SDOH データセット - 変換 (プレビュー) でパブリック データセットを準備する
[この記事はプレリリース ドキュメントであり、変更されることがあります。]
SDOH パブリック データセットには、政府機関や大学などの他の公式ソースによって公開された、健康の社会的決定要因 (SDOH) の集約データが含まれています。 これらのデータセットは、都道府県、国、郵便番号などの地理レベルで、さまざまな SDOH パラメーターを統合します。 SDOH データセット - 変換 (プレビュー) では、これらの地理レベルのデータセットを CSV (コンマ区切り値) または XLSX (Excel Open XML スプレッドシート) 形式で取り込み、カスタム データ モデルに正規化することができます。
プレビュー リリースでは、さまざまな SDOH ドメインからの次の 8 つのサンプル SDOH データセットが提供されており、データ パイプラインの実行や、ブロンズ、シルバー、ゴールドのレイクハウス レイヤーによるデータ変換の検討に役立ちます:
USDA の食品環境アトラス: 店舗/レストランの近接性、食品価格、栄養補助プログラム、コミュニティの特性などの要因が含まれます。 これらの要因は、食品の選択、食事の質、そして最終的には健康状態に影響を与えます。
USDA の Rural Atlas: 人口、仕事、郡の分類、所得、退役軍人などの社会経済的要因に関する統計を提供します。
AHRQ の SDOH データ: SDOH の 5 つの主要領域に関する詳細を提供します:
- 年齢、人種/民族、退役軍人の地位などの社会的背景。
- 所得、失業率などの経済的背景。
- 教育です
- 住宅、犯罪、交通などの物理的インフラストラクチャ。
- 健康保険などの医療的背景。
ロケーション アフォーダビリティ インデックス: 世帯の住居費と交通費を近隣レベルで推計します。
環境正義指数: 複数のソースからデータを集約し、国勢調査区域ごとに環境不正義が健康に及ぼす累積的な影響をランク付けします。
ACS 教育達成度: 大規模かつ継続的な人口統計調査から導き出された、地理的領域の教育に関する分析情報を提供します。
オーストラリアの SEIFA: 所得、教育、雇用、住宅などのオーストラリアの国勢調査データを組み合わせ、地域の社会経済的特徴をまとめています。
英国剥奪指数: 英国内で広く使用されている社会経済指標で、さまざまな側面をカバーする小さな地域の貧困を評価します。
ここで:
- USDA: 米国農務省
- AHRQ: 医療研究品質局
- ACS: アメリカン コミュニティ サーベイ
- SEIFA: 地域の社会経済指標
重要
これらのデータセットは単なるサンプルではなく、それぞれの組織によって公開された完全な実際のデータセットです。 これらは、地理的領域の SDOH プロファイルを正確に表しています。 これらは連邦政府機関の公式出版物であるため、修正する場合には注意してください。
フォルダー構造
SDOH データセット - 変換 (プレビュー) のランディング ゾーンは、取り込み、プロセス、失敗 の 3 つのフォルダーで構成されます。 これらのフォルダーの詳細については、統合フォルダー構造 を参照してください。
インジェスト前に SDOH データセットを準備する
SDOH パブリック データセットを取り込む前に、正常に取り込む準備ができていることを確認してください。 次のセクションでは、2 つのシナリオについて説明します:
- 自分のデータセットを使用する
- サンプル データセットを使用する
自分のデータセットを使用する
SDOH パブリック データセットは、形式、量、構造において、公開する組織によって大きく異なります。 キャプチャした情報を収集および交換するための確立された基準がありません。 したがって、データ モデル内で表現する前に、それらを共通の形状に統一することが不可欠です。
