クイック スタート: データフローとデータ パイプラインを使用してデータを移動および変換する
このチュートリアルでは、データフローとデータ パイプラインエクスペリエンスによって、強力で包括的な Data Factory ソリューションを作成する方法について説明します。
前提 条件
開始するには、次の前提条件が必要です。
- アクティブなサブスクリプションを持つテナント アカウント。 無料アカウントを作成します。
- Microsoft Fabric が有効になっているワークスペースがあることを確認します。既定のマイ ワークスペースではないワークスペース を作成します。
- テーブルデータを含むAzure SQL データベース。
- BLOB ストレージ アカウント。
パイプラインと比較したデータフロー
Dataflows Gen2 を使用すると、ローコード インターフェイスと 300 以上のデータと AI ベースの変換を使用して、他のどのツールよりも柔軟性の高いデータのクリーンアップ、準備、変換を簡単に行うことができます。 Data Pipelines を使用すると、すぐに使用できる豊富なデータ オーケストレーション機能を使用して、企業のニーズを満たす柔軟なデータ ワークフローを作成できます。 パイプラインでは、タスクを実行するアクティビティの論理グループを作成できます。これには、データフローを呼び出してデータをクリーンアップして準備することが含まれる場合があります。 2 つの間にはいくつかの機能が重複していますが、特定のシナリオに使用する機能の選択は、パイプラインの豊富さを必要とするか、データフローのよりシンプルで制限された機能を使用できるかによって異なります。 詳細については、Fabric 意思決定ガイドの を参照してください。
