Azure Data Factory からの移行の計画
Microsoft Fabric は、Microsoft の市場をリードするすべての分析製品を 1 つのユーザー エクスペリエンスにまとめる、Microsoft のデータ分析 SaaS 製品です。 Fabric Data Factory では、Azure Data Factory (ADF) と同様の機能を使用して、ワークフロー オーケストレーション、データ移動、データ レプリケーション、データ変換を大規模に提供します。 Fabric Data Factory に最新化する既存の ADF 投資がある場合、このドキュメントは、移行に関する考慮事項、戦略、およびアプローチを理解するのに役立ちます。
Azure PaaS ETL/DI サービス ADF & Synapse パイプラインとデータ フローからの移行には、いくつかの重要な利点があります。
- 電子メールや Teams アクティビティを含む新しい統合パイプライン機能により、パイプラインの実行中にメッセージを簡単にルーティングできます。
- 組み込みの継続的インテグレーションと配信 (CI/CD) 機能 (デプロイ パイプライン) では、Git リポジトリとの外部統合は必要ありません。
- OneLake データ レイクとのワークスペース統合により、一括管理画面で簡単に分析を管理できます。
- 完全に統合されたパイプライン アクティビティを使用して、Fabric でセマンティック データ モデルを簡単に更新できます。
Microsoft Fabric は、セルフサービスと IT で管理されるエンタープライズ データの両方に対応する統合プラットフォームです。 データ量が急激に増加し、複雑さが増す中、Fabric のお客様は、最大の組織のすべてのユーザーがスケーリング、セキュリティで保護され、管理しやすく、アクセスできるエンタープライズ ソリューションを求めています。
近年、Microsoft は、Premium にスケーラブルなクラウド機能を提供するために多大な労力を費やしました。 そのため、Fabric の Data Factory は、数十年にわたって構築されたデータ統合開発者とデータ統合ソリューションの大規模なエコシステムをすぐに支援し、前の世代で利用できる同等の機能をはるかに超える機能を適用します。
当然ながら、お客様は、Fabric 内でデータ統合ソリューションをホストすることで統合する機会があるかどうかを確認しています。 一般的な質問は次のとおりです。
- Fabric パイプラインでは、依存しているすべての機能が動作しますか?
- Fabric パイプラインでのみ使用できる機能は何ですか?
- 既存のパイプラインを Fabric パイプラインに移行する方法
- エンタープライズ データ インジェストに関する Microsoft のロードマップは何ですか?
プラットフォームの違い
ADF インスタンス全体を移行する場合、ADF と Fabric の Data Factory の間には多くの重要な違いがあります。これは、Fabric への移行時に重要になります。 このセクションでは、これらの重要な違いをいくつか説明します。
Azure Data Factory と Fabric Data Factory の機能の違いの機能マッピングの詳細については、「Fabric と Azure Data Factory での Data Factory の比較を参照してください。
統合ランタイム
ADF では、統合ランタイム (IR) は、ADF がデータ処理を完了するために使用するコンピューティングを表す構成オブジェクトです。 これらの構成プロパティには、クラウド コンピューティングとデータ フロー Spark コンピューティング サイズの Azure リージョンが含まれます。 その他の IR の種類には、オンプレミスデータ接続用のセルフホステッド IR (SHIR)、SQL Server Integration Services パッケージを実行するための SSIS IR、Vnet 対応クラウド IR などがあります。
![Azure Data Factory の [統合ランタイム] タブを示すスクリーンショット。](media/migrate-planning-azure-data-factory/integration-runtimes.png)
