多変量の異常検出
リアルタイム インテリジェンスでの多変量異常検出の一般的な情報については、「Microsoft Fabric での多変量異常検出 - 概要」を参照してください。 このチュートリアルでは、サンプル データを使用して、Python ノートブックの Spark エンジンを使用して多変量異常検出モデルをトレーニングします。 その後、Eventhouse エンジンを使用してトレーニング済みのモデルを新しいデータに適用することで、異常を予測します。 最初のいくつかの手順で環境を設定し、次の手順でモデルをトレーニングし、異常を予測します。
前提条件
- Microsoft Fabric 対応の容量を持つワークスペース
- ワークスペースの管理者、共同作成者、またはメンバーのロール。 このアクセス許可レベルは、環境などの項目を作成するために必要です。
- データベースのあるワークスペース内のイベントハウス。
- GitHub リポジトリからサンプル データをダウンロードする
- GitHub リポジトリからノートブックをダウンロードする
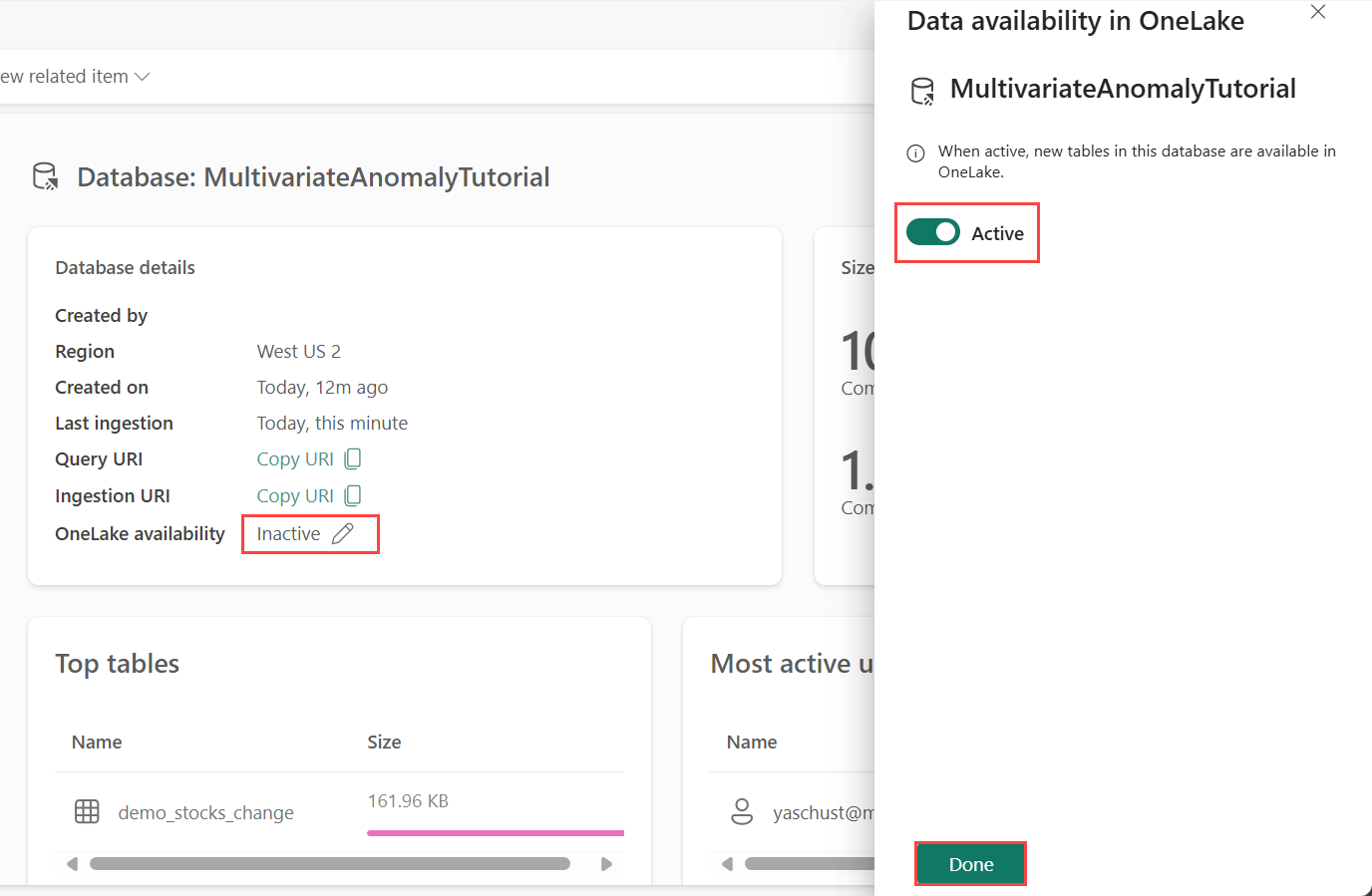
パート 1- OneLake の可用性を有効にする
Eventhouse でデータを取得する前に、OneLake の可用性を 有効にする必要があります。 この手順は、取り込んだデータが OneLake で使用できるようになるため、重要です。 後の手順では、Spark Notebook からこの同じデータにアクセスしてモデルをトレーニングします。
ワークスペースから、前提条件で作成した Eventhouse を選択します。 データの保存先となるデータストアを選択します。
[データベースの詳細] ペインで、OneLake の可用性のボタンを [オン] に切り替えます。
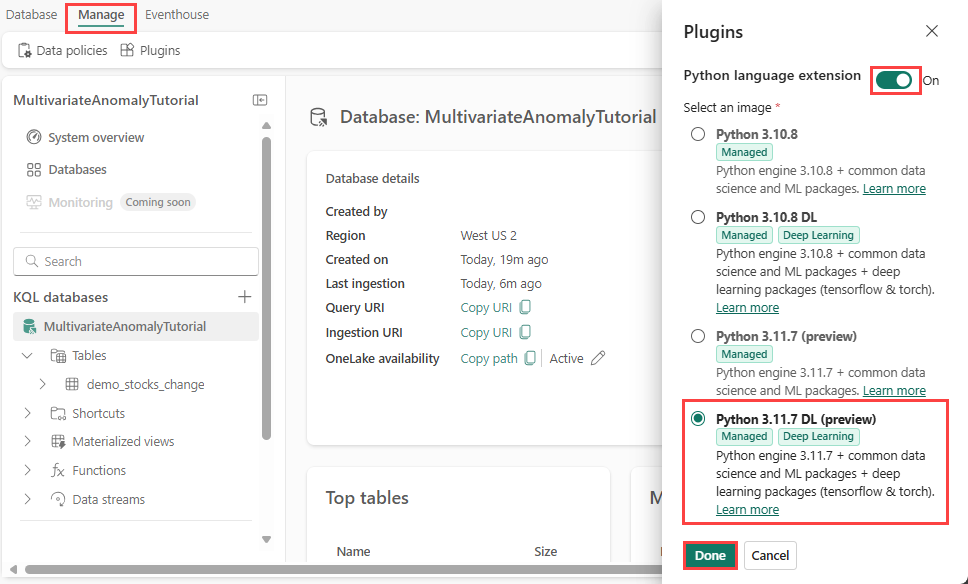
パート 2- KQL Python プラグインを有効にする
この手順では、Eventhouse で Python プラグインを有効にします。 この手順は、KQL クエリセットで異常の予測 Python コードを実行するために必要です。 時系列データの異常検出器 パッケージを含む正しい画像を選択することが重要です。
Eventhouse画面で、リボンから[Eventhouse>Plugins] を選択します。
[プラグイン] ウィンドウで、Python 言語拡張機能を [オン] に切り替えます。
Python 3.11.7 DL (プレビュー)を選択します。
完了 を選択します。

パート 3- Spark 環境を作成する