データフローを使用してデータを変換する
データフローを設定するには、次の手順に従います。
手順 1: データフローを作成する
Fabric 対応ワークスペースを選択し、[新しい]を選択します。 次に、[データフロー Gen2] を選択します。
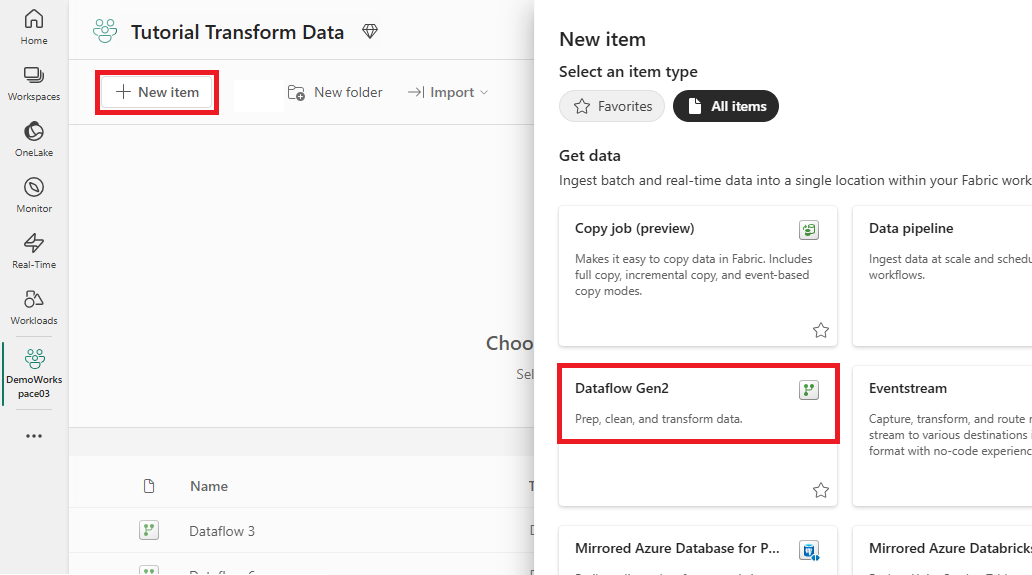
データフロー エディター ウィンドウが表示されます。 [SQL Server からインポート] カードを選択します。
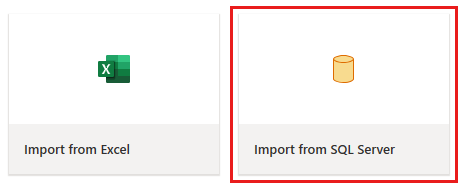


手順 2: データを取得する
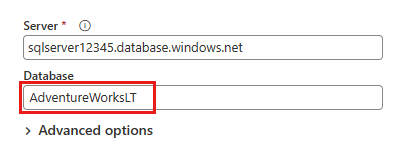
次に表示される [データ ソースへの接続] ダイアログで、Azure SQL データベースに接続するための詳細を入力し、[次へ] 選択します。 この例では、前提条件で Azure SQL データベースを設定するときに構成された AdventureWorksLT サンプル データベースを使用します。
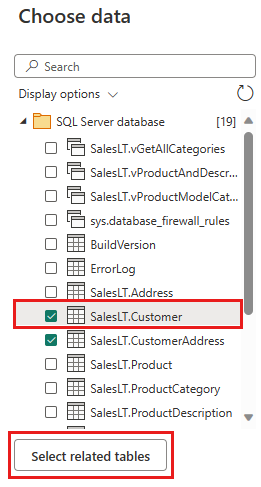
変換するデータを選択し、作成を選択します。 このクイックスタートでは、AdventureWorksLT Azure SQL DB 用に提供されたサンプル データから SalesLT.Customer を選択し、[関連テーブルの選択] ボタンを して、他の 2 つの関連テーブルを自動的に含めます。


