マイクロサービスの回復性と高可用性
ヒント
このコンテンツは eBook の「コンテナー化された .NET アプリケーションの .NET マイクロサービス アーキテクチャ」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

予期しない障害の解決は、特に分散システムで最も困難な問題の 1 つです。 開発者が記述するコードの多くには、例外処理が含まれており、これもテストで最も多くの時間がかかる箇所です。 問題は、エラーを処理するコードを記述するよりも複雑です。 マイクロサービスを実行しているコンピューターがに障害が発生した場合にどうなるでしょう。 このマイクロサービスの障害 (ハード自体の問題) を検出する必要があるだけでなく、マイクロサービスを再起動するための何らかの処理も実行する必要があります。
マイクロサービスは、障害に対する回復力を持つ必要があるだけでなく、しばしば可用性のために別のコンピューターで再起動できる必要があります。 この回復力は、マイクロサービスのために保存された状態、およびマイクロサービスがこの状態を正常に回復できるかどうか、さらにマイクロサービスが正常に再起動できるかどうかを意味します。 言い換えると、コンピューティング機能の回復力 (プロセスをいつでも再起動できる) だけでなく状態またはデータの回復力 (データ損失がなく、データの一貫性が維持されている) が必要です。
アプリケーションのアップグレード中にエラーが発生したときなど、他のシナリオでは、回復性の問題が複雑化します。 展開システムと連携するマイクロサービスは、新しいバージョンへの進行を継続できるかどうか、または代わりに一貫性のある状態を維持するために以前のバージョンにロールバックするかどうかを決定する必要があります。 進行を続けるために十分なマシンを使用できるかどうか、マイクロサービスの以前のバージョンを回復する方法などの疑問を考慮する必要があります。 このアプローチでは、アプリケーション全体とオーケストレーターでこれらの決定を行うことができるように、マイクロサービスから正常性に関する情報を出力する必要があります。
さらに、回復力はクラウドベースのシステムがどのように動作する必要があるかに関連します。 前述のように、クラウドベースのシステムは障害を受け入れる必要があり、そこから自動的に回復を試みる必要があります。 たとえば、ネットワークまたはコンテナーの障害が発生した場合、多くの場合、クラウドの傷害は部分的なので、クライアント アプリまたはクライアント サービスが、メッセージの送信を再試行したり要求を再試行したりするための戦略を持っている必要があります。 このガイドの「回復性があるアプリケーションを実装する」のセクションでは、部分的な障害に対処する方法を説明します。 この問題を処理するためのさまざまなポリシーが提供される Polly などのライブラリを使用することによる、.NET で指数バックオフまたは遮断器パターンを使用した再試行などの手法について説明しています。
正常性の管理とマイクロサービスでの診断
当然のことでありながら見落とされがちなのは、マイクロサービスが、その正常性と診断を報告する必要があることです。 報告しない場合、操作の観点からの分析情報がほとんどありません。 独立したサービスのセット間の診断イベントを関連付けること、およびイベントの順序を理解するためにコンピューター クロックのずれを処理することは困難です。 合意したプロトコルとデータ形式でマイクロサービスと対話するのと同じように、正常性および診断イベントをログに記録する方法を標準化する必要があります。これは、最終的にクエリと表示のためのイベントの保存につながります。 マイクロサービスのアプローチでは、異なる複数のチームが単一のログ記録形式に合意することが重要です。 アプリケーションでの診断イベントの表示に一貫した方法が必要です。