選択した SDOH パブリック データセットを取り込んで変換するには、次の 3 つの重要な情報を追加します:
レイアウト: SDOH データをキャプチャするための標準コード セットがないため、各フィールドの意味を理解することは困難です。 この問題を解決するには、レイアウト という名前の新しいシートを追加してデータセットのデータ ディクショナリを作成するか (データセットが XLSX 形式の場合)、次の例に示す列を含む新しい CSV ファイルを作成します (データセットが CSV 形式の場合)。
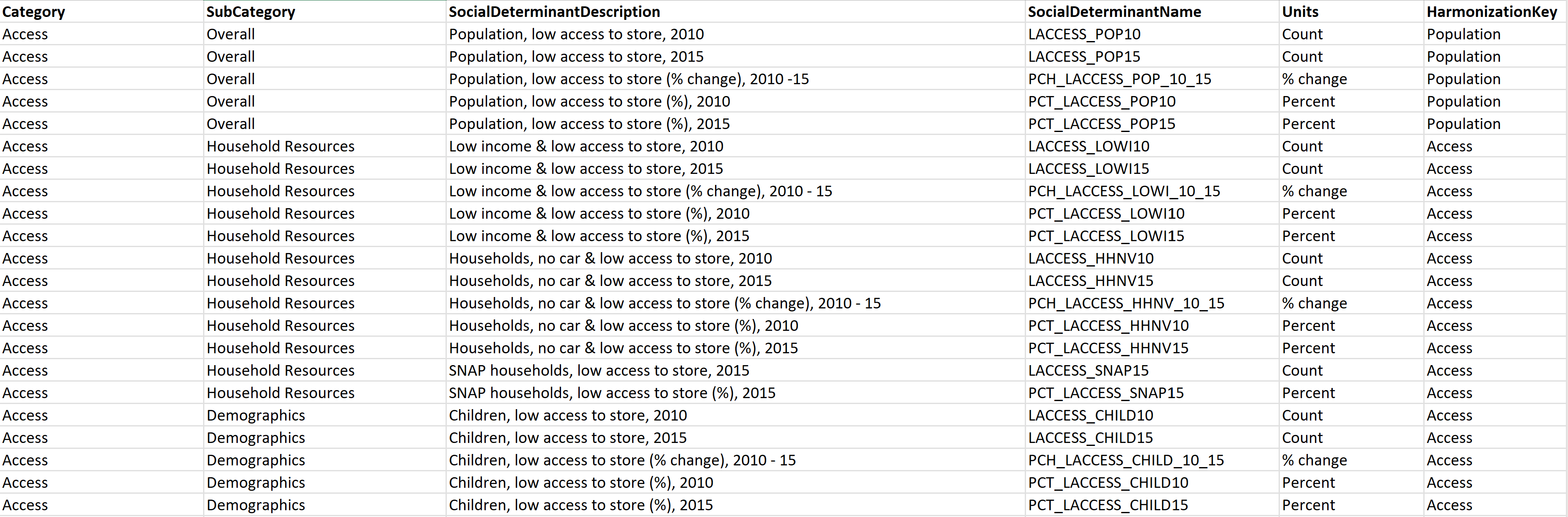
DataSetMetadata: SDOH データセットはさまざまな公開元から提供されるため、データセットに関する重要な詳細を記録することが重要です。 DataSetMetadata という名前の新しいシートを追加するか (データセットが XLSX 形式の場合)、次の例に示す列を含む新しい CSV ファイルを作成します (データセットが CSV 形式の場合)。

LocationConfiguration: 地域によって、位置データはさまざまな方法で定義および編成されます。 SDOH パイプラインがデータセットの地理的構造を理解できるようにするには、LocationConfiguration という名前の新しいシートを追加するか (データセットが XLSX 形式の場合)、次の例に示す列を含む新しい CSV ファイル (データセットが CSV 形式の場合) を作成します。
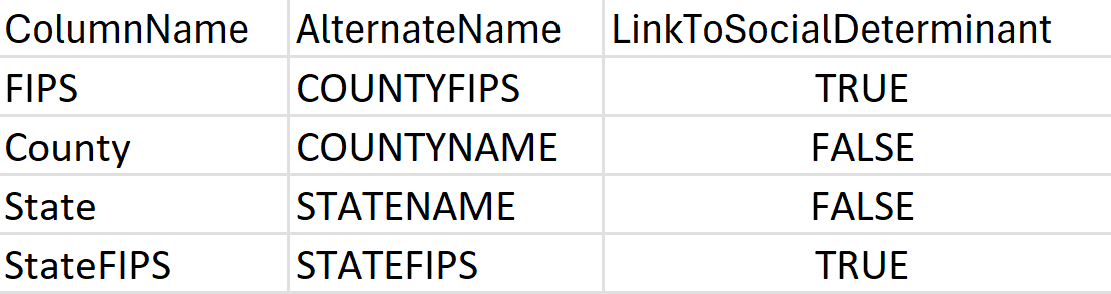



または:
- サンプル SDOH データセットの構造を参照して、社会的決定要因のカテゴリ、メタデータ、調和キーなどの必要な情報を入力できます。
- 元のデータセットから特定のフィールドを取り込みたくない場合は、データ シートからフィールドを削除するか、レイアウト シートで詳細を空白のままにします。 どちらの場合も、シルバー データ モデルには含まれません。
- 名前、公開日、公開元が同じデータセットは、重複として扱われます。
サンプル データセットを使用する
医療データ ソリューションで提供されるサンプル SDOH データセットには、すべての前提条件情報が事前に入力されており、OneLake で使用できます。 これらはローカルで抽出できます。
データセットを Fabric ワークスペースにアップロードする
データセットの準備ができたら、次の 2 つのオプションのいずれかを選択してアップロードします。 オプション 2 は、SDOH データセット - 変換 (プレビュー) で提供されるサンプル データセットを使用している場合にのみ使用できます。
- オプション 1: データセットを手動でアップロードする。
- オプション 2: スクリプトを使用して、データセットをアップロードする。
データセットを手動でアップロードする
医療データ ソリューション環境で、healthcare#_msft_bronze レイクハウスを選択します。
取り込み フォルダーを開きます。 詳細については、フォルダーの説明 を参照してください。
フォルダー名の横にある省略記号 (...) を選択し、フォルダーのアップロード を選択します。
ローカル システムからデータセットをアップロードします。 OneLake ファイル エクスプローラー を使用して、次のパスでデータセットを検索します:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset。取り込み フォルダーを更新します。 SDOH サブフォルダー内にデータセット ファイルが表示されます。
スクリプトを使用して、データセットをアップロードする
重要