手順 3: データを変換する
選択されていない場合は、ページ下部のステータス バーにある [ダイアグラム ビュー ] ボタンを選択するか、Power Query エディターの上部にある [表示] メニューの下にある [ダイアグラム ビュー 選択します。 これらのオプションのいずれかを使用して、ダイアグラム ビューを切り替えることができます。
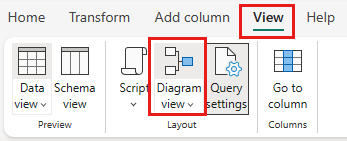
[SalesLT Customer] クエリを右クリックするか、クエリの右側にある縦方向の省略記号を選択してから、[クエリのマージ] を選びます。
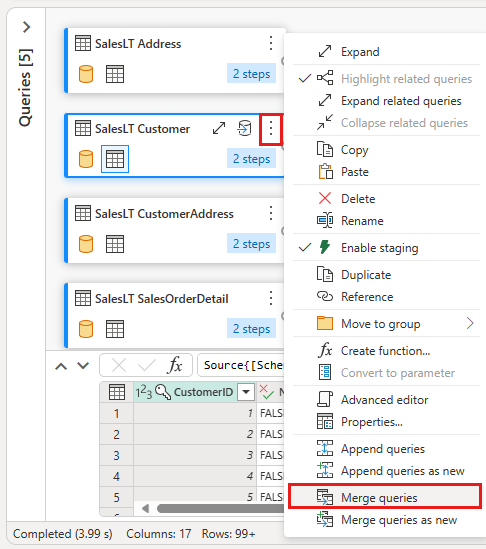
マージを構成するには、右側のテーブルとして SalesLTOrderHeader テーブルを選択し、各テーブルの CustomerID 列を結合列として指定し、結合の種類として 左外部 を選択します。 次 [OK] を選択してマージ クエリを追加します。
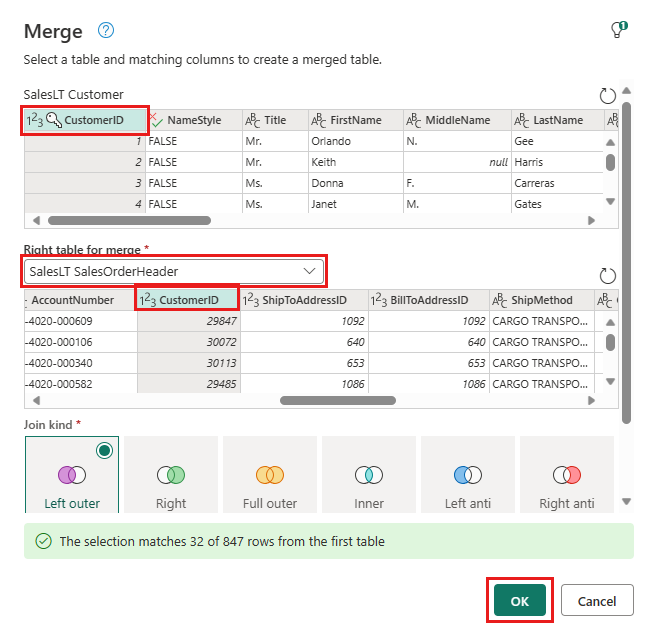
作成した新しいマージ クエリから、[データ変換先 追加] ボタンを選択します。これは、上に矢印が付いたデータベース シンボルのように見えます。 次に、送信先の種類として Azure SQL Database を選択します。
![新しく作成されたマージ クエリの [データ変換先の追加] ボタンが強調表示されているスクリーンショット。](media/transform-data/select-data-destination-inline.png)