正常性チェック
正常性は診断とは異なります。 正常性は、適切なアクションを実行するためにマイクロサービスが現在の状態を報告することです。 可用性を維持するためのアップグレードと展開の操作は、この良い例です。 プロセスのクラッシュやコンピューターの再起動のために、サービスが現在異常でも、サービスは引き続き動作している場合があります。 最も望まないことは、アップグレードの実行によってこれを悪化させることです。 最良のアプローチは、最初に調査を行うか、マイクロサービスが回復できるように時間を与えることです。 マイクロサービスからの正常性イベントは、情報に基づいた意思決定を行い、実質的に自己修復サービスを作成するのに役立ちます。
このガイドの ASP.NET Core サービス セクションでの正常性チェックの実装では、新しい ASP.NET HealthChecks ライブラリをマイクロサービスで使用し、適切なアクションを実行するために状態を監視サービスに報告する方法について説明しています。
AspNetCore.Diagnostics.HealthChecks と呼ばれる優れたオープンソース ライブラリを使用することもできます。これは、GitHub で入手でき、NuGet パッケージとして入手することもできます。 このライブラリでも正常性チェックが行われますが、チェックが 2 種類あります。
- 稼動:マイクロサービスが稼動しているかどうか。つまり要求を受け入れ、応答できるかどうかがチェックされます。
- 準備:マイクロサービスの依存関係 (データベース、キュー サービスなど) 自体が準備できていて、マイクロサービスが求められた操作を実行できるかどうかがチェックされます。
診断とログのイベント ストリームを使用する
ログは、例外、警告、単純な情報メッセージを含み、アプリケーションまたはサービスがどのように実行されているかに関する情報を提供します。 通常、各ログは、テキスト形式イベントごとに 1 つの行がありますが、複数行にわたって例外のスタック トレースが表示されることがよくあります。
モノリシック サーバー ベースのアプリケーションでは、ログをディスク上のファイルに書き込み (ログ ファイル)、その後ツールを使用して分析することができます。 アプリケーションの実行は、固定サーバーまたは VM に制限されているため、イベントのフローの分析は一般的にそれほど複雑ではありません。 ただし、複数のサービスがオーケストレーター クラスタ内の多くのノードに渡って実行される分散アプリケーションでは、分散イベントを関連付けることは難しい課題です。
マイクロサービスベースのアプリケーションは、イベントまたはログファイルの出力ストリームをアプリケーション自体で保存しないようにする必要があり、さらに中央の場所へのイベントのルーティングも管理しないようにする必要があります 透過的になっている必要があります。つまり、各プロセスは、標準出力にイベント ストリームを書き込むだけで、それが実行されている実行環境インフラストラクチャによって収集されるようにする必要があります。 これらのイベント ストリーム ルーターの例として、Microsoft.Diagnostic.EventFlow は、複数のソースからイベント ストリームを収集し、出力システムに公開します。 これらには、開発環境や、Azure Monitor や Azure Diagnostics などのクラウド システムに向けた、シンプルな標準出力を含めることができます。 ログの検索、アラート、レポート、監視を行うことができる優れたサードパーティ製のログ分析プラットフォームとツールもあり、Splunk のようにリアルタイムで実行できるものもあります。