このオプションは、提供されているサンプル データセットを使用する場合にのみ使用してください。
医療データ ソリューションの Fabric ワークスペースに移動します。
+ 新規アイテム を選択します。
新しいアイテム ウィンドウで、ノートブック を検索して選択します。
ノートブックに次のコード スニペットをコピーします。
workspace_id = '<workspace_id>' # Workspace ID. Retrieve the value from the healthcare#_msft_config_notebook. one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint. Retrieve the value from the healthcare#_msft_config_notebook. solution_id = "<solution_id>" # Solution ID. Retrieve the value from the healthcare#_msft_config_notebook. bronze_lakehouse_id = "<bronze_lakehouse_id>" # To locate the bronze lakehouse ID, open the bronze lakehouse and check the URL in the browser's address bar: https://{baseurl}/lakehouse/{GUID}/details). The {GUID} value in the URL is the bronze lakehouse ID. def copy_source_files_and_folders(source_path, destination_path): # List the contents of the source directory source_contents = mssparkutils.fs.ls(source_path) # List the contents of the destination directory try: destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} except Exception as e: print(f"Destination path {destination_path} does not exist or is empty. Creating the path.") destination_files = {} mssparkutils.fs.mkdirs(destination_path) # Copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" if item.isDir: # Recursively copy the contents of the directory copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # Define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_id}@{one_lake_endpoint}/{solution_id}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/XLSX" # Copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)ノートブックを実行します。 これで、サンプルの SDOH データセットが 取り込み フォルダー内の指定された場所に移動します。
これで、SDOH データセットのインジェストの準備が整いました。