マージ クエリを発行する Azure SQL データベース接続の詳細を指定します。 この例では、宛先のデータ ソースとして使用した AdventureWorksLT データベースも使用できます。
![[データ送信先に接続] ダイアログを示すスクリーンショット。サンプル値が設定されています。](media/transform-data/configure-data-destination.png)
データを格納するデータベースを選択し、テーブル名を指定してから、[次へ] 選択します。
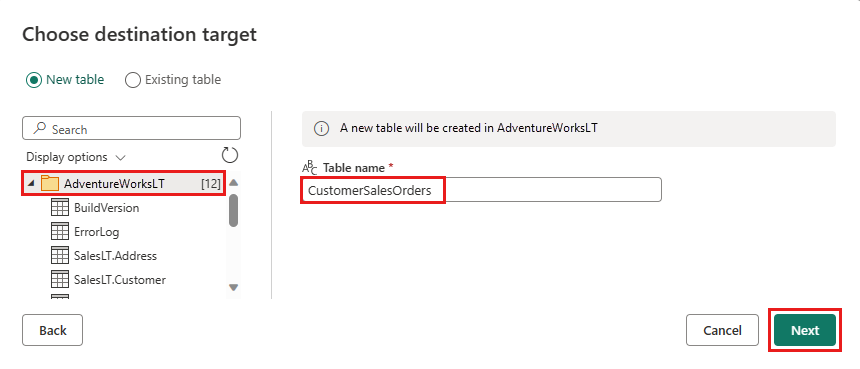
[保存先の設定 を選択]ダイアログボックスで既定の設定をそのまま使用し、ここで変更を加えずに 設定 保存を選択するだけです。
![[宛先設定の選択] ダイアログを示すスクリーンショット。](media/transform-data/choose-destination-settings.png)
データフロー エディターのページで [公開] を選択して、データフローを公開します。
![データフロー gen2 エディターの [発行] ボタンが強調表示されているスクリーンショット。](media/transform-data/publish-dataflow-gen2-inline.png)

![新しく作成されたマージ クエリの [データ変換先の追加] ボタンが強調表示されているスクリーンショット。](media/transform-data/select-data-destination.png#lightbox)
