Microsoft Fabric で Apache Spark ライブラリを管理する
ライブラリは、事前に記述されたコードのコレクションであり、開発者はそれらをインポートして追加の機能を提供することができます。 ライブラリを使用すると、一般的なタスクを実行するために新規にコードを記述する必要がないので、時間と労力を節約できます。 代わりに、ライブラリをインポートし、その関数とクラスを使用して目的の機能を実現できます。 Microsoft Fabric では、ライブラリの管理と使用に役立つ複数のメカニズムが提供されています。
- 組み込みのライブラリ: 各 Fabric Spark ランタイムには、人気のあるプレインストール済みライブラリの豊富なセットが用意されています。 すべての組み込みライブラリの一覧は、Fabric Spark ランタイムに関する記事に記載されています。
- パブリック ライブラリ: パブリック ライブラリは、現在サポートされている PyPI や Conda などのリポジトリから提供されます。
- カスタム ライブラリ: カスタム ライブラリとは、自身または自身の組織がビルドしたコードのことです。 Fabric では、それらは .whl、.jar、および .tar.gz 形式でサポートされています。 R 言語については、Fabric では .tar.gz のみがサポートされています。 Python カスタム ライブラリの場合は、.whl 形式を使用します。
ライブラリ管理のベスト プラクティスの概要
以下のシナリオでは、Microsoft Fabric でライブラリを使うときのベスト プラクティスについて説明します。
シナリオ 1: 管理者がワークスペースの既定のライブラリを設定する
既定のライブラリを設定するには、ワークスペースの管理者である必要があります。 管理者として、次のタスクを実行できます。
ワークスペースの設定にアタッチされたノートブックと Spark ジョブ定義は、ワークスペースの既定の環境にインストールされたライブラリを使ってセッションを開始します。
シナリオ 2: 1 つまたは複数のコード項目のライブラリ仕様を保持する
異なるコード項目に共通のライブラリがあり、頻繁に更新する必要がない場合は、環境にライブラリをインストールし、それをコード項目にアタッチするのがよい方法です。
発行時に環境のライブラリが有効になるまでにしばらく時間がかかります。 通常は、ライブラリの複雑さに応じて 5 から 15 分かかります。 このプロセスの間に、システムは可能性のある競合の解決を助け、必要な依存関係をダウンロードします。
この方法の利点の 1 つは、アタッチされた環境で Spark セッションが開始されるときに、正常にインストールされたライブラリを確実に使用できることです。これにより、プロジェクトの共通ライブラリを維持する作業が不要になります。
安定性があるので、パイプライン シナリオにはそれを強くお勧めします。
シナリオ 3: 対話型実行でのインライン インストール
ノートブックを使って対話形式でコードを記述する場合、PyPI や Conda の新しいライブラリをさらに追加したり、1 回だけ使うカスタム ライブラリを検証したりするには、インライン インストールを使うのがベスト プラクティスです。 Fabric のインライン コマンドを使用すると、現在のノートブック Spark セッションでライブラリを有効にできます。 このようにすると、インストールは速くなりますが、インストールされるライブラリは異なるセッション間で保持されません。
%pip install は場合によって異なる依存関係ツリーを生成し、ライブラリの競合につながる可能性があるため、インライン コマンドはパイプラインの実行では既定でオフになっており、パイプラインでの使用はお勧めしません。