この手順では、Spark エンジンを使用して多変量異常検出モデルをトレーニングする Python ノートブックを実行する Spark 環境を作成します。 環境を作成する方法について詳しくは、「環境の作成と管理」に関するページを参照してください。
ワークスペースから [+ 新しい項目]、次に [環境] を選びます。
![新しい項目ウィンドウの [環境] タイルのスクリーンショット。](media/multivariate-anomaly-detection/create-environment.png)
環境の名前 MVAD_ENV を入力して、[作成] を選びます。
環境の [ホーム] タブで、[ランタイム>1.2 (Spark 3.4、デルタ 2.4)] を選択します。
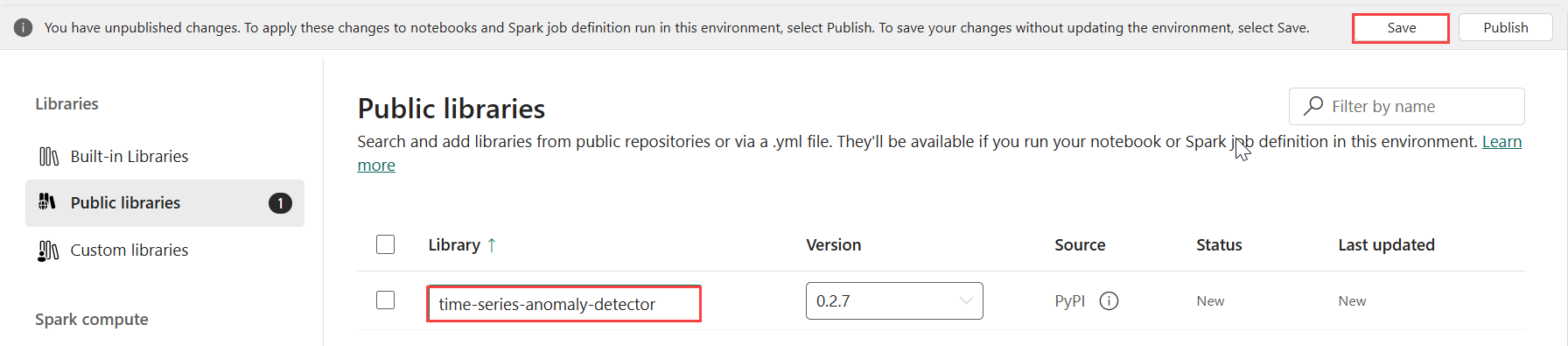
ライブラリで、[パブリック ライブラリ]を選択します。
[PyPI から追加] を選択します。
検索ボックスに、「time-series-anomaly-detector」と入力します。 バージョンには、最新バージョンが自動的に設定されます。 このチュートリアルは、バージョン 0.3.2 を使用して作成されました。
[保存] を選択します。
環境内の [ホーム] タブを選択します。
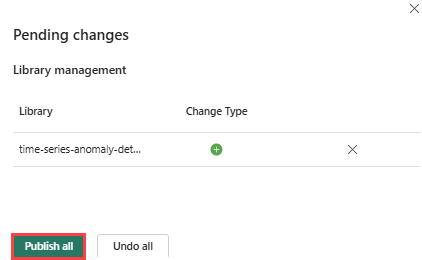
リボンから、[発行] アイコンを選択します。

すべて公開を選択します。 この手順は、完了するまでに数分かかることがあります。
![新しい項目ウィンドウの [環境] タイルのスクリーンショット。](media/multivariate-anomaly-detection/create-environment.png#lightbox)

パート 4- Eventhouse にデータを取り込む
データを格納する KQL データベースにカーソルを合わせます。 その他のメニュー [...]>[データの取得]>[ローカル ファイル] を選択します。
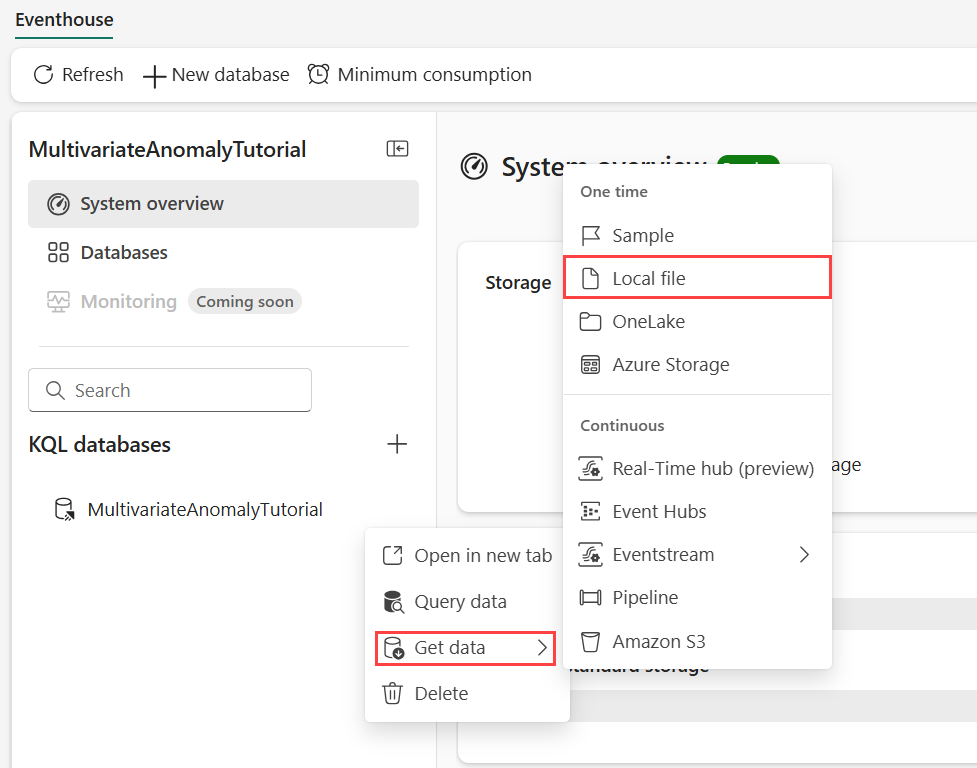
[+ 新しいテーブル] を選択しテーブル名に「demo_stocks_change」と入力します。
[データのアップロード] ダイアログで、[ファイルの参照] を選択し前提条件でダウンロードしたサンプル データ ファイルをアップロードします
[次へ] を選択します。
[データの検査] セクションで、[最初の行が列ヘッダー] を[オン] に切り替えます。
完了 を選択します。
データをアップロードしたら、[閉じる] を選択します。
パート 5- OneLake パスをテーブルにコピーする
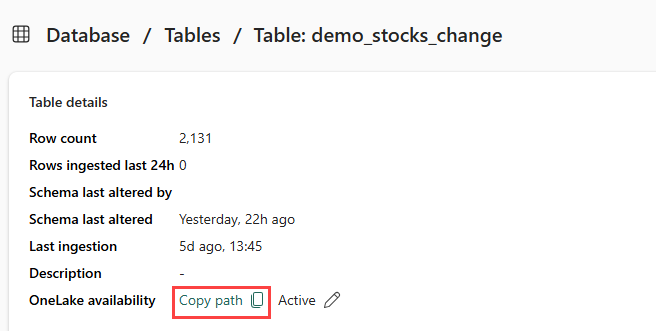
