Fabric 環境での Spark コンピューティング構成設定
Microsoft Fabric のデータ エンジニアリングとデータ サイエンのエクスペリエンスは、フル マネージドの Spark コンピューティング プラットフォームで動作します。 このプラットフォームは、並外れた速度と効率を提供するように設計されています。 これには、スターター プールとカスタム プールがあります。
Fabric 環境には、ノートブックと Spark ジョブによってアタッチされるとユーザーが Spark セッションを構成できる Spark コンピューティング プロパティなどの構成のコレクションが含まれます。 環境を使用すると、Spark ジョブを実行するためのコンピューティング構成を柔軟にカスタマイズできます。 環境では、コンピューティング セクションにより、ユーザーは Spark セッション レベルのプロパティを構成して、ワークロードの要件に基づいて Executor のメモリとコアをカスタマイズできます。
ワークスペース管理者は、[ワークスペースの設定] 画面の [Data Engineering/Science] セクションの [プール] タブにある [アイテムのコンピューティング構成をカスタマイズする] スイッチを使用して、コンピューティングのカスタマイズを有効または無効にすることができます。
ワークスペース管理者は、この設定を有効にすることで、Fabric 環境で既定のセッション レベルのコンピューティング構成を変更することを、メンバーと共同作成者に委任できます。
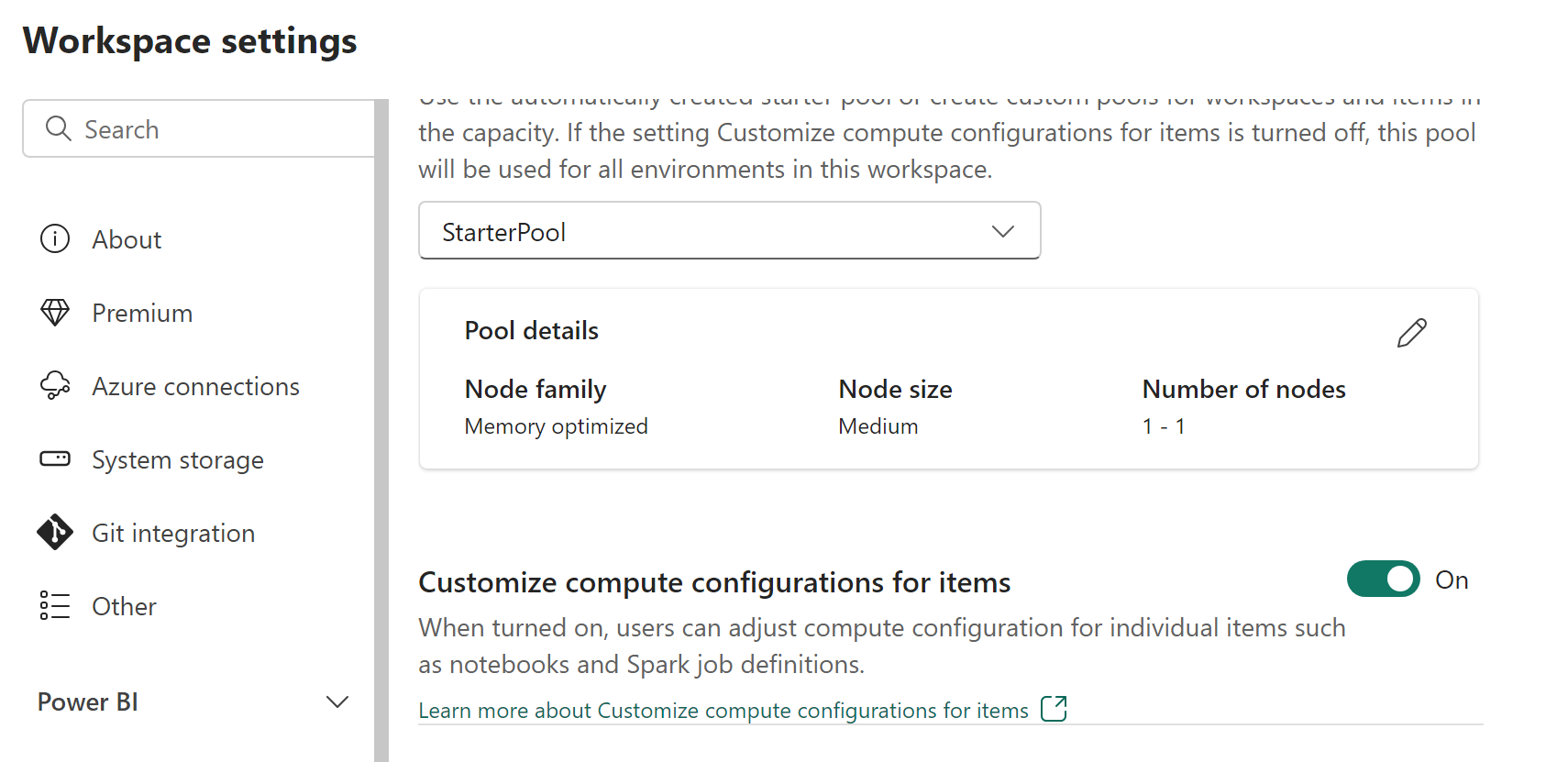
ワークスペース管理者がワークスペース設定でこのオプションを無効にした場合、環境のコンピューティング セクションが無効になり、ワークスペースにおける既定のプールのコンピューティング構成が Spark ジョブの実行に使用されます。
環境でのセッション レベルのコンピューティング プロパティのカスタマイズ
ユーザーとして、Fabric ワークスペースで利用可能なプールの一覧から環境のプールを選択できます。 Fabric ワークスペース管理者は、既定のスターター プールとカスタム プールを作成します。
![環境の [コンピューティング] セクションでプールを選択する場所を示すスクリーンショット。](media/environment-introduction/environment-pool-selection.png)
[コンピューティング] セクションでプールを選択したら、選択したプールのノード サイズと制限の範囲内で、Executor のコアとメモリを調整できます。
例: 環境プールとして、ノード サイズが大 (16 Spark 仮想コア) のカスタム プールを選択します。 その後、ジョブ レベル要件に基づいて、Driver/Executor コアを4、8、16 のいずれかに選択できます。 Driver と Executor に割り当てるメモリは、28 g、56 g、112 g のいずれかを選択できますが、いずれも大のノード メモリ制限の範囲内です。
![環境の [コンピューティング] セクションでコア数を選択する場所を示すスクリーンショット。](media/environment-introduction/env-cores-selection.png)
Spark コンピューティング サイズとそのコアまたはメモリ オプションの詳細については、「Microsoft Fabric の Spark コンピューティングとは」を参照してください。