サポートされるライブラリの種類の概要
| ライブラリの種類 | 環境ライブラリ管理 | インライン インストール |
|---|---|---|
| Python Public (PyPI & Conda) | サポートされています | サポートされています |
| Python カスタム (.whl) | サポートされています | サポートされています |
| R Public (CRAN) | サポートされていません | サポートされています |
| R カスタム (.tar.gz) | カスタム ライブラリとしてサポート | サポートされています |
| Jar | カスタム ライブラリとしてサポート | サポートされています |
インライン インストール
インライン コマンドは、ノートブック セッションごとのライブラリの管理をサポートします。
Python のインライン インストール
システムは Python インタープリターを再起動して、ライブラリの変更を適用します。 コマンド セルを実行する前に定義された変数は失われます。 Python パッケージを追加、削除、または更新するためのすべてのコマンドを、ノートブックの先頭に置くことを強くお勧めします。
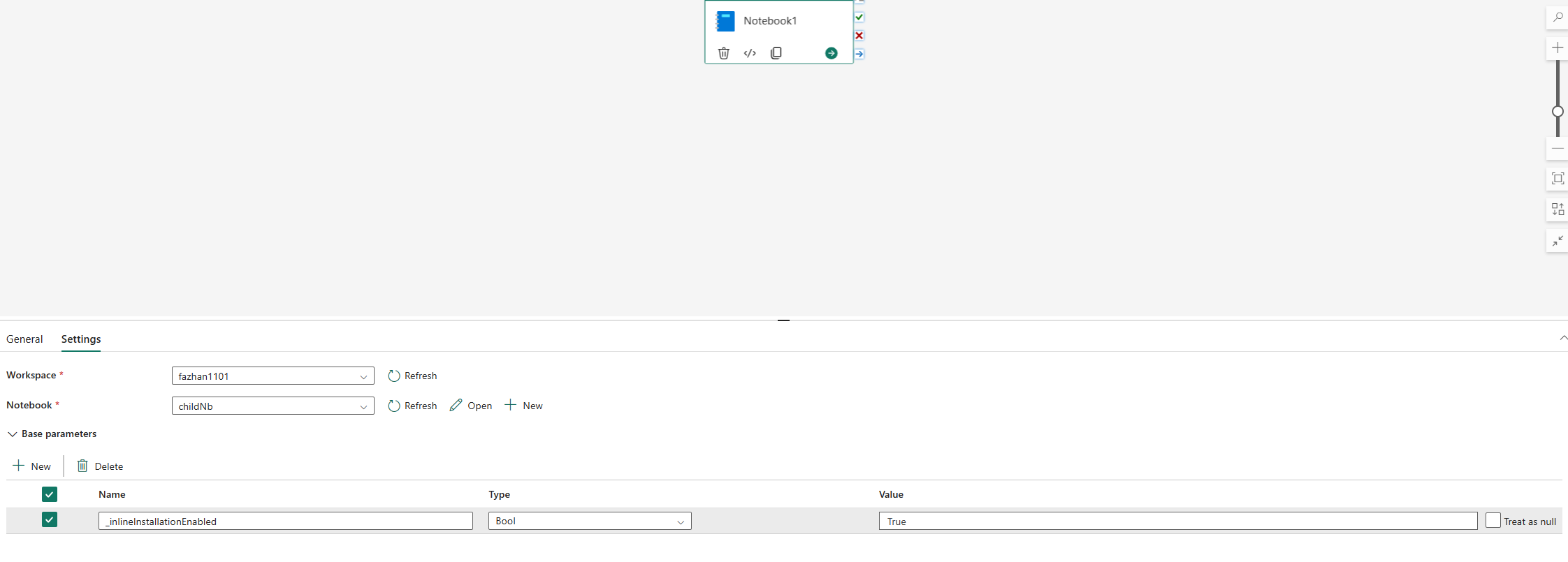
Python ライブラリの管理のインライン コマンドは、既定でノートブック パイプラインの実行で無効になっています。 パイプラインの%pip installを有効にする場合は、bool パラメーターが True と等しい "_inlineInstallationEnabled" をノートブック アクティビティ パラメーターに追加します。
Note
%pip installは、一貫性のない結果が生じる可能性があります。 環境にライブラリをインストールし、パイプラインでの使用をお勧めします。
ノートブック参照の実行では、Python ライブラリを管理するためのインライン コマンドはサポートされていません。 実行の正確性を確保するために、これらのインライン コマンドを参照先のノートブックから削除することをお勧めします。
%pip の代わりに !pip をお勧めします。 !pip は IPython 組み込みシェル コマンドであり、次の制限があります。
!pipは、Executor ノードではなく、ドライバー ノードにのみパッケージをインストールします。!pipを通じてインストールされるパッケージは、組み込みパッケージと競合する場合、または既にノートブックにインポートされている場合には影響しません。
ただし、%pip はこれらのシナリオを処理します。 %pip を通じてインストールされたライブラリは、ドライバーノードと Executor ノードの両方で使用でき、ライブラリが既にインポートされている場合でも有効です。
ヒント
通常、%conda install コマンドは 、新しい Python ライブラリをインストールする %pip install コマンドよりも時間がかかります。 完全な依存関係をチェックし、競合を解決します。
信頼性と安定性を向上させるために %conda install を使用できます。 インストールするライブラリがランタイム環境にプレインストールされているライブラリと競合しないことがわかっている場合、%pip install を使用できます。
使用可能なすべての Python インライン コマンドとその説明については、「%pip コマンド」と「%conda コマンド」を参照してください。
インライン インストールを使用して Python パブリック ライブラリを管理する
この例では、インライン コマンドを使用してライブラリを管理する方法を示します。 Python 用の強力な視覚化ライブラリである altair を使用して、1 回限りのデータ探索を行うとします。 このライブラリがワークスペースにインストールされていないとします。 次の例では、conda コマンドを使用して手順を説明します。