demo_stocks_changeテーブルを選択してください。 [テーブルの詳細 ペインで、OneLake フォルダー 選択して、OneLake パスをクリップボードにコピーします。 このコピーしたテキストをテキスト エディターのどこかに保存して、後の手順で使用します。
パート 6- ノートブックを準備する
ワークスペースを選択します。
[インポート]、[ノートブック] を選択し、[このコンピューターから] を選択します。
[アップロード] を選択し、前提条件でダウンロードしたノートブックを選択します。
ノートブックがアップロードされたら、ワークスペースからノートブックを見つけて開くことができます。
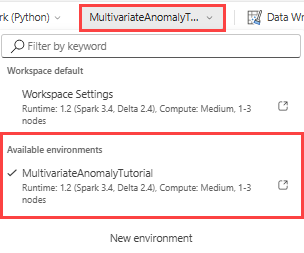
上部のリボンで、[ワークスペースのデフォルト] ドロップダウンを選択し、前の手順で作成した環境を選択します。
パート 7- ノートブックを実行する
標準パッケージをインポートします。
import numpy as np import pandas as pdSpark では OneLake ストレージに安全に接続するために ABFSS URI が必要であるため、次の手順では、OneLake URI を ABFSS URI に変換するためにこの関数を定義します。
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriOneLakeTableURI プレースホルダーを、パート 5 からコピーした OneLake URI に置き換えて、OneLake パスをテーブル にコピーし、demo_stocks_change テーブルを pandas データフレームに読み込みます。
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]次のセルを実行して、トレーニングデータフレームと予測データフレームを準備します。
Note
実際の予測は、「パート 9- Predict-anomalies-in-the-kql-queryset」 で Eventhouse によってデータに対して実行されます。 運用シナリオでは、イベントハウスにデータをストリーミングする場合、新しいストリーミング データに対して予測が行われます。 チュートリアルの目的上、データセットはトレーニングと予測のために日付ごとに 2 つのセクションに分割されています。 これは、履歴データと新しいストリーミング データをシミュレートするためです。
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')セルを実行してモデルをトレーニングし、Fabric MLflow モデル レジストリに保存します。