![データフロー gen2 エディターの [発行] ボタンが強調表示されているスクリーンショット。](media/transform-data/publish-dataflow-gen2.png#lightbox)
データ パイプラインを使用してデータを移動する
Dataflow Gen2 を作成したら、パイプラインで操作できます。 この例では、データフローから生成されたデータを Azure Blob Storage アカウントのテキスト形式にコピーします。
手順 1: 新しいデータ パイプラインを作成する
ワークスペースから [新しい] を選択し、次に [データ パイプライン] を選択します。
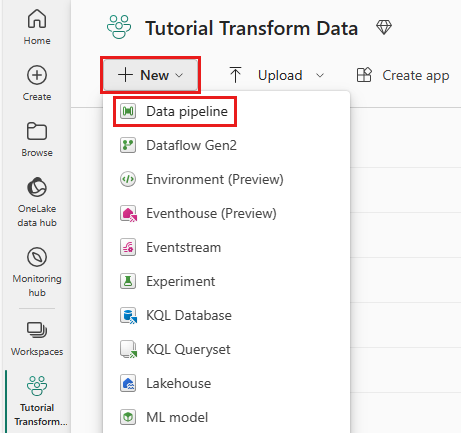
パイプラインに名前を付けて、作成を選択します。
手順 2: データフローを構成する
[アクティビティ] タブで Dataflow を選択して、新しいデータフロー アクティビティをデータ パイプラインに追加します。

パイプライン キャンバスでデータフローを選択し、[設定] タブを選択します。ドロップダウン リストから、前に作成したデータフローを選択します。
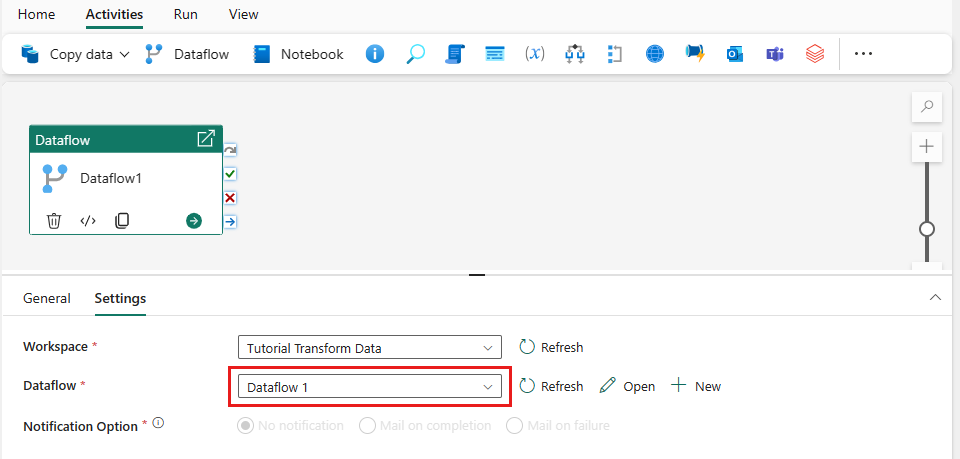
[保存] を選択してから、[実行] を選んでデータフローを実行し、前の手順で設計したマージされたクエリ テーブルを最初に設定します。
![[実行] を選択する場所を示すスクリーンショット。](media/transform-data/save-run-pipeline-dataflow-only.png)
