式のドキュメント処理モデルをトレーニングするには、次の手順に従います。
手順 1: ドキュメントを追加して分析する
構造化または自由形式のドキュメント処理モデルを作成すると、[ 抽出する情報の選択] ページが開きます。 ここでは、AI モデルがドキュメントから抽出するすべての情報 ( 名前、 住所、 金額など) を一覧表示します。
注:
使用するファイルの例を探す場合は、 ドキュメント処理モデルの入力ドキュメントの要件と最適化のヒントを参照してください。
最初に、[抽出する情報の選択] ページで、モデルの抽出対象に設定するフィールドおよびテーブルを定義します。 詳細な手順については、「抽出するフィールドとテーブルを定義する」を参照してください。
モデルが処理するドキュメント レイアウトのコレクションは、必要なだけ作成することができます。 詳細な手順については、「コレクションごとにドキュメントをグループ化する」を参照してください。
コレクションを作成し、それぞれに少なくとも 5 つのサンプル ファイルを追加すると、Syntex 上の AI Builder によってアップロードされたドキュメントが調べられ、フィールドとテーブルが検出されます。 通常、このプロセスには数秒かかります。 分析が完了したら、ドキュメントのタグ付けに進むことができます。
手順 2: フィールドとテーブルにタグを付けます
モデルが抽出するフィールドとテーブル データを理解するよう設定するため、ドキュメントをタグ付けする必要があります。 詳細な手順については、「ドキュメントにタグを付ける」を参照してください。
手順 3: モデルをトレーニングして公開する
モデルを作成してトレーニングしたら、発行して SharePoint で使用できます。 モデルを発行するには、[発行] を選択 します。 詳細な手順については、「 ドキュメント処理モデルをトレーニングして発行する」を参照してください。
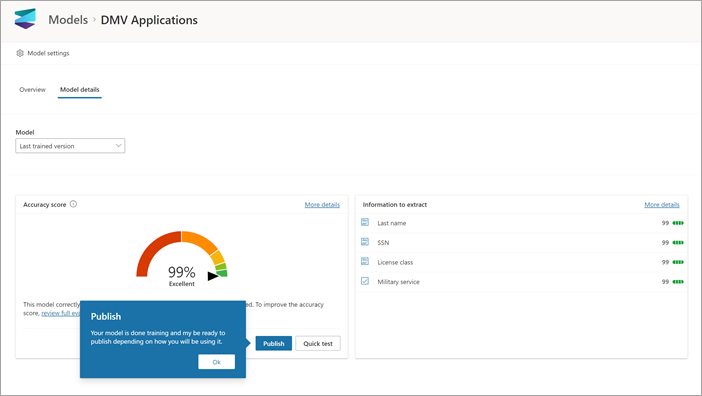
モデルが発行されたら、モデルのホーム ページに移動します。 次に、モデルをドキュメント ライブラリに適用するオプションがあります。
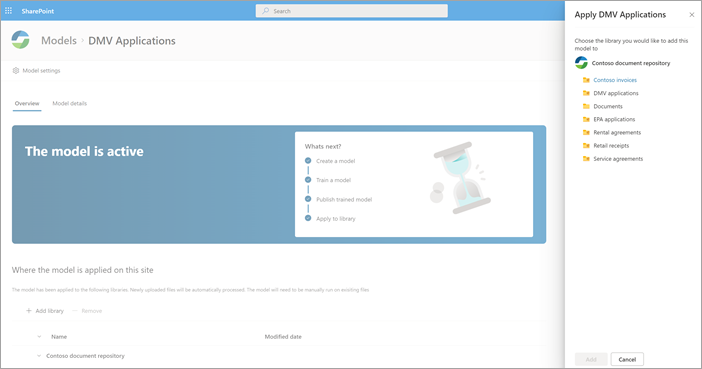
手順 4: モデルを使用する
[ドキュメント ライブラリ モデル] ビューで、選択したフィールドが列として表示されるようになりました。
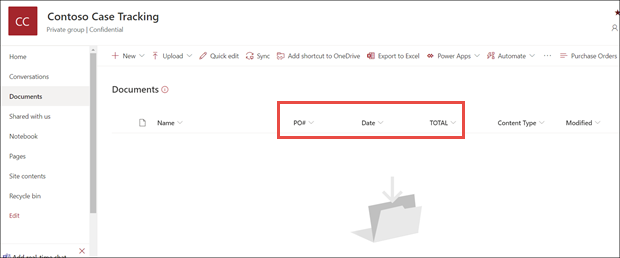
[ドキュメント] の横にある [情報] リンクで、フォーム処理モデルがこのドキュメント ライブラリに適用されていることが示されています。
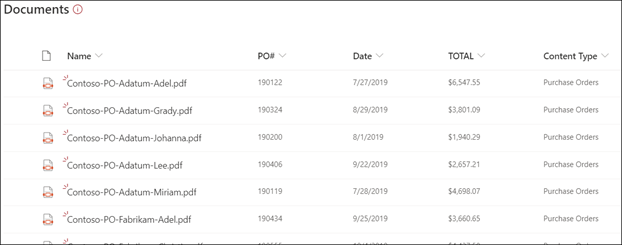
ファイルをドキュメント ライブラリにアップロードします。 モデルがコンテンツ タイプとして識別するファイルには、ビュー内のファイルが一覧表示され、列に抽出されたデータが表示されます。
注:
構造化または自由形式のドキュメント処理モデルと非構造化ドキュメント処理モデルが同じライブラリに適用されている場合、ファイルは非構造化ドキュメント処理モデルとそのモデルのトレーニング済みの抽出器を使用して分類されます。 ドキュメント処理モデルに一致する空の列がある場合、抽出された値を使用して列が設定されます。
処理するページ範囲を設定する
このモデルでは、ファイル全体ではなく、ファイルのページ範囲を処理するように指定できます。 [ モデル設定] の [ ページ範囲 ] 設定でこれを行います。 既定では、[ ページ範囲 ] 設定は空です。 ページ範囲が指定されていない場合、ドキュメント全体が処理されます。 詳細については、「 特定のページから情報を抽出するページ範囲を設定する」を参照してください。