正常性および診断情報を管理するオーケストレーター
マイクロサービスベースのアプリケーションを作成するときには、複雑さを処理する必要があります。 もちろん、単一のマイクロサービスを扱うのは簡単ですが、数十または数百の種類の数千のマイクロサービスのインスタンスは複雑な問題です。 これは単なるマイクロサービス アーキテクチャの構築のことではありません。安定し、凝縮したシステムを構築する場合、高可用性、アドレス指定能力、回復力、正常性、および診断が必要です。
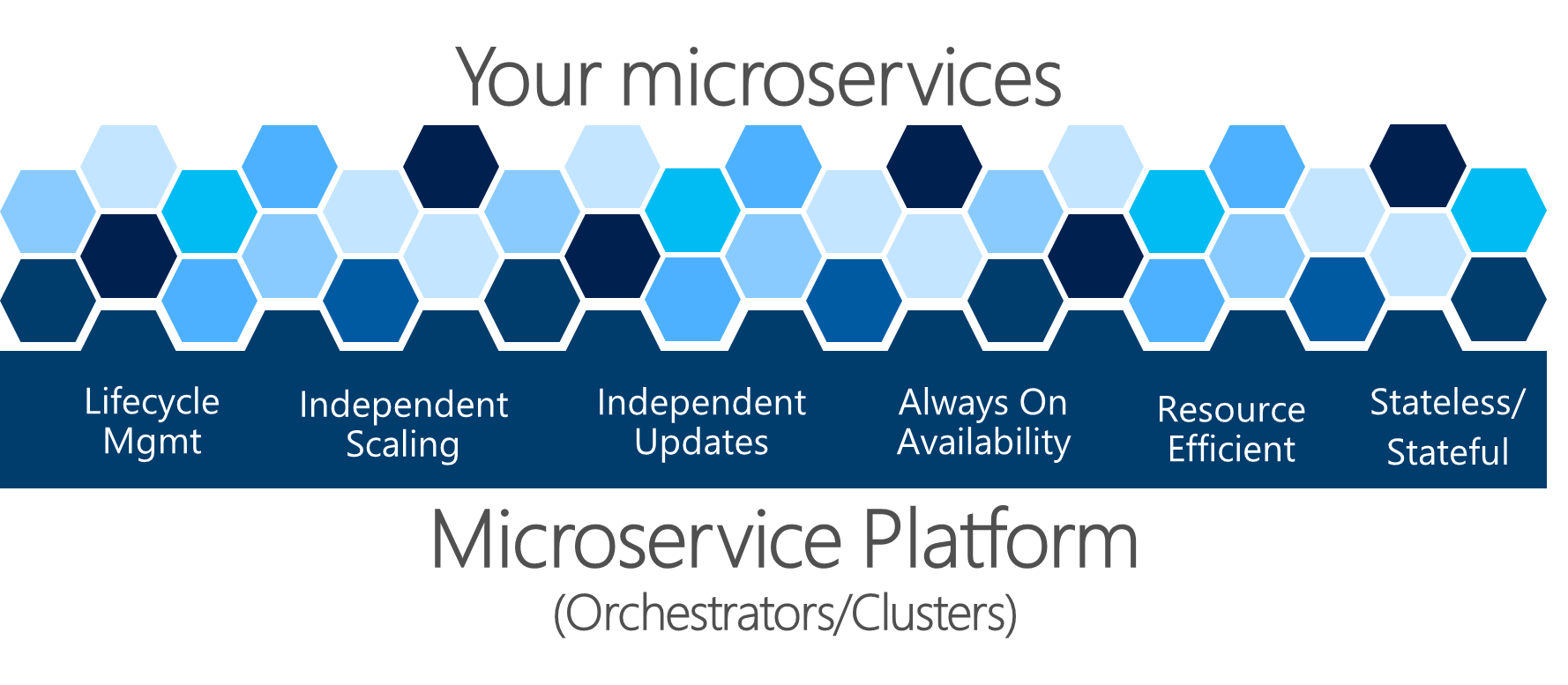
図 4-22 マイクロサービス プラットフォームは、アプリケーションの正常性の管理の基礎です
図 4-22 に示す複雑な問題は、自分で解決するのは困難です。 開発チームは、ビジネス上の問題の解決、およびマイクロサービスベースのアプローチでのカスタム アプリケーションの構築に集中する必要があります。 複雑なインフラストラクチャの問題の解決を重視しないようにする必要があります。そのようにすると、どのマイクロサービスベースのアプリケーションのコストも膨大になります。 したがって、マイクロサービス指向プラットフォームでは、オーケストレーターまたはマイクロサービス クラスターと呼ばれるものが、インフラストラクチャ リソースを効率的に使用して、サービスの構築と実行の難しい問題を解決しようとします。 このアプローチにより、マイクロサービス アプローチを使用するアプリケーションの構築の複雑な作業が軽減されます。
異なるオーケストレーターが同様に聞こえる可能性がありますが、次のセクションで説明するように、OS のプラットフォームによって機能と成熟度の状態が異なります。
その他の技術情報
Twelve-Factor App. XI. ログ: イベント ストリームとしてログを処理する
https://12factor.net/logsMicrosoft 診断 EventFlow ライブラリ GitHub リポジトリ。
https://github.com/Azure/diagnostics-eventflowAzure Diagnostics について
https://learn.microsoft.com/azure/azure-diagnosticsWindows コンピューターを Azure Monitor サービスに接続する
https://learn.microsoft.com/azure/azure-monitor/platform/agent-windows意味を表すログ:セマンティック ログ アプリケーション ブロックを使用する
https://learn.microsoft.com/previous-versions/msp-n-p/dn440729(v=pandp.60)Splunk 公式サイト。
https://www.splunk.com/Windows イベント トレーシング (ETW) の EventSource クラス API
https://learn.microsoft.com/dotnet/api/system.diagnostics.tracing.eventsource
.NET