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )次のセルを実行して、Kusto Python サンドボックスを使用して予測に使用する登録済みのモデル パスを抽出します。
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)後の手順で使用するために、最後のセル出力からモデル URI をコピーします。
パート 8- KQL クエリセットを設定する
一般的な情報については、「KQL クエリセットの作成」を参照してください。
- ワークスペースから [+ 新しい項目]>[KQL クエリセット] を選びます。
- 名前 MultivariateAnomalyDetectionTutorial を入力し、次に [作成] を選びます。
- OneLake データ ハブ ウィンドウで、データを格納した KQL データベースを選択します。
- [接続] を選択します。
パート 9- KQL クエリセットの異常を予測する
次の '.create-or-alter function' クエリを実行して、
predict_fabric_mvad_fl()ストアド関数を定義します。.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }次の予測クエリを実行し、出力モデルの URI を、手順 7 最後にコピーした URI に置き換えます。
このクエリは、トレーニング済みのモデルに基づいて 5 つの株式の多変量異常を検出し、結果を
anomalychartとしてレンダリングします。 異常なポイントは最初のストック (AAPL) にレンダリングされますが、多変量の異常 (つまり、特定の日付の 5 つのストックの共同変更の異常) を表します。let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
結果の異常グラフは次の図のようになります。

リソースをクリーンアップする
チュートリアルが完了したら、作成したリソースを削除して、他のコストが発生しないようにすることができます。 リソースを削除するには、次の手順を実行します。
- ワークスペースのホームページを参照します。
- このチュートリアルで作成した環境を削除します。
- このチュートリアルで作成したノートブックを削除します。
- このチュートリアルで使用した Eventhouse または database を削除します。
- このチュートリアルで作成した KQL クエリセットを削除します。