手順 3: コピー アシスタントを使用してコピー アクティビティを追加する
キャンバスで データのコピー を選択し、コピー アシスタント ツールを開いて作業を開始します。 または、リボンの [アクティビティ] タブの [データのコピー] ドロップダウン リストから [コピー アシスタント を使用] を選択します。
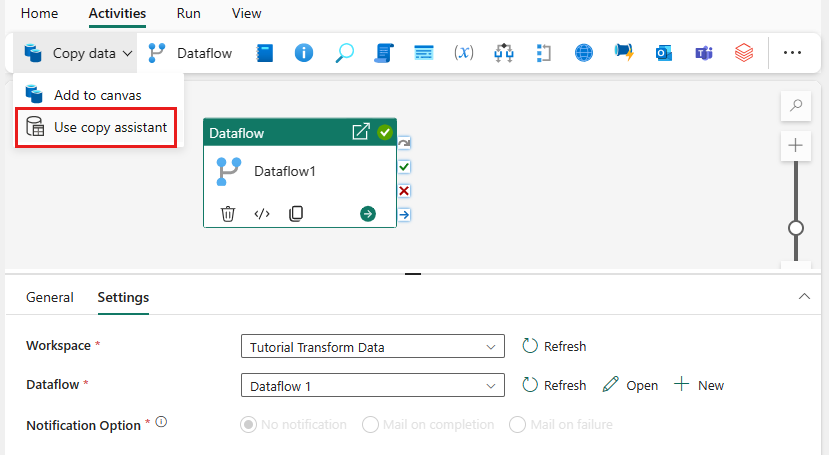
データソースの種類を選択します。 このチュートリアルでは、データフローを作成したときに使用した Azure SQL Database を使用して、新しいマージ クエリを生成します。 サンプル データ オファリングの下にスクロールし、[Azure] タブを選択してから、[Azure SQL Database] を選びます。 次 次 を選択して続行します。
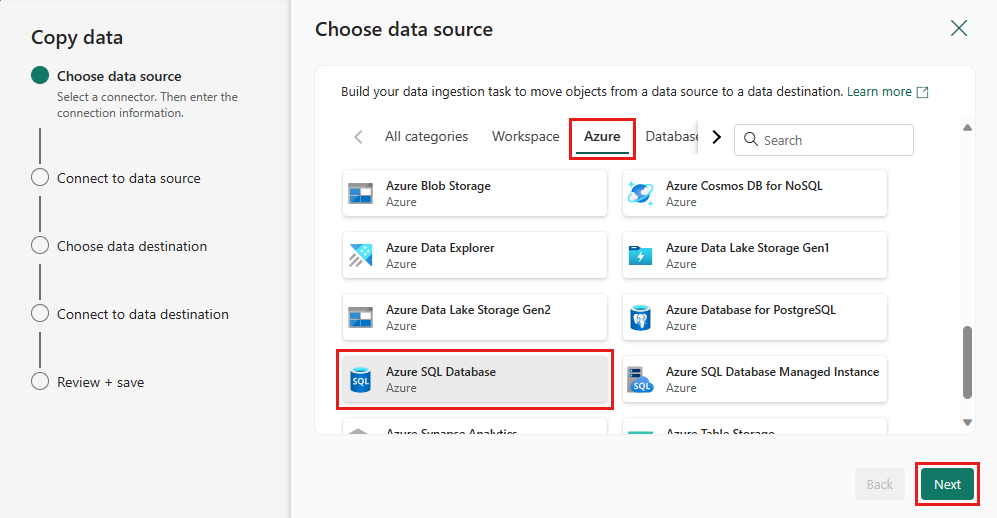
[新しい接続の作成]を選択して、データソースへの接続を作成します。 パネルに必要な接続情報を入力し、データベースの AdventureWorksLT を入力します。ここで、データフローでマージ クエリを生成しました。 次 を選択します。
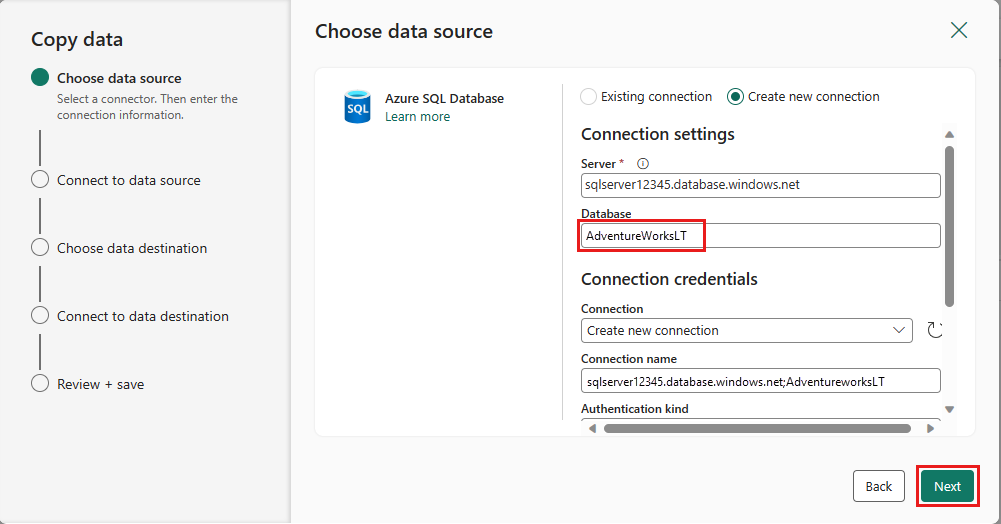
前のデータフロー ステップで生成したテーブルを選択し、次 選択します。
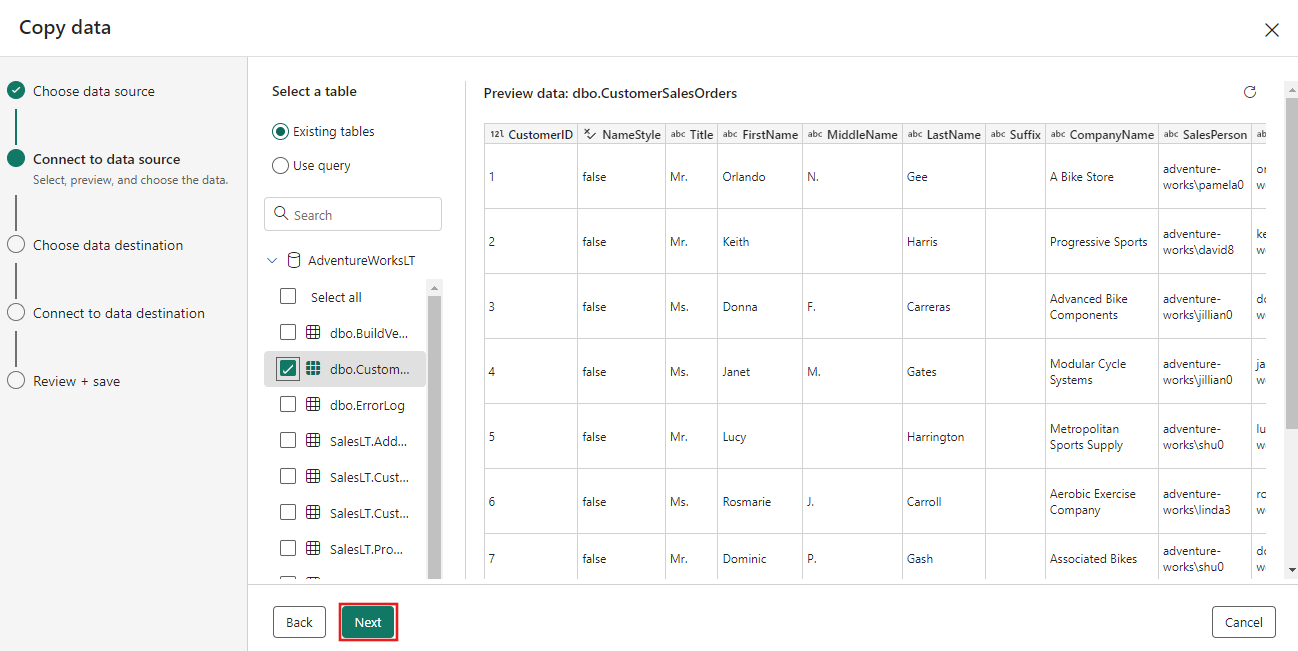
宛先として、「Azure Blob Storage 」を選択して、「次へ 」を選択します。