Microsoft Fabric はサービスとしてのソフトウェア (SaaS) 製品ですが、ADF はサービスとしてのプラットフォーム (PaaS) 製品です。 この違いは、統合ランタイムの観点から言うと、Fabric のパイプラインやデータフローを使用するように何も構成する必要がないということです。既定では、Fabric 容量が配置されているリージョンでクラウドベースのコンピューティングを使用するためです。 SSIS ID は Fabric に存在せず、オンプレミスのデータ接続では、オンプレミスデータ ゲートウェイ (OPDG) と呼ばれるファブリック固有のコンポーネントを使用します。 また、セキュリティで保護されたネットワークへの仮想ネットワーク ベースの接続では、Fabric の仮想ネットワーク データ ゲートウェイを使用します。
ADF から Fabric に移行する場合、パブリック ネットワーク Azure (クラウド) の ID を移行する必要はありません。 SHIR を OPDG として再作成し、仮想ネットワークが有効な Azure IR を仮想ネットワーク データ ゲートウェイ として再作成する必要があります。
![[ファブリック管理] ページの [接続とゲートウェイの管理] オプションを示すスクリーンショット。](media/migrate-planning-azure-data-factory/manage-gateways.png)
パイプライン
パイプラインは ADF の基本的なコンポーネントであり、データ移動、データ変換、およびプロセス オーケストレーションのために ADF プロセスのプライマリ ワークフローとオーケストレーションに使用されます。 Fabric Data Factory のパイプラインは ADF とほぼ同じですが、Power BI に基づく SaaS モデルに適合する追加のコンポーネントを備えています。 この類似性には、電子メール、Teams、セマンティック モデルの更新のネイティブ アクティビティが含まれます。
Fabric Data Factory のパイプラインの JSON 定義は、2 つの製品間のアプリケーション モデルの違いにより、ADF とは若干異なります。 この違いのため、パイプライン JSON のコピー/貼り付け、パイプラインのインポート/エクスポート、または ADF Git リポジトリの参照はできません。
ADF パイプラインを Fabric パイプラインとして再構築する場合は、基本的に ADF で使用したワークフロー モデルとスキルと同じものを使用します。 主な考慮事項は、Fabric に存在しない ADF の概念であるリンクされたサービスとデータセットに関係しています。
リンクされたサービス
ADF では、リンクされたサービスは、データ移動、データ変換、およびデータ処理アクティビティのためにデータ ストアに接続するために必要な接続プロパティを定義します。 Fabric では、コピーやデータフローなどのアクティビティのプロパティである接続として、これらの定義を再作成する必要があります。
データセット
データセットは、ADF 内のデータの形状、場所、および内容を定義しますが、Fabric にはエンティティとして存在しません。 Fabric Data Factory パイプラインでデータ型、列、フォルダー、テーブルなどのデータ プロパティを定義するには、パイプライン アクティビティ内と、リンクされたサービス セクションで前に参照した Connection オブジェクト内で、これらの特性をインラインで定義します。
データフロー
Data Factory for Fabric では、データフロー という用語はコードフリーのデータ変換アクティビティを指しますが、ADF では、同じ機能を データ フローと呼びます。 Fabric Data Factory データフローには、ADF Power Query アクティビティで使用される Power Query 上に構築されたユーザー インターフェイスがあります。 Fabric でデータフローを実行するために使用されるコンピューティングは、新しい Fabric Data Warehouse コンピューティング エンジンを使用して大規模なデータ変換のためにスケールアウトできるネイティブ実行エンジンです。
ADF では、データ フローは Synapse Spark インフラストラクチャ上に構築され、データ フロー スクリプトと呼ばれる基になるドメイン固有言語 (DSL) を使用する構築ユーザー インターフェイスを使用して定義されます。 この定義言語は、M と呼ばれる定義言語を使用して動作を定義する Fabric の Power Query ベースのデータフローとは大きく異なります。 ユーザー インターフェイス、言語、および実行エンジンの違いにより、Fabric データフロー と ADF データ フロー 互換性がないため、ソリューションを Fabric にアップグレードするときに、ファブリック データフロー、ADF データ フローを再作成する必要があります。
