データ ストレージ内の Microsoft Graph データを分析する
この記事では、ビジネス プロセスと生産性を向上させるためにエンタープライズ コラボレーション データの複雑な分析を必要とするビジネス シナリオの一般的な Microsoft Graph 統合パターンについて説明します。
このシナリオは、大量の抽出された Microsoft 365 データに依存しており、次の要件があります。
- データ統合の種類。
- Microsoft 365 境界からアプリへの送信データ フロー。
- 複数の月にまたがる大量のデータ。
- 比較的高いデータ待機時間。最初のデータ抽出には、最大 1 年前のメッセージが含まれる場合があります。
このシナリオに最適なオプションは、Microsoft Graph Data Connect を使用することです。 クライアントは、Azure Data Lake や Azure Synapse などの大容量データ ストレージを設定し、Azure サブスクリプションを有効にし、Azure Data FactoryまたはAzure Synapse パイプラインを構成する必要があります。
次の図は、このソリューションのアーキテクチャを示しています。
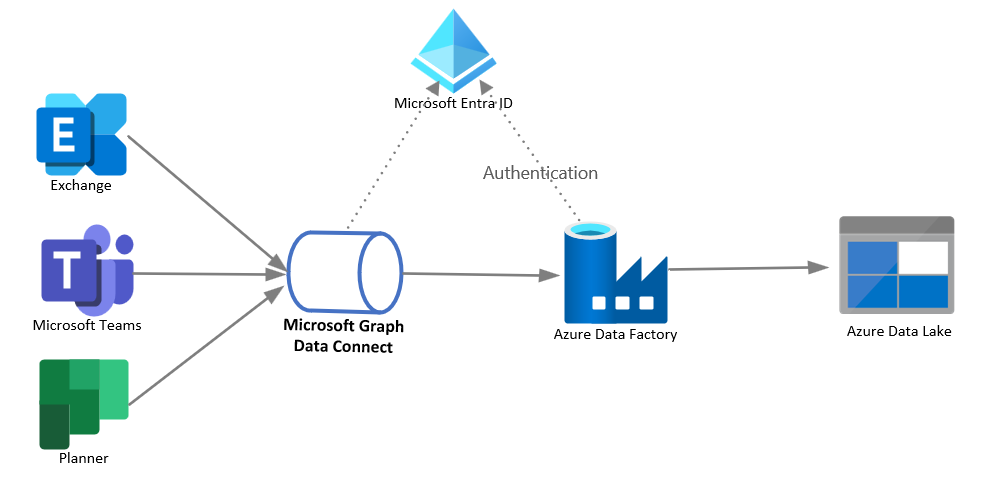
ソリューション コンポーネント
ソリューション アーキテクチャには、次のコンポーネントが含まれています。
- Microsoft Graph Data Connect は、詳細なデータの同意を得て Microsoft 365 データの大規模な抽出を可能にし、暗号化、geo フェンス、監査、ポリシーの適用など、すべての Azure ネイティブ サービス機能をサポートします。
- Azure Data Factory (ADF) を使用すると、ETL (抽出、変換、読み込み) と ELT (抽出、読み込み、変換) を簡単に構築でき、直感的な環境でコードフリーで処理したり、コードを記述したりできます。
- Azure Data Lake を使用すると、さまざまな形式で大量の構造化データと非構造化データを保持できます。
- Microsoft Entra ID。これは Microsoft Graph API の認証を管理するために必要であり、OAuth フローを有効にするために委任されたアクセス許可とアプリケーションのアクセス許可をサポートします。
考慮事項
次の考慮事項は、この統合パターンの使用をサポートします。
可用性: クライアント ADF は、スケジュールまたはアドホックベースで一括でデータを抽出できます。
待機時間: このシナリオのデータ待機時間は、履歴データの抽出や、スケジュールされたタスクとして実行される非同期プロセスによる Microsoft Graph Data Connect ストレージへの最新のデータの配信によって異なる場合があります。 ADF ではバッチ処理とファイル転送が使用されるため、ADF の大規模なデータ抽出のパフォーマンスは、詳細な HTTP API よりも高速です。
スケーラビリティ: このアーキテクチャを使用すると、環境のデータ移動スループットを最大化するパイプラインを開発できます。 これらのパイプラインでは、次のリソースを完全に利用できます。
- ソース データ ストアと宛先データ ストア間のネットワーク帯域幅。
- ソースまたは宛先データ ストアの 1 秒あたりの入出力操作 (IOPS) と帯域幅。
ソリューションの複雑さ: このデータエグレス ソリューションは、カスタム コードを必要とせず、コンポーネントが少なく、データ待機時間に耐えられるため、統合の観点から見ると複雑さが低くなります。