OneLake からデータを取得する
この記事では、OneLake から新しいテーブルまたは既存のテーブルにデータを取得する方法について説明します。
前提 条件
- Microsoft Fabric に対応した容量 を備えたワークスペース
- レイクハウス
- 編集アクセス許可を持つ KQL データベース
Lakehouse からファイル パスをコピーする
ワークスペースから、使用するデータ ソースを含む Lakehouse 環境を選択します。
目的のファイルの上にカーソルを置き、[その他の (...)] メニューを選択し、[プロパティ] 選択します。
重要
- フォルダー パスはサポートされていません。
- ワイルドカード (*) はサポートされていません。
![Lakehouse ファイルのドロップダウン メニューのスクリーンショット。[プロパティ] というタイトルのオプションが強調表示されています。](media/get-data-onelake/lakehouse-file-menu.png)
[URL] で [クリップボードにコピー] アイコンを選択し、それを後の手順で取得するためにどこかに保存してください。
![Lakehouse ファイルの [プロパティ] ウィンドウのスクリーンショット。ファイルの URL の右側にあるコピー アイコンが強調表示されています。](media/get-data-onelake/lakehouse-file-properties.png)
ワークスペースに戻り、KQL データベースを選択します。
![Lakehouse ファイルのドロップダウン メニューのスクリーンショット。[プロパティ] というタイトルのオプションが強調表示されています。](media/get-data-onelake/lakehouse-file-menu.png#lightbox)
![Lakehouse ファイルの [プロパティ] ウィンドウのスクリーンショット。ファイルの URL の右側にあるコピー アイコンが強調表示されています。](media/get-data-onelake/lakehouse-file-properties.png#lightbox)
ソース
KQL データベースの下部のリボンで、[データの取得] 選択します。
[データの取得] ウィンドウで、[ソース] タブが選択されています。
使用可能な一覧からデータ ソースを選択します。 この例では、OneLakeからデータを取り込みます。
![ソース タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png)
![ソース タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png#lightbox)
構成
ターゲット テーブルを選択します。 新しいテーブルにデータを取り込む場合は、+新しいテーブル を選択し、テーブル名を入力します。
手記
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含む最大 1024 文字を指定できます。 特殊文字はサポートされていません。
[ソースへのリンク] に、「Lakehouse からファイル パスをコピーする」でコピーした Lakehouse のファイル パスを貼り付けます。
手記
各項目の非圧縮サイズが最大1GBの項目を最大で10個追加できます。
![新しいテーブルが入力され、OneLake ファイル パスが追加された [構成] タブのスクリーンショット。](media/get-data-onelake/configure-tab.png)
[次へ] を選択します。
![新しいテーブルが入力され、OneLake ファイル パスが追加された [構成] タブのスクリーンショット。](media/get-data-onelake/configure-tab.png#lightbox)
検査する
[検査] タブが開き、データのプレビューが表示されます。
インジェスト プロセスを完了するには、[完了]を選択します。

必要 に応じて:
- コマンド ビューアー を選択して、入力から生成された自動コマンドを表示およびコピーします。
- スキーマ定義ファイル ドロップダウンを使用して、スキーマが推論されるファイルを変更します。
- ドロップダウンから目的の形式を選択して、自動的に推論されるデータ形式を変更します。 詳細については、「Real-Time Intelligence でサポートされるデータ形式の」を参照してください。
- 列を編集します。
- データ型 に基づいて詳細オプションを調べる。
列の編集
手記
- 表形式 (CSV、TSV、PSV) の場合、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の種類を変更することはできません。 別の形式の列にマップしようとすると、最終的に空の列になる可能性があります。
テーブルで行うことができる変更は、次のパラメーターによって異なります。
- テーブル タイプは新規または既存です
- マッピングの種類が新規かまたは既存か
| テーブルの種類 | マッピングの種類 | 可能な変更 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換 、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 列の追加 (データ型の変更、名前の変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | 何一つ |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、単純な取り込み時間変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列 作成または更新します。
マッピング変換は、データ型が int または long のソースを使用して、文字列型または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- Unixマイクロ秒から日付時間を取得
- DateTimeFromUnixNanoseconds
データ型に基づく詳細オプション
表形式 (CSV、TSV、PSV):
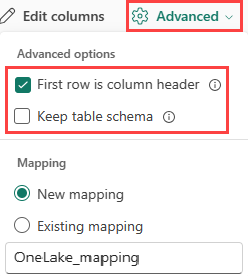
表形式を "既存のテーブル" に取り込もうとしている場合、[詳細]、[テーブル スキーマを保持する] の順に選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれているわけではありません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは変わりません。 このオプションをオフにすると、データ構造に関係なく、受信データに対して新しい列が作成されます。
最初の行を列名として使用するには、[詳細]>[最初の行を列ヘッダーにする] を選択します。
JSON:
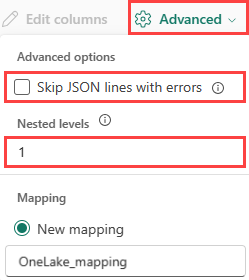
JSON データの列分割を決定するには、高度な>入れ子になったレベルを 1 から 100 まで選択します。
[詳細]>[エラーのある JSON 行をスキップする] を選択すると、データは JSON 形式で取り込まれます。 このチェック ボックスをオフのままにすると、データは multijson 形式で取り込まれます。
概要
データ準備 ウィンドウでは、データ インジェストが正常に完了すると、3 つのステップすべてが緑色のチェック マークでマークされます。 カードを選択してクエリを実行したり、取り込まれたデータを削除したり、インジェストの概要のダッシュボードを表示したりできます。

関連コンテンツ
- KQL クエリセット 内のデータのクエリ
- Power BI レポート でデータを視覚化する