トリガー
壁時計のタイム スケジュール、タンブリング ウィンドウ タイム スライス、ファイル ベースのイベント、またはカスタム イベントに基づいてパイプラインを実行するように ADF に通知します。 これらの機能は Fabric でも似ていますが、基になる実装は異なります。
Fabric では、トリガー パイプラインの概念としてのみ存在します。 Fabric でパイプライン トリガーが使用する大規模なフレームワークは、Data Activatorと呼ばれます。これは、Fabric のリアルタイム インテリジェンス機能のイベントおよびアラート サブシステムです。
![Azure Data Factory の [トリガー] ページを示すスクリーンショット。](media/migrate-planning-azure-data-factory/azure-data-factory-triggers.png)
Fabric Data Activator には、ファイル イベントおよびカスタム イベント トリガーの作成に使用できる "アラート" があります。 スケジュール トリガーは、Fabricにおいて「スケジュール」として知られる、独立したエンティティです。 これらのスケジュールは Fabric のプラットフォーム レベルであり、パイプラインに固有ではありません。 これらは、Fabric では "トリガー" とは呼ばれません。
ADF から Fabric にトリガーを移行するには、ファブリック パイプラインのプロパティであるスケジュールとしてスケジュール トリガーを再構築することを検討してください。 また、他のすべての種類のトリガーについては、Fabric パイプライン内の [トリガー] ボタンを使用するか、Fabric でデータ アクティベーターをネイティブに使用します。
![Fabric パイプライン エディターの Data Factory の [トリガーの追加] ボタンを示すスクリーンショット。](media/migrate-planning-azure-data-factory/add-trigger.png)
デバッグ
Fabric でのパイプラインのデバッグは、ADF よりも簡単です。 このシンプルさは、Fabric Data Factory パイプラインには、ADF パイプラインとデータ フローで見つかるデバッグ モード という別の概念がないためです。 代わりに、パイプラインをビルドすると、常に対話型モードになります。 パイプラインをテストしてデバッグするには、開発サイクルの準備ができたら、パイプライン エディターのツール バーから再生ボタンを選択するだけで済みます。 Fabricパイプラインでは、ステップワイズパターンで対話的にデバッグが行われるまで、デバッグは含まれません。 代わりに、Fabric では、アクティビティの状態を利用し、テストするアクティビティのみをアクティブとして設定し、他のすべてのアクティビティを非アクティブに設定して、同じテストおよびデバッグ パターンを実現します。 Fabric でこのデバッグ エクスペリエンスを実現する方法については、次のビデオを参照してください。
変更データ キャプチャ
ADF の Change Data Capture (CDC) は、データ ストアのソース側 CDC 機能を適用することで、データをすばやく増分的に移動できるようにするプレビュー機能です。 CDC アーティファクトを Fabric Data Factory に移行するには、これらのアーティファクトを Fabric ワークスペース内で コピー ジョブ アイテムとして再作成します。 この機能は、ADF CDC と同様に、パイプラインを必要とせずに使いやすい UI で増分データ移動の同様の機能を提供します。 詳細については、Fabric の Data Factory の コピー ジョブ を参照してください。
Azure Synapse Link
ADF では使用できませんが、Synapse パイプライン ユーザーは、ターンキー アプローチで SQL データベースからデータ レイクにデータをレプリケートするために Azure Synapse Link を頻繁に利用します。 Fabric では、Azure Synapse Link 成果物をワークスペース内のミラーリング項目として再作成します。 詳細については、Fabric データベース ミラーリングに関するページを参照してください。
