Azure Machine Learning ベースのモデルを使用する
Dynamics 365 Customer Insights の統合データ - データは、追加のビジネス インサイトを生成できる機械学習モデルを構築するためのソースです。 Customer Insights - Data は Azure Machine Learning と統合し、独自のカスタム モデルを使用します。
前提条件
- Customer Insights - Data へのアクセス
- アクティブな Azure Enterprise のサブスクリプション
- 統合顧客プロファイル
- Azure Blob Storage へのテーブルのエクスポートが構成済み
Azure Machine Learning ワークスペースの設定
ワークスペースを作成するためのさまざまなオプションについては、Azure Machine Learning ワークスペースの作成 を参照してください。 最適なパフォーマンスを得るには、Customer Insights 環境に地理的に最も近い Azure リージョンにワークスペースを作成します。
Azure Machine Learning Studio からワークスペースにアクセスします。 ワークスペースを 操作する方法 はいくつかあります。
Azure Machine Learning デザイナーと連携する
Azure Machine Learning デザイナーは、データセットとモジュールをドラッグ アンド ドロップできるビジュアル キャンバスを提供します。 デザイナーから作成されたバッチ パイプラインは、Customer Insights - Data に統合できます (適切に構成されている場合)。
Azure Machine Learning SDK との連携
データ サイエンティストと AI 開発者は、Azure Machine Learning SDK を使用して、機械学習ワークフローを構築します。 現在、SDK を使用してトレーニングされたモデルは直接統合することはできません。 このモデルを使用するバッチ推論パイプラインは、Customer Insights - Data との統合に必要です。
Customer Insights - Data と統合するためのバッチ パイプラインの要件
データベースの構成
バッチ推論パイプラインに Customer Insights のテーブル データを使用するデータセットを作成します。 これらのデータセットをワークスペースに登録します。 現在、.csv 形式の 表形式データセット のみをサポートしています。 テーブル データに対応するデータセットをパイプラインのパラメータとするする必要があります。
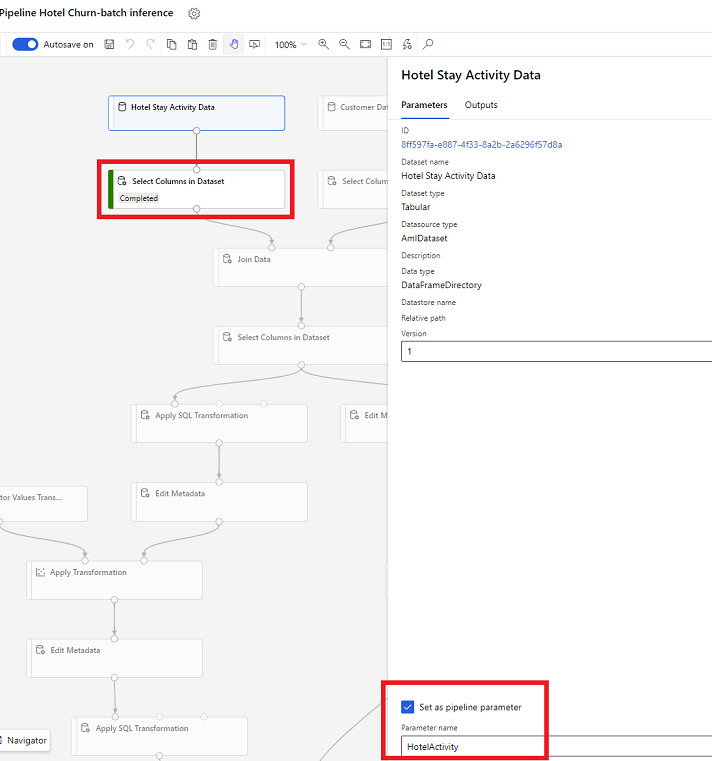
デザイナーのデータセット パラメーター
デザイナーで、データセットで列を選択 を開き、パイプライン パラメーターとして設定 を選択して、パラメーターの名前を指定します。
SDK (Python) のデータセット パラメーター
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
バッチ推論パイプライン
デザイナーでは、トレーニング パイプラインを使用して、推論パイプラインを作成または更新します。 現在、バッチ推論パイプラインのみがサポートされています。
SDK を使用して、パイプラインをエンドポイントに公開できます。 現在、Customer Insights - Data は、Machine Learning ワークスペースにあるバッチ パイプライン エンドポイントの、既定のパイプラインと統合されています。
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
パイプライン データをインポートする
デザイナーは、パイプラインの出力を Azure Storage にエクスポートできる データ エクスポート モジュール を提供します。 現在、モジュールはデータストア型の Azure Blob Storage を使用し、データストア と 相対 パス をパラメータ化する必要があります。 システムは、パイプラインの実行中に、アプリケーションにアクセス可能なデータストアとパスを使用して、これら両方のパラメーターを上書きします。
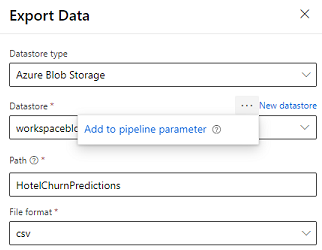
コードを使用して推論出力を作成する場合、ワークスペースで 登録済みデータストア 内のパスに出力をアップロードできます。 パスとデータストアがパイプラインでパラメーター化されている場合、Customer insights は推論出力を読み込んでインポートできます。 現在、csv 形式の 1 つの表形式の出力がサポートされています。 パスには、ディレクトリとファイル名が含まれている必要があります。
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name