インライン コマンドを使用すると、ノートブックの他のセッションや他のアイテムに影響を与えることなく、ノートブック セッションで altair を有効にすることができます。
ノートブック コード セルで次のコマンドを実行します。 最初のコマンドでは、altair ライブラリをインストールします。 また、視覚化に使用できるセマンティック モデルを含む vega_datasets をインストールします。
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandセルの出力は、インストールの結果を示します。
別のノートブック セルで次のコードを実行することで、パッケージとセマンティック モデルをインポートします。
import altair as alt from vega_datasets import dataこれで、セッション スコープの altair ライブラリを試すことができます。
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
インライン インストールを使用して Python カスタム ライブラリを管理する
Python カスタム ライブラリは、ノートブックのリソース フォルダーまたはアタッチされた環境にアップロードできます。 リソース フォルダーは、各ノートブックと環境によって提供される組み込みのファイル システムです。 詳しくは、「Notebook のリソース」をご覧ください。 アップロードした後は、カスタム ライブラリをコード セルにドラッグ アンド ドロップでき、ライブラリをインストールするインライン コマンドが自動的に生成されます。 または、次のコマンドを使ってインストールできます。
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R のインライン インストール
R ライブラリを管理するために、Fabric では install.packages()、remove.packages()、および devtools:: コマンドがサポートされています。 使用可能なすべての R インライン コマンドと説明については、「install.packages コマンド」と「remove.package コマンド」を参照してください。
インライン インストールを使用して R パブリック ライブラリを管理する
次の例を使用して、R パブリック ライブラリをインストールする手順について説明します。
R フィード ライブラリをインストールするには:
ノートブック リボンで作業言語を SparkR(R) に切り替えます。
ノートブック セルで次のコマンドを実行して、caesar ライブラリをインストールします。
install.packages("caesar")これで、Spark ジョブでセッション スコープの caesar ライブラリを試すことができます。
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
インライン インストールによるJarライブラリの管理
.jar ファイルは、次のコマンドを使用してノートブック セッションでサポートされます。
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
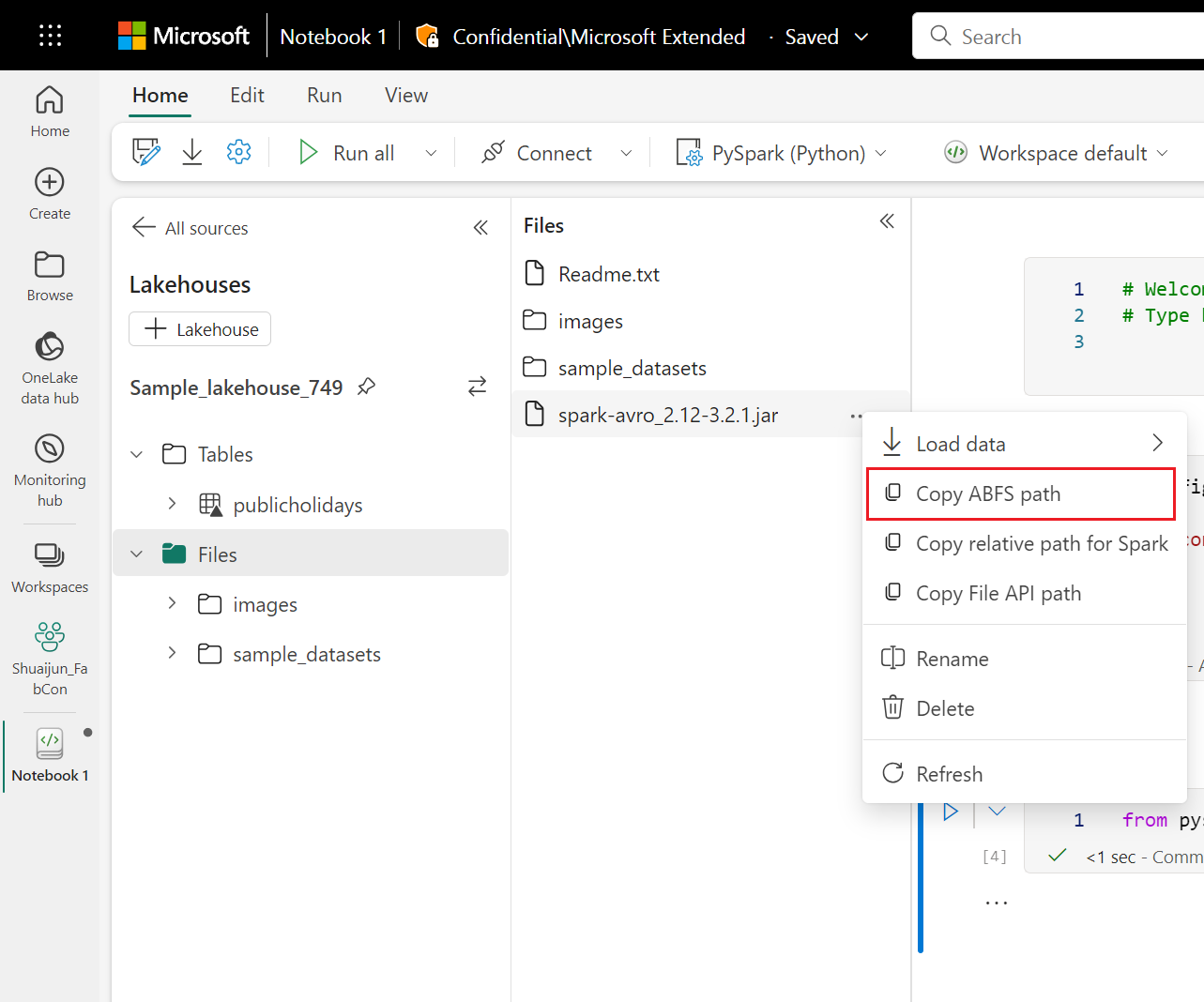
コード セルでは、Lakehouse のストレージを例として使用しています。 ノートブック エクスプローラーでは、完全なファイル ABFS パスをコピーし、コード内で置き換えることができます。