SQL Server Integration Services (SSIS)
SSIS は、Microsoft が SQL Server に付属しているオンプレミスのデータ統合および ETL ツールです。 ADF では、ADF SSIS IR を使用して SSIS パッケージをクラウドにリフト アンド シフトできます。 Fabric では、IR の概念がないため、現在この機能を使用することはできません。 ただし、近日中に製品に提供したいと考えている Fabric から SSIS パッケージの実行をネイティブに有効にすることに取り組んでいます。 それまでの間、Fabric Data Factory を使用してクラウドで SSIS パッケージを実行する最善の方法は、ADF ファクトリで SSIS IR を開始してから、ADF パイプラインを呼び出して SSIS パッケージを呼び出す方法です。 次のセクションで説明する呼び出されたパイプライン アクティビティを使用して、ファブリック パイプラインから ADF パイプラインをリモート呼び出すことができます。
Invoke パイプライン アクティビティ
ADF パイプラインで使用される一般的なアクティビティは、ファクトリ内の別のパイプラインを呼び出す パイプラインの実行アクティビティ です。 Fabric では、呼び出しパイプライン アクティビティとして、このアクティビティを強化しました。 パイプラインの呼び出しアクティビティの ドキュメントを参照してください。
このアクティビティは、マッピング データ フローや SSIS などの ADF 固有の機能を使用する多くの ADF パイプラインがある移行シナリオに役立ちます。 これらのパイプラインをそのまま ADF または Synapse パイプラインに保持し、そのパイプラインを新しい Fabric Data Factory パイプラインからインラインで呼び出すには、Invoke パイプライン アクティビティを使用し、リモート ファクトリ パイプラインをポイントします。
移行シナリオの例
次のシナリオは、ADF から Fabric Data Factory に移行するときに発生する可能性がある一般的な移行シナリオです。
シナリオ 1: ADF パイプラインとデータ フロー
ファクトリ移行の主なユース ケースは、ADF ファクトリ PaaS モデルから新しい Fabric SaaS モデルへの ETL 環境の最新化に基づいています。 移行する主要なファクトリ項目は、パイプラインとデータ フローです。 これら 2 つの最上位項目 (リンクされたサービス、統合ランタイム、データセット、トリガー) の外部で移行を計画する必要がある基本的なファクトリ要素がいくつかあります。
- リンクされたサービスは、パイプライン アクティビティの接続として Fabric で再作成する必要があります。
- データセットは Factory に存在しません。 データセットのプロパティは、コピーやルックアップなどのパイプライン アクティビティ内のプロパティとして表され、Connections には他のデータセット プロパティが含まれます。
- 統合ランタイムは Fabric に存在しません。 ただし、セルフホステッド IR は、Fabric のオンプレミス データ ゲートウェイ (OPDG) と、Fabric のマネージド仮想ネットワーク ゲートウェイとして Azure 仮想ネットワーク IR を使用して再作成できます。
- これらの ADF パイプライン アクティビティは、Fabric Data Factory には含まれません。
- Data Lake Analytics (U-SQL) - この機能は非推奨の Azure サービスです。
- 検証アクティビティ - ADF の検証アクティビティは、メタデータの取得アクティビティ、パイプライン ループ、If アクティビティを使用して、Fabric パイプラインで簡単に再構築できるヘルパー アクティビティです。
- Power Query - Fabric では、すべてのデータフローは Power Query UI を使用して構築されるため、ADF Power Query アクティビティから M コードをコピーして貼り付け、Fabric でデータフローとしてビルドできます。
- Fabric Data Factory に見つからない ADF パイプライン機能のいずれかを使用している場合は、Fabric の Invoke パイプライン アクティビティを使用して、ADF 内の既存のパイプラインを呼び出します。