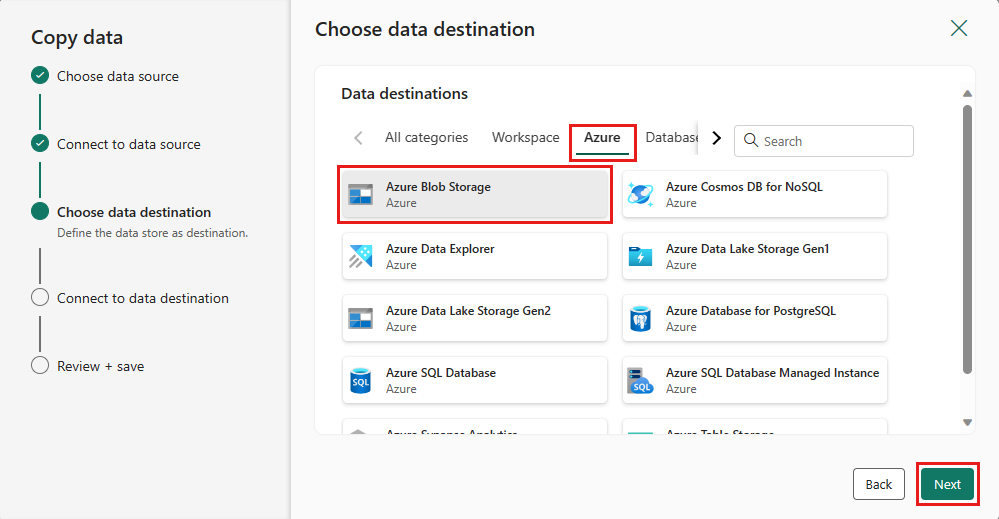
[新しい接続の作成] を選んで、宛先への接続を作成します。 接続の詳細を入力し、[次へ] 選択します。
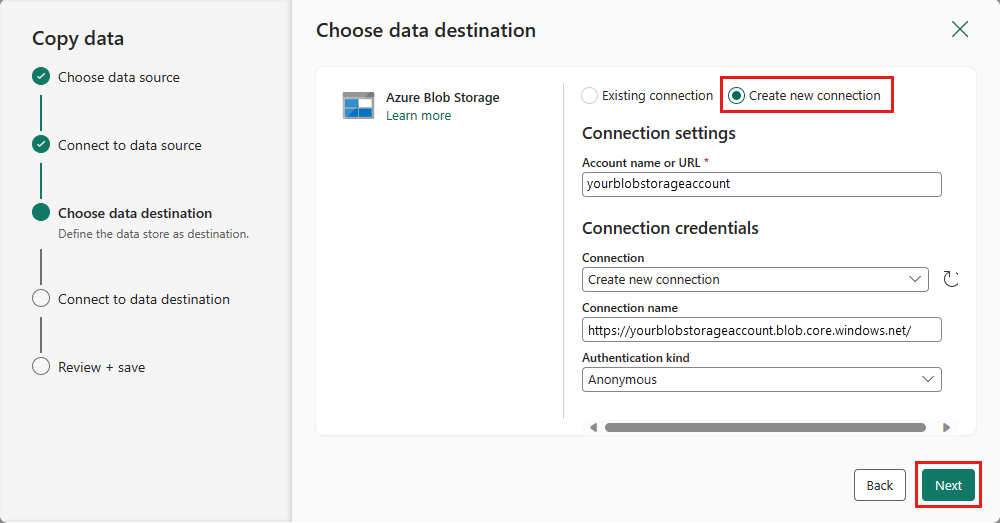
フォルダーパスの を選択し、ファイル名を指定し、[次へ] を選択します。
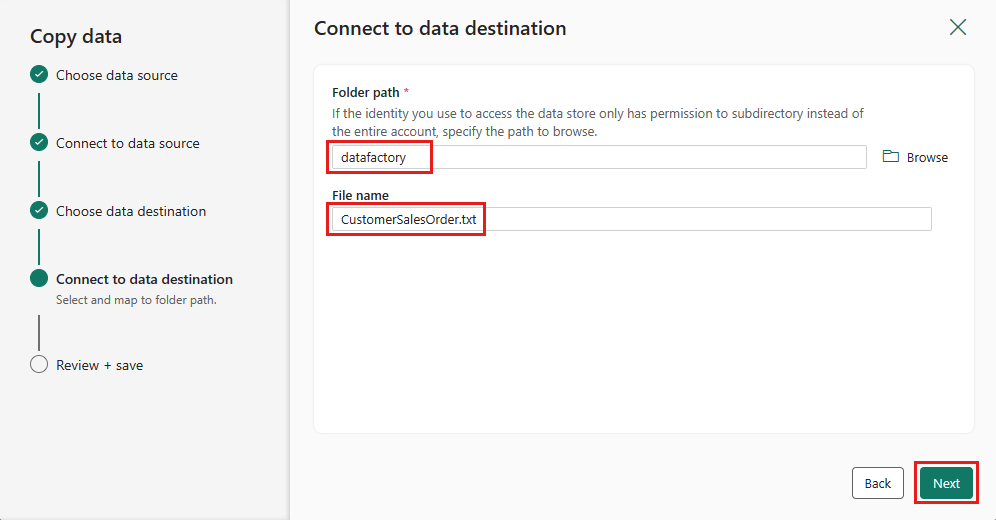
[次 を再度選択して、既定のファイル形式、列区切り記号、行区切り記号、圧縮の種類 (必要に応じてヘッダーを含む) を受け入れます。
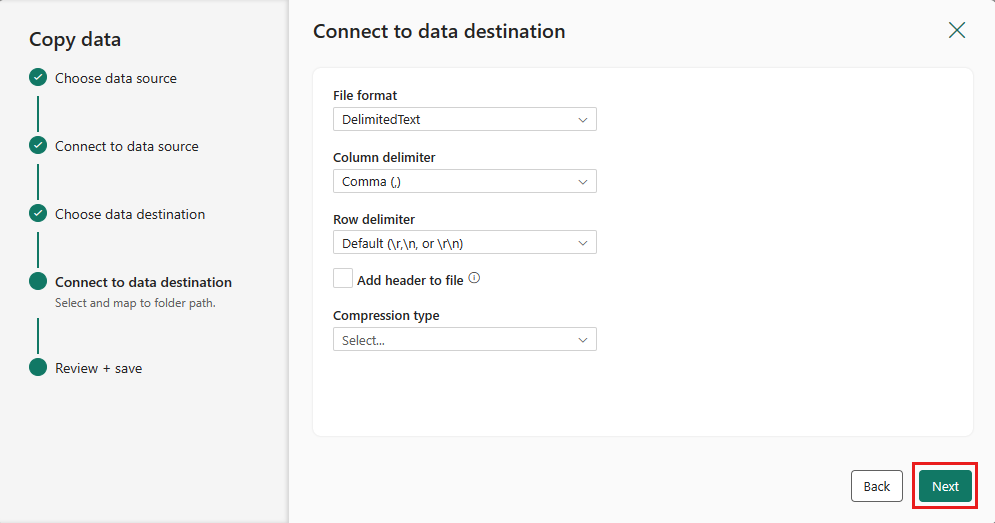
設定を完了します。 その後、確認して [保存して実行] を選択してプロセスを完了します。
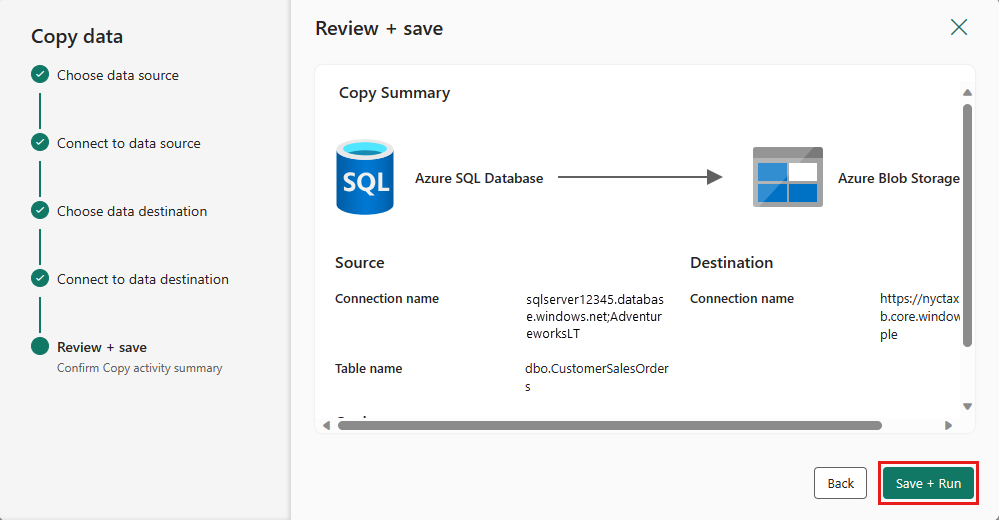
手順 5: データ パイプラインを設計し、データを実行して読み込むよう保存する
[データフロー] アクティビティの後に [コピー] アクティビティを実行するには、[データフロー] アクティビティの [成功] から [コピー] アクティビティにドラッグします。 Copy アクティビティは、データフロー アクティビティが成功した後にのみ実行されます。

[保存] を選択して、データ パイプラインを保存します。 次 [ の実行] を選択してデータ パイプラインを実行し、データを読み込みます。
![[保存して実行] を選択する場所を示すスクリーンショット。](media/transform-data/save-run-pipeline.png)