分類日付フィールド
任意のカスタム モデルがドキュメント ライブラリに適用されると、[ 分類日 ] フィールドがライブラリ スキーマに含まれます。 既定では、このフィールドは空です。 ただし、ドキュメントがモデルによって処理および分類されると、このフィールドは完了の日付タイム スタンプで更新されます。
モデルに 分類日のスタンプが付いている場合は、 Syntex がファイル フローを処理した後に電子メールを送信 するを使用して、SharePoint ドキュメント ライブラリのモデルによって新しいファイルが処理および分類されたことをユーザーに通知できます。
フローを実行するには:
ファイルを選択し、[ 統合>Power Automate>フローの作成] を選択します。
[ フローの作成 ] パネルで、[ Syntex がファイルを処理した後に電子メールを送信する] を選択します。
![[フロー の作成] パネルと [フロー] オプションが強調表示されているスクリーンショット。](../media/content-understanding/integrate-create-flow.png)
フローを使用して情報を抽出する
重要
このセクションの情報は、Syntex の最新リリースには適用されません。 これは、以前のリリースで作成されたフォーム処理モデルについてのみ参照として残されます。 最新リリースでは、既存のファイルを処理するようにフローを構成する必要はなくなりました。
構造化または自由形式のドキュメント処理モデルが適用されているライブラリ内の選択したファイルまたはファイルのバッチを処理するには、2 つのフローを使用できます。
ドキュメント処理モデルを使用して画像または PDF ファイルから情報を抽出する - ドキュメント処理モデル を実行して、選択した画像または PDF ファイルからテキストを抽出します。 選択した 1 つのファイルを一度に 1 つサポートし、PDF ファイルとイメージ ファイル (.png、.jpg、.jpeg) のみをサポートします。 フローを実行するには、ファイルを選択し、[ Automate>Extract info] を選択します。
![[情報の抽出] が強調表示されている [自動化] メニューを示すスクリーンショット。](../media/content-understanding/automate-extract-info.png)
ドキュメント処理モデルを使用してファイルから情報を抽出する - ドキュメント処理モデル と共に使用して、ファイルのバッチから情報を読み取り、抽出します。 一度に最大 5,000 個の SharePoint ファイルを処理します。 このフローを実行すると、設定できる特定のパラメーターがあります。 次の操作を行うことができます:
- 以前に処理されたファイルを含めるかどうかを選択します (既定では、以前に処理されたファイルは含まれません)。
- 処理するファイルの数を選択します (既定値は 100 ファイル)。
- ファイルを処理する順序を指定します (選択肢は、ファイル ID、ファイル名、ファイル作成時刻、または最終変更時刻です)。
- 順序を並べ替える方法 (昇順または降順) を指定します。
![パラメーター オプションが強調表示されている [フローの実行] パネルを示すスクリーンショット。](../media/content-understanding/run-flow-panel.png)
注:
ドキュメント処理モデル フローを使用して画像または PDF ファイルから情報を抽出すると、ドキュメント処理モデルが関連付けられたライブラリで自動的に使用できます。 ドキュメント処理モデル フローを使用してファイルから情報を抽出するフローは、必要に応じてライブラリに追加する必要があるテンプレートです。