- 次の ADF パイプライン アクティビティは、単一目的のアクティビティに結合されます。
- Azure Databricks アクティビティ (Notebook、Jar、Python)
- Azure HDInsight (Hive、Pig、MapReduce、Spark、ストリーミング)
次の図は、ファイル パスと圧縮設定を含む ADF データセット構成ページを示しています。
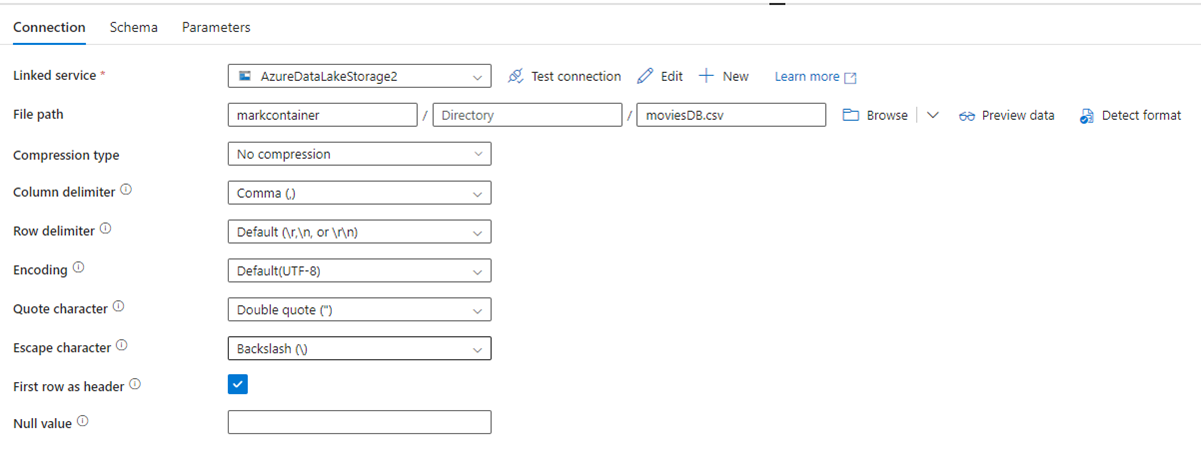
次の図は、Fabric の Data Factory のコピー アクティビティの構成を示しています。このアクティビティでは圧縮とファイル パスがインラインで行われます。
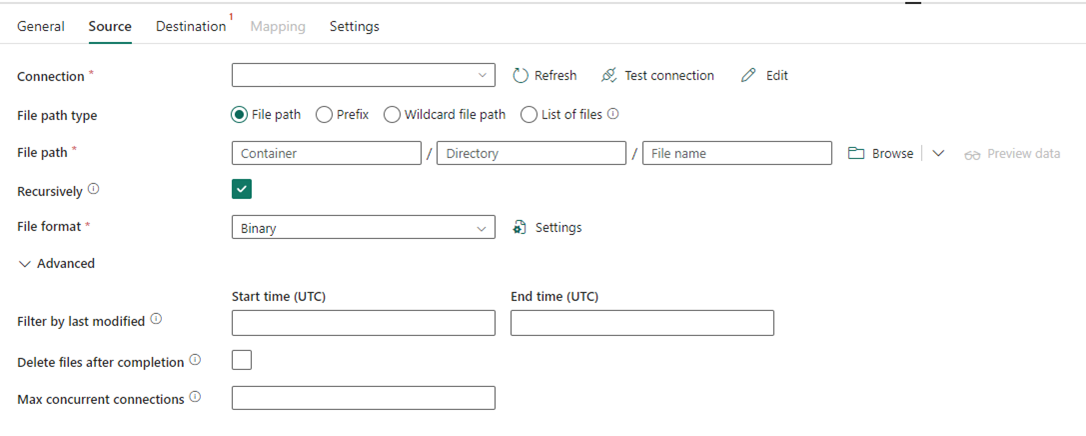
シナリオ #2: CDC、SSIS、およびエアフローを含む ADF
ADF の CDC & エアフローはプレビュー機能ですが、ADF の SSIS は長年にわたって一般公開されている機能です。 これらの機能はそれぞれ異なるデータ統合ニーズに対応しますが、ADF から Fabric に移行する場合は特別な注意が必要です。 Change Data Capture (CDC) は最上位レベルの ADF 概念ですが、Fabric では、この機能は コピー ジョブと見なされます。
エアフローは、ADF クラウド管理の Apache エアフロー機能であり、Fabric Data Factory でも使用できます。 同じエアフロー ソース リポジトリを使用することも、DAG を取得して、変更を必要とせず、コードを Fabric エアフロー オファリングにコピー/貼り付けることもできます。
シナリオ 3: Git 対応 Data Factory から Fabric への移行
ADF または Synapse ファクトリとワークスペースが ADO または GitHub の独自の外部 Git プロバイダーに接続されているのは、必須ではありませんが一般的です。 このシナリオでは、ファクトリとワークスペース項目を Fabric ワークスペースに移行し、Fabric ワークスペースに Git 統合を設定する必要があります。
Fabric には、ワークスペース レベルで CI/CD を有効にする主な 2 つの方法が用意されています。Git 統合では、独自の Git リポジトリを ADO に取り込み、Fabric と組み込みのデプロイ パイプラインから接続します。このパイプラインでは、独自の Git を使用しなくても、コードを上位の環境に昇格できます。
どちらの場合も、ADF の既存の Git リポジトリは Fabric では機能しません。 代わりに、新しいリポジトリをポイントするか、Fabric で新しい デプロイ パイプライン を開始し、Fabric でパイプライン成果物を再構築する必要があります。
既存の ADF インスタンスを Fabric ワークスペースに直接マウントする
以前は、既存の ADF パイプライン投資を維持し、Fabric からインラインで呼び出すメカニズムとして、Fabric Data Factory の呼び出しパイプライン アクティビティを使用する方法について説明しました。 Fabric 内では、同様の概念をさらに 1 歩進め、Fabric ワークスペース内のファクトリ全体をネイティブの Fabric アイテムとしてマウントできます。
使用シナリオのマウントの詳細については、「コンテンツのコラボレーションと配信のシナリオを参照してください。
Fabric ワークスペース内に Azure Data Factory をマウントすると、考慮すべき多くの利点があります。 Fabric を初めて使用していて、同じウィンドウ内にファクトリを並べておきたい場合は、Fabric に取り付けて、Fabric 内の両方を管理できます。 完全な ADF UI は、マウントされたファクトリから使用できるようになりました。この UI では、Fabric ワークスペース内から ADF ファクトリ項目を完全に監視、管理、編集できます。 この機能により、これらの項目をネイティブ Fabric 成果物として Fabric に移行する作業を簡単に開始できます。 この機能は主に使いやすさを目的としており、Fabric ワークスペース内の ADF ファクトリを簡単に確認できます。 ただし、パイプライン、アクティビティ、統合ランタイムなどの実際の実行は、Azure リソース内で引き続き発生します。
関連コンテンツ
Fabric の ADF から Data Factory への移行に関する考慮事項