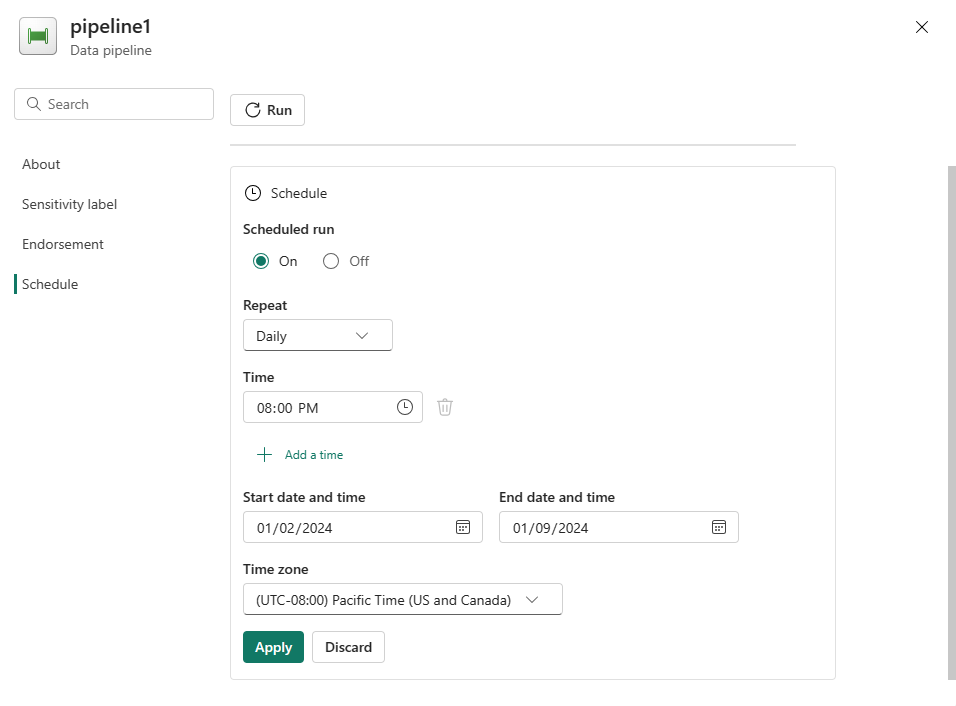
パイプラインの実行をスケジュールする
パイプラインの開発とテストが完了したら、自動的に実行されるようにスケジュールできます。
パイプライン エディター ウィンドウの [ホーム] タブで、[スケジュール] を選択します。
![パイプライン エディターの [ホーム] タブのメニューにある [スケジュール] ボタンのスクリーンショット。](media/transform-data/schedule-button.png)
必要に応じてスケジュールを構成します。 この例では、年の終わりまで毎日午後 8 時に実行するようにパイプラインをスケジュールします。
関連コンテンツ
このサンプルでは、マージ クエリを作成して Azure SQL データベースに格納する Dataflow Gen2 を作成して構成し、データベースから Azure Blob Storage のテキスト ファイルにデータをコピーする方法を示します。 次の方法について学習しました。
- データフローを作成します。
- データフローを使用してデータを変換します。
- データフローを使用してデータ パイプラインを作成します。
- パイプライン内のステップの実行を順序付けます。
- コピー アシスタントを使用してデータをコピーします。
- データパイプラインを実行およびスケジュールします。
次は、パイプライン実行の監視について詳しく説明します。
Microsoft Fabric でパイプラインの実行を監視する方法